-
STL(C++标准库,体系结构及其内核分析)(STL源码剖析)(每日更新)
文章目录
- 介绍
- Level 0:使用C++标准库
- Level 1:深入认识C++标准库
- Level 2:深入认识C++标准库算法
- Level 3:通用技术
- Level 4:更新完毕,继续向前冲冲冲
介绍
这是自己自学C++侯捷老师的STL源码剖析所记下来的一下个人笔记,方便以后进行学习,查询,为什么要学STL?按侯捷老师的话来说就是:使用一个东西,却不明白它的道理,不高明!
Level 0:使用C++标准库
标准库和STL是同样的东西吗?不是,在标准库当中百分之80左右是STL,STL分为六大部件。
一些新旧标准:- C++标准库没有.h的后缀了,例如
#include - 新式的头文件不带.h,例如
#include,但是原来的带有.h的依然可以使用 - 命名空间,把什么函数,模板之类的可以封装起来,新式的头文件以及组件都被封装到
std当中
0 STL六大部件
- 容器
- 分配器
- 算法
- 迭代器
- 适配器
- 分配器
- 容器:容器要放东西,东西要占用内存,所以容器他非常好的是可以帮我们把内存的问题给解决掉,你看不到内存这个东西,只需要不断从容器当中放入/取出东西就好了,所以容器的背后需要另外一个部件去支持它,这个部件就是分配器,数据在容器里面。
- 分配器:是用来支持容器的。
- 算法:有一些函数/操作是由容器做的,但是更多的是包含在算法当中,操作数据的操作在算法里面。
- 迭代器:如何用算法去操作数据呢?使用迭代器,也就是泛化指针。
- 仿函数:作用像是一种函数。
- 适配器:把容器/算法/迭代器做一些转换。
关系如下:
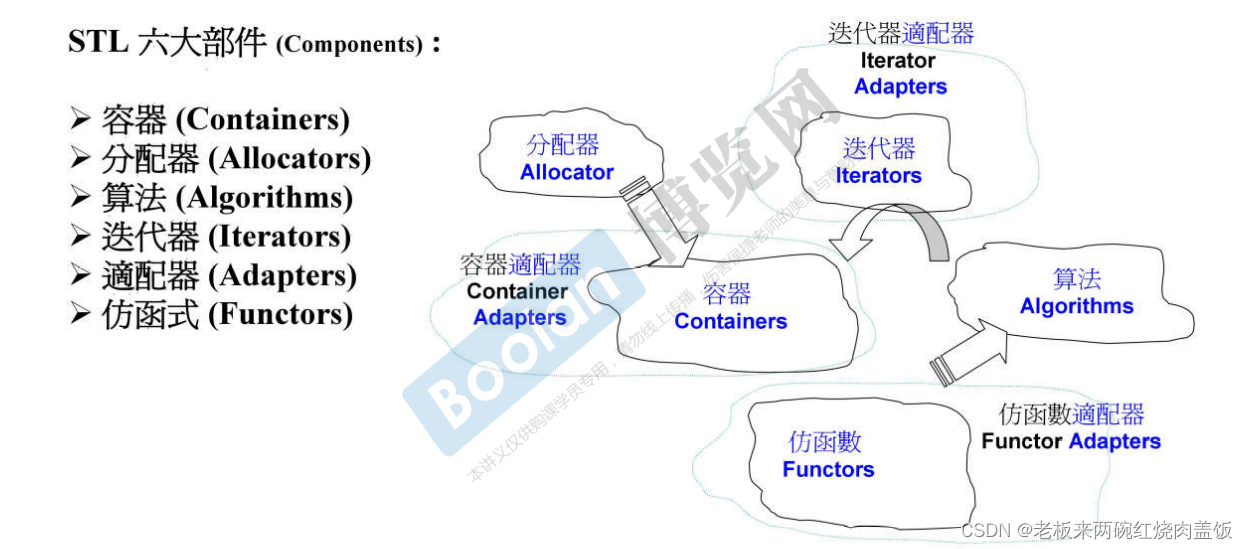
0.1 六大部件之间的关系
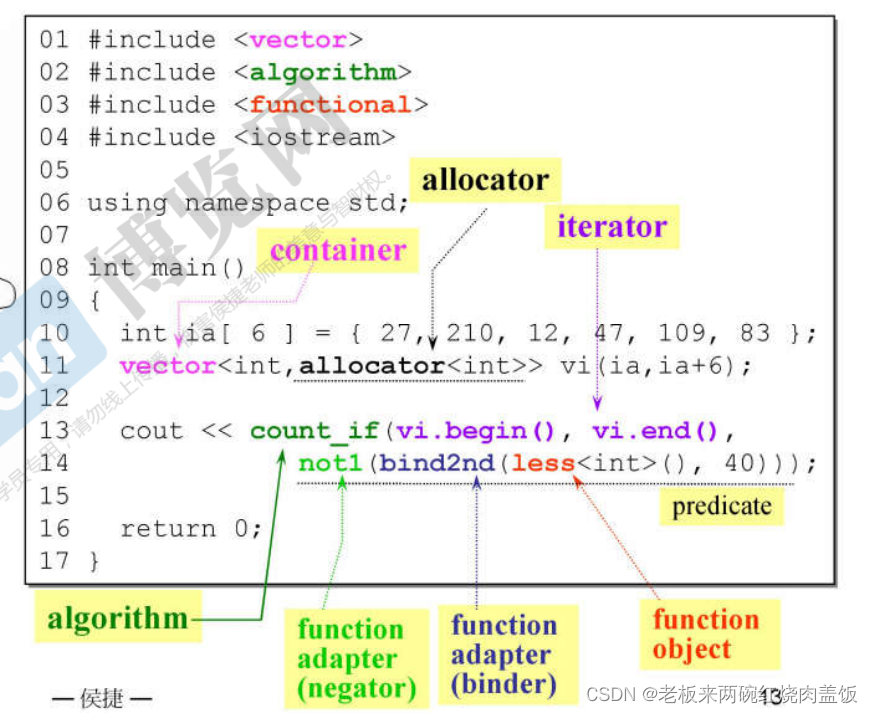
原来
vector,第二个参数是allocator。以上为六大部件之间具体的联系与配合。在上方的程序当中,less这是标准库当中的一个仿函数,然后他的作用是进行比较,比如说() a < b,然后现在利用了count_if这个算法,其作用是找到我们指定目标的数值,现在假如需要找到小于40的值,但是仿函数少了第二参数,所以就可以利用之前适配器的功能,适配器就是把容器/算法/迭代器做出一些转换,使用bind2nd这个转换,即可有了第二参数40;之后又进行函数的转换,加了一个not1,以前要找小于等于40,现在要大于40。0.2 复杂度

0.3 容器是前闭后开(左闭右开)区间
把元素放到容器当中,容器当然是有头有尾的,所有容器都提供begin(),end()迭代器,头没有疑虑,尾巴呢?所谓容器的前闭后开区间,标准库规定,begin()要表示开始的启动,end()表示最后一个元素的下一个元素。
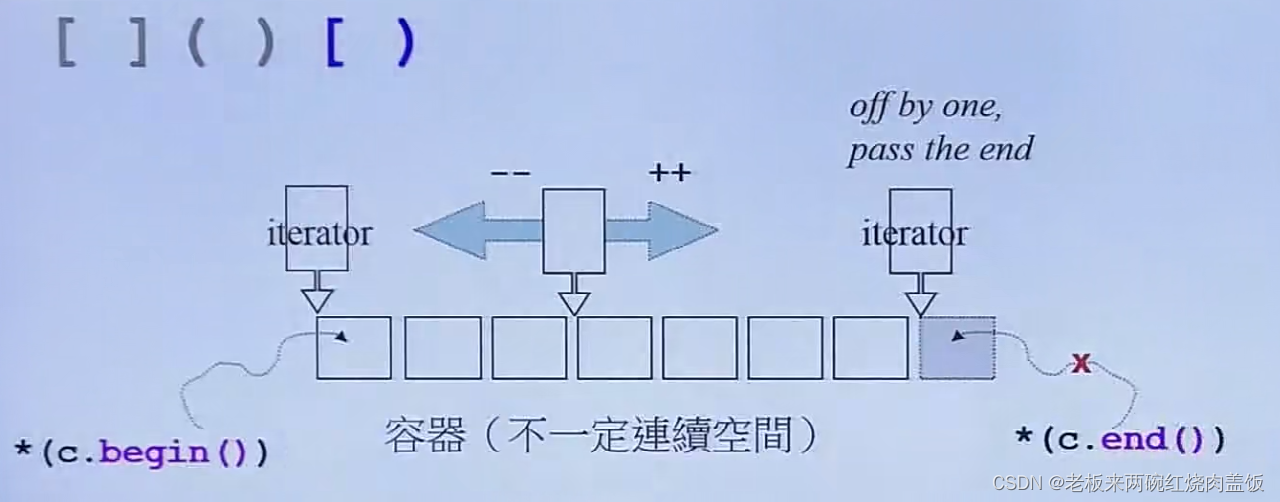
容器的遍历(C++11之前的写法):
Container<T> c; ... Container<T>::iterator ite = c.begin(); for (; ite != c.end(); ++ite) ...- 1
- 2
- 3
- 4
- 5
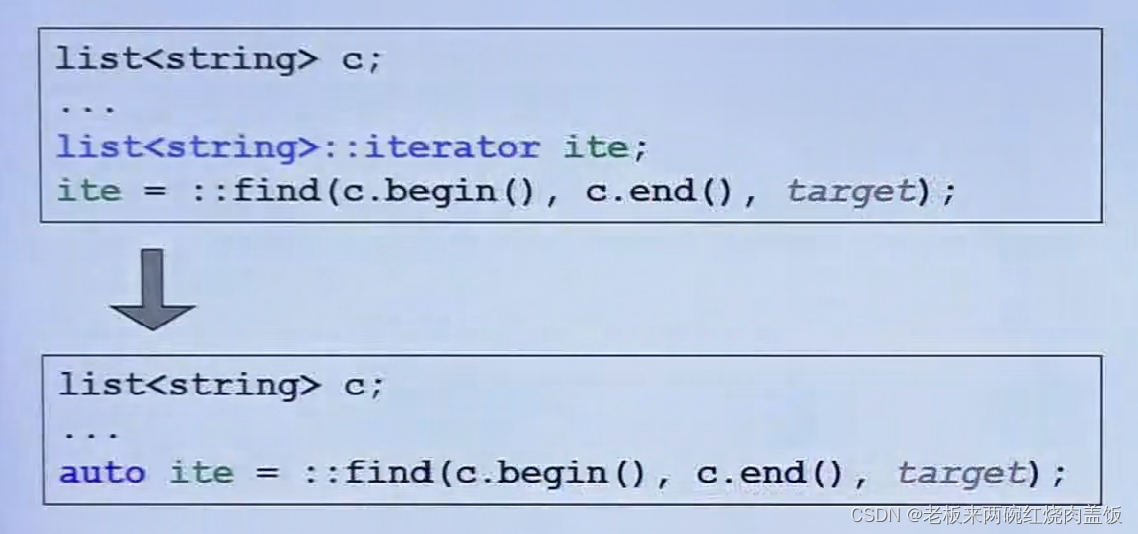
最新的写法(最推荐C++11)
for (auto decl : coll) { statement; }- 1
- 2
- 3
- 4
decl是一个声明,coll是一个容器,相比以前的写法,方便太多了。
不是非必要的时候不用auto,因为知道一个元素的类型还是很重要的。
1 容器的结构与分类
大致上分为两种,序列式容器以及关联式容器(key找value,适用于查找,hashmap)。
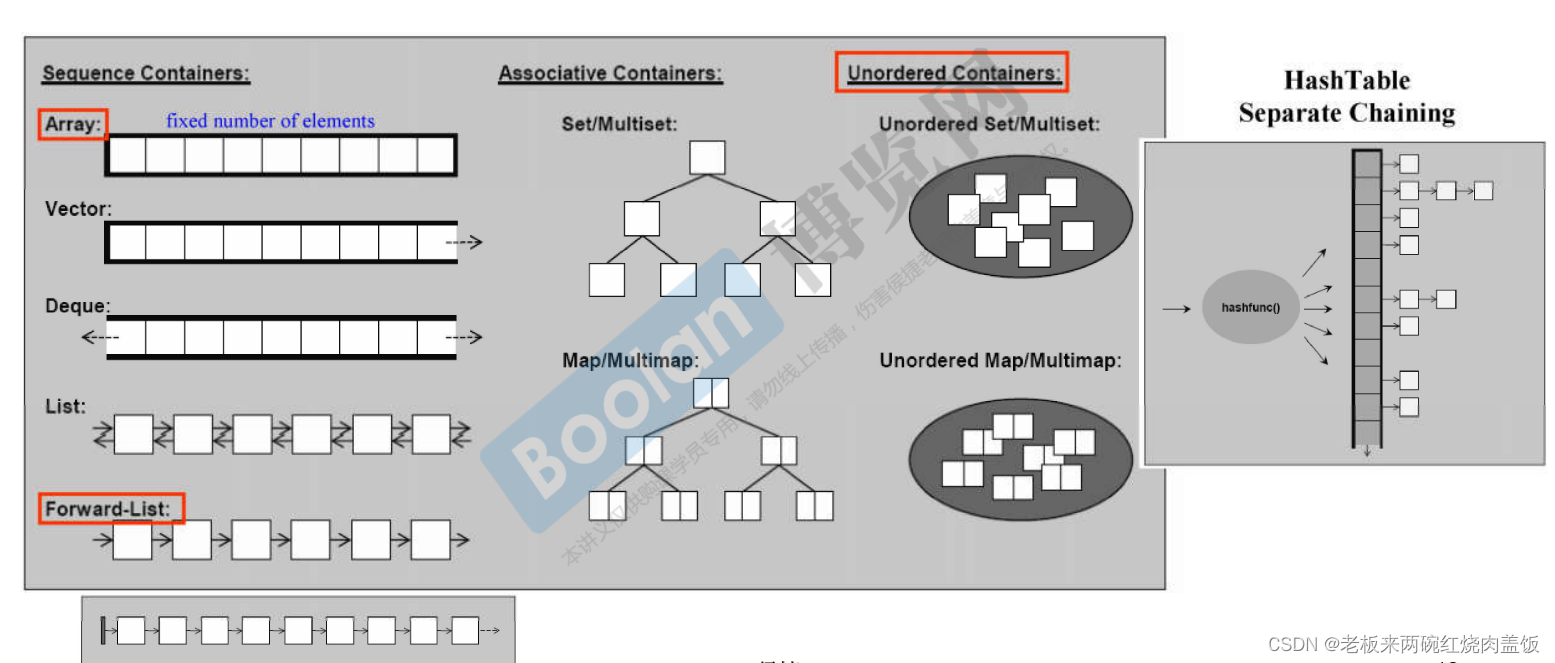
一图看懂各个容器的结构,最后一个单链表是C++11新增的一个容器。
在标准库当中,并没有规定set和map用什么来实现,但是用红黑树(因为左右两边会自己平衡)非常好,所以各家IDE都用红黑树来做set和map。
map,每一个节点,都有key和value,set却没有明确划分。
还有就是,如果选择普通的set和map,里面的元素的key是不能重复的,但是使用multiset以及multimap的时候,里面的key是可以重复的。
哈希表很好,但是某一条链表不能太长,太长就不会太好,因为单链表是要不断进行遍历的,这样时间复杂度就会很高。
测试程序-辅助函数
long get_a_target_long() { long target=0; cout << "target (0~" << RAND_MAX << "): "; cin >> target; return target; } string get_a_target_string() { long target=0; char buf[10]; cout << "target (0~" << RAND_MAX << "): "; cin >> target; snprintf(buf, 10, "%d", target); return string(buf); } int compareLongs(const void* a, const void* b) { return ( *(long*)a - *(long*)b ); } int compareStrings(const void* a, const void* b) { if ( *(string*)a > *(string*)b ) return 1; else if ( *(string*)a < *(string*)b ) return -1; else return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
1.1 使用容器Array
#include#include #include #include //qsort, bsearch, NULL namespace jj01 { void test_array() { cout << "\ntest_array().......... \n"; array<long,ASIZE> c; clock_t timeStart = clock(); for(long i=0; i< ASIZE; ++i) { c[i] = rand(); } cout << "milli-seconds : " << (clock()-timeStart) << endl; // cout << "array.size()= " << c.size() << endl; cout << "array.front()= " << c.front() << endl; cout << "array.back()= " << c.back() << endl; cout << "array.data()= " << c.data() << endl; long target = get_a_target_long(); timeStart = clock(); ::qsort(c.data(), ASIZE, sizeof(long), compareLongs); long* pItem = (long*)::bsearch(&target, (c.data()), ASIZE, sizeof(long), compareLongs); cout << "qsort()+bsearch(), milli-seconds : " << (clock()-timeStart) << endl; // if (pItem != NULL) cout << "found, " << *pItem << endl; else cout << "not found! " << endl; } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
以上函数,ASIZE = 50万,然后加入随机数,再进行排序。
可有把一些组件写在namespace当中,这上面是写了namespace jj01,这样是为了与其他的namespace进行分开。1.2 使用容器vector
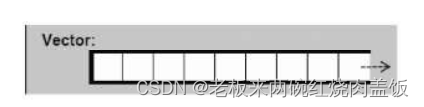
使用vector的时候,要想清楚他的结构,因为是只有一个尾端,所以只有
push_back()操作,没有push_front()操作。vector是两倍增长,放一个增长一个,两倍两倍的增长,而且vector的内存是从别的地方搬过来的,需要注意的是size()是真正存有多少个元素,capacity()是他的真实容量大小。1.3 使用容器list
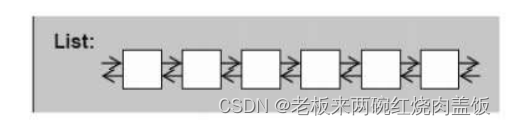
记住list是双向链表,需要注意的是,除了标准库当中有
sort(),在list当中,也有sort()操作,例如l.sort()操作,那怎么选择呢?当某些容器提供了自己的sort()操作肯定是用自己的会比较快一点,list和forwa_list都有自己的sort。1.4 使用容器foward_list

因为是单向链表,所以只有
push_front()。1.5 使用容器slist
同单向链表,其头文件包含在
ext当中。1.6 使用容器deque

deque,双向开口,可进可出的容器,还有需要注意的是,deque是分段连续的,说连续的只是一个假象,其实是分段连续的。
因为两端都可以,所以既可以
push_back(),又可以push_front()。1.7 使用容器stack/queue
一个deque,其实是涵盖了stack/queue的功能的,因为deque是双向进出,而stack则是单向进出的容器。因为stack/queue都是利用deque来完成的,所以其实又不把这两个容器称为容器,而是称为容器的适配器adapter。
1.8 使用容器multiset/map
前面的都是顺序型容器,现在这个是关联型容器。
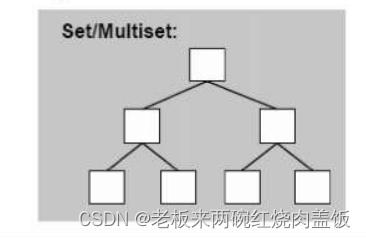
这是由于一个红黑树高度平衡树构成的,查找的话要很快。
1.9 使用容器multimap/map
每一个都是由一个key和一个value组成的。
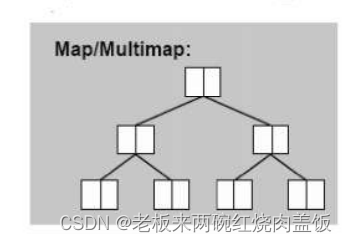
key可能重复,value可能相同。因为是multi,所以不带multi的,key就不会重复。
1.10 使用容器unordered_set
此容器的的基础支撑是以hashtable为结构的。
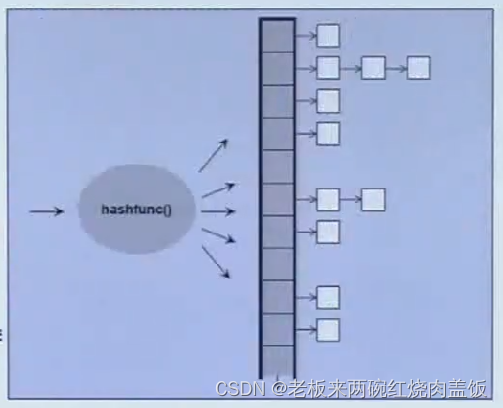
放东西进去要用
insert()命令,这个方框就是篮子,后面衍生出来的链表就是元素,可以说,篮子一定比元素多。如果元素的个数大于等于篮子,那么篮子就会扩充,至少两倍大于元素的个数,加入现在10个元素,5个篮子,当第10个元素挂在第5个篮子上的时候,内部就会开始检查,检查是篮子数小于元素的个数,然后进行扩增,直到篮子数大于元素的个数,然后再把元素重新打散,这就是散列表的由来。而且篮子拖着的元素不能太长,因为单向链表,要依次遍历过去查找。很长的话,时间效率就会很低。1.11 使用容器unordered_map
与上边差不多,就是hashmap。
2 使用分配器allocator
容器的背后需要一个东西来迟滞他对内存的使用,这个东西就是分配器allocator。在理想的情况下,我们最好是不知道这个东西,一定会存在这个东西,但是我们最好是不知道,但是首先第一个条件是不用写出来,容器就有一个默认的分配器,确实在使用接口是这样;第二个条件是这个默认的分配器要够好,当然可以自己写一个分配器。

可以看出,每一个容器的分配器的声明,都是模板,模板一定有第二参数,如红色的,默认的使用
std::allocator。2.1 有哪些分配器?

以上。
使用上方的分配器,在list当中进行演示。
list<string, allocator<string>> c1; //3140 list<string, __gnu_cxx::malloc_allocator<string>> c2; //3110 list<string, __gnu_cxx::new_allocator<string>> c3; //3156 list<string, __gnu_cxx::__pool_alloc<string>> c4; //4922 list<string, __gnu_cxx::__mt_alloc<string>> c5; //3297 list<string, __gnu_cxx::bitmap_allocator<string>> c6; //4781- 1
- 2
- 3
- 4
- 5
- 6
switch (choice) { case 1 : c1.push_back(string(buf)); break; case 2 : c2.push_back(string(buf)); break; case 3 : c3.push_back(string(buf)); break; case 4 : c4.push_back(string(buf)); break; case 5 : c5.push_back(string(buf)); break; case 6 : c6.push_back(string(buf)); break; default: break; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
因为
push_back()每次都会用到内存,所以分配内存就会用到分配器。可以直接使用allocator吗?当然可以,但没必要,因为分配器是支持容器的,我们没必要直接调用分配器去拿内存。
int* p; allocator<int> alloc1; p = alloc1.allocate(1); alloc1.deallocate(p,1); __gnu_cxx::malloc_allocator<int> alloc2; p = alloc2.allocate(1); alloc2.deallocate(p,1);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
以上就是直接使用allocator,就是直接使用分配器,你的负担很重,你要去知道自己使用了多少个内存,这样还回去也就是还多少个内存。
Level 1:深入认识C++标准库
0 OOP(面向对象)和GP(泛型)
面向对象OOP的概念,要有类,封装继承多态,以及虚函数之类的概念。

例如这个,标准库当中链表的设计,list这个类里面当然是要放数据本身的,面向对象就是,数据在类里,操作数据的函数也在类里面,以上就是list类的实现,体现了OOP的概念,即数据(Datas)和方法(Methods)结合。
但是泛型(GP)就不一样了,泛型是数据(Datas)和方法(Methods)分开来,比如:

在这个类里面,都没有
sort()的操作,排序的操作被单独的设置在另外一块区域,可以想象成是sort()的内容是一块全局的区域,而OOP当中的sort()则是局部的区域。

那GP实施这样的操作后,分开来,操作的部分要怎么样才能得到数据的本身呢?答案是迭代器,这两种操作要借助迭代器进行使用。
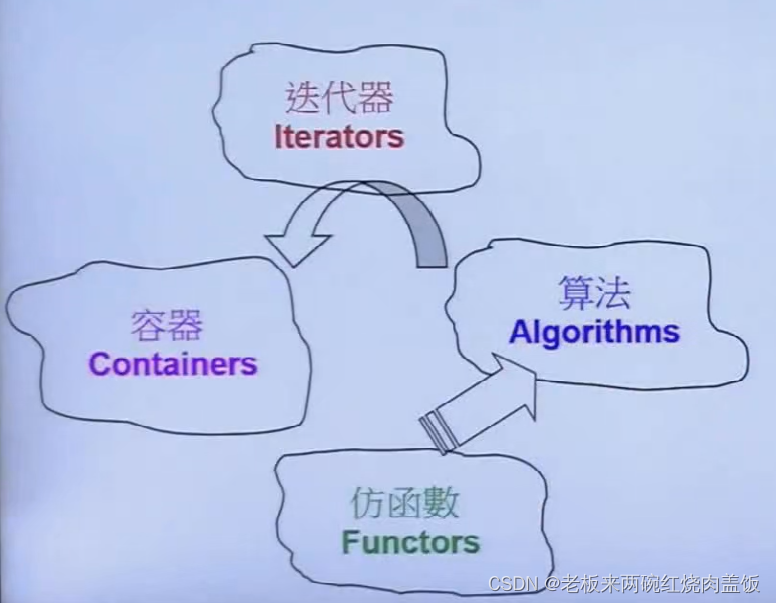
使用迭代器,
begin()/end()给到算法,就可以进行操作。这样有什么好处呢?这样可以分开进行开发,容器算法团队分开开发内容。
为什么刚刚的list中的
sort()操作在类里面呢?因为链表并不是一段连续的空间,其是由指针一个个连接起来的,所以这并不是连续的,但是看全局的sort()排序当中,其迭代器都是连续的量,但是list迭代器不是连续的量,所以这就是为什么list当中要有自己的sort()操作了,而不能用全局的sort()进行排序,这就是为什么有自带的排序尽量用自带的原因。0.1 重载与模板
- 有一些操作符是不能被重载的,比如说
::、.、.*、?:这四个不能被重载,具体的如下:

- 模板,类模板,函数模板,成员模板,可以先把要用的一些数据类型保留。
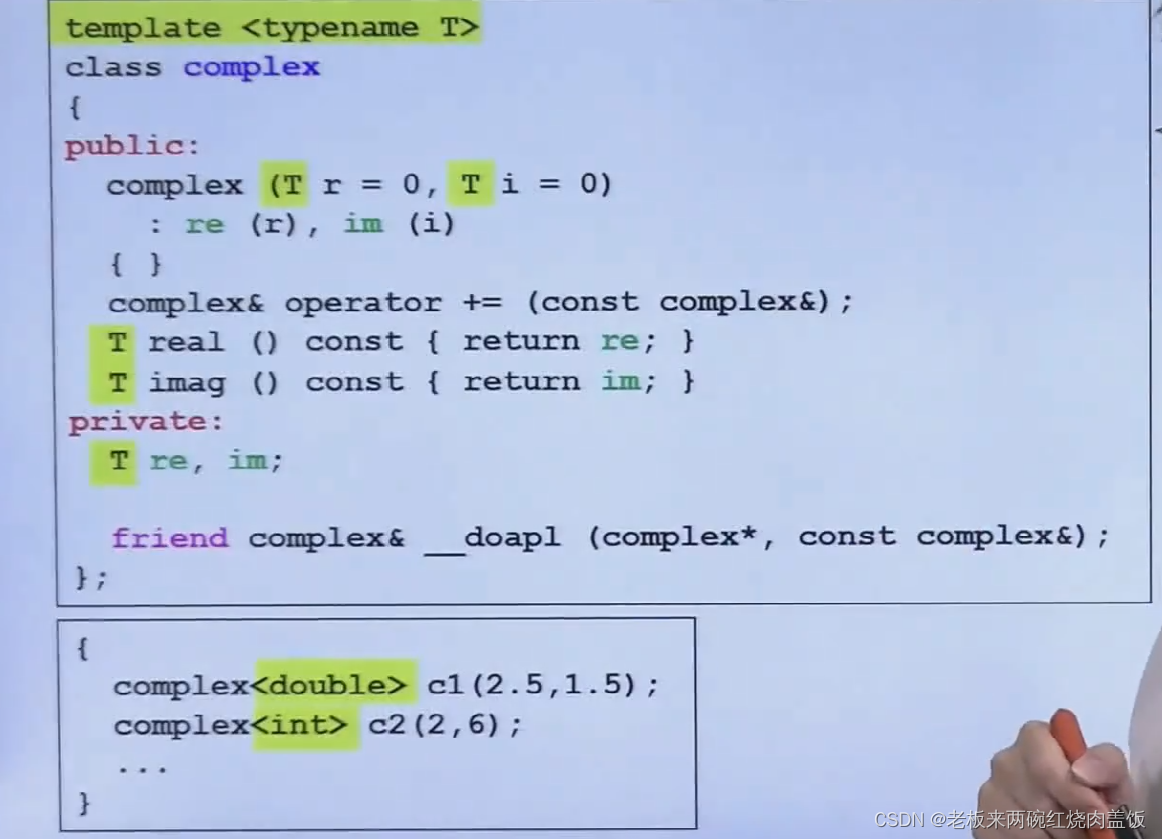
这样编译器会自动推断出未知类型的类型是什么。
0.2 泛化与特化
特化当中,template后的<>是空的。
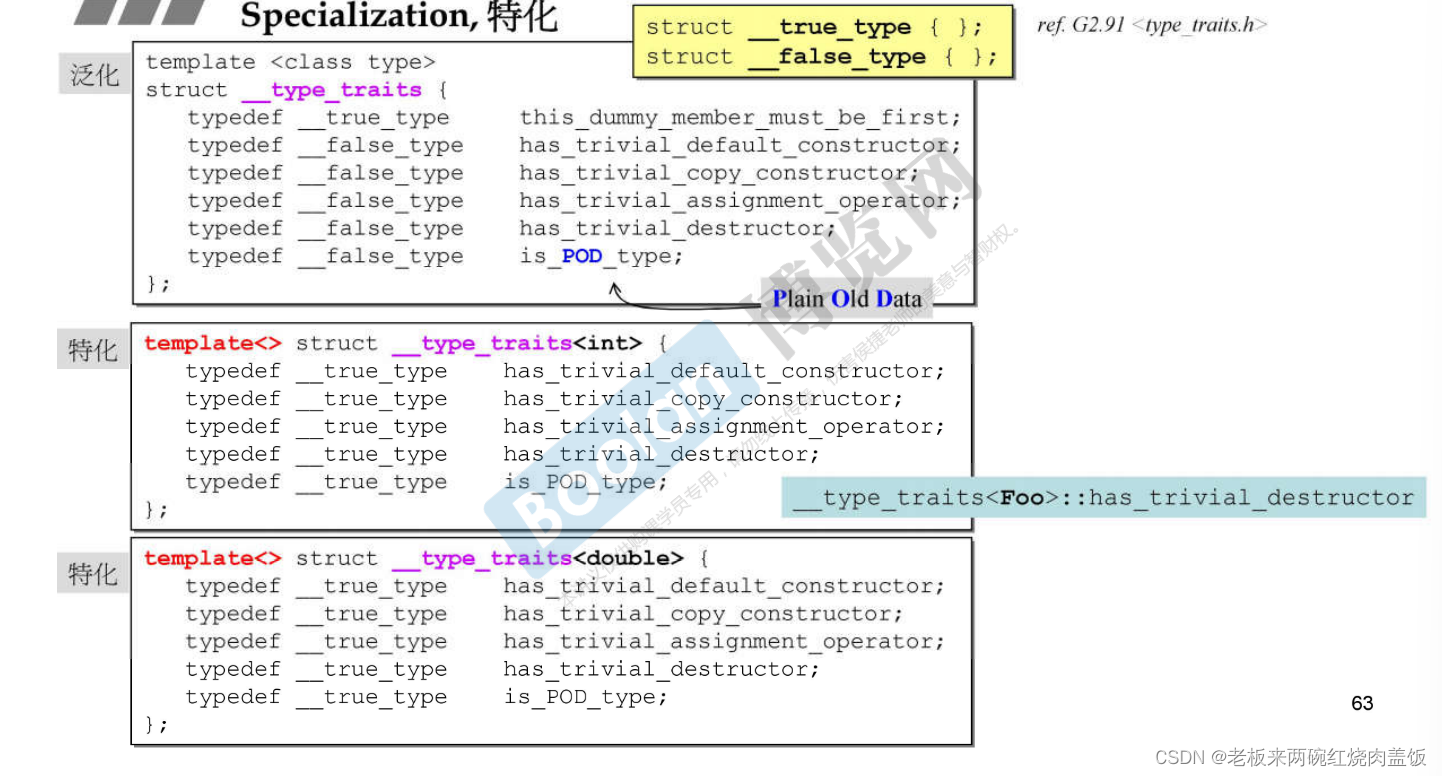

局部特化。
这个局部特化接受两个模板参数(其实上方特化的也可以有多个模板参数),现在呢,这个局部特化参数,两个参数只绑定了一个参数,所以叫做局部(偏)特化。
1 分配器allocator源码剖析
分配器给容器用的,所以分配器的效率好不好关系到容器的效率好不好。
1.1 operator new() 和 malloc()
因为分配器要取出内存,所以在经历过一系列操作的时候,在标准层面上,一系列都会回归到
malloc()上。

可以看出,new()的源代码是使用了malloc()的。
那么,所有的操作都会转化为
malloc(),其分配的内存长什么样子呢?如下: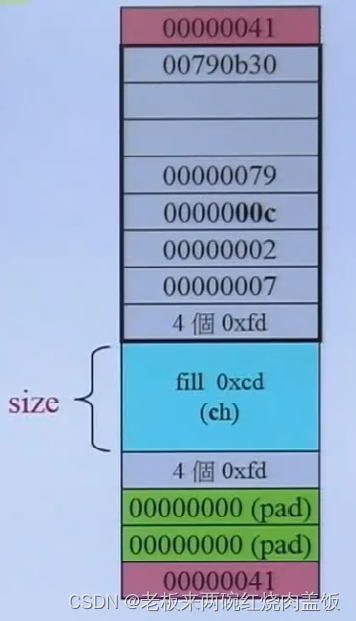
1.2 STL对allocator的使用

可以看出,容器的默认分配器都是使用allocator。
在allocator的源代码当中,分配内存是使用
new()进行操作的。

回收内存的时候,使用
delete()去完成的。
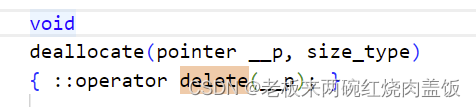
G++的allocator只是以:
operator new和:operator delete完成allocate()和deallocate(),没有任何特殊设计。具体用法:
/分配512ints. int*p = allocator<int>().allocate(512); allocator<int>().deallocate(p, 512);- 1
- 2
- 3
allocator这个原来就是个类模板,现在特化后就变成类名称了,再加上个空的括号,就是一个临时对象,没有名称,也就是临时对象的实例化,有了对象才能调用成员函数。()
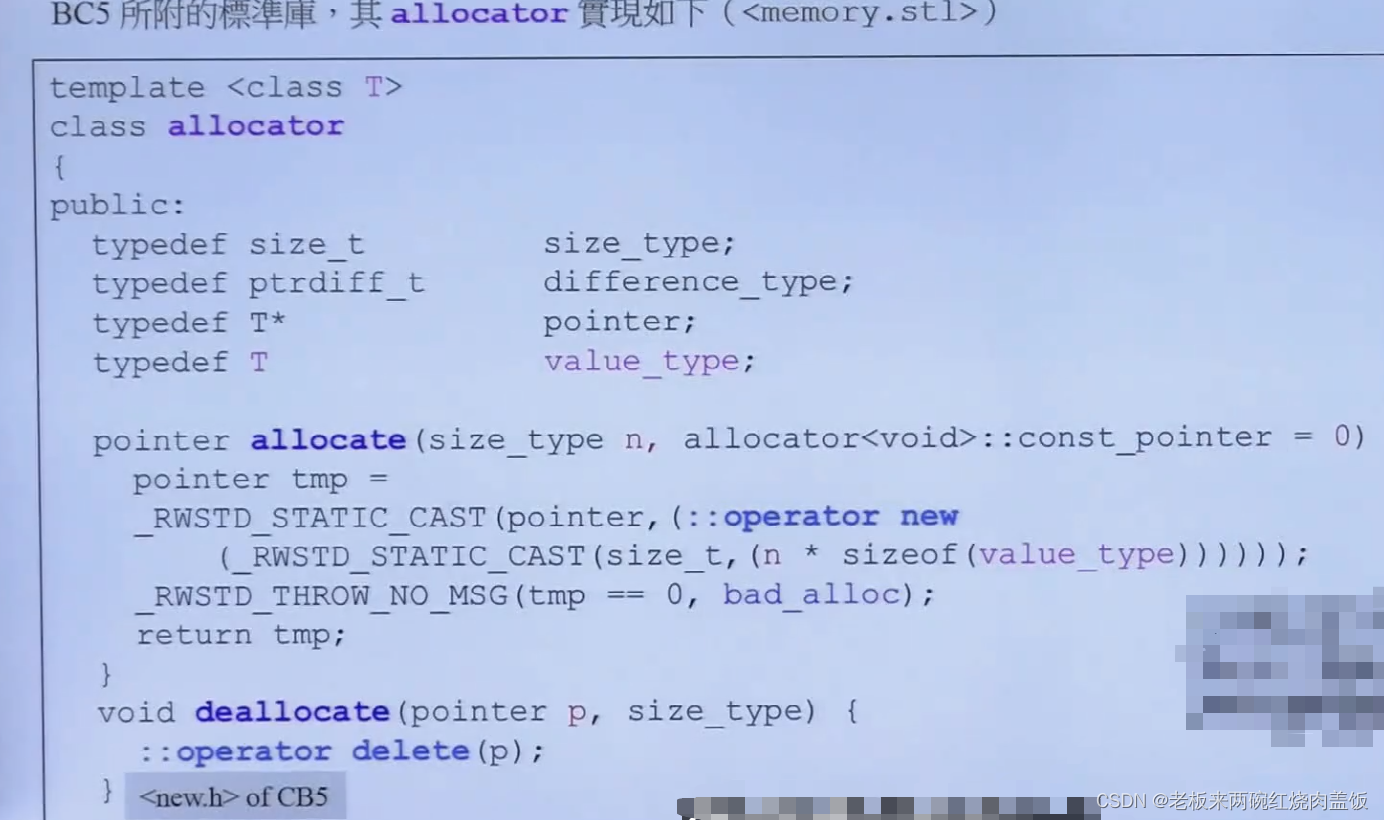

因为太烂了,GNU自己都不在容器中使用。
#ifndef __SGI_STL_ALLOC_H #define __SGI_STL_ALLOC_H #ifndef __STL_CONFIG_H #include#endif #ifndef __SGI_STL_INTERNAL_ALLOC_H #include #endif #ifdef __STL_USE_NAMESPACES using __STD::__malloc_alloc_template; using __STD::malloc_alloc; using __STD::simple_alloc; using __STD::debug_alloc; using __STD::__default_alloc_template; using __STD::alloc; using __STD::single_client_alloc; #ifdef __STL_STATIC_TEMPLATE_MEMBER_BUG using __STD::__malloc_alloc_oom_handler; #endif /* __STL_STATIC_TEMPLATE_MEMBER_BUG */ #endif /* __STL_USE_NAMESPACES */ #endif /* __SGI_STL_ALLOC_H */ // Local Variables: // mode:C++ // End: - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
GNU使用的是这个更高效的allocator。
所有的allocator最后的一步就使
malloc(),所以说,我们要减少次数,防止额外开销(cookie)越来越多,这样才更高效,在容器的状况下,可以不需要cookie。那么,为了减少
malloc()的使用次数,GNU是怎么做的呢?
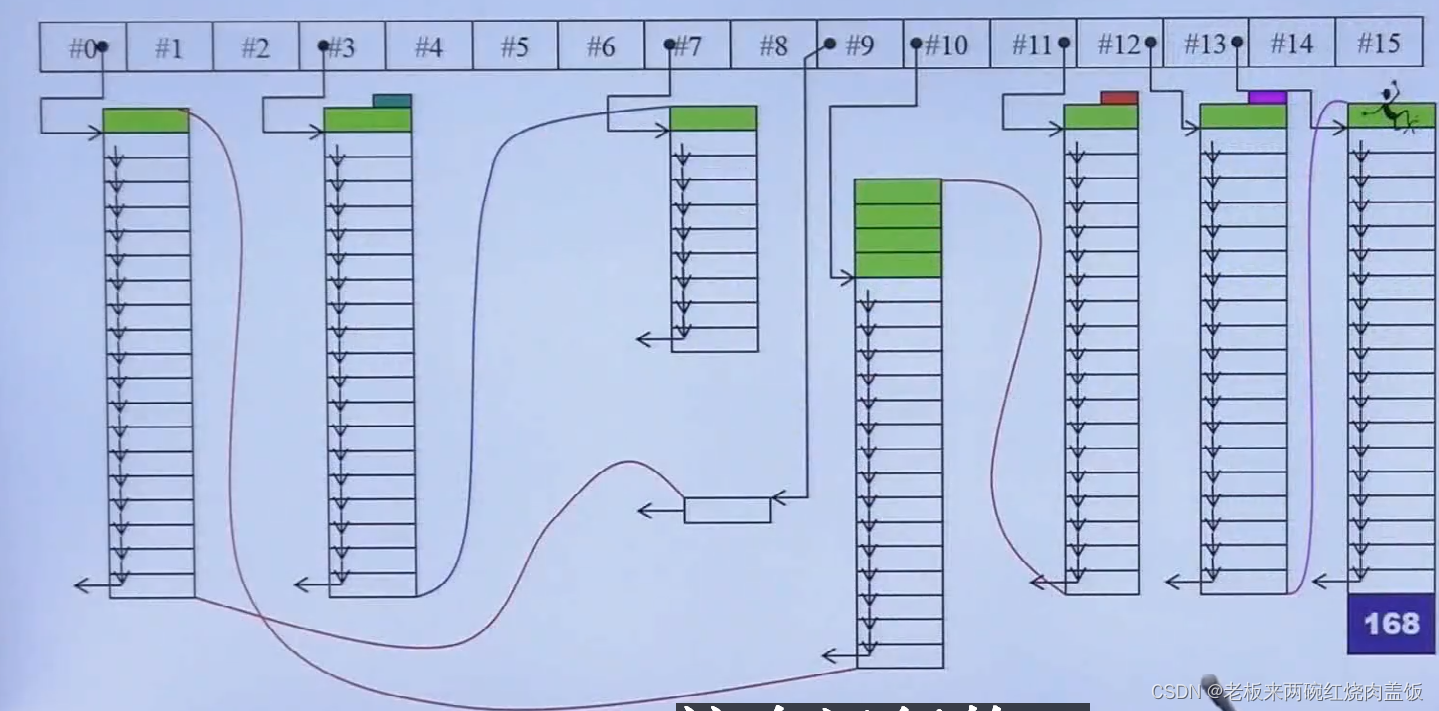
刚刚说了,在容器的状况下,可以不需要cookie,现在GNU就从这里着手,他也不要cookie,还要尽量减少
malloc()的次数。GNU设置了16条链表,每一条链表负责的某一种特定大小的区块用链表串起来。
那么这么多链表的责任分属是怎么样的?
第0条链表负责的是8个字节这种大小,第7号链表负责的是 8 ∗ 8 = 64 8*8 = 64 8∗8=64字节这种大小,以此类推,第15条就是负责 16 ∗ 8 = 128 16*8 = 128 16∗8=128字节大小。一条链表负责8bytes,所有容器,当需要内存的时候,都来和这个分配器要内存,容器的元素大小,会被调整到8的倍数。比如说50,就会被调整到56。调整到56后,分配器就会去看管理这个的链表下有没有挂内存呢?如果没有,才去跟
malloc()要一大块,去切割,切出来的东西用单向链表串起来,所以切出来的每一块就不带cookie。(带cookie,上下会浪费8个bytes,那么存放100万元素,可以省下800万个bytes)这个分配器非常好,但是到了最新的GNU当中的分配器后,又变回了std的默认分配器。2 深度探索list
list是最具代表性的,在list的源代码当中,整个data就只有一个,如下所示:
typedef __list_node<T>* link_type; typedef size_t size_type; typedef ptrdiff_t difference_type; link_type node;- 1
- 2
- 3
- 4
- 5
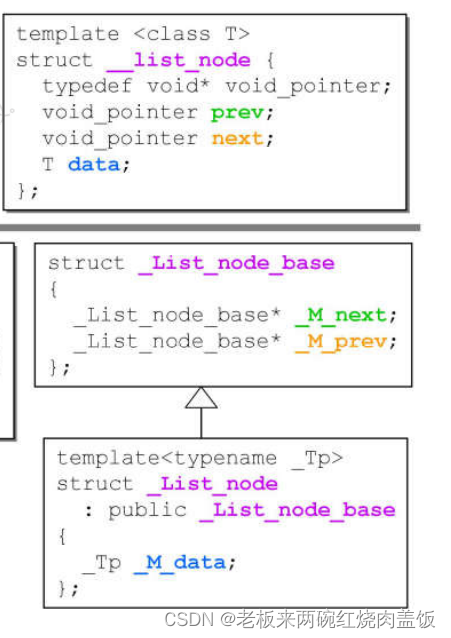
node这个部分是有data的,这个源代码当中,有很多自己定义的那种类型,所以要一层一层的往上扒,这个node是link_type,发现是一个指针,指向list_node,这个node到底多大呢?一个指针4个字节,32位。
本身是一个指针,那么_list_node的定义是什么呢?
struct __list_node { typedef void* void_pointer; void_pointer next; void_pointer prev; T data; };- 1
- 2
- 3
- 4
- 5
- 6
因为是list,所以要有向前以及向后指的两个指针,注意这个指针是void类型的。
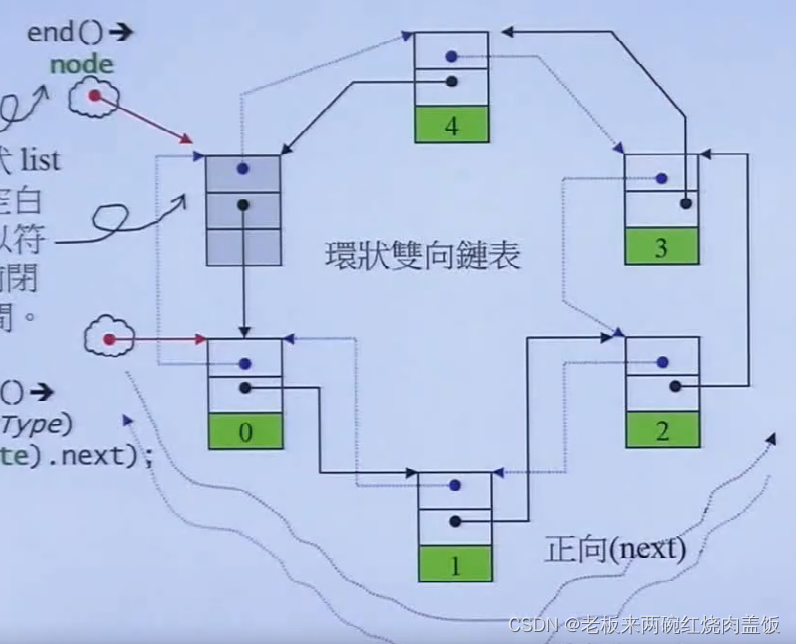
起点和终点就是用iterator指出来的,链表是非连续空间,所以这个itera不能是指针,离散的,所以这个迭代器要非常聪明,除了vector,arry之外,其余的容器的iterator都必须是一个class,
template<class T, class Ref, class Ptr> struct __list_iterator { typedef __list_iterator<T, T&, T*> iterator; typedef __list_iterator<T, const T&, const T*> const_iterator; typedef __list_iterator<T, Ref, Ptr> self;- 1
- 2
- 3
- 4
- 5
iterator当中会有大量的操作符存在,因为要模拟指针,例如++,–之类的
并且至少要有5个typedef:
typedef bidirectional_iterator_tag iterator_category; typedef T value_type; typedef Ptr pointer; typedef Ref reference; typedef __list_node<T>* link_type; typedef size_t size_type; typedef ptrdiff_t difference_type;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- ++操作符,语言规格,前++是没有参数的,后++才有参数,只是为了好区分
self& operator++() { node = (link_type)((*node).next); return *this; } self operator++(int) { self tmp = *this; ++*this; return tmp; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- - -减减操作符则同理
self& operator--() { node = (link_type)((*node).prev); return *this; } self operator--(int) { self tmp = *this; --*this; return tmp; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 注意看,后++当中使用了前++的特性,还有返回类型,一个带引用,一个不带,这是因为操作符要向整数看齐,整数可以做的,操作符就可以做,整数不可以做的,操作符也不可以做,因为C++不允许后++两次,运行前++两次,所以后++的不带引用,是为了阻止其后++两次,所以前++有引用
- 提领
reference operator*() const { return (*node).data; } pointer operator->() const { return &(operator*()); }- 1
- 2
2.1 旧版新版之间的对比

2.9到4.9有进步,指针也不再是void指针了
所有的容器,之前就讲过,一定是前闭后开的区间,即,最后一个元素的下一个元素是不属于容器的,所以这就是为什么list要设计成环状的原因,end()指向的是下面那块灰色的,最后一个元素之后的元素。

和4.9版的进行对比
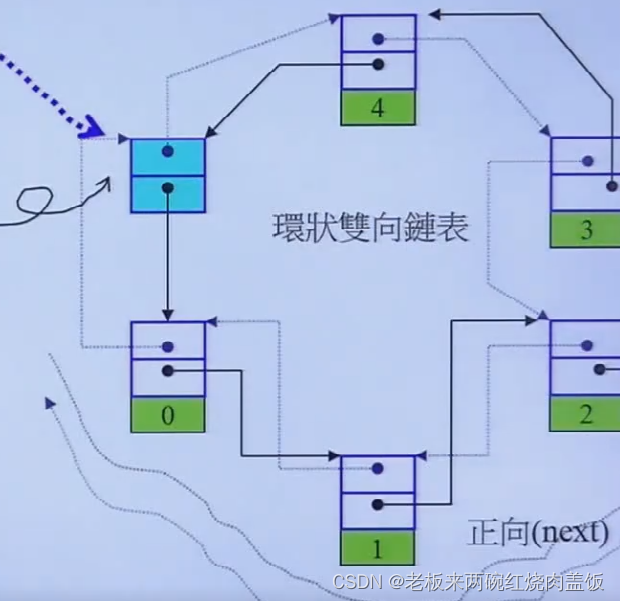
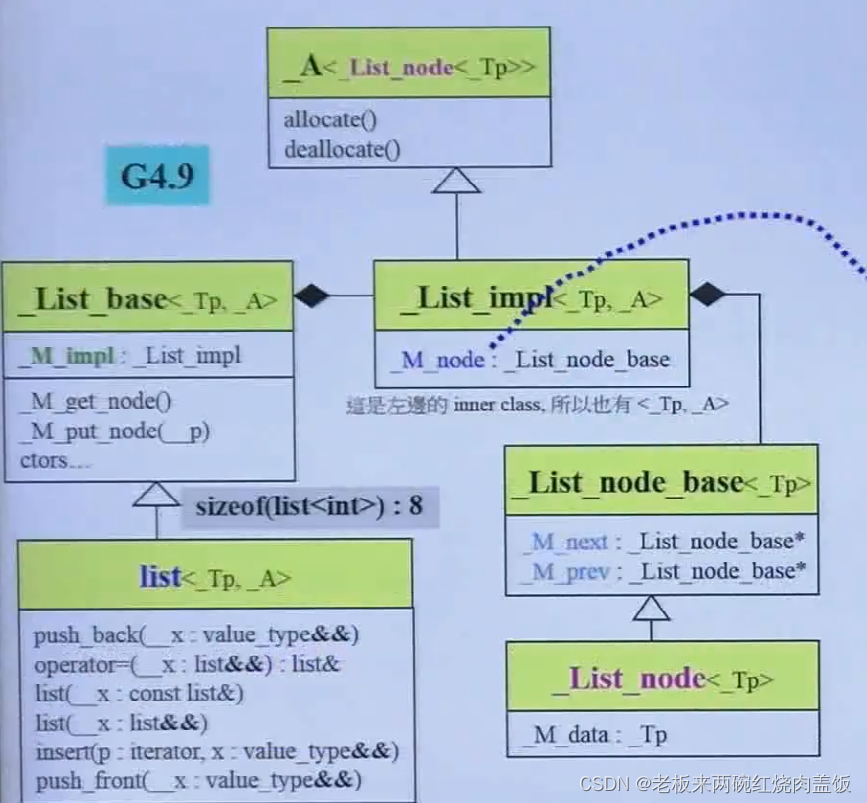
还有下面这个,在2.9的时候,list node为4,到了4.9版的时候怎么变成8了呢?

一些整理。
4.9版中,list类有继承关系,往上找,发现list的大小就是_List_node_base中的两个指针的大小。
2.2 list的iterator
- iterator是算法和容器之间的桥梁,一方面让算法知道他要处理的元素范围,所以通常我们会把容器的begin()和end()传给算法并让算法操作处理

- 在rotate这个算法当中,需要知道iterator的三个属性,其实总共有5种,这里出现了三种,剩下两种是reference和pointer,这五种type就是与迭代器相关的类型,迭代器本身必须定义出来
- 在list当中就定义出来了
template<class T, class Ref, class Ptr> struct __list_iterator { typedef __list_iterator<T, T&, T*> iterator; typedef __list_iterator<T, const T&, const T*> const_iterator; typedef __list_iterator<T, Ref, Ptr> self; typedef bidirectional_iterator_tag iterator_category; typedef T value_type; typedef Ptr pointer; typedef Ref reference;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- iterator_category()是迭代器的分类,比如说这个迭代器能++那个迭代器能- -之类的
- 下方,iterator所指的那个东西,就是value_type,假如所指的是string,那么其就是string
- difference_type是两个iterator之间的距离,应该用什么type表项,比如说可以用integer表示,那么type就是int
2.3 Traits
- 必须区分,收到的iterator到底是class所做出来的iterator还是一般的pointer,这就要使用Traits(中间层)来解决问题了

- 如上,算法想要知道class I的五种相关类型,算法就来问Traits,Traits就来转问I,如下,想知道value_type是什么,就转而去间接问,放到traits当中,然后三种选项进行回答

- 在上方的两个偏特化当中,为什么const *,之后的type没有const呢?是因为value_type是声明变量的,但是加上了const后,变量不能被赋值,所以不能加const
3 深度探索vector
很像一个array,但是他可以扩充,不能在原地扩充,
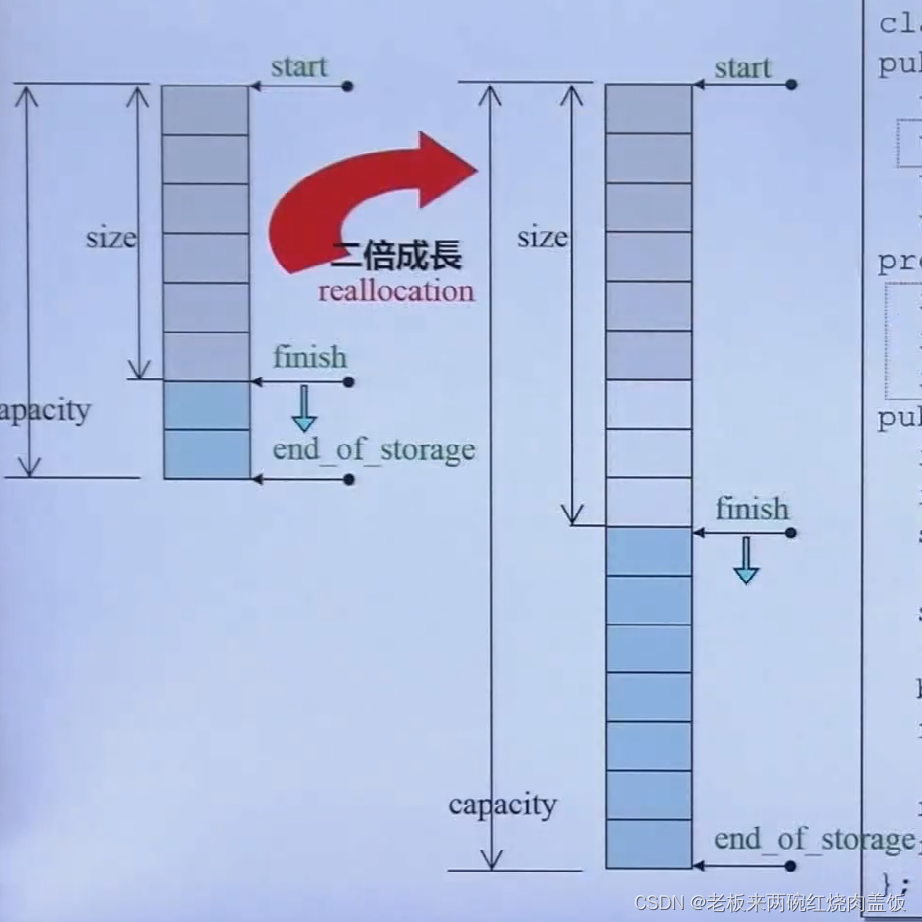
当这个容器,空间不够了,会在内存当中去找另外一块空间,这个空间数量为两倍大,是不是各个编译器都是两倍生长呢?是的
template <class T, class Alloc = alloc> class vector { public: typedef T value_type; typedef value_type* pointer; typedef const value_type* const_pointer; typedef value_type* iterator; typedef const value_type* const_iterator; typedef value_type& reference; typedef const value_type& const_reference; typedef size_t size_type; typedef ptrdiff_t difference_type;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 通过vector的源代码可以看出,这个默认的分配器是alloc,也就是GNU2.9那个最合适的分配器,非默认
protected: typedef simple_alloc<value_type, Alloc> data_allocator; iterator start; iterator finish; iterator end_of_storage;- 1
- 2
- 3
- 4
- 5
- 还有就是,在上图当中的三个指针,就是上方的三个iterator,这三个指针可以控制整个容器,因此,sizeof(vector) = 12bytes(32位)
iterator begin() { return start; } const_iterator begin() const { return start; } iterator end() { return finish; } const_iterator end() const { return finish; }- 1
- 2
- 3
- 4
- 可以看出,begin()传回来的是start,而end()传回来的是finish(因为容器是前闭后开的区间)
- 通过函数调用来返回size(),capacity(),empt()
size_type size() const { return size_type(end() - begin()); } size_type capacity() const { return size_type(end_of_storage - begin()); } bool empty() const { return begin() == end(); }- 1
- 2
- 3
3.1 vector的两倍增长到底是怎么一回事?
- 一定是发生在放元素进去的时候,比如说push_back()

判断是否有空间直接比较finish与end_of_storage这两个数值是否相等。如果没有备用空间了,先把原来的大小记录下来,之后,再把扩容的大小为两倍于原来的大小进行扩容。
最上方的
const size_type len = old_size != 0 ? 2 * old_size : 1;说明了一切

- 在内存当中找到了比原来两倍大的元素该怎么办呢?先把原来的元素copy到新找到的空间,之后再加入下一个元素,但是看源代码,加入下一个元素之后,把安插点之后的内容插入进来(当然psh_back()只是考虑尾部,还有insert()函数要考虑),这是因为一个辅助函数insert_aux这个辅助函数,他不仅仅只是被push_back()调用,还会被其它函数调用,比如说insert(),这样一来,比如说在8个元素的第三个元素中进行插入,这样就有一个插入点之前和插入点之后的情况,所以插入点之后的内容也是要考虑进来的
- vector每次成长的时候,都会大量调用元素的拷贝构造函数以及析构函数,这是因为要不断从内存当中找空间,找到新的空间就得消除原来的空间
3.2 vector的iterator
- vector是一段连续空间,按理说应该用指针就能当iterator
typedef T value_type; typedef value_type* pointer; typedef const value_type* const_pointer; typedef value_type* iterator;- 1
- 2
- 3
- 4
- 从源代码当中可以看出,vector的iterator确实是个指针
- 在list的iterator当中,提出了设计iterator需要5个属性,那么在vector当中,其只是一个指针,那么编译器怎么来得到那5个参数呢?
- 答案是之前讲过的traits,通过这个中介来问,如下是其中3个的问法
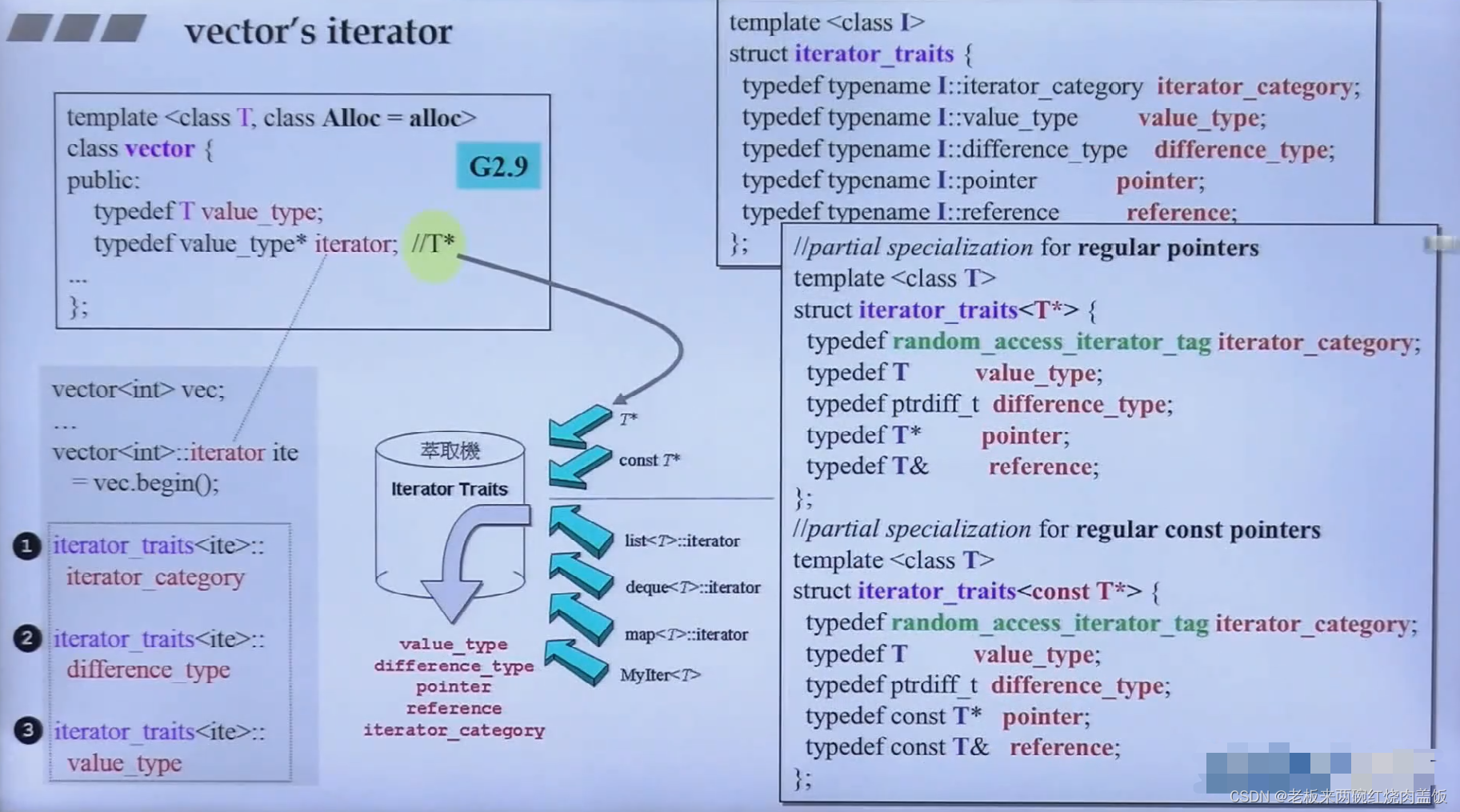
- traits当中有泛化,特化以及偏特化的部分,偏特化主要是指针
3.3 旧版新版之间的对比
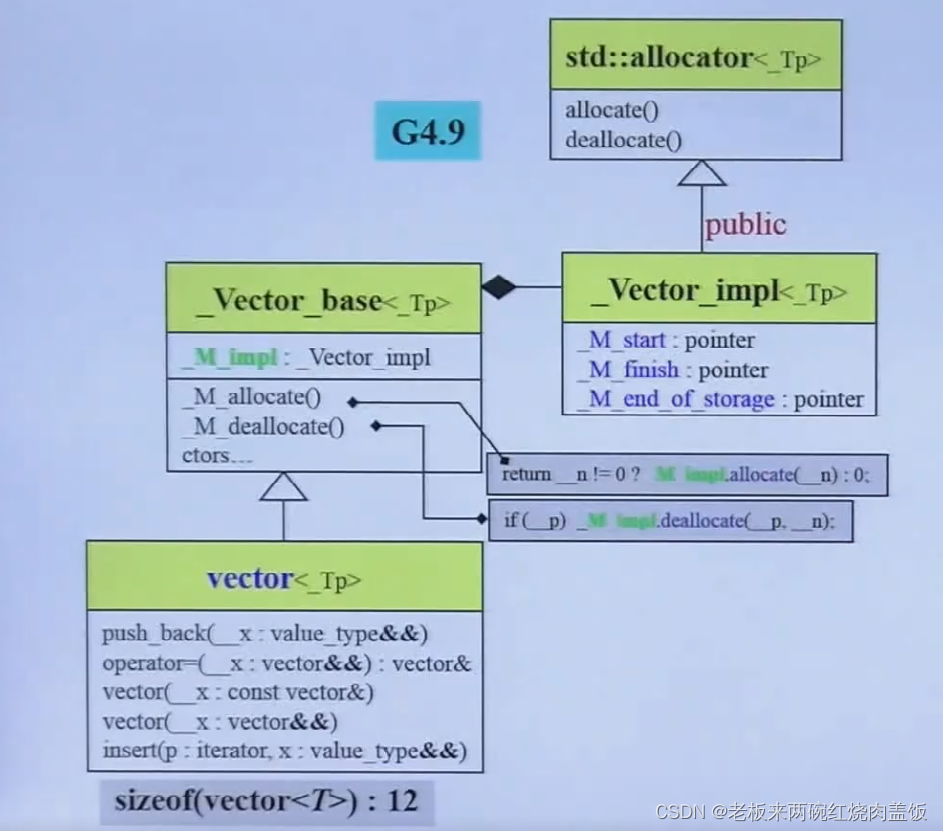
- 和之前的list当中变得一样臃肿,那么4.9版的vector的大小是多少呢?还是三个指针,也就是12字节(32位)
- 为什么用public进行继承?
- public表示“是一种,is a的关系”的继承,现在这里的继承主要是想让其用到父类的功能,所以直接用private继承就可以了,想不清楚这里用public的意义何在
- 总不能说vector“是一种”vector吧?
- vector的iterator有什么变化呢?
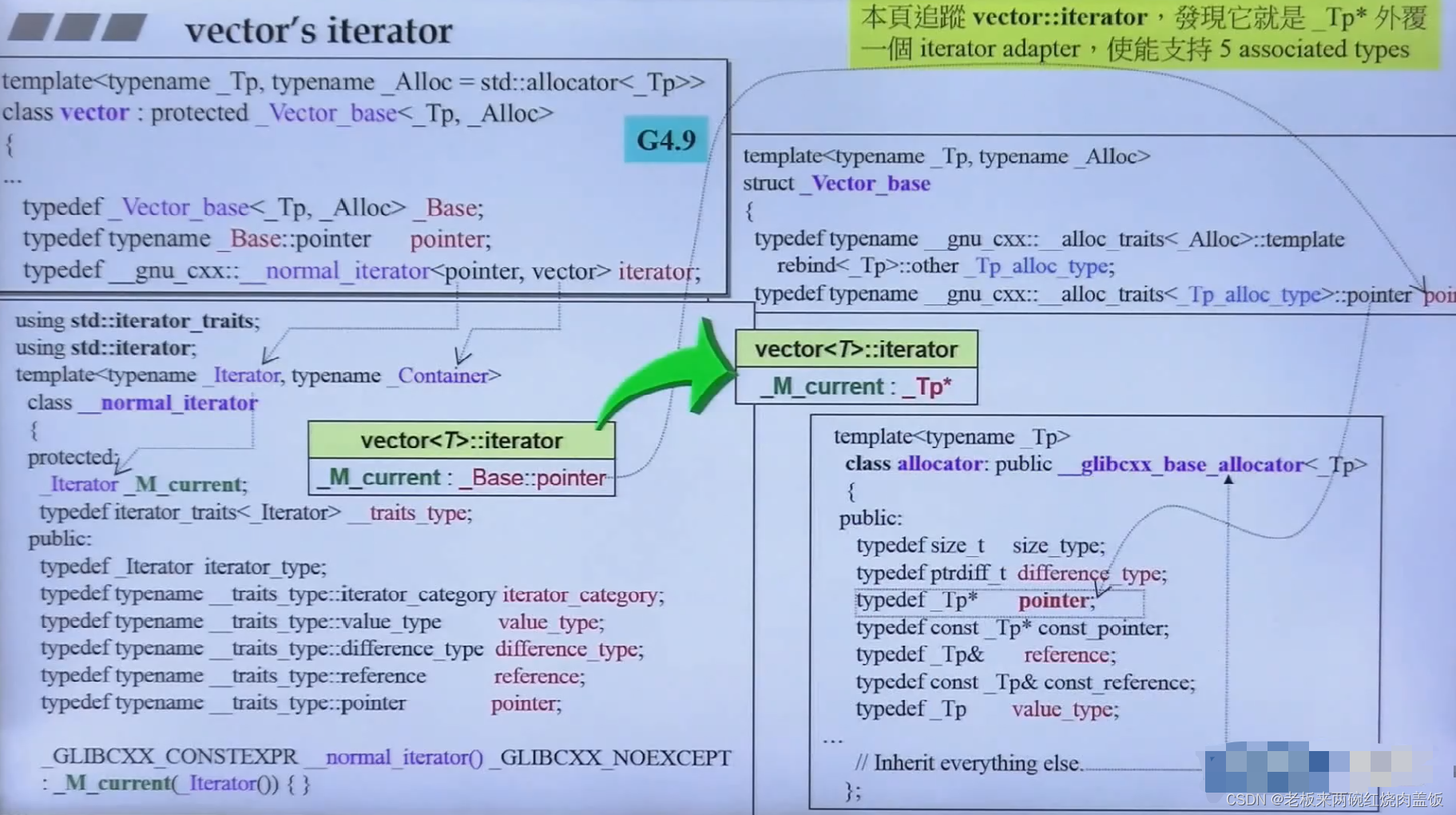
- 绕了这么久,以为是个什么高大上的东西,原来还是GNU2.9版的pointer T
- 在这里面,如果算法又来问5个属性这一类问题的话,那么iterator就是个对象不是单纯的指针了
- 在GNU2.9版很单纯,但是4.9版本就是一坨屎了,舍近求远
4 深度探索array、forward_list
array:
- array比vector更简单了,毕竟长度固定,不能扩容,也就是传统的数组,那为什么要包装成容器呢?
- 答案是变成容器之后,要遵循容器的规律,也就是提供一些iterator迭代器,而这些迭代器呢要提供5种相应的类型(关联类型,之前已经说过很多次了),以便于给算法提供信息,然后让算法执行一些最优化的操作
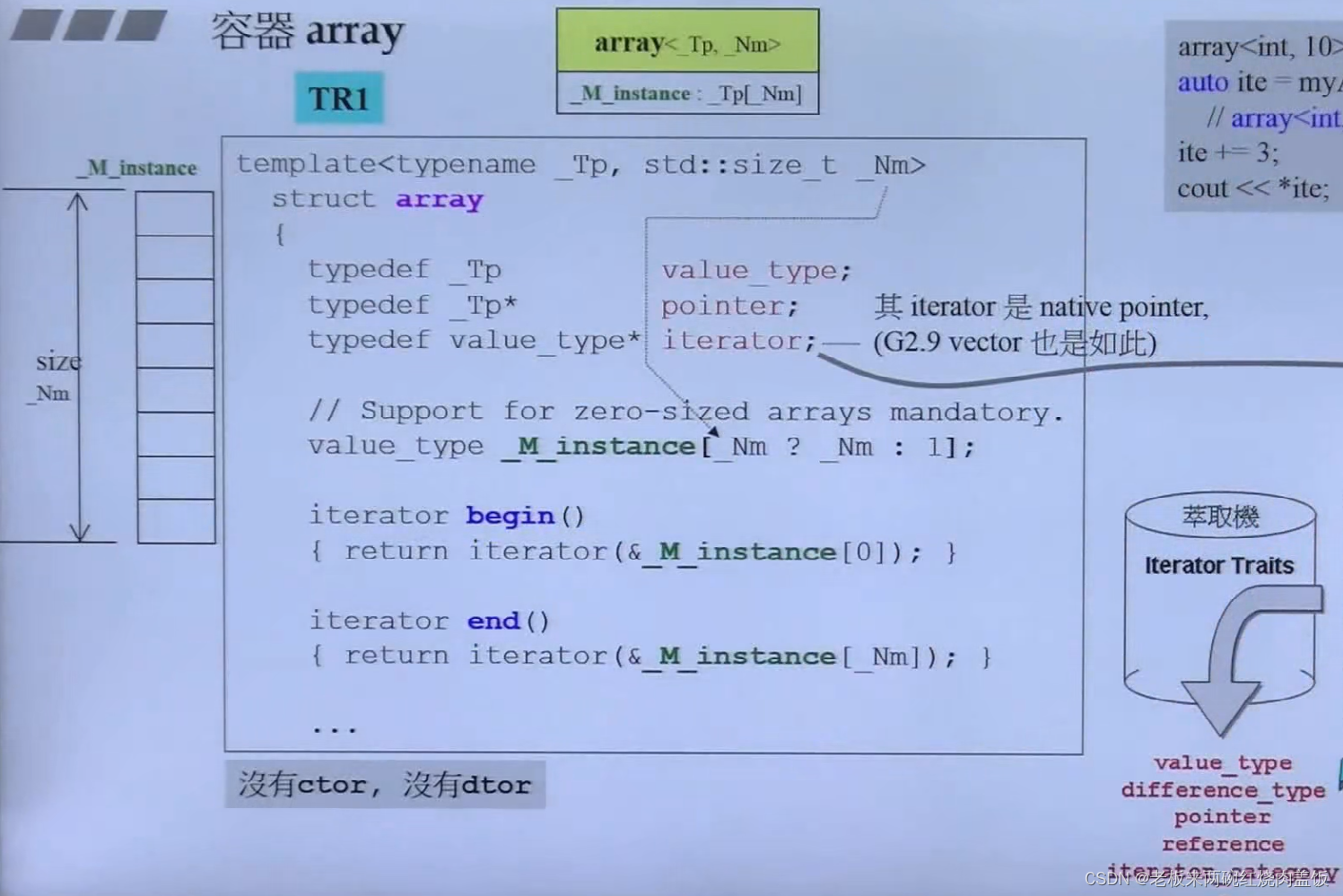
- 这个源代码是tr1的版本,有这么个实现
- array是个struct,基本等于class,怎么用array呢?必须指定大小,这与其他的容器不太一样,
value_type _M_instance[_Nm ? _Nm : 1];,这是在定义一个数组,那么这个数组多大呢?看里面的Nm,如是0,就自动变为1,其他的就按照原先的来 - array也是个连续空间,所以他的迭代器也就是个指针
- 因此算法要得到他的特性的时候,就直接traits进行萃取,萃取机分两部分,一部分指针,一部分class,直接跑到指针类型那里去
forward_list:
- 与list差不多,只不过list双向走,forward_list单向走,仅此而已,就不细讲了
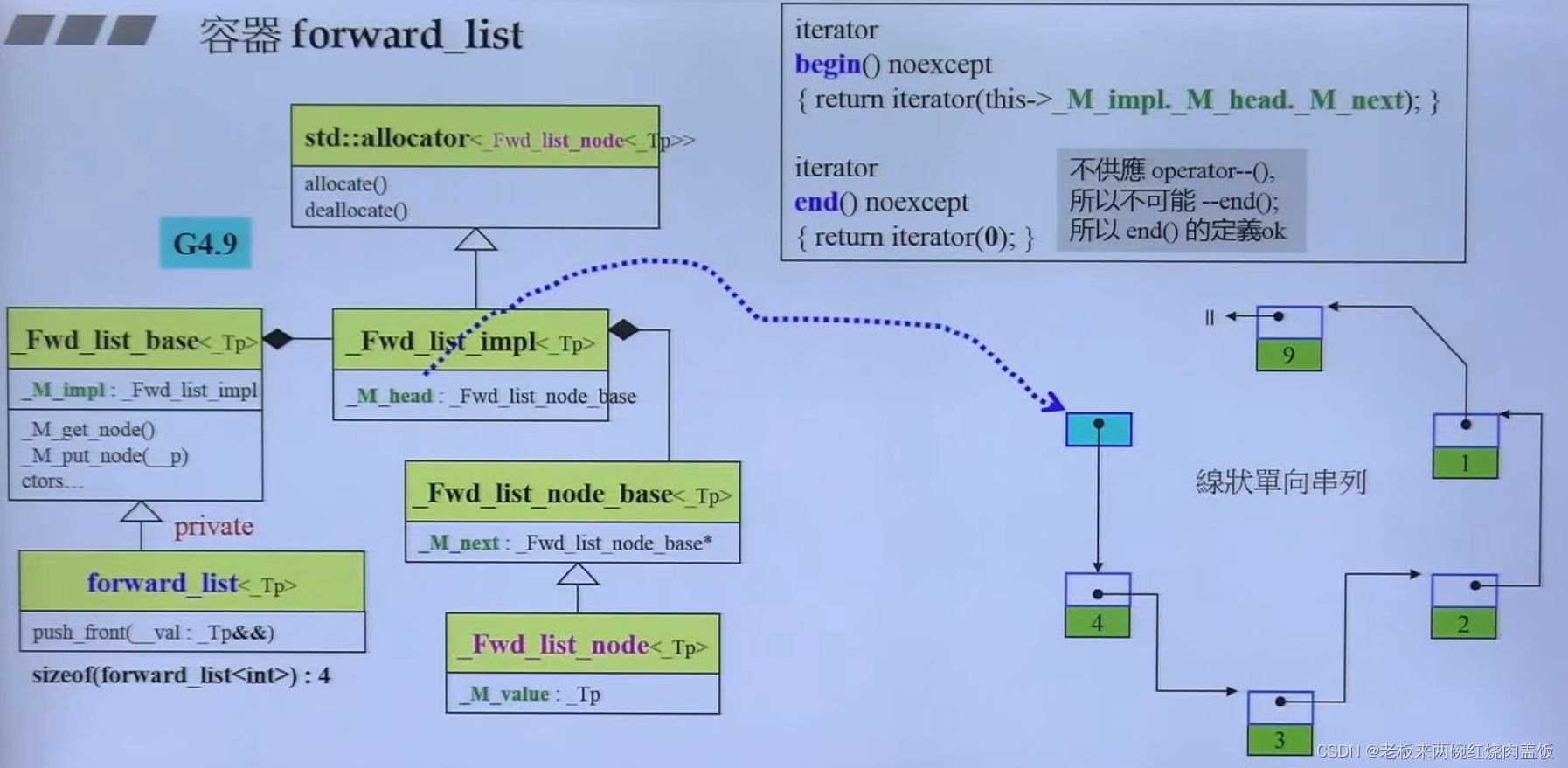
4.1 旧版新版之间的对比
array:

还是依旧臃肿。
5 深度探索deque、queue、stack
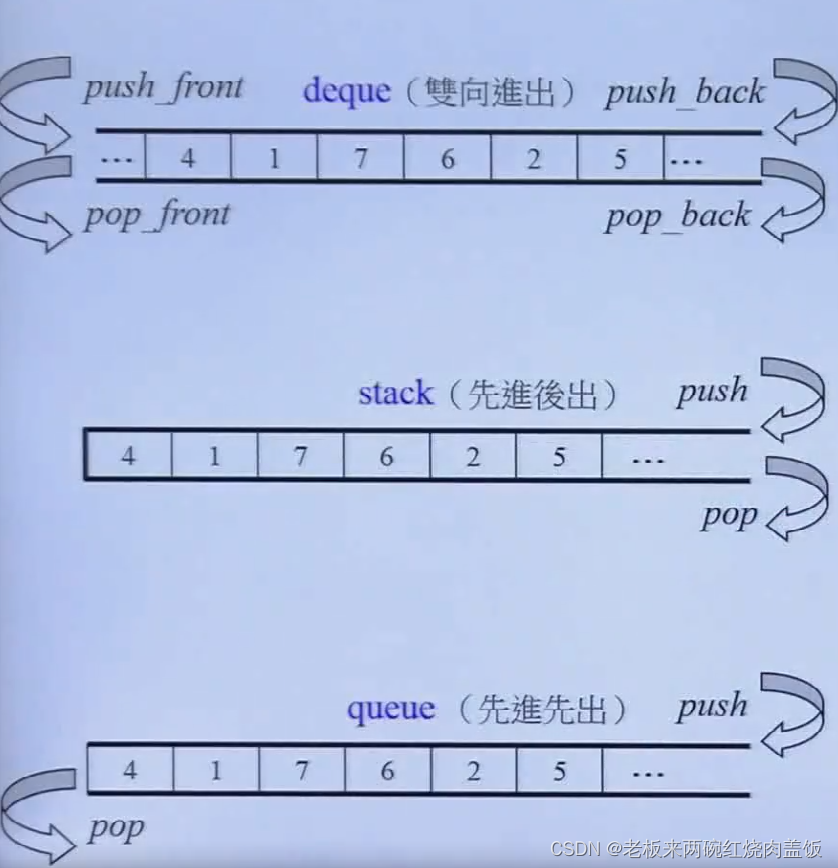
5.1 deque
deque:
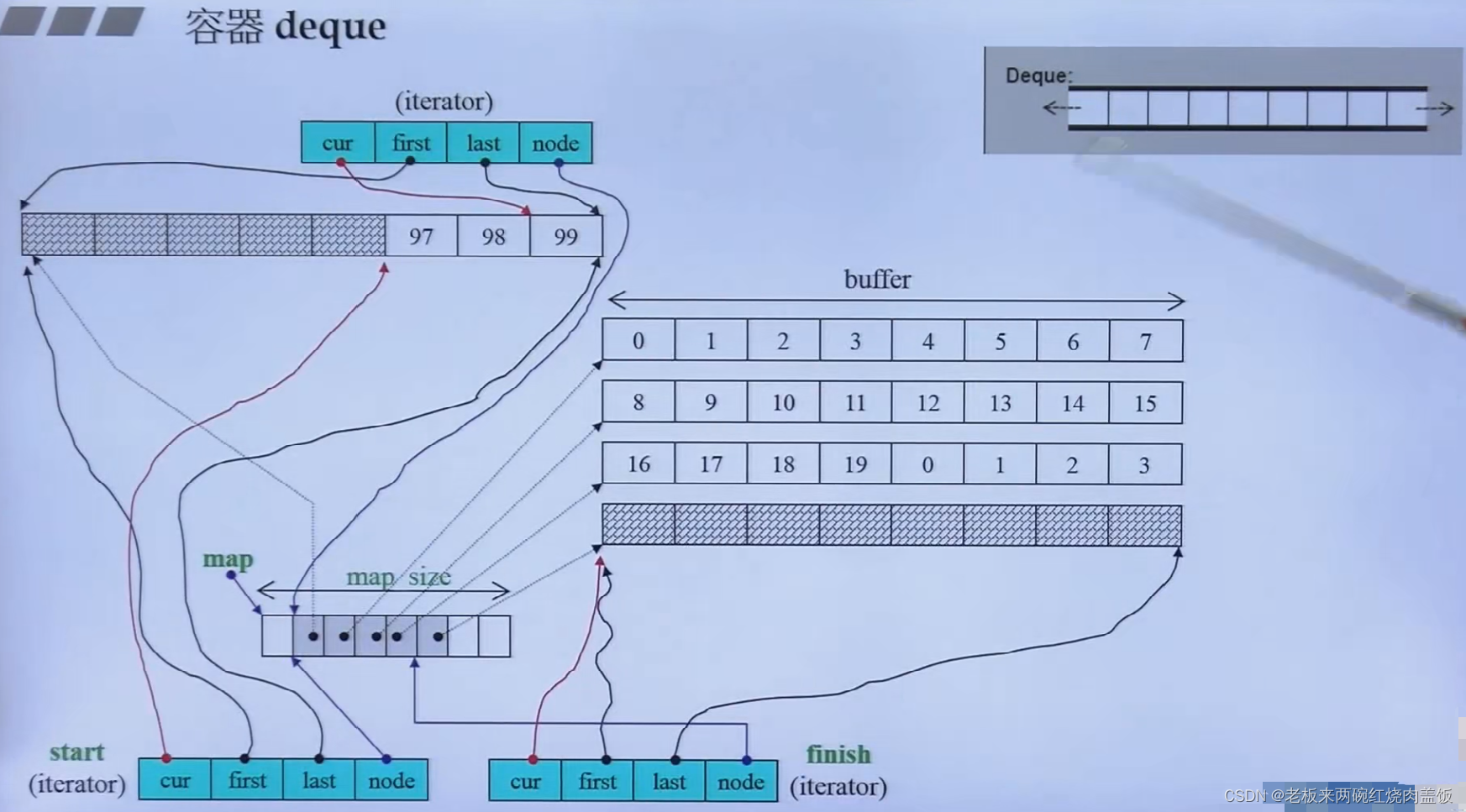
- 一个双向开口的一块空间
- 之前也提到过,前端插入怎么插呢
- 是用分段,分成几个段落(buffer缓冲区,也有称为节点node的),然后进行串接,所以这不是个连续的容器
- deque对外号称分段连续,其实不是连续的
- 那怎么把以上的几段进行连接呢?通过vector
- vector当中的每个元素其实是一个指针,这个指针指向了各个buffer,所以,这五个缓冲区的次序是怎么样呢?就看里面的指针的次序
- deque的迭代器有4个格子
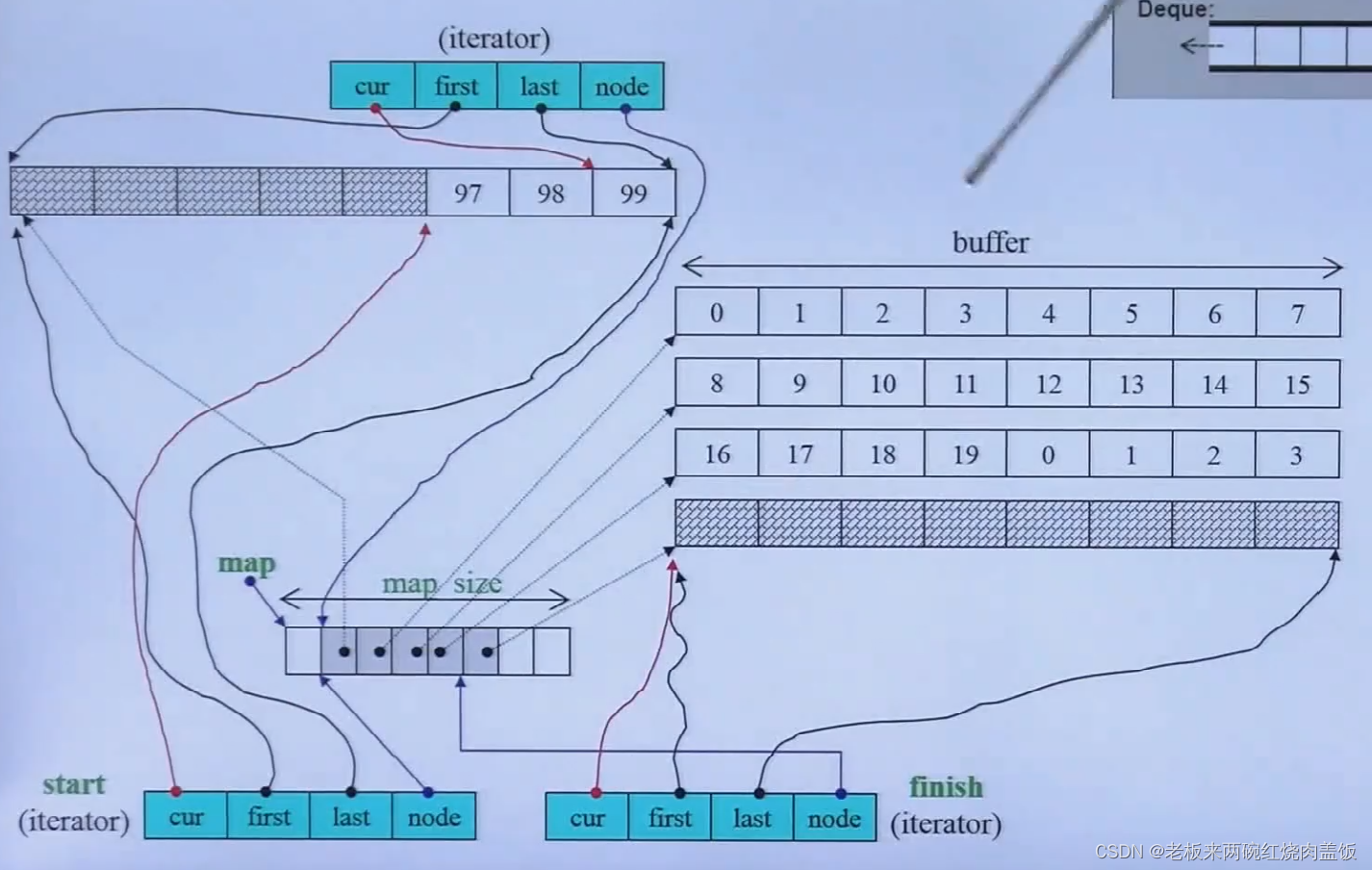
- 这个node指向的就是这个所谓的“控制中心”,因为分段的控制全在这里,当迭代器要++或者其他操作的时候,要看这个分段控制中心的,如下图的红色框中
- first和last指的是刚刚node所指的某一个分段的头和尾,这两个指针作为标兵,标出buffer的边界,如果到了边界,怎么到达下个边界的时候,node进行转变到下一个buffer,将node移向下一个buffer的指针,也就是node++
- cur是迭代器所指向的那个元素
- 为什么上方要画出三个iterator呢?因为除了当前的那个元素,几乎所有的容器还要维护自己容器的头和尾,也就是begin()和end()这两个迭代器
template <class T, class Alloc = alloc, size_t BufSiz = 0> class deque { public: // Basic types typedef T value_type; typedef value_type* pointer; typedef const value_type* const_pointer; typedef value_type& reference; typedef const value_type& const_reference; typedef size_t size_type; typedef ptrdiff_t difference_type; public: // Iterators #ifndef __STL_NON_TYPE_TMPL_PARAM_BUG typedef __deque_iterator<T, T&, T*, BufSiz> iterator; typedef __deque_iterator<T, const T&, const T&, BufSiz> const_iterator; #else /* __STL_NON_TYPE_TMPL_PARAM_BUG */ typedef __deque_iterator<T, T&, T*> iterator; typedef __deque_iterator<T, const T&, const T*> const_iterator; #endif /* __STL_NON_TYPE_TMPL_PARAM_BUG */ #ifdef __STL_CLASS_PARTIAL_SPECIALIZATION typedef reverse_iterator<const_iterator> const_reverse_iterator; typedef reverse_iterator<iterator> reverse_iterator; #else /* __STL_CLASS_PARTIAL_SPECIALIZATION */ typedef reverse_iterator<const_iterator, value_type, const_reference, difference_type> const_reverse_iterator; typedef reverse_iterator<iterator, value_type, reference, difference_type> reverse_iterator; #endif /* __STL_CLASS_PARTIAL_SPECIALIZATION */ protected: // Internal typedefs typedef pointer* map_pointer; typedef simple_alloc<value_type, Alloc> data_allocator; typedef simple_alloc<pointer, Alloc> map_allocator;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
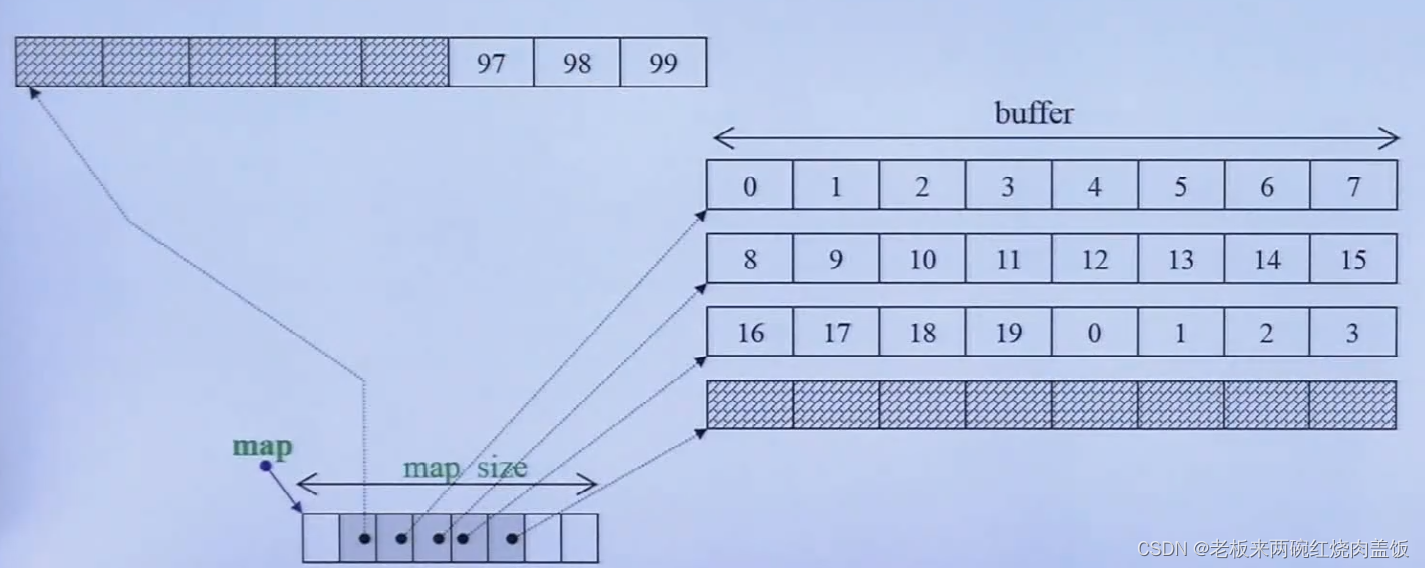
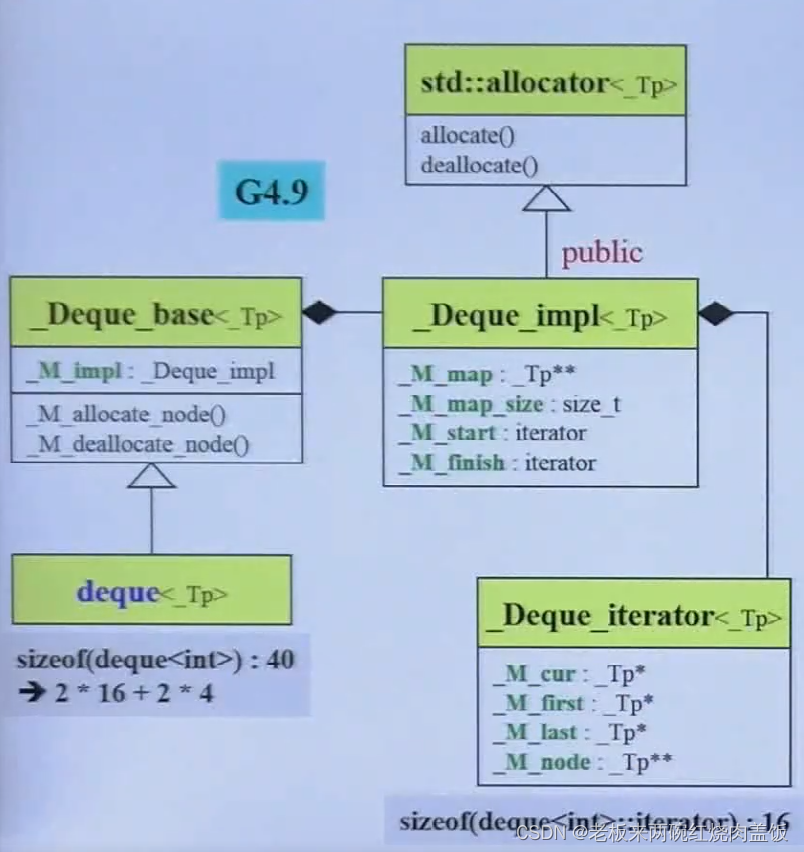
protected: // Data members iterator start; iterator finish; map_pointer map; size_type map_size;- 1
- 2
- 3
- 4
- 5
对应下图

- map_size是可以增长的,因为是vector,还是两倍增长
- 那么这个deque的大小是多少,map_size和map大小是4,和为8,start和finish是iterator,那么这个iterator的大小是多少呢,4个指针大小就是iterator,16字节为1个iterator的大小,2个就是32字节,那么deque基本大小为 32 + 8 = 40 32 + 8 = 40 32+8=40字节
T* cur; T* first; T* last; map_pointer node;- 1
- 2
- 3
- 4
- 为什么默认缓冲区buffer大小为0?
template <class T, class Alloc = alloc, size_t BufSiz = 0>- 1
- 发现了有个内联函数解释
inline size_t __deque_buf_size(size_t n, size_t sz) { return n != 0 ? n : (sz < 512 ? size_t(512 / sz) : size_t(1)); }- 1
- 2
- 3
- 4
- 有指定值的话,n非0的时候,所以结果就是n;n为0的时候,看一个元素多大,如果这个元素大于512,那么一个缓冲区就放一个元素;如果元素小于512,比如放整数,那么大小就是4,放多少个呢,就是 512 / 4 512 / 4 512/4
5.2 deque的iterator
deque:
template <class T, class Ref, class Ptr, size_t BufSiz> struct __deque_iterator { typedef __deque_iterator<T, T&, T*, BufSiz> iterator; typedef __deque_iterator<T, const T&, const T*, BufSiz> const_iterator; static size_t buffer_size() {return __deque_buf_size(BufSiz, sizeof(T)); } #else /* __STL_NON_TYPE_TMPL_PARAM_BUG */ template <class T, class Ref, class Ptr> struct __deque_iterator { typedef __deque_iterator<T, T&, T*> iterator; typedef __deque_iterator<T, const T&, const T*> const_iterator; static size_t buffer_size() {return __deque_buf_size(0, sizeof(T)); } #endif typedef random_access_iterator_tag iterator_category; typedef T value_type; typedef Ptr pointer; typedef Ref reference; typedef size_t size_type; typedef ptrdiff_t difference_type; typedef T** map_pointer; typedef __deque_iterator self; T* cur; T* first; T* last; map_pointer node;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
deque的insert()举例

- 因为每一次都要调用构造函数和析构函数,相当花时间,所以肯定是要往短方向去推
- 这个地方表现出,insert()就会这么做
- 如下图:往短的地方去推动

5.3 deque怎么模拟连续空间
- 看代码当中的注释,全是iterator的功劳
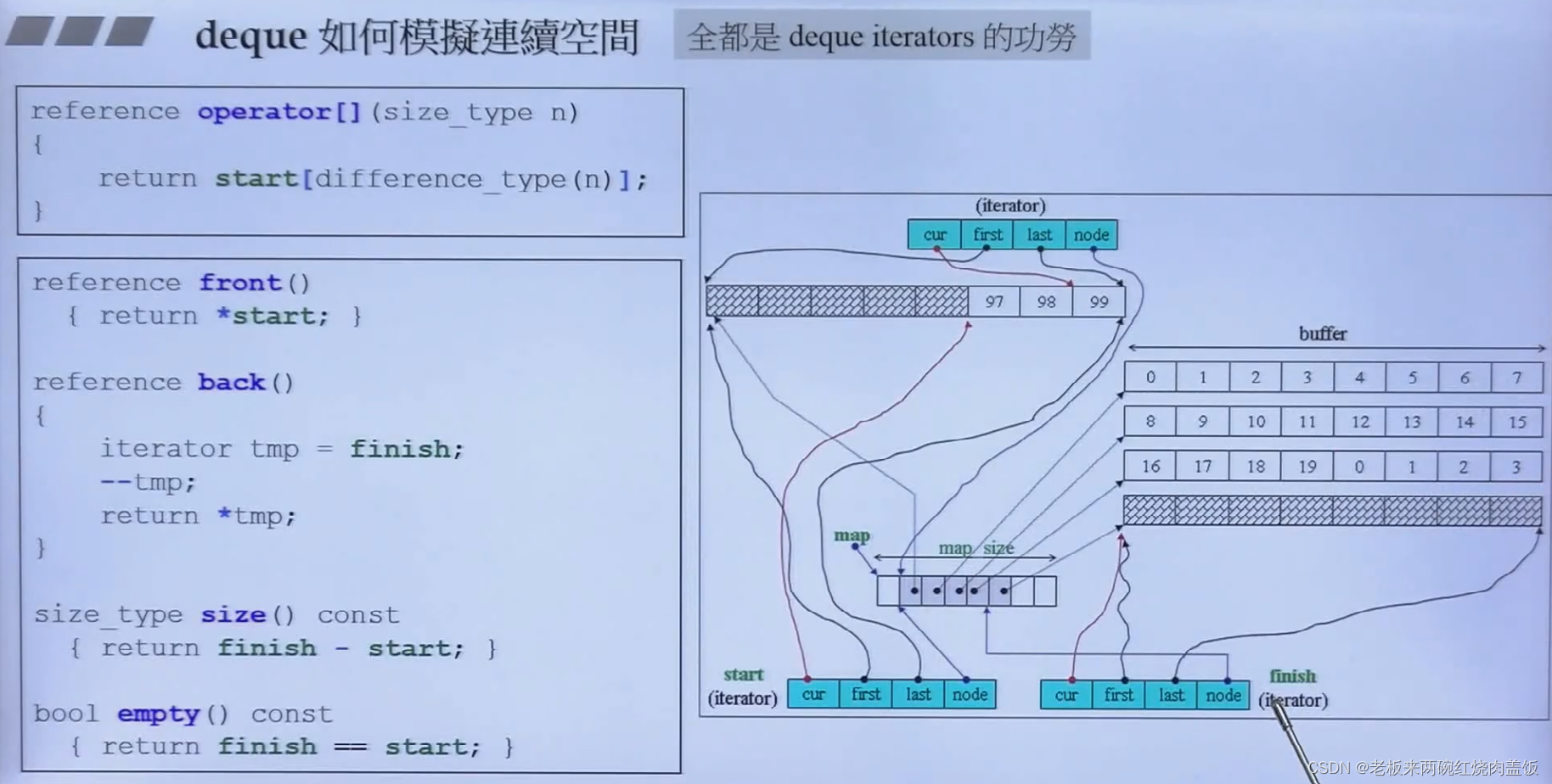
reference front() { return *start; } reference back() { iterator tmp = finish; --tmp; return *tmp; } const_reference front() const { return *start; }//要最前的就传回start,永远指向投 const_reference back() const { const_iterator tmp = finish; --tmp;//finish所指的是最后一个元素下一个的地方,所以就要减去一个 return *tmp; } size_type size() const { return finish - start;; }//看迭代器这个范围当中有多少个缓冲区,则元素的个数就是缓冲区的个数*元素的个数 size_type max_size() const { return size_type(-1); } bool empty() const { return finish == start; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
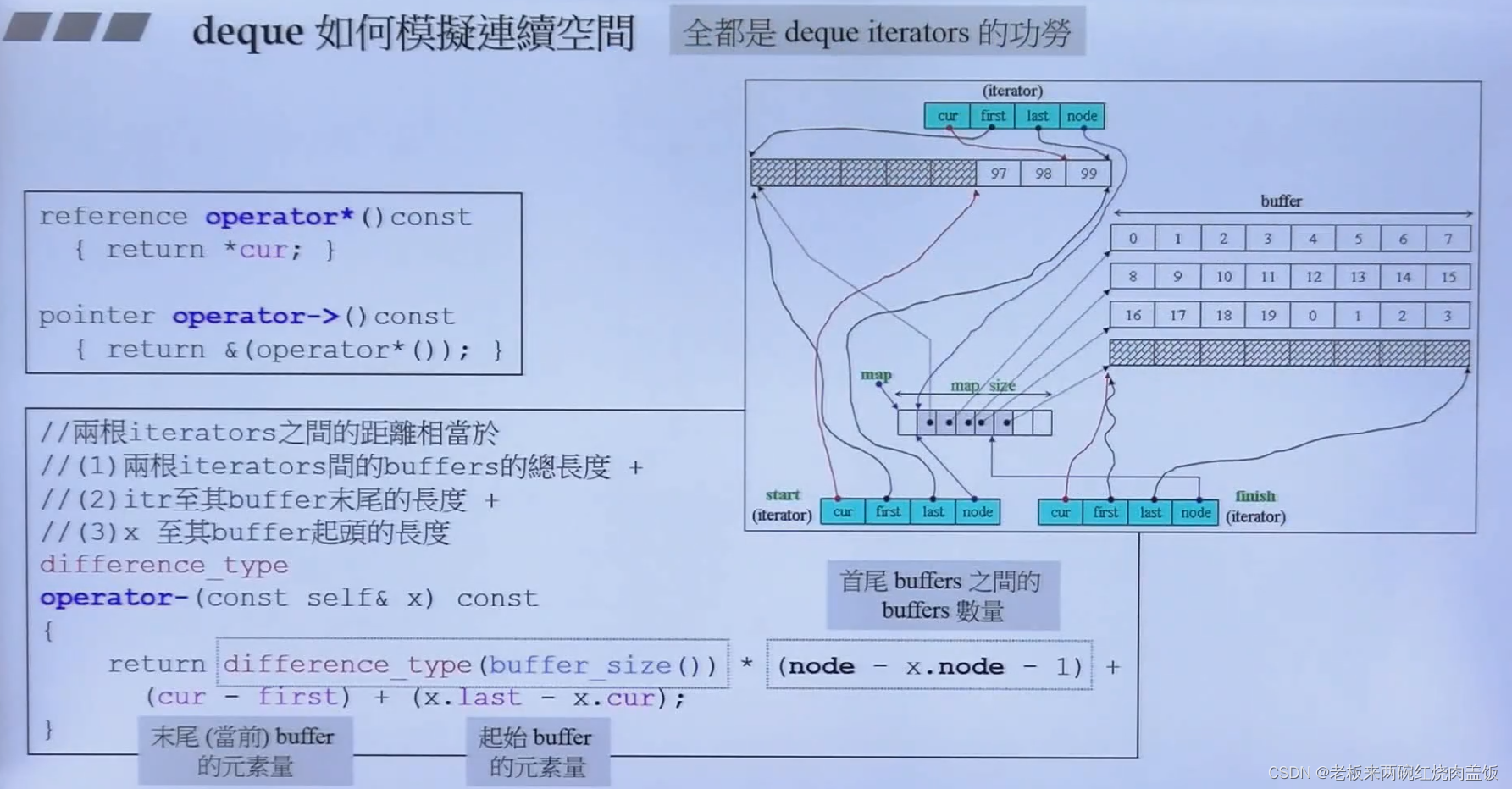
reference operator*() const { return *cur; } #ifndef __SGI_STL_NO_ARROW_OPERATOR pointer operator->() const { return &(operator*()); } #endif /* __SGI_STL_NO_ARROW_OPERATOR */ difference_type operator-(const self& x) const { return difference_type(buffer_size()) * (node - x.node - 1) + (cur - first) + (x.last - x.cur); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

- ++运算符和之前list当中的差不多,后++用前j++进行代替
- 跳到下一个边界需要调用控制中心,才能移动到下一个buffer
- ++就是移动cur
- 就是这里的++和- - 让使用者感觉不到分段,从而感觉到连续
- 现在不看+1了,假如+n呢,那么肯定要判断是否超过了缓冲区的边界,如果超过了肯定要联系控制中心node进行缓冲区的调度
- 如果加完/减完还在当前缓冲区,就没事,如果超过了,就要算出跨越多少缓冲区,就是你要跳的距离/缓冲区的大小
- 到达正确的缓冲区之后,再决定增加几个元素


5.4 deque旧版新版之间的对比
- 一如既往的臃肿
- 大小与2.9版一样
- 取消了buffer_size

- 前面说了,这个控制中心node其实是一个vector,那么vector总会有扩容的时候,在学习vector的时候,知道了vector会找一个两倍于现在大的空间,找到空间后,把原空间的元素进行copy,现在deque中也是copy,但是这里的copy很聪明,会把原来的元素copy到deque当中的中段,这样是为了让其两边都有一定的富余,这样就既可以向左扩充也可以向右扩充
5.5 qeque
- 从以上图结构当中可以看出,可以不用重写queue和stack,可以让其内含一个queue,然后封掉其部分功能,就可以实现
- 有了这个deque以后,queue所做的事情就是如下蓝色的指令,8个函数操作,这些操作都不自己做事,让deque做,转调用的形式

5.6 stack
- 与queue类似,都是用一个deque,都是转调用

5.7 queue和stack能否选择其他容器?
- 如果,他们两个的操作,某容器能提供这些转调用的操作,就能换这个容器作为底层服务
- 发现list和deque都可以作为这两个的底层服务
- 并且这两个都不提供迭代器,所以不能遍历

- 同时,stack可以用vector当做底层服务
- stack 和 queue 都不能用set / map 当做底层结构
6 深度探索rb_tree(红黑树)
- 关联式容器,用key找value

- 红色黑色代表状态
- 红黑树就是二叉搜索树BST,有利于未来的查找
- 红黑树的中序遍历,得到的是一个升序的序列
- 注意看,begin()是指向了5这个节点的,然后end()是指向了15这个节点的,5后只能往上走了
- 不应该使用红黑树的迭代器去修改红黑树的节点值
- 说不应该代表是可修改的?为什么呢,在map当中,可以修改当中的key,但是value不能改
6.1 rb_tree源代码
class rb_tree { protected: typedef void* void_pointer; typedef __rb_tree_node_base* base_ptr; typedef __rb_tree_node<Value> rb_tree_node; typedef simple_alloc<rb_tree_node, Alloc> rb_tree_node_allocator; typedef __rb_tree_color_type color_type; public: typedef Key key_type; typedef Value value_type; typedef value_type* pointer; typedef const value_type* const_pointer; typedef value_type& reference; typedef const value_type& const_reference; typedef rb_tree_node* link_type; typedef size_t size_type; typedef ptrdiff_t difference_type; protected: link_type get_node() { return rb_tree_node_allocator::allocate(); } void put_node(link_type p) { rb_tree_node_allocator::deallocate(p); } link_type create_node(const value_type& x) { link_type tmp = get_node(); __STL_TRY { construct(&tmp->value_field, x); } __STL_UNWIND(put_node(tmp)); return tmp; } link_type clone_node(link_type x) { link_type tmp = create_node(x->value_field); tmp->color = x->color; tmp->left = 0; tmp->right = 0; return tmp; } void destroy_node(link_type p) { destroy(&p->value_field); put_node(p); } protected: size_type node_count; // keeps track of size of tree link_type header; Compare key_compare;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 从红黑源代码当中可以看出,要求放五个模板参数

- 当使用红黑树的时候,标准库的实现要告知key是什么类型,value是什么类型
- 还要告诉KeyOfValue,就是在这个整个节点里面,key要怎么拿出来
- 告诉compare,必须告诉两个元素比大小,key比大小,还是什么比大小,要求要告诉
- 默认的分配器alloc
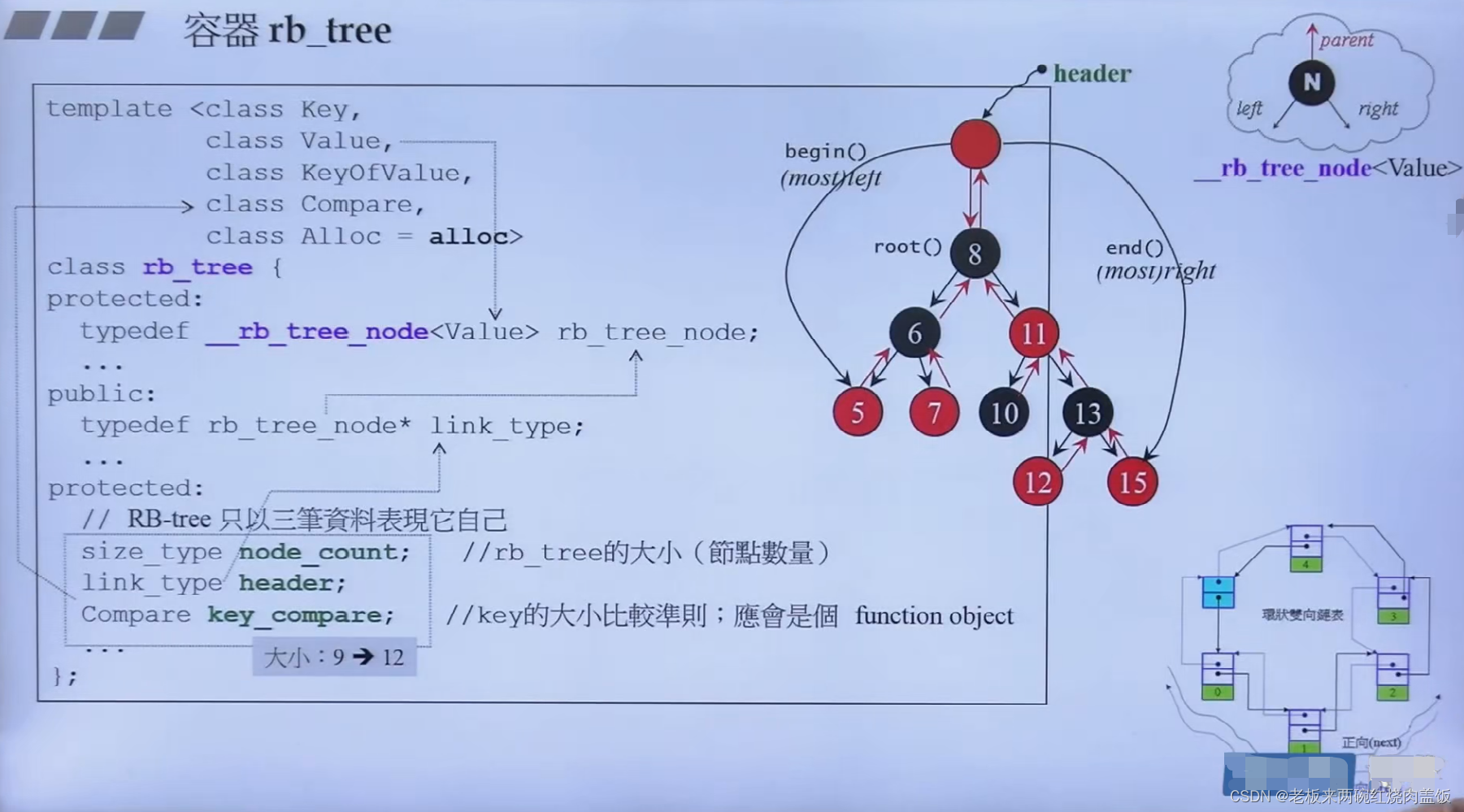
- 在list当中,如图右下角,有一个地方是虚空的,也就是蓝色标记的那个地方,这虚空的是刻意放进去的(为了做前闭后开区间刻意放进去的,不是真正的元素)
- 同理,在红黑树上面,也有一个虚的东西,就是header的那个节点,也是虚的,刻意加进去的
- 设计成这样会使得红黑树好操作一些
- 一个红黑树有多大?看data
protected: size_type node_count; // keeps track of size of tree link_type header; Compare key_compare;- 1
- 2
- 3
- 4
- size_type节点的数量,int
- link_type 是个指针,指向红黑树的节点,节点是_rb_tree_node这个
- Compare就是传给class Compare的一个函数
- 以上,总大小为12
- 一些常用的容器大小

6.2 使用rb_tree
- 填入正确的五个模板参数

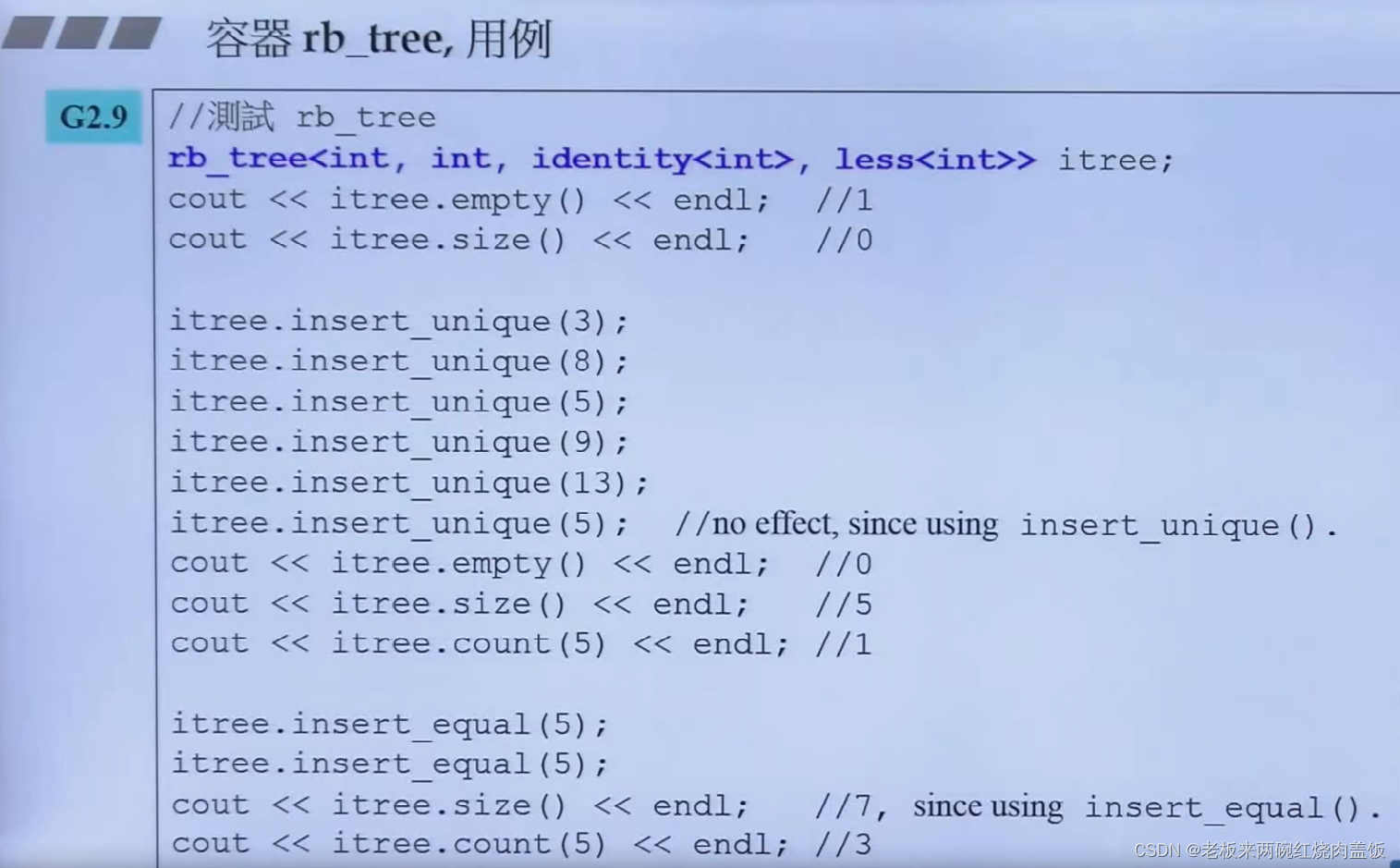
- 可以使用这个方法,直接使用红黑树
6.3 rb_tree旧版新版之间的对比
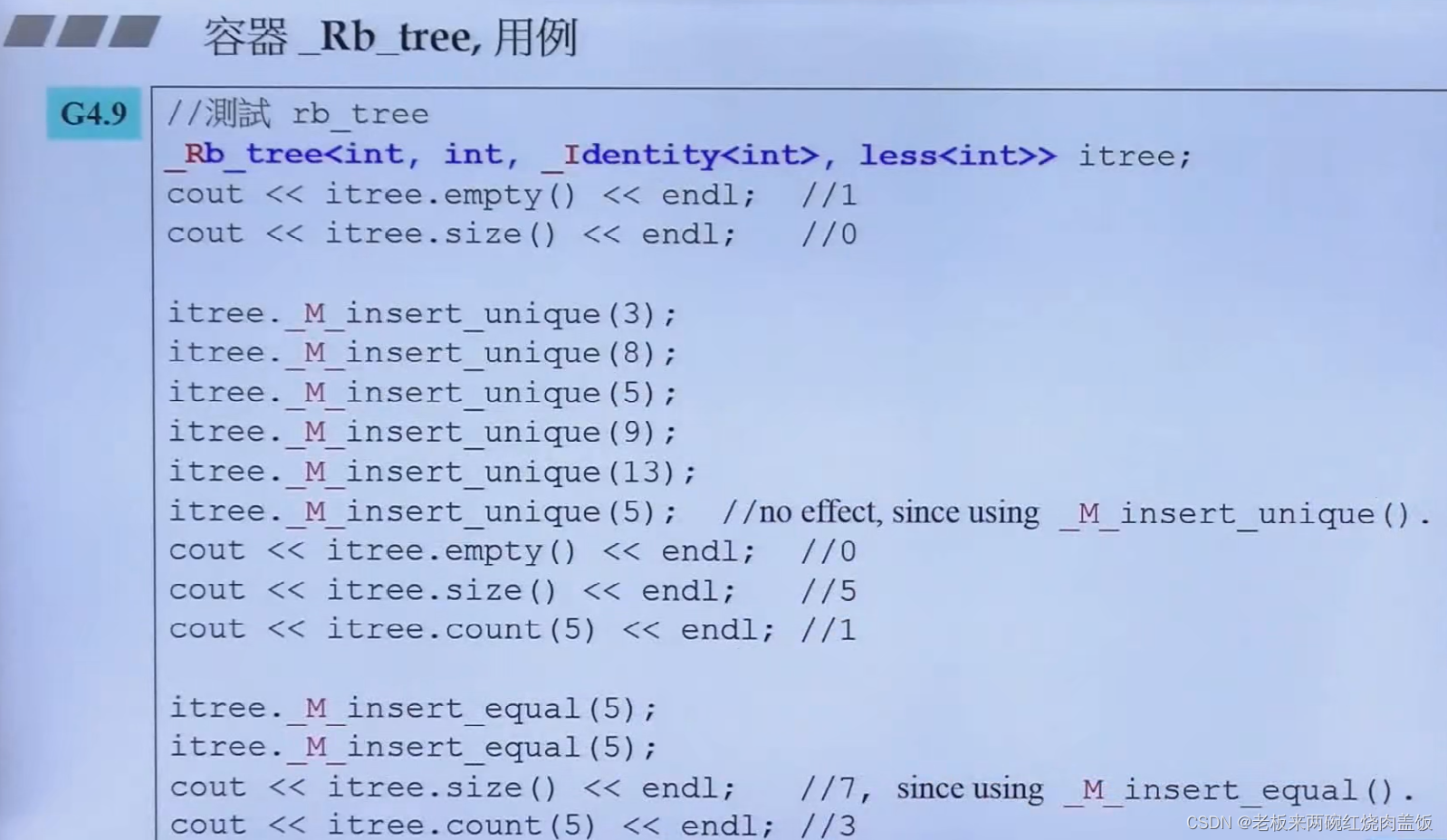
-
两幅图找不同
-
还有4.9版还是变得更加臃肿了,但是其符合OOP
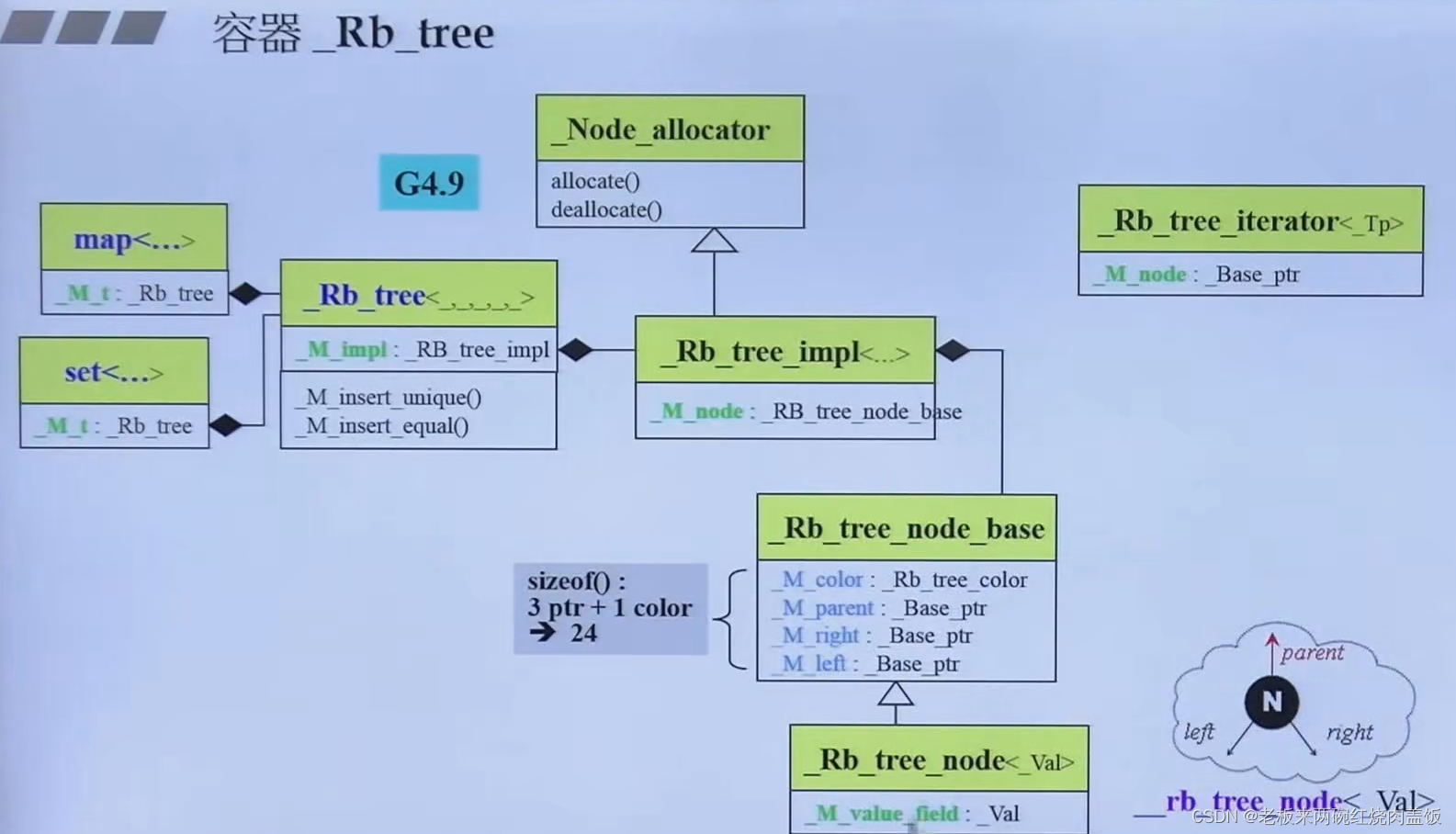
7 深度探索set、multiset
7.1 set
- 这两个容器是以红黑树为底层结构的,而且两个容器的value和key是合一的
- 提供迭代器
- 无法使用set/multiset的迭代器改变元素值,因为key的值就是value
- set的key必须是独一无二的,multiset的可以不是唯一
7.2 set的源代码
template <class Key, class Compare = less<Key>, class Alloc = alloc> #else template <class Key, class Compare, class Alloc = alloc> #endif class set { public: // typedefs: typedef Key key_type; typedef Key value_type; typedef Compare key_compare; typedef Compare value_compare; private: typedef rb_tree<key_type, value_type, identity<value_type>, key_compare, Alloc> rep_type; rep_type t; // red-black tree representing set public: typedef typename rep_type::const_pointer pointer; typedef typename rep_type::const_pointer const_pointer; typedef typename rep_type::const_reference reference; typedef typename rep_type::const_reference const_reference; typedef typename rep_type::const_iterator iterator; typedef typename rep_type::const_iterator const_iterator; typedef typename rep_type::const_reverse_iterator reverse_iterator; typedef typename rep_type::const_reverse_iterator const_reverse_iterator; typedef typename rep_type::size_type size_type; typedef typename rep_type::difference_type difference_type; // allocation/deallocation set() : t(Compare()) {} explicit set(const Compare& comp) : t(comp) {} #ifdef __STL_MEMBER_TEMPLATES template <class InputIterator> set(InputIterator first, InputIterator last) : t(Compare()) { t.insert_unique(first, last); } template <class InputIterator> set(InputIterator first, InputIterator last, const Compare& comp) : t(comp) { t.insert_unique(first, last); } #else set(const value_type* first, const value_type* last) : t(Compare()) { t.insert_unique(first, last); } set(const value_type* first, const value_type* last, const Compare& comp) : t(comp) { t.insert_unique(first, last); } set(const_iterator first, const_iterator last) : t(Compare()) { t.insert_unique(first, last); } set(const_iterator first, const_iterator last, const Compare& comp) : t(comp) { t.insert_unique(first, last); } #endif /* __STL_MEMBER_TEMPLATES */ set(const set<Key, Compare, Alloc>& x) : t(x.t) {} set<Key, Compare, Alloc>& operator=(const set<Key, Compare, Alloc>& x) { t = x.t; return *this; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 一上来就是三个模板参数
- 怎么内含一个红黑树呢?
private: typedef rb_tree<key_type, value_type, identity<value_type>, key_compare, Alloc> rep_type;- 1
- 2
- 3
- rep_type里面有个变量t,就是红黑树,包含了红黑树五个参数
- 注意这里的identity,因为知道了红黑树的结构,也就是key和value都是合一的
- 所以这里的identity就是用来从value取key的作用
- 比大小选用的是less,一个模板,允许你指定要比什么东西,怎么比也要说明

typedef typename rep_type::const_iterator iterator;- 1
- 还有一个就是,当你从set当中取出迭代器,取出的是const_iterator,避免改变元素,这就是为什么不能通过迭代器去改变元素的原因
- set自己都不做东西,用的是其他底层结构的接口,与stack和queue差不多
7.3 multiset
- 和set差不多,就是key可以重复
8 深度探索map、multimap
8.1 map
- 也是以红黑树做为支撑,在set当中,key和value是合一的,但是在map、当中,value包括了key和data,key和data合成了value。

8.2 map源代码
template <class Key, class T, class Compare = less<Key>, class Alloc = alloc> #else template <class Key, class T, class Compare, class Alloc = alloc> #endif class map { public: // typedefs: typedef Key key_type; typedef T data_type; typedef T mapped_type; typedef pair<const Key, T> value_type; typedef Compare key_compare; class value_compare : public binary_function<value_type, value_type, bool> { friend class map<Key, T, Compare, Alloc>; protected : Compare comp; value_compare(Compare c) : comp(c) {} public: bool operator()(const value_type& x, const value_type& y) const { return comp(x.first, y.first); } }; private: typedef rb_tree<key_type, value_type, select1st<value_type>, key_compare, Alloc> rep_type; rep_type t; // red-black tree representing map public: typedef typename rep_type::pointer pointer; typedef typename rep_type::const_pointer const_pointer; typedef typename rep_type::reference reference; typedef typename rep_type::const_reference const_reference; typedef typename rep_type::iterator iterator; typedef typename rep_type::const_iterator const_iterator; typedef typename rep_type::reverse_iterator reverse_iterator; typedef typename rep_type::const_reverse_iterator const_reverse_iterator; typedef typename rep_type::size_type size_type; typedef typename rep_type::difference_type difference_type;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 在map当中,首先是包含了4个红黑树的参数,后面两个是默认值不需要放。

- select1st就是从一堆当中取出第一个,所以从value当中取出第一个就是key
- 对于map,其迭代器可以改data,但是不能改key
- map的迭代器就是红黑树的迭代器
typedef typename rep_type::iterator iterator;- 1
- map的两个元素,被包成了一个pair,也就是key和data,在map当中被包成了一个pair,这个数据结构命名为value_type,然后放到红黑树的第二个参数当中
typedef pair<const Key, T> value_type; typedef rb_tree<key_type, value_type, select1st<value_type>, key_compare, Alloc> rep_type;- 1
- 2
- 3
- 也就是上图右侧上角的红色图,这两个东西组合成了【pair】
- map自动的把key设置为const,所以无论如何key都不能更改
- select1st是GNU独有的,其他编译器只是名字不同,功能上都是一样的

- 注意看最后的return,是
return pair.first也就是select1st的功能
8.3 multimap
- 与map差不多,只是是否可以重复
8.4 map独特的operator[]
- 如果我们要查找一个key,要返回对应的data,比如说key是327,就把红黑树当中第327个传回来,如果这个key不存在,327不存在,这个operator[]就会创建元素,放到那个key位置上

- 上述是怎么实现的呢?通过lower_bound()函数实现的
- 如果没找到327对应的,通过下面的insert()函数,插入一个最合适的进去;如果找到了327对应的,就直接传回327对应的即可
9 深度探索hashtable

- 空间足够时,直接 N = s i z e o f ( T ) ∗ 2 32 N = sizeof(T) * 2^{32} N=sizeof(T)∗232,所以假如编号是32767,那么空间大直接放到32767这个位置上面去
- 空间不足够时,就进行内存压缩,使用 H % M H\%M H%M进行放置(M是空间的内存),这样就会出现一个问题,就是余数会相同,导致两个或者多个元素都被放在同一个位置,发生碰撞
- 发生碰撞就要拉开,放到别的地方去
- 所以就先来先放,然后后来的可能放后面一位,再后来的又放后面一位

- 因为先前那样碰撞后的放法,不合理,导致越到后面计算量就越大
- 所以现在就直接把元素相同的用链表串起来,也就是hashtable
- 因为串的是链表,所以不能太长
- 太长的话,就需要打散,这就是散列表hashtable
- 什么时候需要打散呢(元素个数比篮子(篮子指的是引出链表的那个方块)的个数要多,就需要打散)
- 怎么样打散?就是把篮子增加两倍,增加两倍之后,就要重新计算
- 都会采用素数当中篮子的个数,最开始初始化的篮子个数是3,然后不断扩大两倍,找扩大两倍后左右的素数,3扩大后就是6,找素数5
9.1 hashtable源代码
template <class Value, class Key, class HashFcn, class ExtractKey, class EqualKey, class Alloc = alloc> class hashtable;- 1
- 2
- 3
- 一开始需要给出6个模板参数
- value和key就是rb_tree当中的value和key
- 这是一个幕后英雄和红黑树一样,都是提供底层支持
- hashfcn是什么呢?刚刚说每一个对象有一个编号,那么这个对象怎么折射成号码和编号呢,就是对应这个hashfunc来对应成编号,这个func可以是仿函数,函数对象等
- hashfunc算出来的是hashcode,就是之前例子当中的余数
- extractkey,就是从一包东西中取出key
- equalkey,要告诉排序比较的规则
- alloc就是GNU那个最后的分配器

- 一个hashtable当中有多少data?
private: hasher hash; key_equal equals; ExtractKey get_key;- 1
- 2
- 3
- 4
- 这三个就是模板参数当中的hashfcn,extractkey以及equalkey所创建出来的对象
public: typedef Key key_type; typedef Value value_type; typedef HashFcn hasher; typedef EqualKey key_equal;- 1
- 2
- 3
- 4
- 5
- 在这里使用typedef把类型名称换掉了
- 果然,之前扩大两倍就在猜想篮子是不是vector,没想到真是vector底层实现的
vector<node*,Alloc> buckets; size_type num_elements;- 1
- 2
- 实际大小一开始那上面hash + equals + get_key是3,然后vector当中有3个指针,12字节,然后size_type那里也是4个字节,所以综上加起来为19,调整为4的倍数,为20,所以每个hashtable的字节数为20
template <class Value> struct __hashtable_node { __hashtable_node* next; Value val; };- 1
- 2
- 3
- 4
- 5
- 6
- 因为碰撞之后,需要再挂另外一个节点上去,所以node这里是这样设计的
- GNU是单向链表,VC是双向链表

- cur是指向节点,而不是指向篮子,这里画错了
- ht是指向hashtable本身的迭代器
- 困扰是现在需要指定6个模板参数,该怎么进行使用?


- 很多特化版本
- 如果面对数值,hashfunc该怎么设计,就把数值当做编号,直接return x

-
所以在C++标准库当中,有这种设计好的hashfunc
-
也可以自己写,如上方的特化版本
-
标准库没有提供hash
-
hashcode算出来该落在哪个篮子上呢
-
例如一百个篮子,编号103,那么余数除下来就是落在3号篮子
-
在标准库当中看看是怎么样表现的,如下

- 看最后都是
return hash(key) % n,所以确定落在哪个篮子都是通过取余数来判断
10 深度探索unordered容器
- 以hashtable为底层支持

- C++11的新标准,原来叫做hash,现在变为unordered
- 使用上都与hashmap,hashset之类的都一样,只不过名字改变了
- 之前说过,元素的个数一定小于篮子的个数

- 如图,篮子个数62233,元素个数为32768
Level 2:深入认识C++标准库算法
0 算法是什么东西?
- 算法其实是一个function template

- 如图的右下角,标准库当中的算法都长成那个样子,但是有一些尚未定义出来的类型
- 算法看不到容器,所以必须有迭代器,因为迭代器是容器与算法之间的桥梁,而且同时算法要是知道容器的一些类型,一些性质,算法肯定能最快的找到解决适应这个容器的方法。这样虽然算法看不到容器,但是可以通过迭代器来实现
- 每一个算法肯定有之前的两个迭代器
- 第二个算法模板当中,有第三个参数,打个比方,在写sort的时候,第三个参数可以传入我们自己制定的规则(比如比大小该怎么比,按照什么来比),就是仿函数
1 iterator
1.1 iterator_category

- 容器所提供的iterator_category并不是普普通通的1,2,3…而是这几个类
- tips:一个技巧,就是定义临时对象的时候,后面直接添加小括号()

- 这些函数的名称都相同,是函数重载
- 这五个函数,会根据传入参数的类型,自动去寻找到该调用的函数,这就是为什么iterator_category并不是普普通通的1,2,3…而是这几个类
1.2 istream_iterator & ostream_iterator
- 这两个容器,产生的方式与上面的不一样,从技术上来说,这两个更像是适配器
- 输出的结果是input和output

- 从两个模板参数到四个模板参数
- 在GNU4.9当中,出现了一种很奇怪的形式,看istream_iterator的父类,父类没有data,function,只有一些typedef,这样是为了子类把这些typedef给继承下去

- 同istream_iterator
1.3 typeid
- 通过typeinfo打印出类型的名称

1.4 distance() & advance()
1.4.1 迭代器的分类对算法效率的影响

- 其中首先需要知道的是distance()这个函数,这是计算两个指针之间的距离
- 在这里,distance()接受两个参数,一个是first,一个是last
- 这两个之间的距离是怎么样的呢?直观想法是进行相减
- 但这是连续空间的做法,所以distance在这张图里面,会去调用上面的两个函数_distance
- 其中分为连续空间以及非连续空间
- 连续空间直接相减,就对应了第二个_distance函数,不连续空间就使用第一个_distance,就是看一步一步走过去要走多少步,这样算,所以有一个while循环
- 问题:两根指针的距离到底使用什么type?
- 在迭代器iterator当中,有五个相应的模板参数,其中一个是difference_type
- 所以可以通过traits来问,问他传进来的iterator他的difference_type是什么类型的
- 这个advance()算法也是一样,同理上方的distance()算法

- 也是把iterator结果的类型丢给traits去计算
1.4.1 思考
- 现在有一个问题,之前说了迭代器的分类,是由类而不是由单纯的1,2,3…来表示的,且类这里还有类继承的关系,如下图所示,为什么要这样构造呢,为什么要采用这种形式呢?
- 如下,现在假如调用distance()算法,traits算出来的类型是farward_iterator,而distance()当中有两个函数,两个函数的参数分别是input_iterator_tag以及random_access_iterator,也就是说,在下图当中,只有第一个和最后一个两个迭代器,但是现在是forward_iterator,所以可以使用类继承的关系,类继承就是is a 的关系,然后forward_iterator就是继承了input_iterator,所以选择这个函数参数就直接调用第一个_distance()函数即可,这就是采用类继承的好处
- 所以说虽然这里只用到了两个iterator的版本,但是这4个随便哪一个进来都能找到对应的_distance()

- 以上就是两个很基础的算法,迭代器对算法的影响
1.5 copy()
- 来源端到目的端
- copy()一定是有头尾两个指针指向来源端,尾巴那边只有有一个起点就好了,这样就能一个一个复制过去了,所以一共需要三个参数
- 实际上没这么简单

- 如上,copy在内部不断地做检查,检查传进来的指针,看看是泛化特化还是其他特化的指针,就走对应的通道

- destroy()算法同理

1.6 算法对iterator_category的暗示
- 在template当中会出现类型,然后会提示你要输入什么参数类型

2 算法

- 算法包含在algorithm库函数当中
2.1 accumulate
- 很多算法都有多个版本,这是因为要适配不同的参数形式
- 如下图的accmulate有两个版本,一个多接受了一个运算,即binary_op的运算,两个操作数的
- accumulate第一个版本就是累加,提供一个初值把所有元素都加到初值上,再返回
- 第二个版本传进来的就不是单纯的加了,而是通过binary_op这个规则(例如仿函数,传进去,按照仿函数的规则进行),通过后再进行累加

- 这些黄色油漆的就是仿函数
- 根据参数的个数来使用对应的accumulate函数
- 注意运算符操作符重载,在myobj这个结构体当中,就是重载了小括号,然后呢对应到binary_op的()当中,这个()就是会进行对应的操作

2.2 for_each

- 在一段范围,对你得元素进行操作
- 这个函数,每一步都放一个f函数,进行作用的操作
for_each (myvec.begin(), myvec.end(), myfunc); cout << endl; //output: 10 20 30 for_each (myvec.begin(), myvec.end(), myobj); cout << endl; //output: 10 20 30- 1
- 2
- 3
- 4
- 5
2.3 replace,replace_if、replace_copy

- 只要看到算法后面有if,就代表要给他一个条件
2.4 count、count_if

- 以下容器不带count()成员函数
- array
- vector
- list
- forward_list
- deque
- 以下容器带count()成员函数(这是关联型数据库,通过key找value,所以有count)
- set系列
- map系列
- unordered系列
- 其余的容器都带有count()成员函数
- 就是循环+判断组成了count
- count_if就是自定的条件
2.5 find、find_if
-
判断条件,
while(first != last && *first != value)即可判断 -
与count同理,因为关联型数据结构找的更快,所以有find和count
-
以下容器不带find()成员函数
- array
- vector
- list
- forward_list
- deque
- 以下容器带find()成员函数(这是关联型数据库,通过key找value,所以有find)
- set系列
- map系列
- unordered系列

2.6 sort
因为关联型容器都会排序,所以没有sort。

- 同样可以添加自己的准则进去,也就是仿函数
- sort逆序排序可以使用rbegin以及rend来进行排列

- 看rbegin和rend所拿取的元素内容
2.7 binary_search
- 必须先进行排序

3 仿函数functors
- functors是六大部件当中最简单的一种,唯一有可能写到标准库当中去的
- functors只为算法来服务

- functors如上图,看关系,只是为算法服务的
- 当算法需要独特的准则的时候,比如排序默认由小到大,但是你想从大到小,这时候就要用到functors

- 上图黄色的部分是什么?
- 可以看到每一个标准库所提供的仿函数都有一个继承关系,注意看那个单吗,冒号:
- 上方继承谁呢?binary_function

- binary的就是两个操作数
- unary的就是一个操作数
- 回答问题,上方两个仿函数data大小是多少?
- 理论值为0,但是实际上为1

-
因为less是比大小,所以肯定优先继承有两个操作数的binary_function
-
然后直接继承了三个typedef,这三个理论上是没有大小的
-
这样既没有增加了子类的大小,又白嫖的三个typedef,何乐不为?
-
STL规定每个adaptable function都应该选择适当的继承者而继承之
-
仿函数能否被修改?(被修改,被适配,adaptable)
-
如果你希望你的仿函数被修改,被适配的时候,就必须选择一个最适合的进行继承

-
这种关系就类似算法和迭代器,算法问问题,迭代器回答问题;这里是adapter问问题,functors回答问题,关系类似
-
比如上方的
Operation::result_type,问问题了,问这是什么,所以仿函数就回去找,发现自己本体没有,就去找继承的父类,发现在继承的里面有typedef Arg2 second_argument_type;,所以说,怎么样去回答问题呢?就是仿函数的可以适配adaptable条件就是继承 -
所以说,你想让自己写的functors与STL水乳交融的进行融合的话,就必须选择一个适当的进行继承,也就能去适配器去修饰去改造
- 我们自己写的,但是我们自己写的没有继承,也就是没有融入STL体系结构
- 有继承的和无继承的有什么区别?
- 这是标准库当中的三大类仿函数
- 小括号必须进行重载,因为到时候会调用这个小括号
- 运算符那些为什么要重载,为什么符号也要设置成一个函数?
- 因为你要把这些动作传到算法里面去,告诉他这个动作,所以要写成函数或者仿函数,其拿到这些东西才能做一系列操作

- 以上三个是GNU C++独有的仿函数
- 这些曾经在前面出现过,在弹散列表hashtable
- select1st是为了从key和data合二为一成value的地方取出key(作用于散列表)
- 因为select当中传入的参数都是pair
- 在set的时候,使用过identity
- key和data合二为一成value,所以1st就是key,2nd就是data
3.1 新旧版本之间的对比

- 都改名称了
3.2 sort的仿函数

- 第一个sort并没有传入第三参数
- 第二个传入了第三参数,myfunc
- myobj函数对象也可以当做第三参数
less这是一个类型,我们要创建一个对象,这里直接创建了一个临时对象,这个操作非常常用,就是类型之后直接加上一个小括号- 下面的
greater同理
4 适配器Adapters
- 类似变压器
- 其实adapter是一个换肤工程,就是小小改一下,比如说把接口改一下,三个参数变两个参数,把名称改一下之类的功能
- 要抓住关键,其实adapters要改造某一个东西,比如A把B改造,A就代表B了,A就要面对给大家使用,大家就不会看到B,而是会看到A,但是A自己所要做的一些事就会交给B去做,因为B就是本来就有的好东西,所以A身为一个桥梁是使用者和隐藏在幕后的B的幕后英雄
- A怎么取得B的功能?
- 要么继承要么拥有/内含
- A继承B,那么当然可以使用B的所有资源,A内含B,肯定可以使用
- 在以下的adapter当中,都是内含的方式
- 仿函数的adapter,就是adapter内含了functors;iterator的adapter,就是内含了iterator,容器的adapter,就是内含了一个容器,抓住这个关键点
- 算法想知道一系列问题都得问迭代器

4.1 容器的adapter

- 如图,stack和queue当中,都是内含了deque这个容器
- 假如deque有100个函数,现在只开放给stack和queue的这几个成员函数,这算是一种改造
- 同时,原来叫做push_back()的成员函数,现在叫做push(),这也是一种改造,名称改变了
- 就是要把内含的容器换一种风貌
4.2 binder2nd

- 如上图count_if,要看看计数的条件是什么,就是传入的第三个参数所代表的那个
- 刚刚在仿函数那边也说了,less是一个标准库提供的仿函数,然后当做第三个参数进去,原先的less只是x和y进行比较,现在我不,我想让x与40进行比较,所以现在用bind2nd将第二参数进行绑定,此时是把第二参数也就是y绑定成40,这样就只会计数x和40进行比较
- 所以上方的bind2nd只是把比大小的东西修饰了一下
很奇怪的一件事就是,函数在被调用的时候才会指明参数,现在还没有被调用,就已经把参数绑定成40了,这是为什么呢?
- 我们最大的困惑是以为在
(less这里调用,其实没有(), 40) - 刚刚说过,adapter想改造谁的话或者想修饰谁的话,adapter会把这个谁给包进来
- 现在这个
bind2nd就是通过辅助函数创建了binder2nd,所以真正的幕后英雄就是binder2nd - 以下的adapter都会有一种一致的形式,就是有个class,比较复杂,比较大致的主题,另外会有一个辅助函数,这个class的主体不太好用,所以会在标准库当中另外准备一个辅助函数,这样会好用多了
- 比如说这个
Operation op;什么提示信息都没有,怎么能推出了这是什么?靠辅助函数推出来 - 首先,红色的less会被记录在op当中;后面的40会记录在下一句的value当中
- adapter去修饰什么就要表现成什么的样子,比如修饰functors就要表现出functors的样子
- 所以就有了右下方的重载小括号()的语句
- 所以以上修饰好之后,交给count_if
- count_if就会去逐一去根据我们所设置的条件去对比
if (pred(*first)) - 而所谓你给他的条件,就是
bind2nd(less(), 40);

- 如图,传进来的
bind2nd(less这个跟随bind2nd的这个小括号,通过operator()这个函数进行重载,所以会执行相应的操作,在重载这里,才把op和value拿起来用,才真正的去调用op,op就是红色的less(),并且把value当做第二参数,即40,x就是count_if当做的for loop(), 40) - 打通一个观念,原本只是把参数全部都继起来,内含进来,也没有什么绑定参数什么事情,到后头被调用的时候,才拿出来用,才来谈绑定第二参数的事,这就回答了之前所问的“很奇怪的一件事就是,函数在被调用的时候才会指明参数,现在还没有被调用,就已经把参数绑定成40了,这是为什么呢?”

- 主角是类模板,你要指定模板参数,模板参数是operation,这里的模板参数是
less的类型,这个是个临时对象,所以类型就是() less,所以这个类binder2nd这个要推类模板参数,就不太好用,就打算不直接用这个了,标准库提供一个辅助函数,就是bind2nd

- 名字bind2nd和binder2nd不太一样
- 所以现在对外界的接口是bind2nd,然后less和40是传给红色的op和上方红色的x,然后bind2nd这个辅助函数去帮忙创建binder2nd这个类的对象
return binder2nd又是type_name直接加上小括号产生临时的对象,所以要知道小括号是函数调用还是创建对象(op,arg2_type(x)); - 之前说过,创建对象要指定模板参数,
binder2nd这里要知道operation,现在辅助函数会帮我们去推,去写 - 怎么帮你写呢?借助函数模板可以做实参推导的特性,所以之前count_if当中的
lee是什么东西,放到辅助函数当中,编译器就会给你直接推导出来,就把这个type作为模板参数即可,我们也不需要去推,这就是辅助函数的价值()

- 把参数放进去,就会调用类当中的构造函数,即调用构造函数的两个参数
- 构造函数做什么事?把x记录到op里,把y记录到value里去
- 要把操作实参都记下来
- 现在就把这些东西丢给count_if,count_if也把这些记下来
- count_if的第三参数pred,就是整个bind2nd的东西
- count_if用一个循环,不断的去调用pred,pred就是binder2nd的对象,就调用起小括号重载(),然后就把这边存起来的op和value拿起来用,这里value绑定了第二实参,这样,整个流程就这些

4.2.1 思考
之前所说,在bind2nd当中,我们想检查的是与40有关的是整数,所以绑定的第二实参一定是整数,帮检查出来是好事,如果没检查出来,就是error,那么怎么检查出来呢?靠的是以下灰色的这些东西

- 参数传给辅助函数之后,开始问问题,adapter开始问,operation,我请问你,你的second_argument_type是什么类型,看40能不能转换成这种类型(
arg2_type(x)),相等不相等,这里就是在做判断,如果不能转换,这里就会检测出来 - 所以operation就是来问这个问题

- 同时,如果binder2nd还想被adapter的话,那他还得继承,这里就是继承了unary_function
- 综上,adap就是把东西内含/继承起来,以被后面使用
4.3 not1(函数适配器)
- not1在这里继续修饰右边的东西,其实右边的刚被bind2nd修饰过了
- 像乐高积木,一点一点套
- 本来是小于40,现在就是不小于40,也就是大于等于
- not1传进来就会进行实参推导
- 与原来结果相反传进去即可
4.4 bind

- 以上都统一成bind
- bind是C++11提供的一个适配器,他可以做什么?
- 可以绑定如下东西


- 拿这个测试3,4两个操作
- bind绑定什么,传回来的就是什么
- bind在绑定class里面的东西的时候,比如说成员函数
member functions, _1这里的_1是一个占位符- 由于要使用占位符,就要使用
placeholders - 注意看下方第一个绑定对象,
bind(my_divide, 10, 2),第一个参数是需要绑定的对象,然后2,3参数就是my_divide当中的形参的实参,所以直接return 5了 - 绑定好之后要换名字
auto fn invert bind (my_divide,_2,_1);cout- 注意这两行代码,这里就使用了占位符,并且_1表示第一实参,_2表示第二实参
- 然后因为只是占位,没有赋值,所以下面的cout当中,10是第一实参,2是第二实参
- 所以传(10, 2)进去,得到的是(2, 10)

-
auto fn_rounding bind(my_divide,_1,_2); -
cout << fn_rounding(10,3) <<'\n'; -
注意看这两行,可以发现bind指定了一个模板参数
-
只会指定一个模板参数,这是为了规定他的返回类型,return_type
-
加了这个模板参数就是改变返回类型
-
如果绑定的是member function的话,有一个看不见的实参,这个实参就是this
-
double multiply(){return a * b};//member function其有有個argument:this -
看上方的成员函数,看起来没有形参,实际上有一个this
-
所以
auto bound_memfn = bind(&MyPair::multiply,_1); -
cout << bound_memfn(ten_two)<<'\n'; -
所以那里有一个_1占位符在占位这个this
-
也可以不用_1,直接绑定一个确定值,输出就不用指定了,如下
-
auto bound_memdata = bind(&MyPair::a,ten_two); -
cout << bound_memdata() << '\n'; -
也可以绑定数据成员
-
auto bound_memdata2 = bind(&MyPair::b,_1); -
cout << bound_memdata2(ten_two) << '\n';
利用新的适配器重写bind2nd,
auto fn_=bind(less(),_1,50);
cout << count_if(v.cbegin(),v.cend(),fn_)<
记住,这个bind初始化之后要给一个名字,然后拿名字传入别的地方进行使用4.5 reverse_iterator
- 以上提到的适配器,都是改造函数/仿函数,什么bind2nd,not1之类的,都是仿函数的适配器
- 现在开始改造迭代器的适配器

- 排序默认是升序排序,但是给一个逆向的迭代器就是降序排序
- 要取得逆向的头,其实就是正向的尾巴
- 相反,逆向的尾巴就是正向的头

- 为了实现降序排序,迭代器做了一个reverse的动作
- 还是那个共性,适配器要修饰什么,那么其内部就得有什么
- 修饰iterator,其内部就要有iterator

- current就是iterator
- 最关键是取值,正向是往右取,逆向就是对正向退一格取值
- 比如正向下一个是取索引3,则逆向就是退一格取索引2
reference operator*()const Iterator tmp=current;return *--tmp;- 如上代码就是实现
- 逆向的++就是正向的- -
- +n就是-n,正向逆向相反
- 记住适配器的共性!!!
4.6 inserter
- 准备了一个数组,预留了七个位置,想做copy动作
- 关于copy,有来源端的头尾,以及目的端的头

- copy最根源的源代码就是那个模板
- 所以是把来源端当中的一个一个assign到目的端去
- 因此,才刻意保留7个位置
- 让7个元素赋值过来的时候,才有空间
- 如果没保留这7个位置,或者保留的不够多,当赋值进来这个copy是不管的,其不知道目的端的空间是否合理合法
- 所以在目的端保留的不够多,赋值赋到了不该赋的地方去,就会出现错误,现在的inserter这个动作不用担心这个错误
- 现在两个容器,想把bar给放到foo的元素3之后,但是copy是赋值,做不到插入的结果
- 该怎么进行插入呢,采用inserter(),把目的端的迭代器,改成inserter()的操作
- 现在的难处就是,在copy的源码中,已经写好了内容,如何把assign操作改成inserter()操作呢?
- 操作符重载

- inserter()那里也有辅助函数可以调用
- 太巧妙了,一个写好的东西还能改变其形式

- 把copy源代码当中的=号进行重载
- 达到了插入,inserter()的作用
- 也就是接管了赋值操作
4.7 istream_iterator & ostream_iterator
4.7.1 ostream_iterator

- 这两类迭代器适配器istream_iterator & ostream_iterator都不属于上述的三大类别

- 现在目的端选择的是ostream_iterator这个迭代器
- 上图,把迭代器绑定到一个装置上
std::ostream iteratorout_it(std::cout, ","); - 这个迭代器有两个参数,第一个参数绑定了cout,第二个参数还可以放一个字符串
- 字符串做什么用呢?做分割符号用,放什么都可以

- 源代码当中的*out_stream就是cout
- 然后value就是*first
4.7.2 istream_iterator

- 绑定了cin,想象成键盘进行输入
- 使用istream_iterator定义了两个对象
std::istream iteratoreos;//end-of-stream iterator std::istream iteratoriit(std:cin);//stdin iterator
- 看第二行代码当中的cin,想必这个cin会被适配器给继下来

- 如图,分别调用构造函数,一个没参数的,一个有参数的
- 有参数的传进来是cin,cin就是上图方框中的&s,这个s在源代码当中又是什么呢?
- s是
basic_istream,这东西即为cin祖先,不一定就是cin,其包含了cin - s被继下来之后,马上做一个动作,
++*this; - 然后这个++,看下方源码的运算符重载,触发了重载条件
istream_iterator<T,charT,traits,Distance> &operator++() { if (in_stream && !(*in_stream >> value))in_stream = 0; return *this; }- 1
- 2
- 3
- 4
- 5
-
这个++有什么用?
-
如果in_stream有东西了,而且
(*in_stream >> value)等待输入一个数值放到value当中去,in_stream就是cin -
也就是说,当你创建一个对象,cin就被继起来,而且++,做上方的动作
-
所以这里就打进来一个数值,
std::istream iterator,什么值呢?就是doubleiit(std:cin);//stdin iterator -
这个double就是源代码当中的
T value,所以要输入一个double -
输入完毕后进行判断,看是否等于结束符号,
if (iit != eos) value2 = *iit; -
判断结束就进行取值

- 注意看这个运算符重载,重载*号,就是直接return value
- 所以这两行,就相当于cin输入,再return value

- 例子2:copy

- 第一行程序和上一页一样
- copy就是把刚刚创建好的两个作为来源端,再指定一个成目的端
- 并且目的端还包装成inserter(),就是一个adapter,就是可以把赋值动作,变成安插的动作
- 现在我们希望copy不断的从cin读操作,读data,把读到的数值放到我们的目的端
- iit绑定了cin
- 在创建这个iit对象的时候,就已经开始读第一个数据了

- 所以在
*result = *first;这里,就已经开始return了,不需要读了 - 然后下方的++first,就做到了读一个传一个的操作

- 所以非常巧妙,同一个copy搭配不同的adapter,会有不同的形式表现
5 总结
使用一個東西,
卻不明白它的道理,
不高明!Level 3:通用技术
勿在浮沙築高台
0 一个万用的hash function
- 所谓的hash function就是喜欢所产生的hash code越乱越好,不要重复
- 你要写一个hash function,你的形式该是怎样?
- 现在,打算将Customer当成一个元素放入容器,所以要为这个类写hash function

- hash function有两种形式,一种就是单纯的写为一般的函数
- 这个函数当然就是接受customer
- 至于里头怎么设计,这是后面的事情
- 另一种形式,就是写成成员函数的形式
- 两种形式

unordered_set- 成员函数形式就要写出hash function在哪里,是什么形式
unordered_set- 第二种形式搭配容器来写的话,就有点复杂,第一个模板参数是元素的类型,第二个模板参数是函数类型,还得把函数的地址放进来

- hash function是个空的类,但是对特殊类型有特化
- 上方建立了临时对象,当做函数来用,传入参数
- 但是这样穿在同一个篮子上的元素就会多,碰撞多,造成查找麻烦
- 改进

- 把元素的几个部分一个一个地放进去,有几个就放几个
- 但是发现hash_val重载的有点多,那么到底是调用哪个hash_val()呢?

- 上图这个1版本,其接受的模板参数是任意个,
- 第二个版本呢?模板参数是T,模板参数也是…,代表任意多
- 第二个版本与第一个版本不同的是,在于函数的参数为size_t&,而第1个函数当中是const Types&
- 所以在调用的时候,会根据满足哪一个状况来看调用哪个
- 第3个版本,函数参数,包含了size_t&,以及constT&
- 那么这个函数应该调用哪一个呢?
hash_val(c.fname,c.Iname,c.no);应该调用第1个版本 - 反正就是本来传进来n个种子,把n个种子分为1 + (n - 1),然后再把n - 1在拿出来,分为 1 + (n - 2),这样不断进行下去,就能一次一次取出元素,作为种子的变化
- 注意看版本3,模板参数非无限,所以当取到最后一个元素的时候,就会落到版本3

- 按照上面,做奇奇怪怪的运算,算出来的就是hash code,乱七八糟
- 当然,hash就是要越乱越好
- 0x9e3779b9是什么?
- 黄金比例


-
篮子个数永远大于元素的个数
-
刚刚说明的hash_function除了之前的两个形式,现在还有个形式3,如下


- string的特化版本
1 tuple
- 一堆东西的组
- 这是标准库的东西
- 就是你要多少东西,元素,可以任意的指定要多少元素进去
- 这些元素可以是任意的类型
- 如下,tuple的用法

- 拿出元素使用
get<0>(t1)这样的语句 - 还可以进行比较
- 为什么输出是32呢?无法理解,理论是28,会不会是空class占呢?空class理论上是0,实际上是1,然后4的倍数,就是4,28+4=32?
- 不会,不应该,因为单独存在,就是1,但是被继承,就是0,所以不会是这样,无法理解
1.1 tuple的构造

- 这里又有参数量,数量可变的一种模板,任意个元素
- 注意看,tuple会继承自己
- 一行是
- 接着递归,就是不断减少一个
- 比如原本5个成分,接下来就是4个成分

- 由于会自动递归,就会一再一再地继承
- 如上图,右上角
- 当为0的时候,就是一个特化版本,第二行代码
- head()传回第一个成分值m_head
- tail()传回尾部那一块(除去head),tail会得到父类成分的起点

2 type_traits
- 在默认情况下,类型都是重要的

- 特化和偏特化当中,类型都不重要
_type_traits通过这个去问问题::has_trivial_destructor
2.1 type_traits的用法


- type_traits太强了
- 萃取机能知道你写的类的细节

3 cout
- 首先cout肯定是一个对象,因为不能直接拿类来使用
class ostream : virtual public ios { // NOTE: If fields are changed, you must fix _fake_ostream in stdstreams.C! void do_osfx(); public: ostream() { } ostream(streambuf* sb, ostream* tied=NULL); int opfx() { if (!good()) return 0; else { if (_tie) _tie->flush(); _IO_flockfile(_strbuf); return 1;} } void osfx() { _IO_funlockfile(_strbuf); if (flags() & (ios::unitbuf|ios::stdio)) do_osfx(); } ostream& flush(); ostream& put(char c) { _strbuf->sputc(c); return *this; ostream& operator<<(char c); ostream& operator<<(unsigned char c) { return (*this) << (char)c; } ostream& operator<<(signed char c) { return (*this) << (char)c; } ostream& operator<<(const char *s); ostream& operator<<(const unsigned char *s) { return (*this) << (const char*)s; } ostream& operator<<(const signed char *s) { return (*this) << (const char*)s; } ostream& operator<<(const void *p); ostream& operator<<(int n); ostream& operator<<(unsigned int n); ostream& operator<<(long n); ostream& operator<<(unsigned long n); ..... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
class _IO_ostream_withassign : public ostream { public: _IO_ostream_withassign& operator=(ostream&); _IO_ostream_withassign& operator=(_IO_ostream_withassign& rhs) { return operator= (static_cast<ostream&> (rhs)); } }; extern _IO_ostream_withassign cout, cerr;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 直接看源代码,是一个类的实例化
extern说的是,这个变量可以被文件之外的东西使用,可以被外界使用,文件之外的都能看到他cout是_IO_ostream_withassign,那么_IO_ostream_withassign又是什么呢?_IO_ostream_withassign继承自ostream,ostream虚继承自ios,在虚继承中,有很多重载,如果是自己的类型也想用cout输出得像下面一样重载后写进标准库

4 moveable
4.1 moveable元素对vector速度能效的影响

- 如图,上面是放了moveable元素的,下面是没放moveable元素的
- 测试基准都是300万次
- 一个一个放进去,应该每个都是调用构造函数,现在理应是300万次构造函数
- cctor是拷贝构造函数,mctor是move构造函数
- 现在放的是有moveable元素的,所以调用的是move constructor,发现调用了719万次
- 下面同理,没moveable元素的,就调用copy constructor,也是719万次
- 时间差异也很大,movable元素的是8547,无moveable元素的是14235
- 解释一下,这里为什么是719万次调用构造函数因为这是vector,300万次元素用完之后,又要去找比原空间大两倍的空间进行搬移,所以需要719万次,拷贝过程就引发拷贝构造或拷贝赋值,所以多出这么多,如果刚刚指定800万的vector,就无须调用这么多
- copy和move copy


- 这里就差别巨大了,move快多了
4.2 moveable元素对list速度能效的影响
- 链表,就是你放300w个元素,就是300w个节点,没有什么扩充增长的

- 如图,300w个元素,300w个节点,就是300w个move constructor或者是300w个copy constructor
- 发现差距不大了
- 这后面都是节点,并没有哪个容器像vector一样,需要增长,并且需要扩容两倍的动作,所以后面的容器差距都没那么大
4.3 写一个moveable的class

- copy assignment就是深拷贝,不但把指针拷贝过来,还把指针指向的对象拷贝过来
- move与其他的差异只在下方

- 如图,reference of reference

- 这是move的动作,相当于拷贝完指针,再撤销掉原来的那个,再将拷贝指针指向原先的指针所指向的对象,这就是与copy深拷贝的区别,这是浅拷贝,但是浅拷贝很危险,因为原来的东西不能用了,所以你想原来的东西不使用了,才可以选择move copy

- 增加一个movable的东西就要增加对应的几块
5 测试函数
5.1 元素的move

- 现在测试vector,vector有五次调用,有movable版本也有non-movable版本
- 传进去,编译器会推导出相应类型
- 取出来,才知道要放什么元素进去
c1.insert(ite,V1type(buf));这里是一个临时对象,所以编译器知道放进去后原来的就不被使用了,所以自动调用movable的constructor- 如图,调用了719w次


M c11(c1);就是调用传统的copy constructorM c12(std::move(c1));就是调用move constructor,使用完,浅拷贝后,c1就废了- move之后就是废了,危险的
5.2 容器的move

- 这个函数,就是把来源端的起点和终点,拷贝到目的端
- 这就是vector容器的深拷贝,copy constructor

- 容器的move,就是把三根指针进行交换
- 做完之后,来源端与目的端指向相同的部分,这就很快了
- 所以看到来源端与目的端都指向相同的东西
- 很危险所以要确认来源的部分不要使用了,才能使用move
- string也是带有move的结构
Level 4:更新完毕,继续向前冲冲冲
C++标准库真是个宝库,受益匪浅
-
相关阅读:
“逗鹅冤”出续集,冒充老干妈员工诈骗腾讯案主犯被判刑12年
Python: 开始使用工厂模式设计
使用nexus上传jar包图文教程
电脑重做系统---win10
Java并发编程中的基础概念Monitor
[附源码]计算机毕业设计JAVAJAVA点餐系统
small synopsis - MYSQL for beginners
STM32 ADC介绍和应用
11/20总结报告
如何保证语音芯片的稳定性能和延长使用寿命
- 原文地址:https://blog.csdn.net/weixin_44673253/article/details/126650707