-
Chapter 6 CNN(Convolutional Neural Network)
Why CNN for Image
事实上,一些图案比整个图像会小很多。神经元不一定要看到整个图像才能判别图形,可以用较少的参数连接到较小的区域。
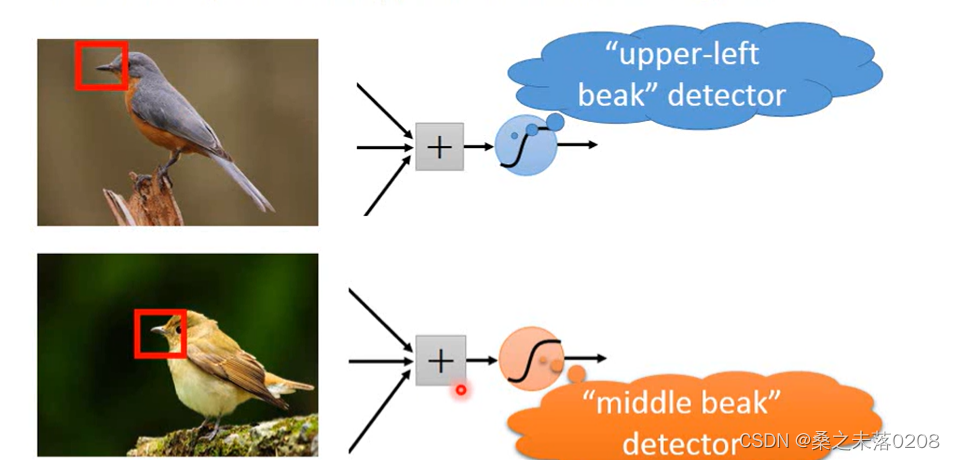
举个例子,可以通过观测鸟嘴来判断图片中的动物为“鸟”。

同样的部位会出现在图片中不同的地区,如下图,第一幅图片鸟嘴出现在图片左上角的位置,第二幅图片鸟嘴出现在图片正中间的位置。由于都是鸟嘴,做的几乎就是相同的事情,所以这两组可以使用相同的一组参数。
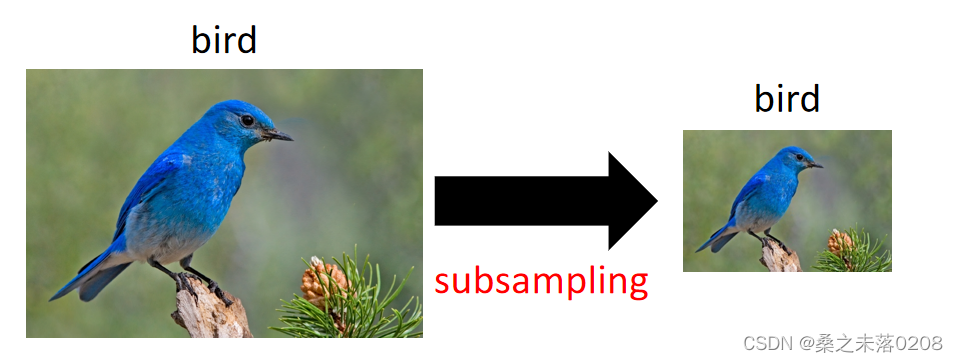
 Subsampling
Subsampling对图片进行subsampling也不会改变对象,只是可以将图像变小,如下图。这样,网络处理图像的参数会更少。
The whole CNN

相关属性:

CNN-Convolution(卷积)
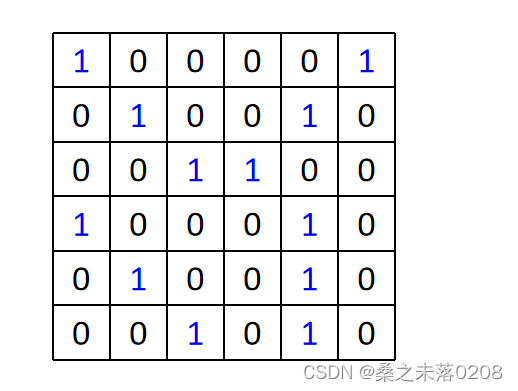
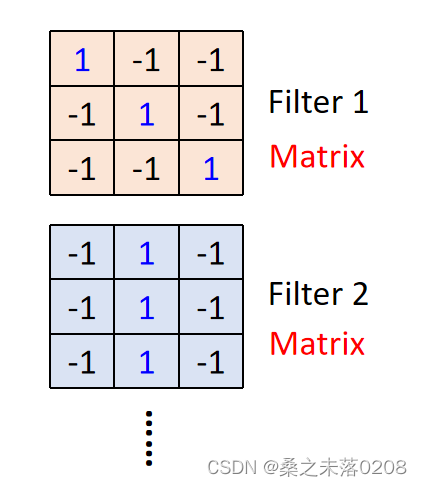
stride表示每次移动的距离。
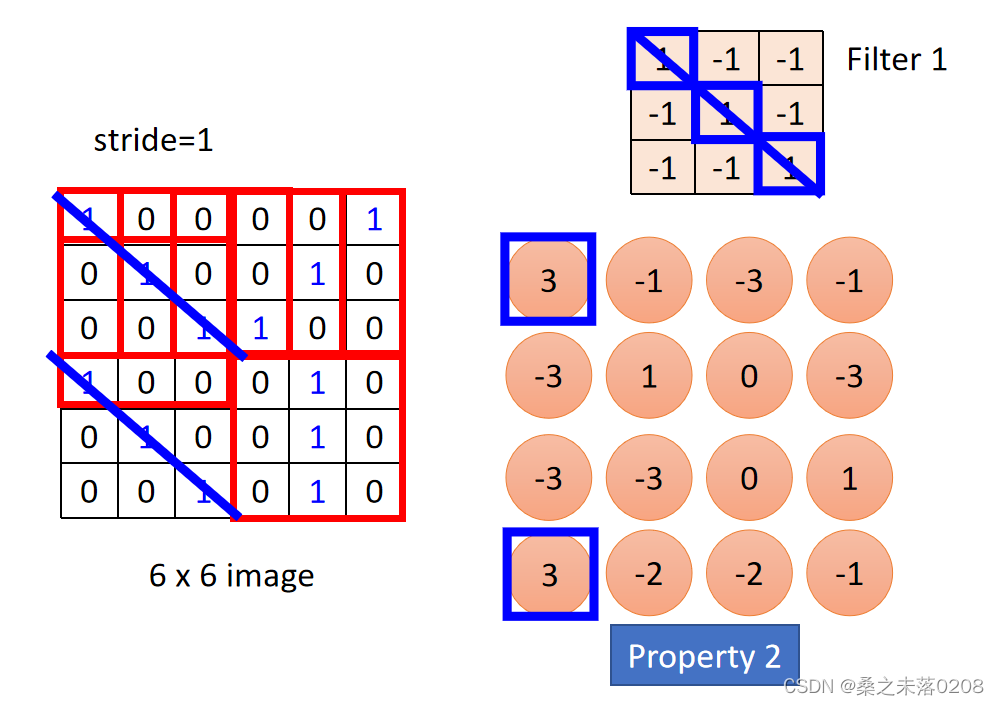
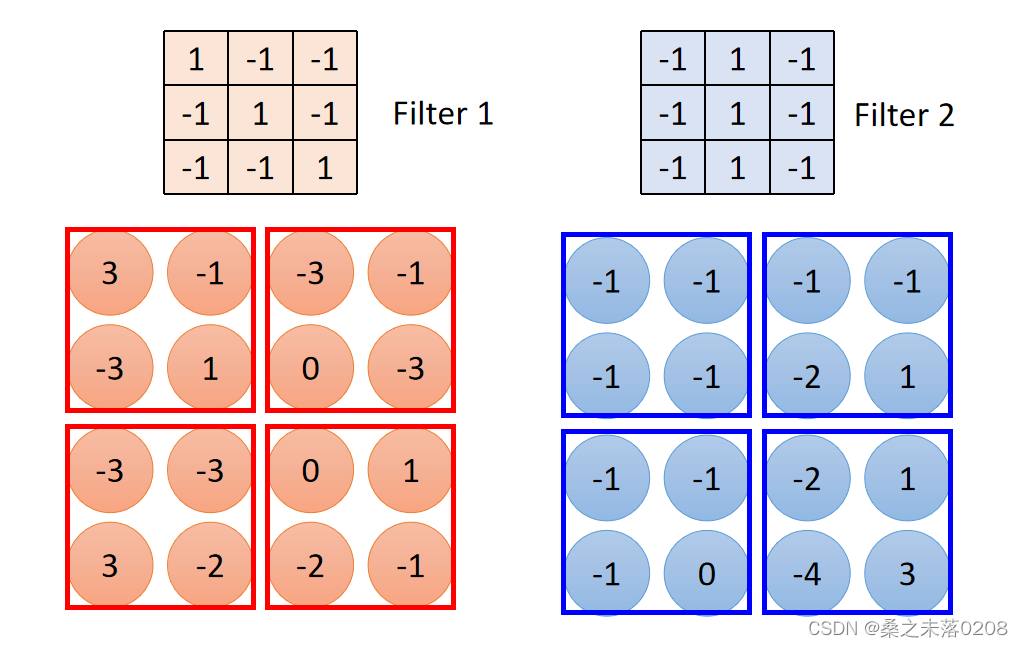
这样6x6的矩阵就可以缩小成4x4的矩阵。然后重复这类操作,得到property 2,和property 1 组成feature map。
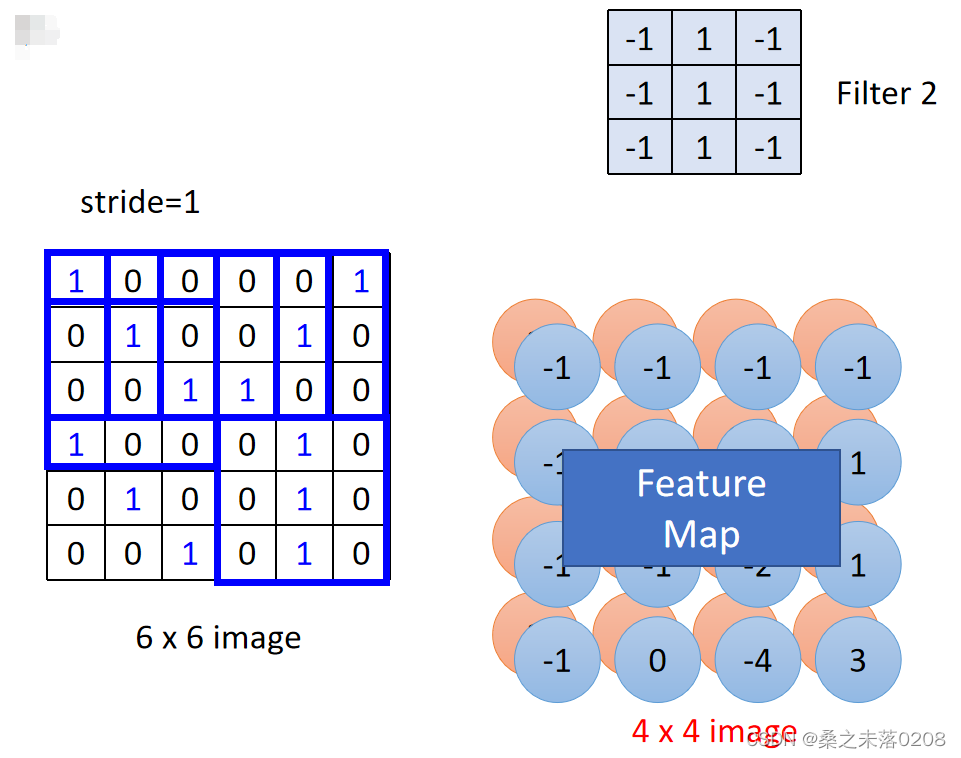
CNN – Colorful image
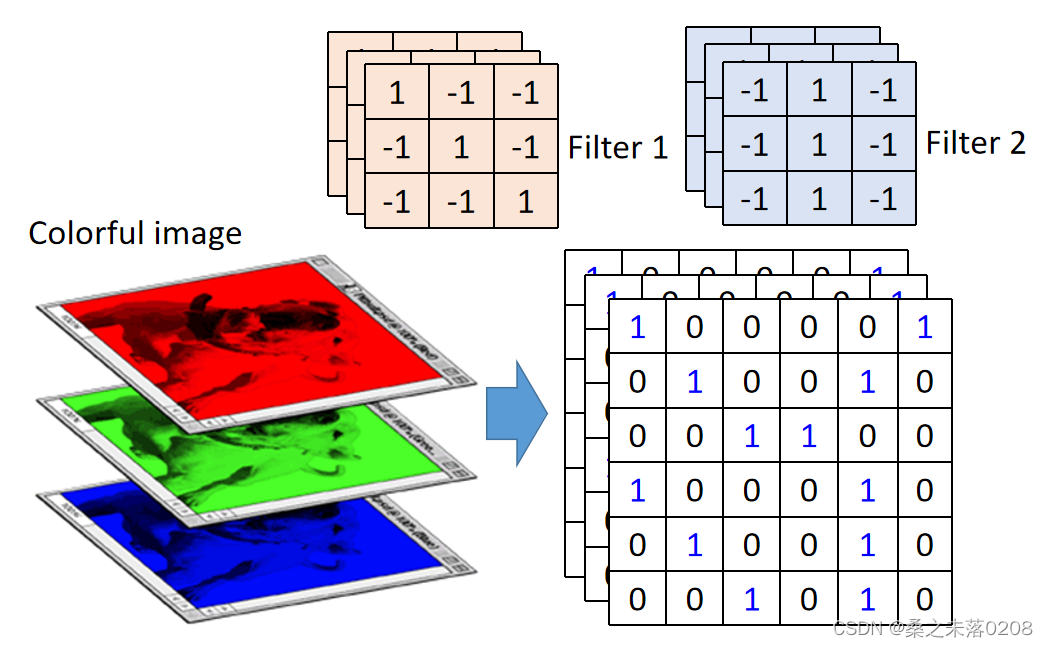
对于有颜色的图案来说,图像也会变成三层6x6的矩阵,filter变成了三层
Convolution v.s. Fully Connected
两者看上去没有什么联系,如下:
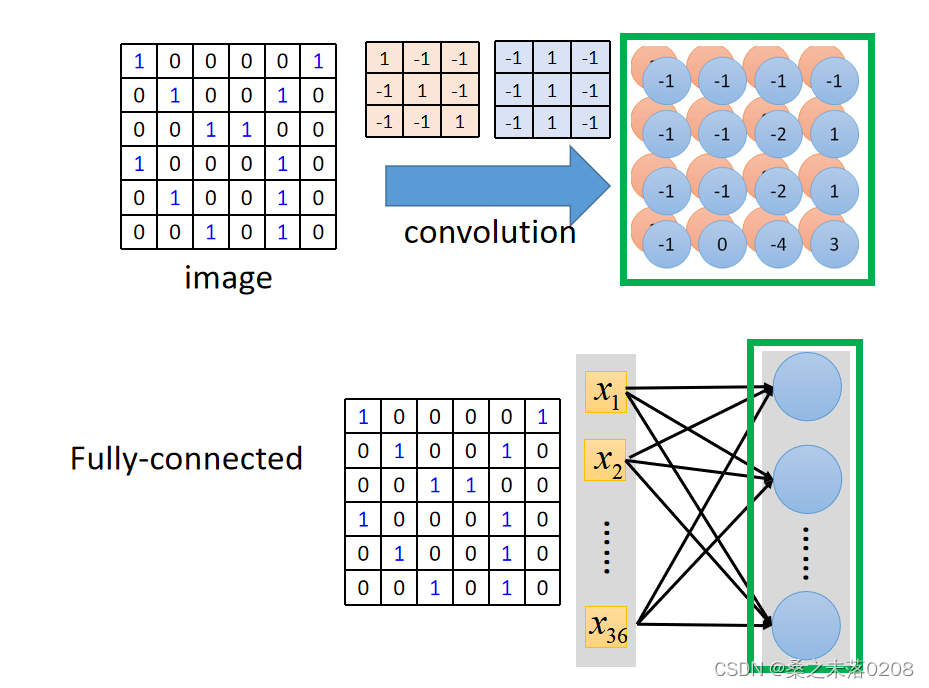
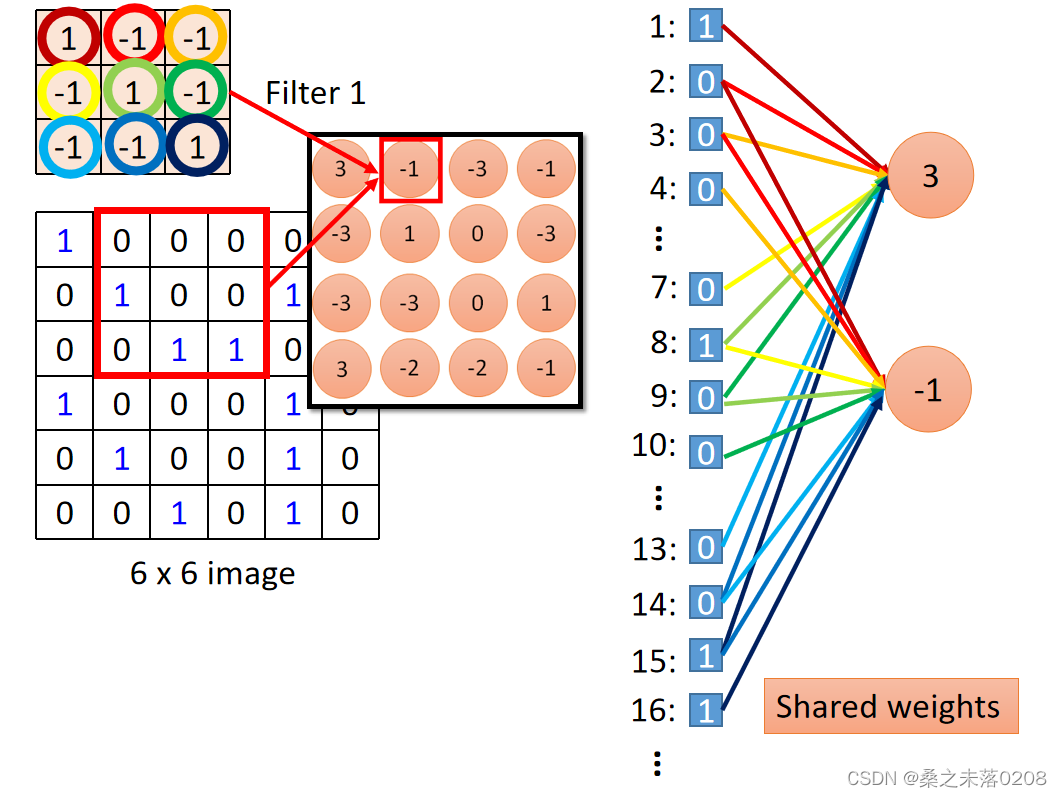
但是将 Convolution中6x6的矩阵变成36个参数摊开,那么filter就可以变成权重,相同颜色表示相同权重,所以权重是共享的。这时,Convolution 就可以变成Fully Connected。
CNN – Max Pooling
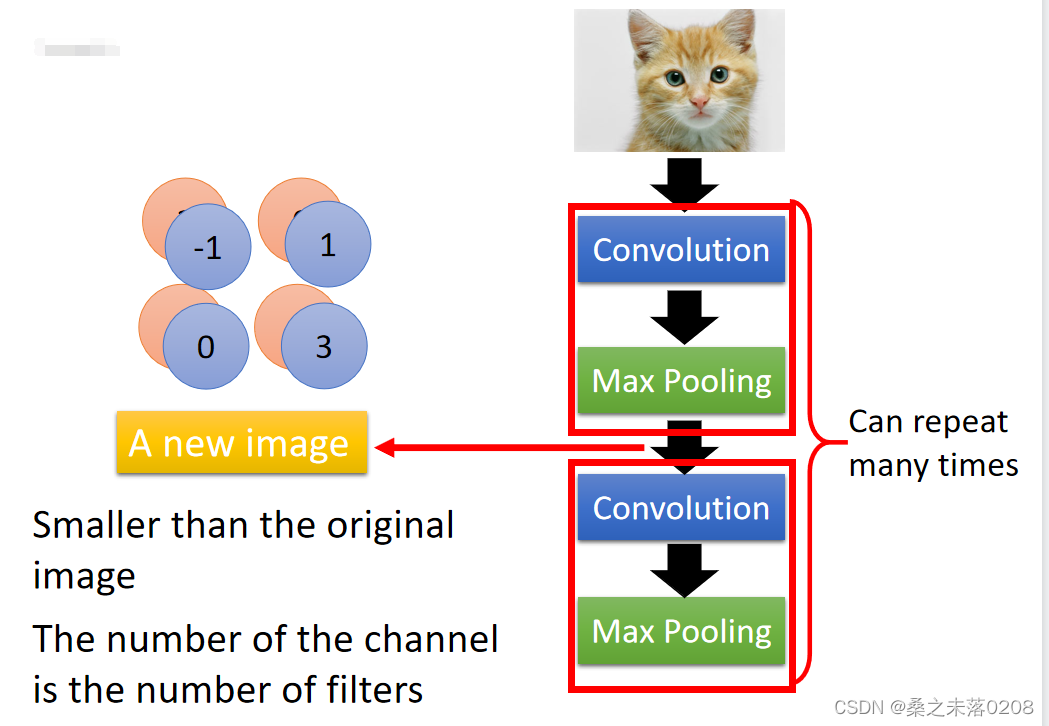
通过每个filter得到4x4的矩阵,将其划分为四块,取每块中的最大值出来,就变成了2x2的矩阵,即产生更小的新图像。

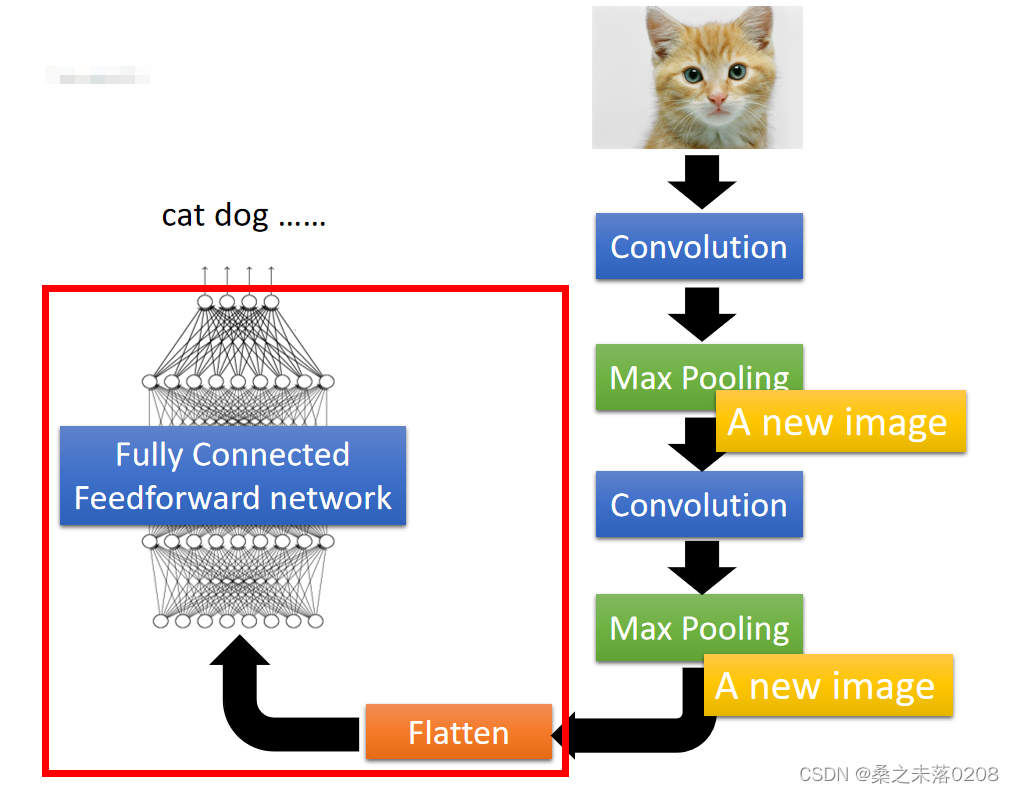
其中flatten的过程如下:
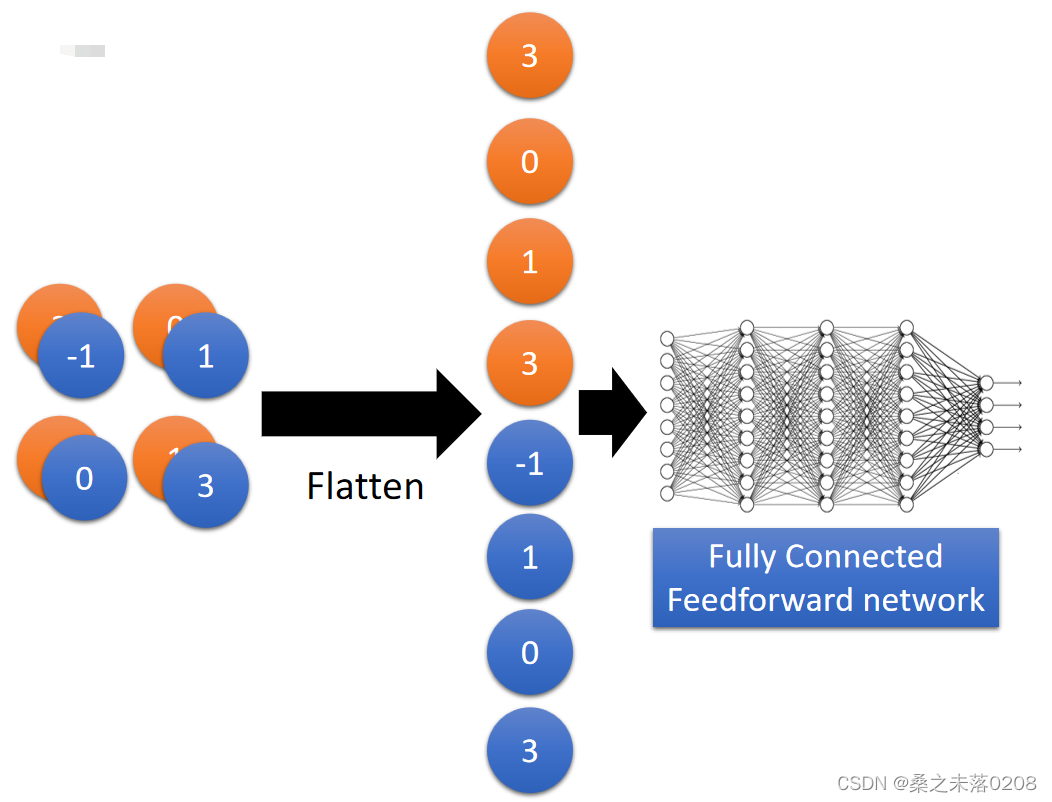
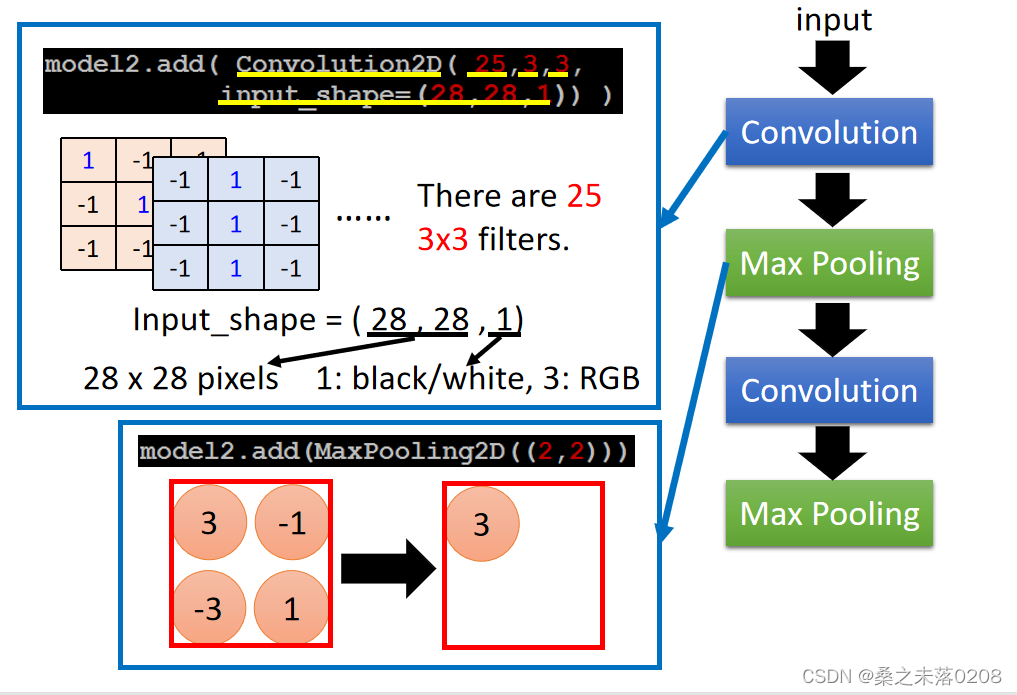
CNN in Keras
input_shape=(28,28,1)
28,28:表示初始的形状是28x28的矩阵。
1:表示黑or白


What does CNN learn?
一个filter做的事情是什么呢?从下图右侧我们可以看到第二个filter的输出是一个11x11的矩阵。拿出第k个filter(11x11的矩阵),矩阵中每个值设置为
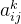 。
。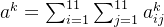 ,其中
,其中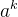 表示第k个filter的激活程度。我们现在需要找一张image使得第k个filter的激活程度最大,使用的方法是梯度上升法。
表示第k个filter的激活程度。我们现在需要找一张image使得第k个filter的激活程度最大,使用的方法是梯度上升法。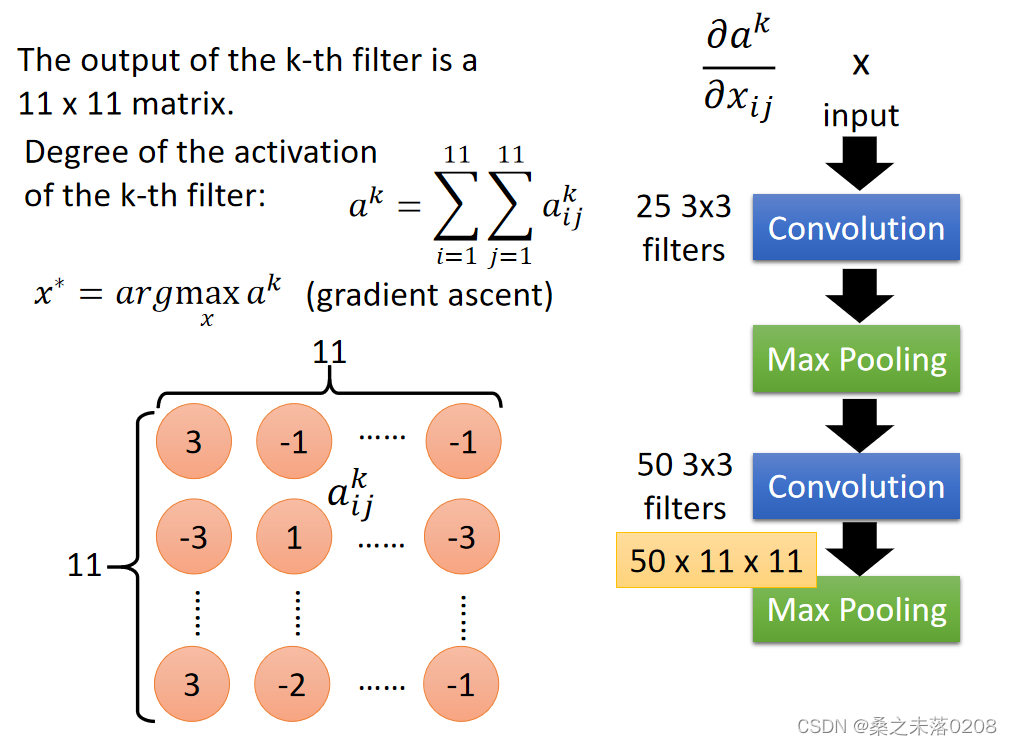
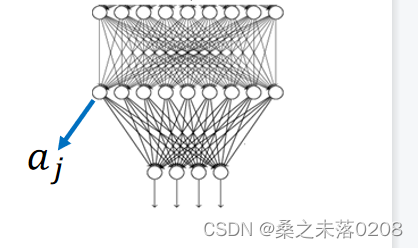
得到的结果如下(前12个filter)。
然后flatten,将图形扩大到一张完整的图形之中
那么,对于输出是怎样的呢?

深度神经网络是很容易被欺骗的,我们可以看到每个数字的image看起来都差不多。

那么,该如何让image更加明显。我们希望存在一个x,不仅使得
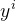 最大,而且使得像素的加和最小(即:每个image处有非常少的地方涂上了笔画)。
最大,而且使得像素的加和最小(即:每个image处有非常少的地方涂上了笔画)。
Deep Dream
给定一张照片,机器将会添加它看到的东西。CNN夸大了它所看到的东西。
依赖于经过数百万张图像训练的神经网络。使用方便,只需要上传一张图片,工具根据原图生成新图片即可。
Deep style
给定一张照片,使其风格像名画(也是给定的),如下图:

图片来源于网络。
CNN的应用
(1)围棋——Alpha Go
(2)演讲
(3)文本
-
相关阅读:
【开发问题系列】CSV转Excel
windows server充当DHCP服务器与华为模拟器对接下发地址
Feign
JVM-4
mysql之搭建MMM架构实现高可用
ABeam Insight | 智能制造系列(4):物联网(IoT)× 智能制造
学习Autodock分子对接
推荐算法之召回模型:DSSM、YoutubeDNN
node.js多版本管理器nvm的安装和使用
关于Modal的封装的记录【Vue3、computed、Naive UI】
- 原文地址:https://blog.csdn.net/qwertyuiop0208/article/details/126636888