-
解决哈希冲突的方案
什么是哈希表
一种实现关联数组抽象数据类型的数据结构,这种结构可以将关键码映射到给定值。简单来说哈希表(key-value)之间存在一个映射关系,是键值对的关系,一个键对应一个值。
什么是哈希冲突
当两个不同的数经过哈希函数计算后得到了同一个结果,即他们会被映射到哈希表的同一个位置时,即称为发生了哈希冲突。简单来说就是哈希函数算出来的地址被别的元素占用了
产生哈希冲突的影响因素
装填因子α(装填因子 α =数据总数 / 哈希表长)、哈希函数、处理冲突的方法
解决哈希冲突方案
开放定址法
再哈希法
链地址法
建立公共溢出区:将哈希表分为基本表和溢出表,将发生冲突的都存放在溢出表中
开放定址法
我们在遇到哈希冲突时,去寻找一个新的空闲的哈希地址。
公式:Hi=(H(key)+di)% m (i=1,2,…,n)
线性探测法
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上往后加一个单位,直至不发生哈希冲突
公式中的di含义:di=1,2,3,…,m-1
 存在问题:出现非同义词冲突(两个不想同的哈希值,抢占同一个后续的哈希地址)被称为堆积或聚集现象
存在问题:出现非同义词冲突(两个不想同的哈希值,抢占同一个后续的哈希地址)被称为堆积或聚集现象平方探测法(二次探测)
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上先加1的平方个单位,若仍然存在则减1的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
公式中的di含义:di=1^2,-1^2,2^2,-2^2,…,k^2,-k^2 ( k<=m/2 )
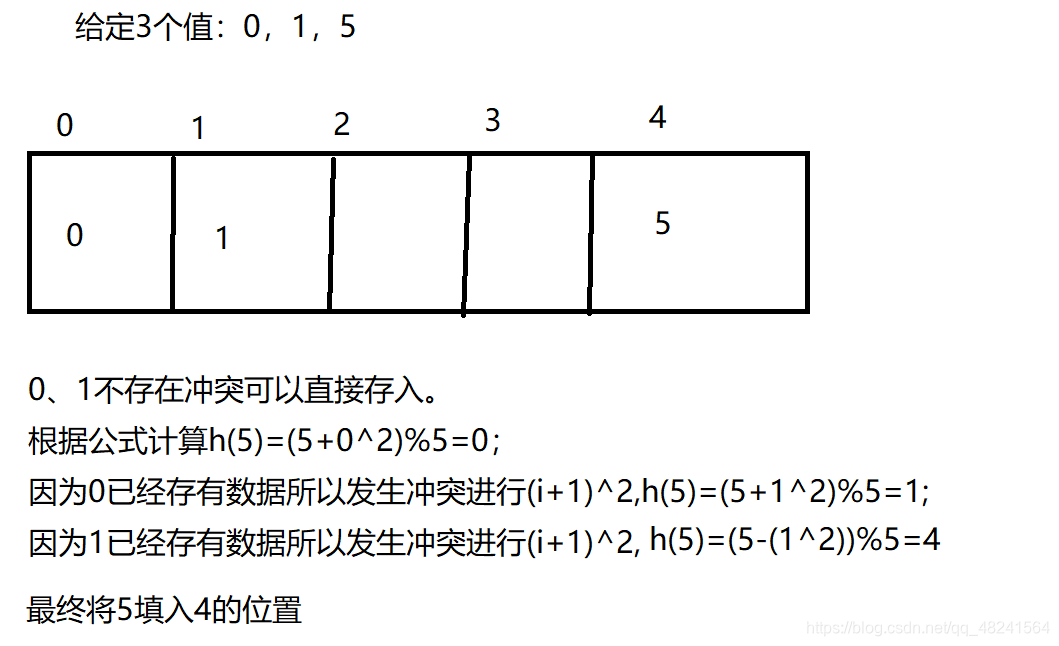
伪随机探测
按顺序决定值时,如果某数据已经存在,通过随机函数随机生成一个数,在原来值的基础上加上随机数,直至不发生哈希冲突。
公式中的di含义:di=伪随机数序列,具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
再哈希法
同时构造多个不同的哈希函数,等发生哈希冲突时就使用第二个、第三个……等其他的哈希函数计算地址,直到不发生冲突为止
优点
不易产生聚集
缺点
增加了计算时间
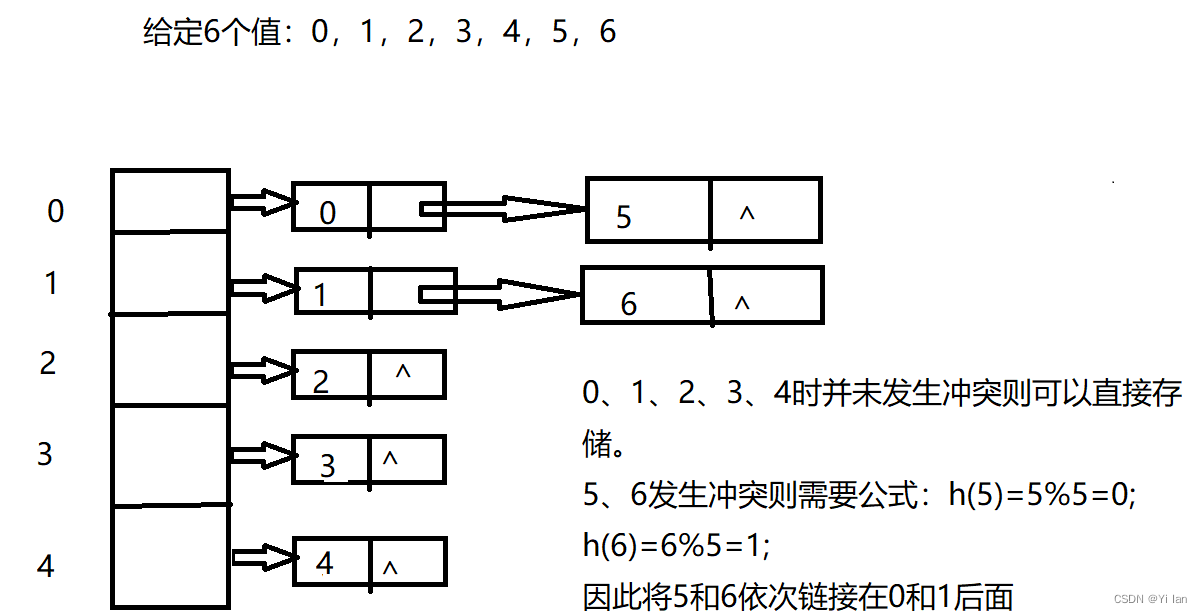
链地址法
将所有哈希地址相同的记录都链接在同一链表中(HashMap使用此法)。如下图:
公式:h(x)=xmod(Hashtable.length);
优点:
1. 处理冲突简单,无堆积现象。即非同义词决不会发生冲突,因此平均查找长度较短;
2. 适合总数经常变化的情况。(因为拉链法中各链表上的结点空间是动态申请的)
3. 占空间小。装填因子可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计
4. 删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。缺点:
1. 查询时效率较低。(存储是动态的,查询时跳转需要更多的时间)
2. 在key-value可以预知,以及没有后续增改操作时候,开放定址法性能优于链地址法。
3. 不容易序列化
建立公共溢出区
将哈希表分为基本表和溢出表,将发生冲突的都存放在溢出表中
-
相关阅读:
二阶段day3
算法系列二:插值查找、斐波那契查找
Ubuntu20.04下Mysql安装和配置远程登录
阿里P8晒1月工资条,看完真的狠狠扎心了…
计算机毕业设计成品java项目开发实例SSM+MySQL实现的家庭医生预约平台
您的连接不是s连接 上不去g 的解决办法
最小二乘法在编程中的实现
七夕活动_一个移动鼠标播放告白气球的Python程序(2022年8月可用)
Pytorch学习:神经网络模块torch.nn.Module和torch.nn.Sequential
PMI-ACP练习题(19)
- 原文地址:https://blog.csdn.net/sanylove/article/details/127906253