-
【Hadoop】shuffle机制中的Partition分区 源码Debug 自定义Partition分区代码实现
1 需求
将统计结果按照条件输出到不同文件中
2 默认的partition分区
在job代码中,不使用
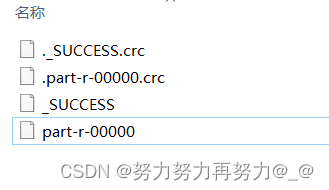
job.setNumReduceTasks(具体的数值)进行设置时,默认进入以下代码,由于没有设置,所以partition的值为1,进入else,getPartition()方法的返回值是0,最后在output目录下生成的文件,只有一个,且序号是000002.1 没有设置NumReduceTask的Debug
在Mapper类的map方法中的context.write()方法上打断点,进入WrappedMapper类的write方法
@Override public void write(KEYOUT key, VALUEOUT value) throws IOException, InterruptedException { mapContext.write(key, value); }- 1
- 2
- 3
- 4
- 5
强制进入write方法,接着会进入TaskInputOutputContextImpl类的write方法
/** * Generate an output key/value pair. */ public void write(KEYOUT key, VALUEOUT value) throws IOException, InterruptedException { output.write(key, value); }- 1
- 2
- 3
- 4
- 5
- 6
强制进入write方法,会进入MapTask的write方法
@Override public void write(K key, V value) throws IOException, InterruptedException { collector.collect(key, value,partitioner.getPartition(key, value, partitions)); }- 1
- 2
- 3
- 4
- 5
强制进入位与collect方法的第三个参数位置的方法
partitioner.getPartition(key, value, partitions)方法,此时partitions=1@SuppressWarnings("unchecked") NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext, JobConf job, TaskUmbilicalProtocol umbilical, TaskReporter reporter ) throws IOException, ClassNotFoundException { collector = createSortingCollector(job, reporter); partitions = jobContext.getNumReduceTasks(); if (partitions > 1) { partitioner = (org.apache.hadoop.mapreduce.Partitioner<K, V>) ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job); } else { partitioner = new org.apache.hadoop.mapreduce.Partitioner<K, V>() { @Override public int getPartition(K key, V value, int numPartitions) { return partitions - 1; } }; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.2 设置NumReduceTask的Debug
若是在代码中使用了
job.setNumReduceTasks(2)进行设置,则会进入如下代码:- 在Mapper类的map方法的context.write()处设置断点
- 进入WrappedMapper的write方法
- 进入TaskInputOutputContextImpl的write方法
- 进入MapTask的write方法
- 进入MapTask的write方法中collector.collect()第三个参数的partitioner.getPartition()这个方法
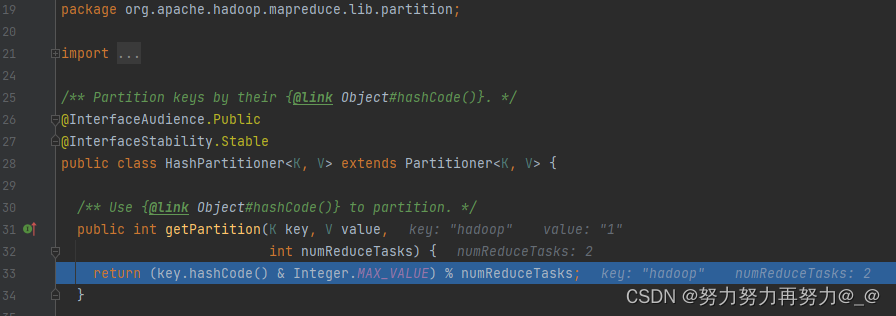
由于在Driver类中设置了ReduceTask的数量,这次进入的getPartition方法与之前没有设置的不一样,这次进入了HashPartition类中的getPartition方法,可以清楚的看到,这里显示numReduceTask的值为2
/** Partition keys by their {@link Object#hashCode()}. */ @InterfaceAudience.Public @InterfaceStability.Stable public class HashPartitioner<K, V> extends Partitioner<K, V> { /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
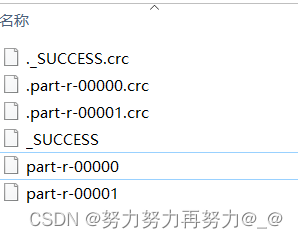
当只设置了2个ReduceTask的时候,如果key的hashCode值是偶数,那么就会在0号分区,如果key的hashCode值是奇数,那么就会在1号分区
具体的hashCode值的计算方法,需要不断进入方法,最后是由WritableComparator类的hashBytes方法返回的
/** Compute hash for binary data. */ public static int hashBytes(byte[] bytes, int offset, int length) { int hash = 1; for (int i = offset; i < offset + length; i++) hash = (31 * hash) + (int)bytes[i]; return hash; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
3 自定义Partition
【Hadoop】序列化、反序列化、序列化案例实操(包括Windows本地运行,hadoop集群运行)这篇博客中,计算了每一个手机号的总上行流量、总下行流量、总流量,最后输出到了一个文件中
现在需要根据手机号前三位数字进行分类,136、137、138、139开头的手机号分别放置在一个单独的文件中,其余数字开头的手机号放置在另一个文件中
3.1 自定义分区类
在序列化案例的基础上,增加了一个分区类PhonePartition,其中重写的getPartition()方法的返回值就是具体的分区号
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class PhonePartition extends Partitioner<Text, FlowBean> { @Override public int getPartition(Text text, FlowBean flowBean, int numPartitions) { //获取手机号前三位 String pre3 = text.toString().substring(0, 3); //作为具体的分区号 int partition; if ("136".equals(pre3)){ partition = 0; }else if ("137".equals(pre3)){ partition = 1; }else if ("138".equals(pre3)){ partition = 2; }else if ("139".equals(pre3)){ partition = 3; }else { partition = 4; } return partition; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
3.2 修改Driver驱动类
添加如下两行设置代码
//指定自定义分区类 job.setPartitionerClass(PhonePartition.class); //指定NumReduceTask job.setNumReduceTasks(5);- 1
- 2
- 3
- 4
- 5
3.3 输入
使用【Hadoop】序列化、反序列化、序列化案例实操(包括Windows本地运行,hadoop集群运行)相同的输入phone_data.txt
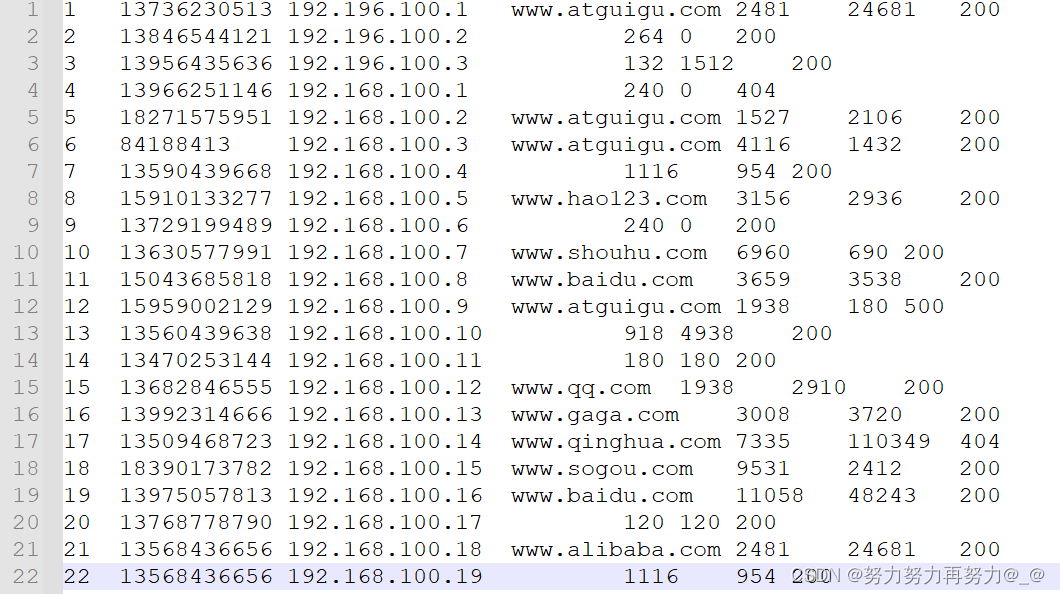
3.4 输出
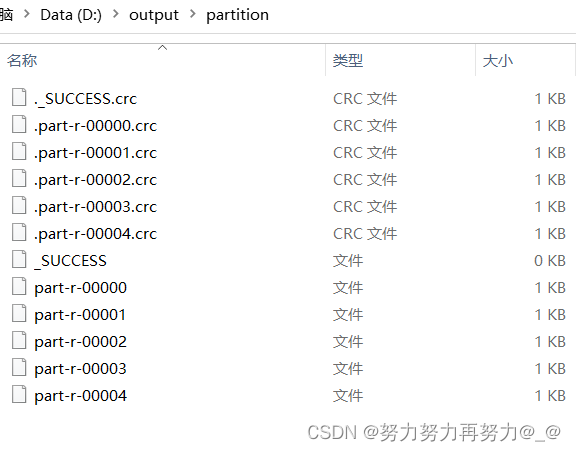



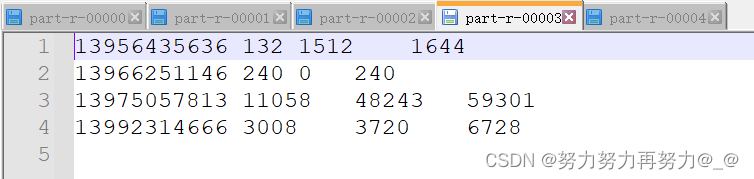
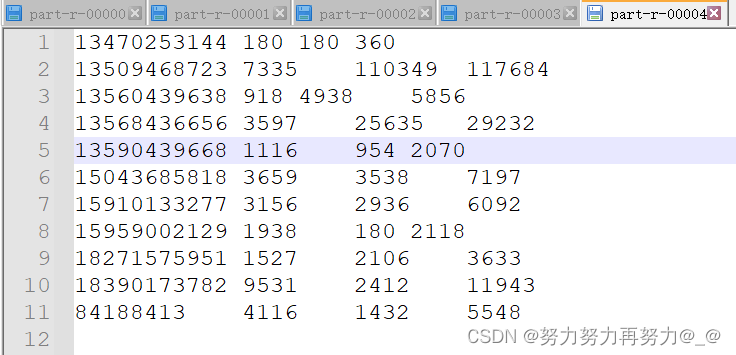
-
相关阅读:
一键批量按比例修改视频尺寸:视频剪辑软件使用技巧
17-数据结构-查找-(顺序、折半、分块)
FFmpeg编解码的那些事(1)
嵌入式分享合集117
坑,实现 WebMvcConfigurationSupport 后 SimpleUrlHandlerMapping不见了
Github 2024-02-20开源项目日报 Top10
第五章 树 24 AcWing 1636. 最低公共祖先
[毕业设计源码下载]精品基于Python实现的学生在线选课系统[包运行成功]
HCNP Routing&Switching之DHCP安全
点云从入门到精通技术详解100篇-基于路侧激光雷达的交通目标感知方法与实现
- 原文地址:https://blog.csdn.net/guliguliguliguli/article/details/126685518