-
【博客480】prometheus-----数据查找过程
prometheus-----数据查找过程
先给出index文件的结构:
┌────────────────────────────┬─────────────────────┐ │ magic(0xBAAAD700) <4b> │ version(1) <1 byte> │ ├────────────────────────────┴─────────────────────┤ │ ┌──────────────────────────────────────────────┐ │ │ │ Symbol Table │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Series │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Label Index 1 │ │ │ ├──────────────────────────────────────────────┤ │ │ │ ... │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Label Index N │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Postings 1 │ │ │ ├──────────────────────────────────────────────┤ │ │ │ ... │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Postings N │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Label Index Table │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Postings Table │ │ │ ├──────────────────────────────────────────────┤ │ │ │ TOC │ │ │ └──────────────────────────────────────────────┘ │ └──────────────────────────────────────────────────┘- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
假设:查询某一条series的所有时间点的数据,比如:
({name:http_requests}{job:api-server}{instance:0}),且时间为start/end的所有序列数据
先从选择Block开始,遍历所有Block的meta.json,找到具体的Block:

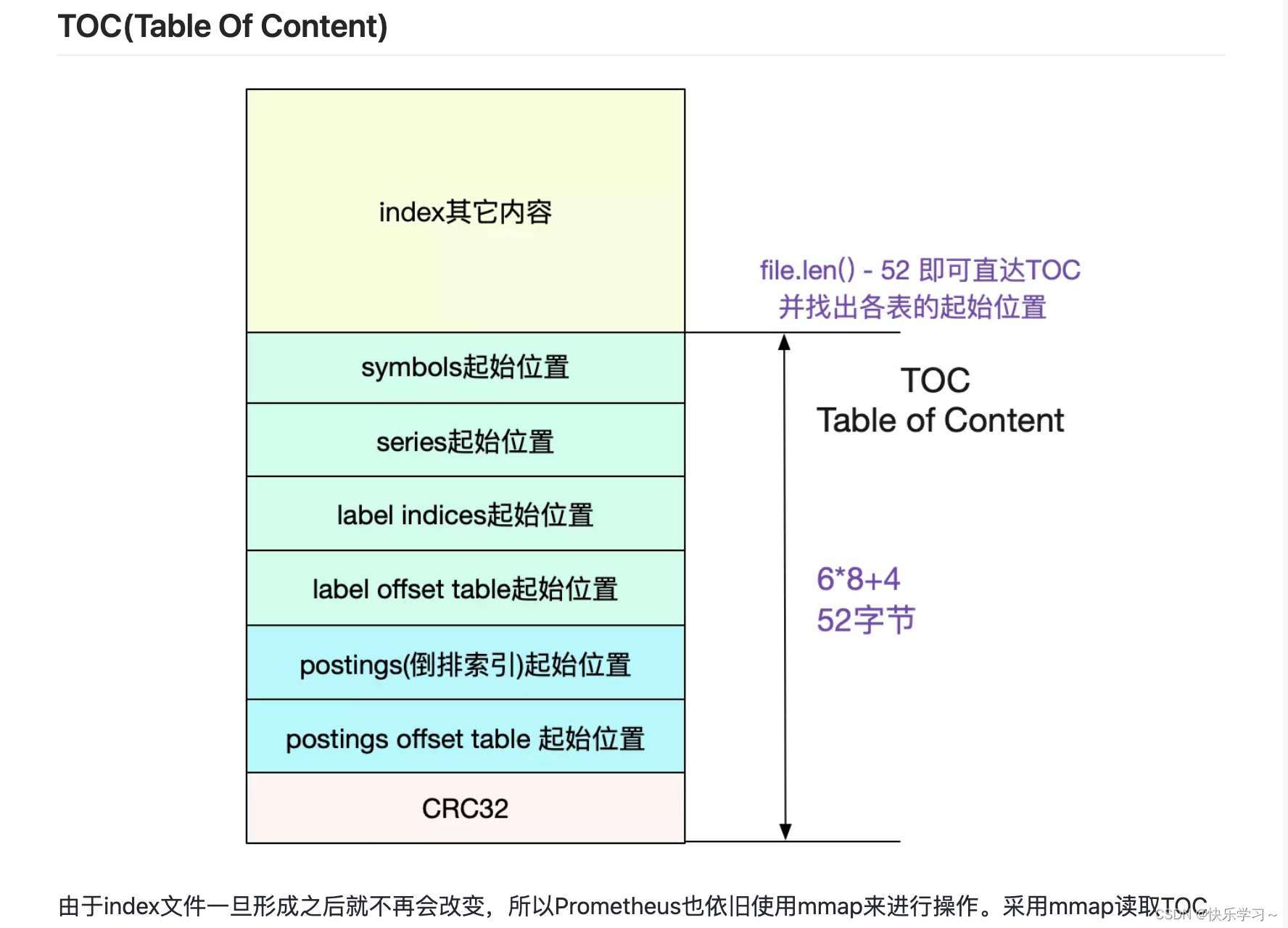
通过Labels找数据是通过倒排索引。我们的倒排索引是保存在index文件里面的。 那么怎么在这个单一文件里找到倒排索引的位置呢?这就引入了TOC(Table Of Content)
Posting offset table 以及 Posting实现了倒排索引机制。
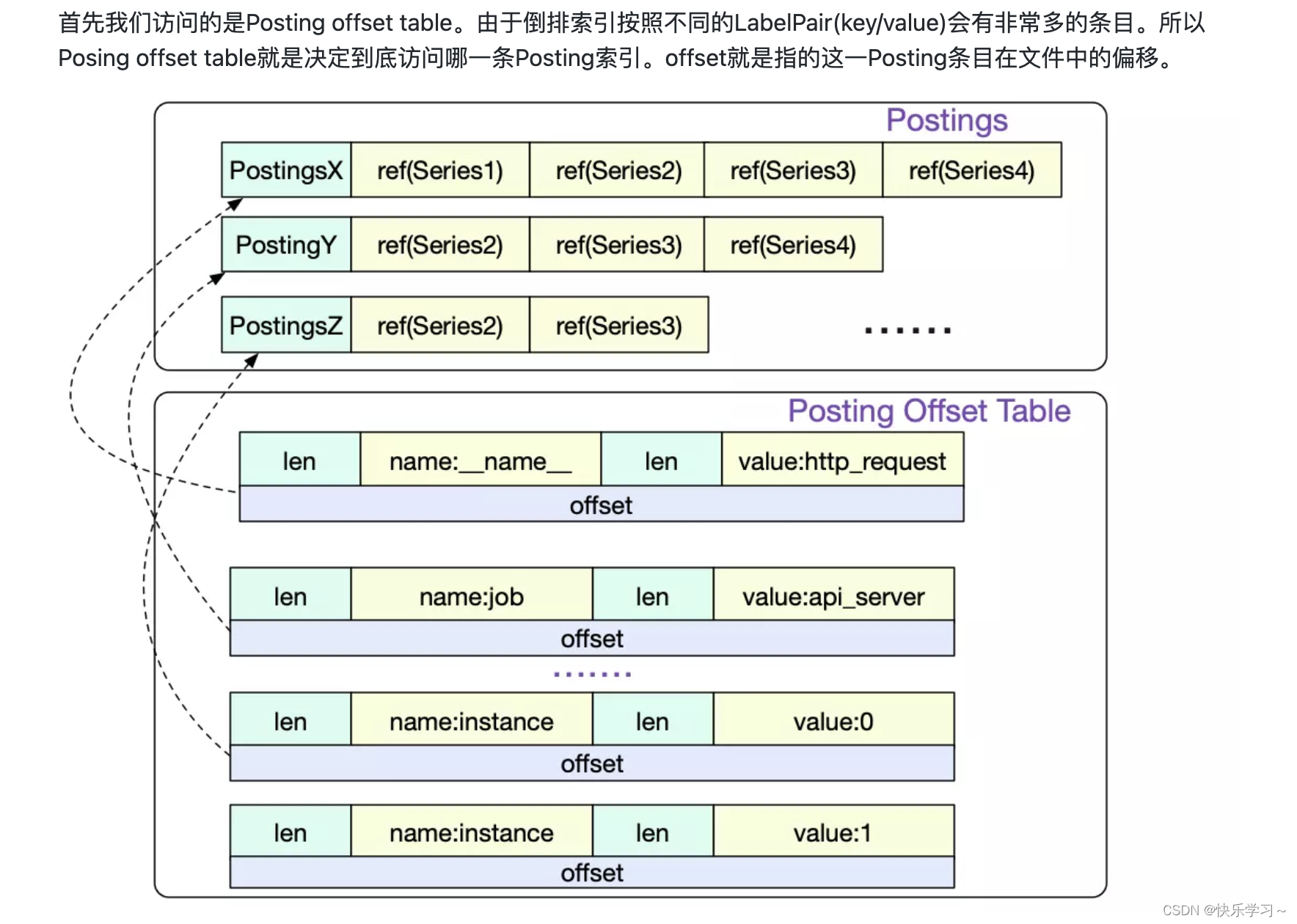

posting中的ref就是偏移量,因为每条series的大小是固定的,因此固定大小乘上偏移量,就能在index文件中找到series
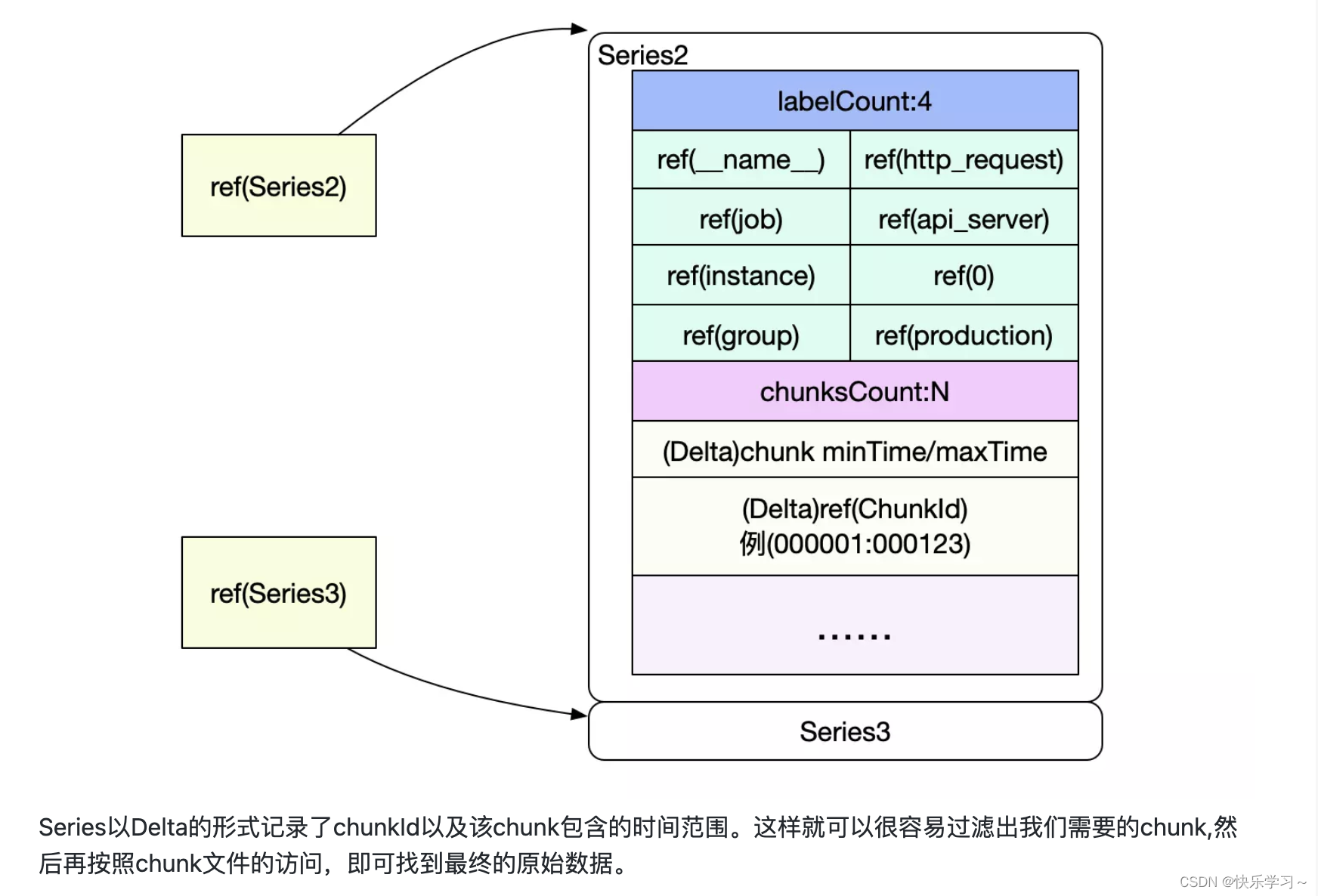
这里ref(series)的值是一个8字节的值,其中4个字节存储量series对应的chunk文件id,另外四个字节存储量其对应的时序数据在chunk文件中的偏移量
每个block中的chunk里面有很多小chunk,每个小chunk就是一堆时序数据,时序数据的存储大致上长这样:

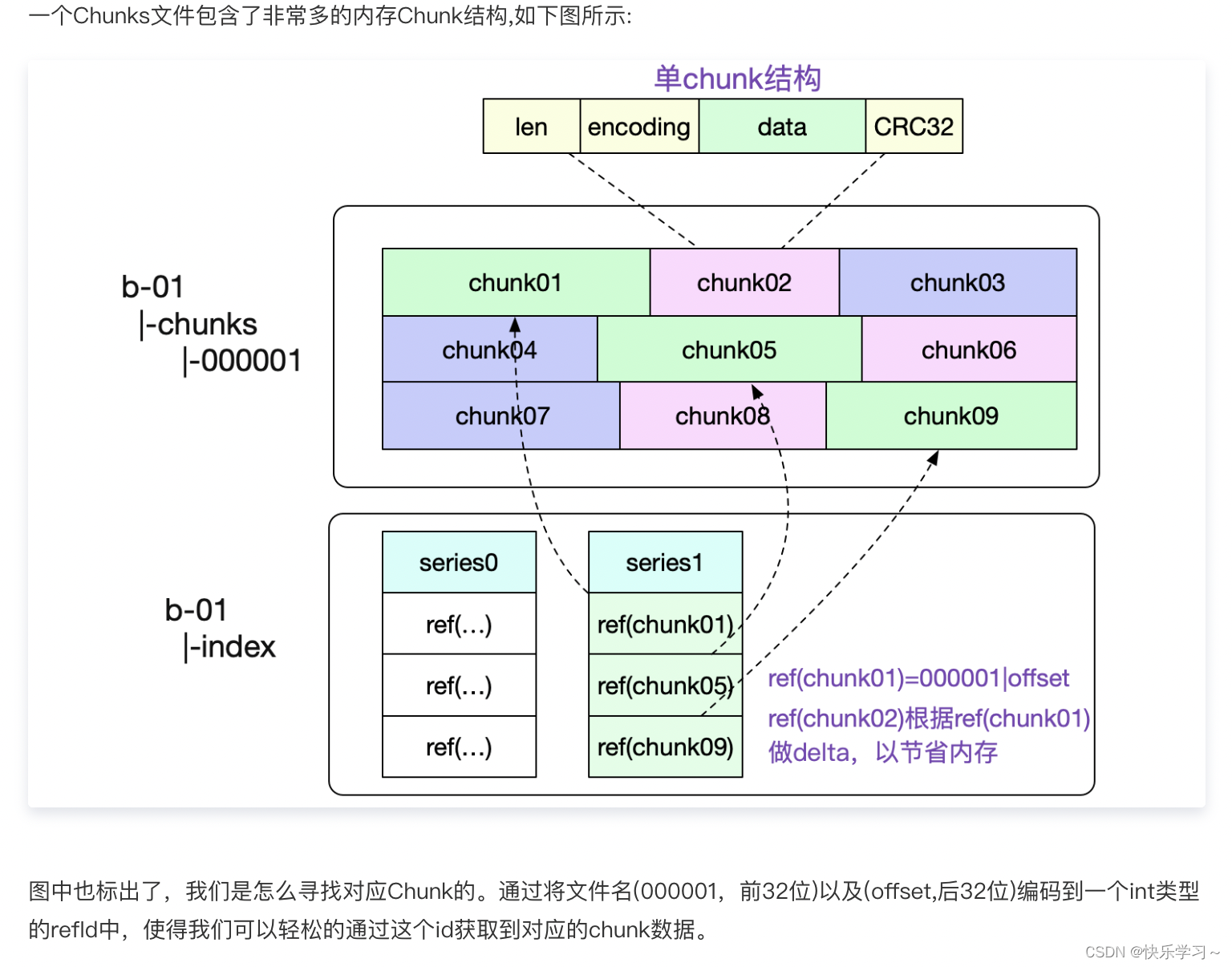
chunk文件则是通过mmap来访问里面具体偏移量对应的时序数据,也就是sample:

符号表:
查找过程中的label名字和值的具体字符串形式都是存在符号表的,然后通过下标来查询对应的值

总结
block文件夹下的chunk文件夹是chunk文件的集合,里面每个chunk文件中又有很多的chunk结构,每个chunk结构就是某个series对应的时序数据。index文件中的series条目会记录其所有的chunk结构所在的chunk文件id以及在文件中的偏移量,以供查询
- 对于一个series的查询,先通过遍历Block的meta.json,根据时间范围,找到符合时间要求的block,然后对每个block里的样本数据进行查询
- 根据block中的index文件中的TOC(也就是目录,记录着各个部分的偏移量),找到倒排索引表和条目Posting offset table 以及 Posting
- 根据要查询的series的label集合,在Posting offset table中查到这些label集合对应哪些Posting
- 然后在这些Posting中将series取出来,并求合集,就得到了符合要求的series
- 根据Posting中存的series偏移量,去index文件中找到具体的series条目
- 根据series条目里记录着其数据所在的那些chunk的位置,这个由一个8字节的ref变量来指示。其中4字节存放了chunk文件的id,另外4字节存放了在chunk文件中的偏移量
- 根据ref的指示,在由mmap映射进来的chunk文件中的对应偏移量位置找到对应的时序数据
- 汇总每个block的结果
-
相关阅读:
【Elasticsearch教程8】Mapping字段类型之keyword
Android相机调用-libusbCamera【外接摄像头】【USB摄像头】 【多摄像头预览】
码蹄集 - MT3435 · 赋值 - 二分图问题 - 图文讲解
助力移动物联网开启高质量发展新征程,芯讯通获“2022年移动物联网先进企业”奖
OPenFast中AeroDyn,ElastoDyn,ElastoDyn_Tower,ServoDyn的作用!
【React】github搜索案例实现兄弟组件通信(axios、PubSub、fetch)
100106. 元素和最小的山形三元组 I
【论文笔记】4D Millimeter-Wave Radar in Autonomous Driving: A Survey
动态树的最值
水波纹文字效果动画
- 原文地址:https://blog.csdn.net/qq_43684922/article/details/126690539
