-
[模型]拉格朗日插值法

1 拉格朗日插值法的适用场景
拉格朗日插值法主要用于对样本点较少的数据的补全处理。对于 总体样本数较多的数据,可以在插值点的附近选取若干个合适的节点(不宜过多) 用于拉格朗日插值多项式的构建。
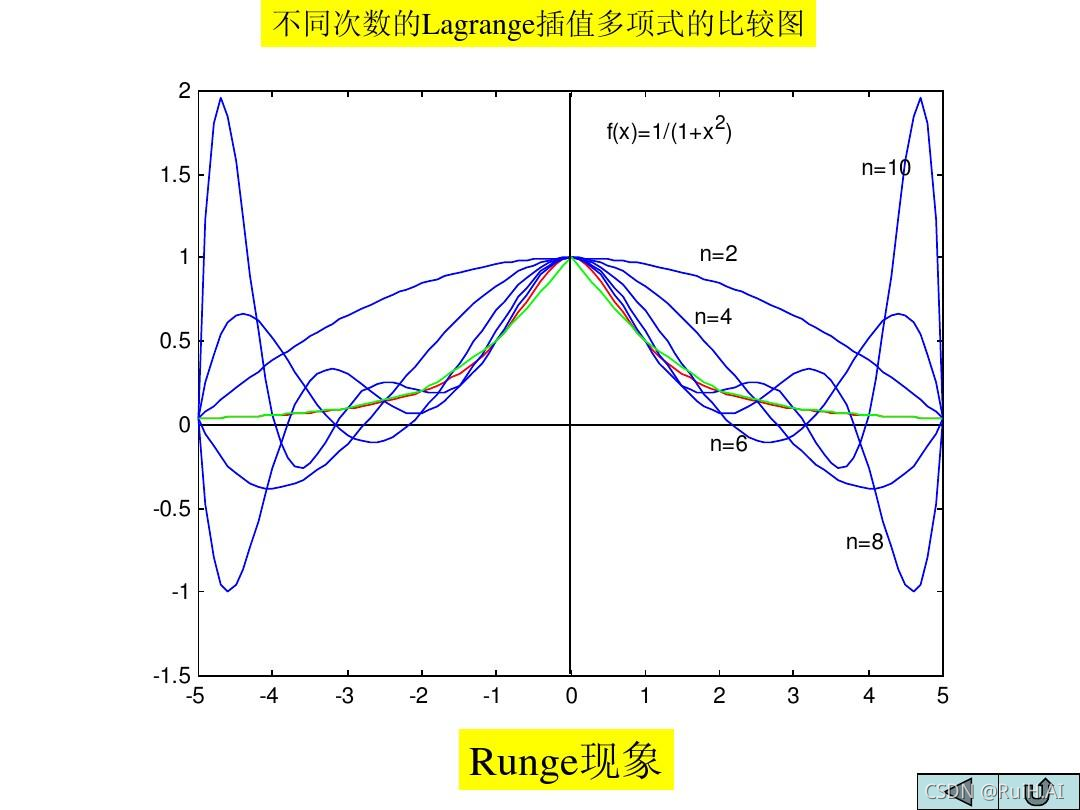
拉格朗日插值法主要用于对样本点较少的数据的补全处理,是由于当多项式的阶数较大时,可能会出现龙格现象。
龙格现象:
龙格现象是指,在区间内取等距插值点,运用插值多项式进行逼近时,逼近多项式在区间两端会发生震荡,并且随着插值次数增高,震荡现象也会严重,因而逼近误差也会增大。
[1]寿媛,陈豫眉.利用MQ拟插值解决高次插值所出现的龙格现象[J].洛阳师范学院学报,2016,35(05):6-9.DOI:10.16594/j.cnki.41-1302/g4.2016.05.002.解决龙格现象可以使用分段线性插值,利用分区间的低阶多项式对被插值函数进行良好地逼近。
2 拉格朗日插值法的基本原理
在插值点的附近选取若干合适的节点,构造一个简单的插值函数 y = p ( x ) y = p(x) y=p(x) ,要求构造的插值函数穿过选取的节点。在所选数据区间用插值函数 p ( x ) p(x) p(x) 的值作为原来函数 f ( x ) f(x) f(x) 的值,使得 f ( x i ) = p ( x i ) , i = 1 , 2 , 3 , ⋯ , n f(x_{i}) = p(x_{i}), i = 1, 2, 3, \cdots, n f(xi)=p(xi),i=1,2,3,⋯,n 成立。由此可见,插值法的实质是根据已知的节点数据或线图上某些已知点的数据构造一个既简单又能够保证精度的插值函数 p ( x ) p(x) p(x) ,并利用该插值函数快速获取原函数在对应位置的数据,这种利用若干节点来构造插值函数的方法称为拉格朗日插值法。
[1] 林昌华,杨岩.拉格朗日插值法在工程设计及CAD中的应用[J].重庆理工大学学报(自然科学),2013,27(12):34-37.
$y = p(x)$ $p(x)$ $f(x)$ $f(x_{i}) = p(x_{i}), i = 1, 2, 3, \cdots, n$- 1
- 2
- 3
- 4
3 拉格朗日插值多项式的构建
使用拉格朗日插值法对数据进行补全,一列一列数据进行补全。
对于原函数 f ( x ) f(x) f(x) ,已有给定的 n + 1 n+1 n+1 个取值点,分别为 ( x 0 , y 0 ) , ( x 1 , y 1 ) , ⋯ , ( x n , y n ) (x_{0}, y_{0}), (x_{1}, y_{1}), \cdots, (x_{n}, y_{n}) (x0,y0),(x1,y1),⋯,(xn,yn) , 其中, x i x_{i} xi 的取值为 1 , 2 , ⋯ , n + 1 1, 2, \cdots, n+1 1,2,⋯,n+1, y i y_{i} yi 为已有的数据值。由于原函数 f ( x ) f(x) f(x) 的任意两个取值点的 x i x_{i} xi 都互不相同,据此进行拉格朗日插值多项式的构建。
x i x_{i} xi 对应位置的 y i y_{i} yi 为缺失值,该 x i x_{i} xi 跳过
x i x_{i} xi 为已知数据对应的位置
x i x_{i} xi 如何取值根据实际情况而定


$f(x)$ $n+1$ $(x_{0}, y_{0}), (x_{1}, y_{1}), \cdots, (x_{n}, y_{n})$ $x_{i}$ $1, 2, \cdots, n+1$ $y_{i}$ $f(x)$- 1
- 2
- 3
- 4
- 5
- 6
- 7
第一步:根据已有给定的 n + 1 n+1 n+1 个取值点,求每个取值点对应的拉格朗日基本多项式 L j ( x ) L_{j}(x) Lj(x)。其对应的表达式为:
L j ( x ) = ∏ i = 0 , i ≠ j n x − x i x j − x i = x − x 0 x j − x 0 ⋯ x − x j − 1 x j − x j − 1 x − x j + 1 x j − x j + 1 ⋯ x − x n x j − x n L_{j}(x)=\prod_{i=0, i \neq j}^{n} \frac{x-x_{i}}{x_{j}-x_{i}}=\frac{x-x_{0}}{x_{j}-x_{0}} \cdots \frac{x-x_{j-1}}{x_{j}-x_{j-1}} \frac{x-x_{j+1}}{x_{j}-x_{j+1}} \cdots \frac{x-x_{n}}{x_{j}-x_{n}} Lj(x)=i=0,i=j∏nxj−xix−xi=xj−x0x−x0⋯xj−xj−1x−xj−1xj−xj+1x−xj+1⋯xj−xnx−xn第二步:根据已知的 n + 1 n+1 n+1 个取值点,使用第一步中求出的每个取值点对应的拉格朗日基本多项式 L j ( x ) L_{j}(x) Lj(x),求已知 n + 1 n+1 n+1 个点对应的拉格朗日插值多项式 L ( x ) L(x) L(x)。其表达式为:
L ( x ) = ∑ j = 0 n y j L j ( x ) L (x)=\sum_{j=0}^{n} y_{j}L_{j}(x) L(x)=j=0∑nyjLj(x)$n+1$ $L_{j}(x)$ $$L_{j}(x)=\prod_{i=0, i \neq j}^{n} \frac{x-x_{i}}{x_{j}-x_{i}}=\frac{x-x_{0}}{x_{j}-x_{0}} \cdots \frac{x-x_{j-1}}{x_{j}-x_{j-1}} \frac{x-x_{j+1}}{x_{j}-x_{j+1}} \cdots \frac{x-x_{n}}{x_{j}-x_{n}}$$ $L(x)$ $$L (x)=\sum_{j=0}^{n} y_{j}L_{j}(x)$$- 1
- 2
- 3
- 4
- 5
求出的拉格朗日插值多项式
5 拉格朗日插值法补全数据实现
5.1 Python 实现
代码参考自:
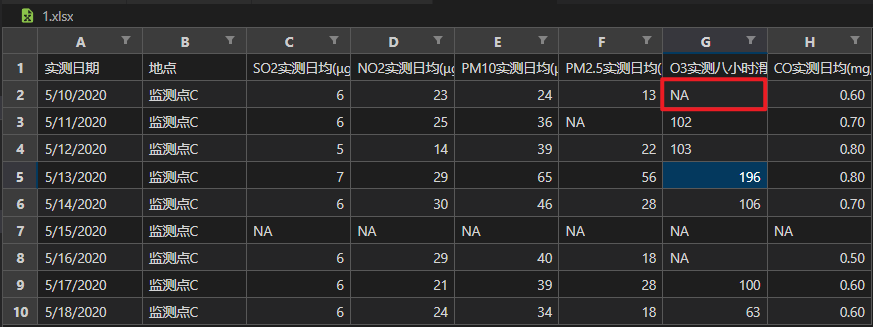
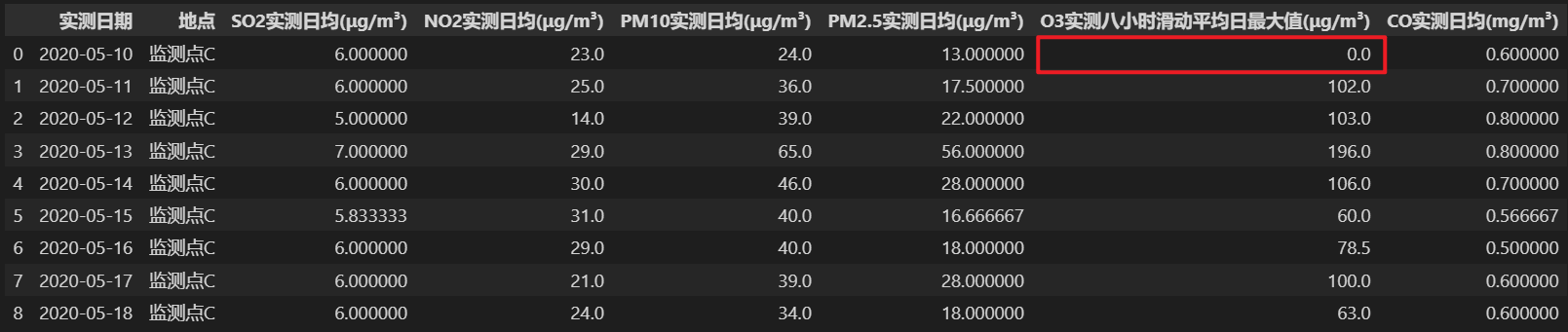
[1]赵莉,孙娜,李丽萍,崔杰.拉格朗日插值法在数据清洗中的应用[J].辽宁工业大学学报(自然科学版),2022,42(02):102-105+117.DOI:10.15916/j.issn1674-3261.2022.02.007.方法一:
1.对于表格第一行的缺失值和最后一行的缺失值无法进行填补
2.对于从第一行开始缺失的数据,且从第一行开始连续缺失的数据的个数大于k,无法进行缺失值填补。import numpy as np import pandas as pd # 引入拉格朗日插值法所需的方法 from scipy.interpolate import lagrange # 文件读取 data = pd.read_excel('./1.xlsx') # 字符串表示的空值预处理 def fun(x): if (x=='—' or x=='NULL' or x=='NA'): return np.nan else: return x data = data.applymap(fun) # 生成拉格朗日插值 def interpolate_columns(data_col, missing_val_idx, k=2): """ data_col: 需要进行缺失值填补的列 missing_val_idx: 数据缺失的单元格在该列对应的索引 k: 缺失值前后取值的个数, 默认为2个,防止出现龙格现象 return: 返回拉格朗日插值 """ # 防止取缺失值前后的非缺失值时下标越界 # 向缺失值前取值的个数,默认为 k f_k = k # 如果缺失值前还有的数值个数小于 k # 更改取值个数 if(missing_val_idx < k): f_k = missing_val_idx # 向缺失值后取值的个数,默认为 k b_k = k # 如果缺失值后还有的数值个数小于 k # 更改取值个数 if((data_col.size-missing_val_idx-1) < k): b_k = data_col.size-missing_val_idx-1 # 获取二者的较小值 if(f_k <= b_k): k = f_k else: k = b_k # 取出当前缺失值位置前后 k 个值 y = data_col[ list(range(missing_val_idx-k, missing_val_idx)) + list(range(missing_val_idx+1, missing_val_idx+1+k)) ] # 去除空值 y = y[ y.notnull() ] # 生成拉格朗日插值函数 f = lagrange(y.index, list(y)) # 计算并返回缺失值将要填补的数据值 return f(missing_val_idx) # 遍历数据表 # 每列 for i in data.columns[2:]: # 遍历每列中的每个单元格 for j in range(data[i].size): # 如果单元格为空 # 进行拉格朗日插值 if data[i].isnull()[j]: data[i][j] = interpolate_columns(data[i], j) data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60


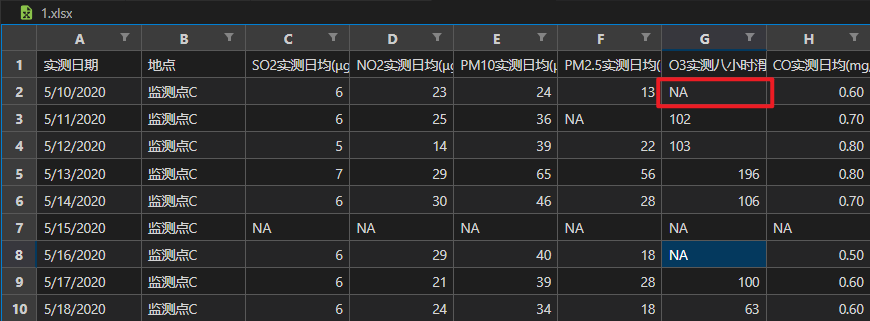
方法二:
对于从第一行开始缺失的数据,且从第一行开始连续缺失的数据的个数大于k,无法进行缺失值填补。且后面的缺失值的填补会受到前面无法填补的缺失值的影响(如果向前取值,无法填补的缺失值在取值范围内)。from cmath import isnan import numpy as np import pandas as pd # 引入构建拉格朗日插值多项式所需的方法 from scipy.interpolate import lagrange # 文件读取 data = pd.read_excel('./1.xlsx') # 字符串表示的空值预处理 def fun(x): if (x=='—' or x=='NULL' or x=='NA'): return np.nan else: return x data = data.applymap(fun) # 拉格朗日插值法填补缺失数据 def interpolate_columns(data_col, missing_val_idx, k=2): """ data_col: 需要进行缺失值填补的列 missing_val_idx: 数据缺失的单元格在该列对应的索引 k: 缺失值前后取值的个数, 默认为向前向后取2个, 防止出现龙格现象 return: 返回缺失值的拉格朗日插值 """ # 防止取缺失值前后的非缺失值时下标越界 # 向缺失值前取值的个数,初始值为 k f_k = k # 如果缺失值前还有的数值个数小于 k # 更改取值个数 if(missing_val_idx < k): f_k = missing_val_idx # 向缺失值后取值的个数,初始值为 k b_k = k # 如果缺失值后还有的数值个数小于 k # 更改取值个数 if((data_col.size-missing_val_idx) < k): b_k = data_col.size-missing_val_idx-1 # 从缺失值位置开始, 向前取 f_k 个数, 向后取 b_k 个数 y = data_col[missing_val_idx-f_k : missing_val_idx+b_k+1] # print(y) # 去除空值 y = y[ y.notnull() ] # 生成拉格朗日插值多项式 f = lagrange(y.index, list(y)) # 使用生成的拉格朗日插值多项式计算并返回缺失值将要填补的数据值 return f(missing_val_idx) # 遍历数据表 # 按列进行遍历 for i in data.columns[2:]: # 遍历每列中的每个单元格 for j in range(data[i].size): # 如果单元格为空 # 进行拉格朗日插值 if data[i].isnull()[j]: data[i][j] = interpolate_columns(data[i], j) data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
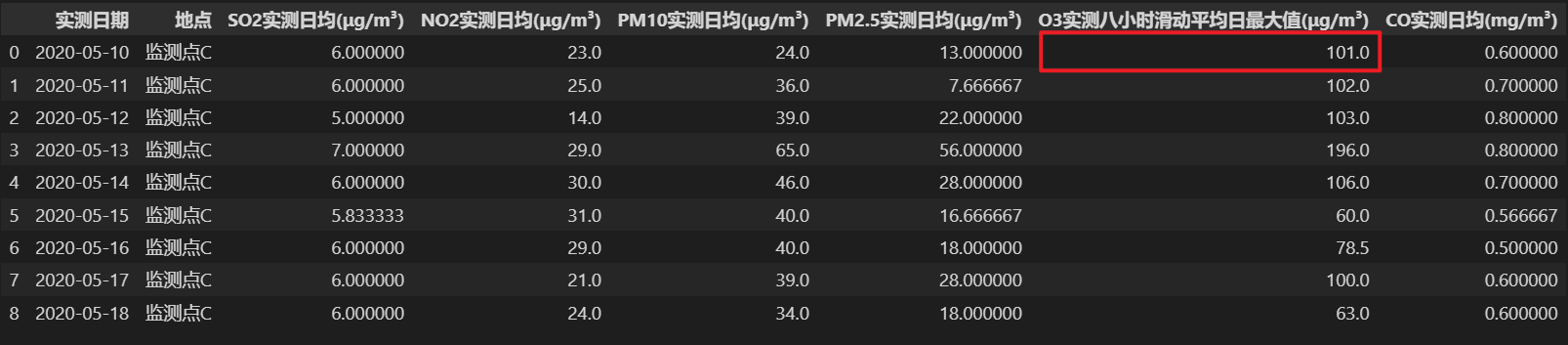
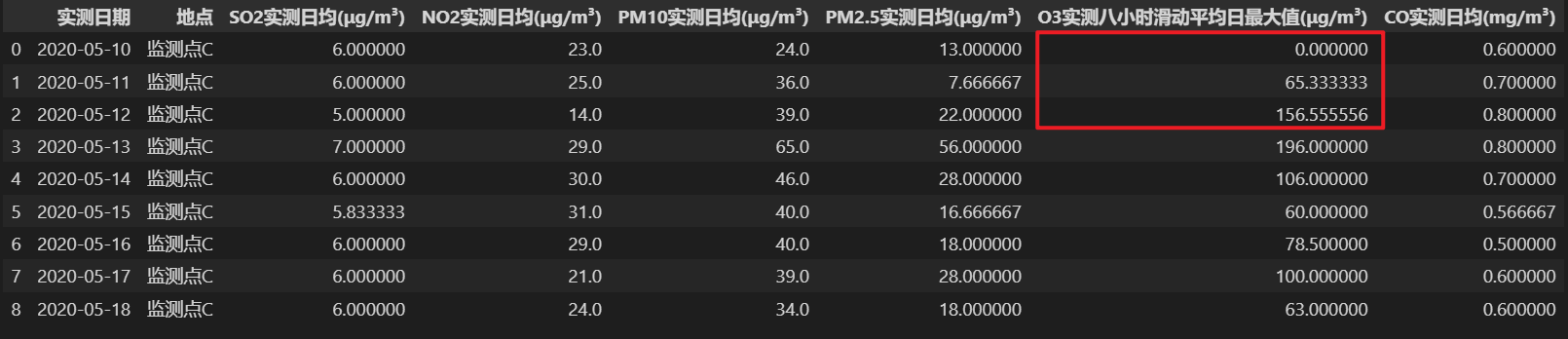
采用循环取值的方法,向前向后取非空值,直到数值个数达到指定的个数或循环遍历完数据集。会照成连续缺失的数值的填补值一致。
# 用于保存取出的非缺失值 y = [] # 开始向前取非缺失值的位置 start_idx = missing_val_idx # 已取非缺失值的个数计数 cnt = 0 while (True): # 已取非缺失值的个数达到指定个数 if (cnt == f_k): break # 当前将要取的值的位置 start_idx -= 1 # 达到数据集的边界退出 if (start_idx < 0): break # 当前值为空值跳过 if (isnan(data_col[start_idx])): continue y.append(data_col[start_idx]) cnt += 1 # 保证取出的数据值的相对位置与原来的位置一致 y.reverse() # 开始向后取非缺失值的位置 start_idx = missing_val_idx # 已取非缺失值的个数计数 cnt = 0 while (True): if (cnt == b_k): break start_idx += 1 if (start_idx >= data_col.size): break if (isnan(data_col[start_idx])): continue y.append(data_col[start_idx]) cnt += 1 print(y) y = pd.Series(y)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
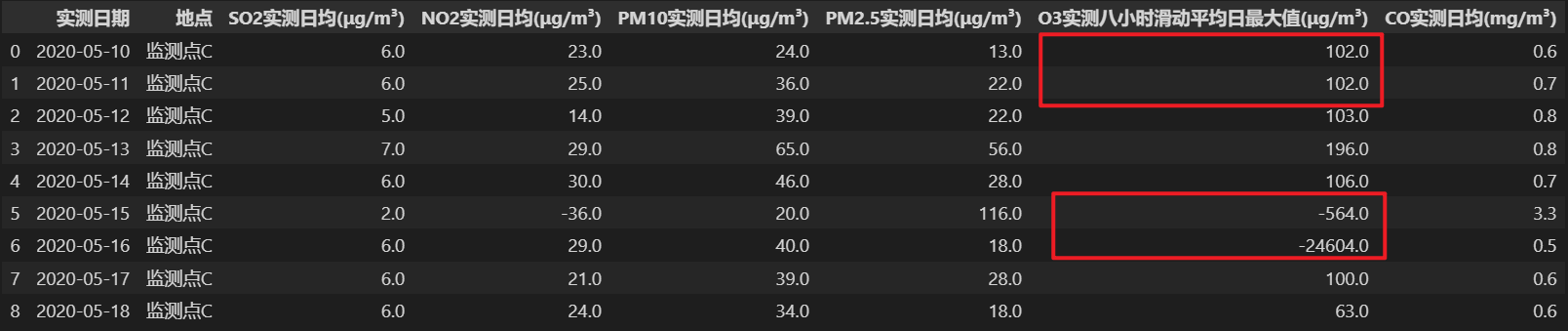
6 插值效果验证
选取部分正常数据(已有给定的未缺失数据)作为测试集,使用已构建的拉格朗日插值多项式对测试集进行插值,结合实际数据,对测试集的插值进行误差检测。选取均方误差(MSE)、均方根误差(RMSE)以及平均绝对百分比误差(MAPE)作为评价指标。
误差越小,插值效果越好。

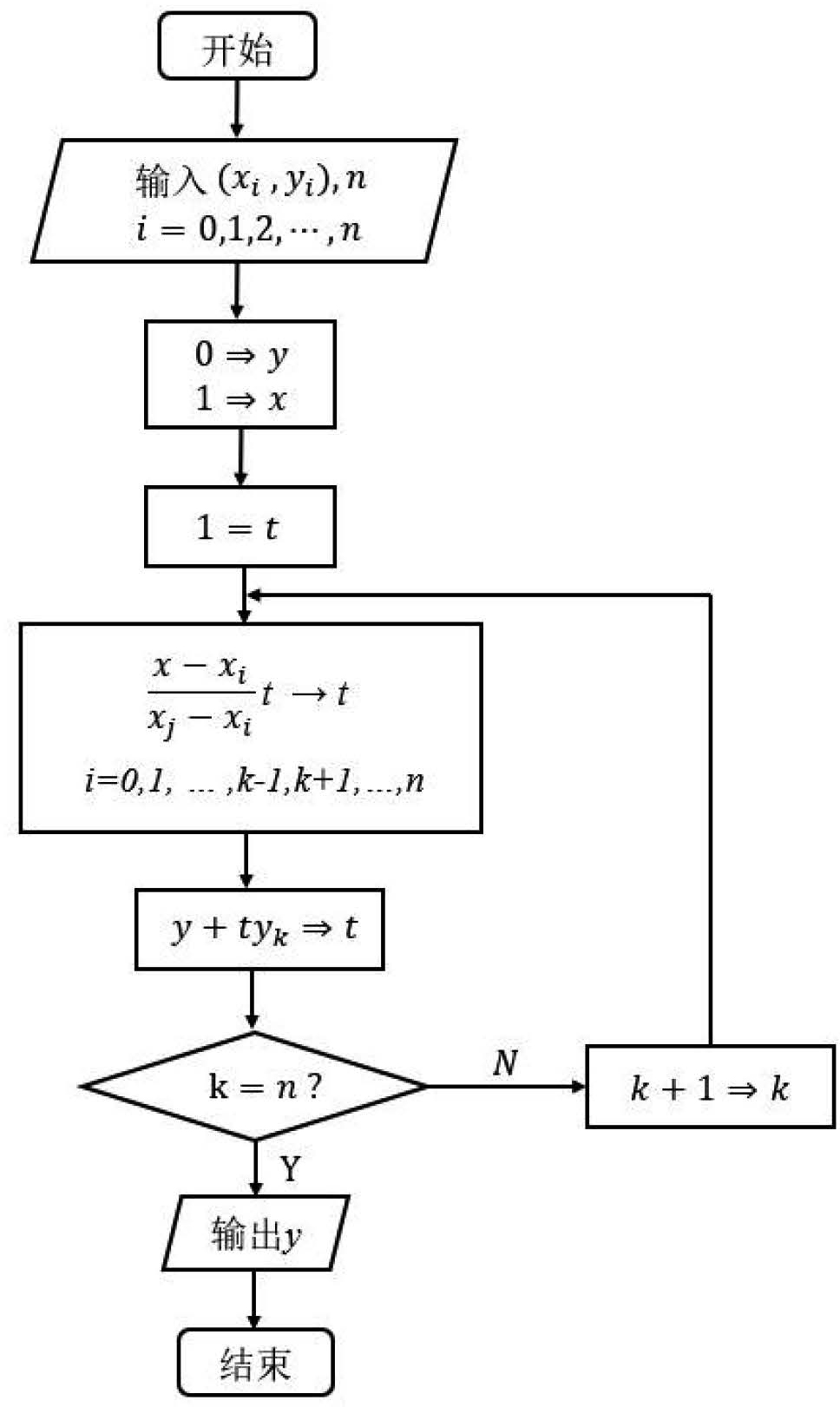
7 拉格朗日插值法算法流程图
-
相关阅读:
es6(三)——常用es6(函数、数组、对象的扩展)
RH8任务计划(单一/循环)
java基于Springboot+vue的医院体检预约挂号系统 elementui
css第十二课:盒子模型
Redux的基本使用过程详解
JavaScript:实现二维向量以及各种向量操作算法(附完整源码)
Using Multiple RDF Knowledge Graphs for Enriching ChatGPT Responses
大一Web课程设计:企业网站——HTML+CSS+JavaScript电子购物商城(37页面)
算法小讲堂之平衡二叉树|AVL树(超详细~)
redis,mongoDB,mysql,Elasticsearch区别
- 原文地址:https://blog.csdn.net/m0_53022813/article/details/126634453