-
什么是GPT
什么是GPT
参考资料:
https://zhuanlan.zhihu.com/p/350017443
https://zhuanlan.zhihu.com/p/106462515
https://www.cnblogs.com/yifanrensheng/p/13167796.html
https://blog.csdn.net/weixin_45577864/article/details/119651372
Generative Pre-trained Transformer(GPT)
GPT系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的NLP任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A等,而完成这些任务并不需要有监督学习进行模型微
GPT仅仅需要非常少的数据便可以理解这个任务的需求并达到接近或者超过state-of-the-art的方法。
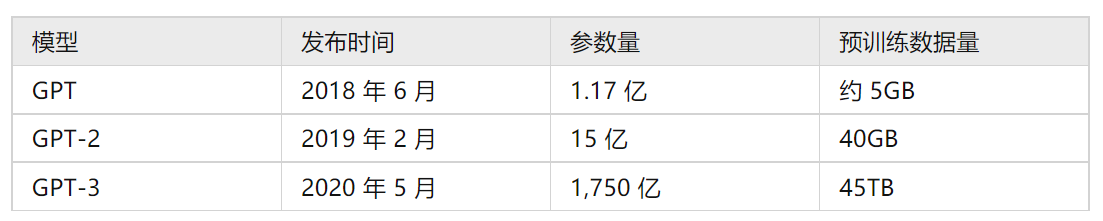
GPT是一种半监督学习方法,它致力于用大量无标注数据让模型学习“常识”,以缓解标注信息不足的问题。
GPT底层也基于Transformer模型,与针对翻译任务的Transformer模型不同的是:它只使用了多个Deocder层。
GPT 采用两阶段过程,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)。
- 特征抽取器不是用的 RNN,而是用的 Transformer,上面提到过它的特征抽取能力要强于 RNN,这个选择很明显是很明智的;
-
相关阅读:
K8s使用RDMA进行高速通信
Linux 中设置静态IP的方法步骤
力扣刷题-数组-螺旋矩阵
一些css记录
5(6)-羧基四甲基罗丹明,CAS号:150347-56-1
PyCharm 配置sqlite3驱动下载问题
SCSI介绍和SCSI命令承载于各类总线的方式
SpringSecurity系列 - 18 SpringSecurity Oauth2 搭建授权服务器和资源服务器
详解升讯威在线客服系统前端多国语言实现技术:原生支持葡文、印尼文、土耳其文、俄文
【服务器学习】hook模块
- 原文地址:https://blog.csdn.net/Hodors/article/details/127625893