-
Leetcode 652. 寻找重复的子树
1.题目描述
给定一棵二叉树
root,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。
如果两棵树具有相同的结构和相同的结点值,则它们是重复的。
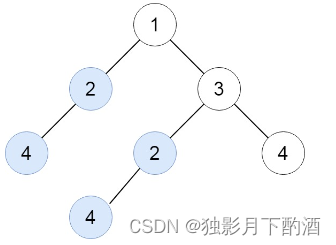
输入:root = [1,2,3,4,null,2,4,null,null,4]
输出:[[2,4],[4]]

输入:root = [2,1,1]
输出:[[1]]
输入:root = [2,2,2,3,null,3,null]
输出:[[2,3],[3]]
提示:
- 树中的结点数在
[1,10^4]范围内。 -200 <= Node.val <= 200
2.思路分析
DFS+哈希
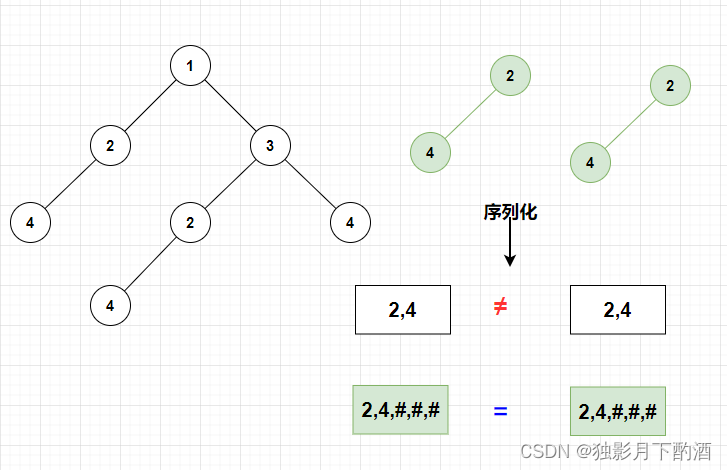
将每一棵子树都「序列化」成一个字符串,并且保证:
- 相同的子树会被序列化成相同的子串;
- 不同的子树会被序列化成不同的子串。
只要使用一个哈希表存储所有子树的序列化结果,如果某一个结果出现了超过一次,我们就发现了一类重复子树。
3.代码实现
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: def findDuplicateSubtrees(self, root: Optional[TreeNode]) -> List[Optional[TreeNode]]: visited, result = {}, [] def dfs(root: Optional[TreeNode]) -> str: if not root: return "" serial = "#".join((str(root.val), dfs(root.left), dfs(root.right))) if serial not in visited: visited[serial] = 1 else: visited[serial] += 1 if visited[serial] == 2: result.append(root) return serial dfs(root) return result- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
复杂度分析:
- 时间复杂度: O(n^2), 序列化的代价是 O(n),遍历的代价是 O(n)
- 空间复杂度: O(n^2)
- 树中的结点数在
-
相关阅读:
Delphi时间戳转日期、日期转时间戳
h5唤起微信小程序
【算法可视化】图论专题
【网页设计】基于HTML在线图书商城购物项目设计与实现_(图书商城10页) bootstarp响应式
17.重定向(redirect)和请求转发(forward)
基于局部自适应阈值分割和Hough变换的答题卡识别算法-含Matlab代码
超声波、毫米波、ToF激光雷达——在低功耗场景的应用选型
11场面试无一被拒!Alibaba Java面试参考指南真香
谷粒商城 高级篇 (五) --------- 商品上架
WPF下实现拖动任意地方都可以拖动窗口
- 原文地址:https://blog.csdn.net/weixin_44852067/article/details/126702605
