-
大数据随记 —— Hadoop 环境搭建
大数据系列文章:👉 目录 👈

一、虚拟机环境准备
1. 虚拟机网络模式设置为 NAT
① 点击 “编辑虚拟机设置”
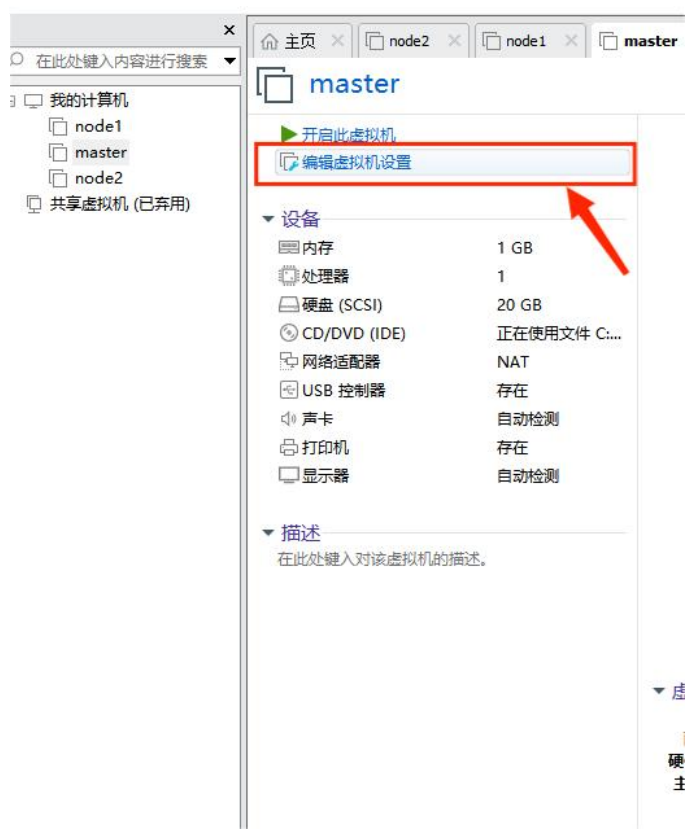
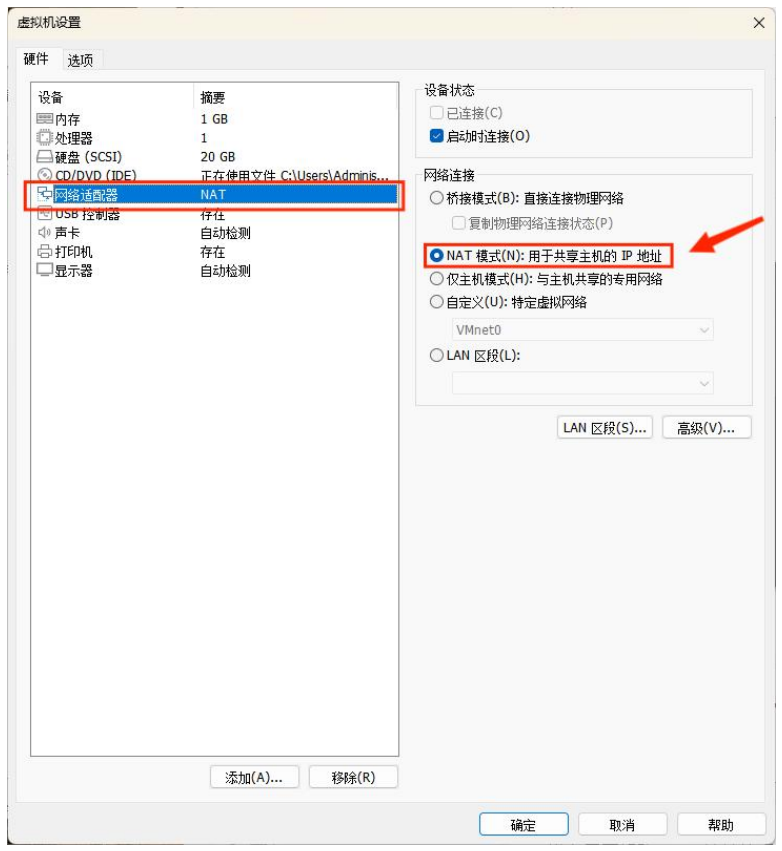
② 点击 “网络适配器” → “NAT模式” 即可。
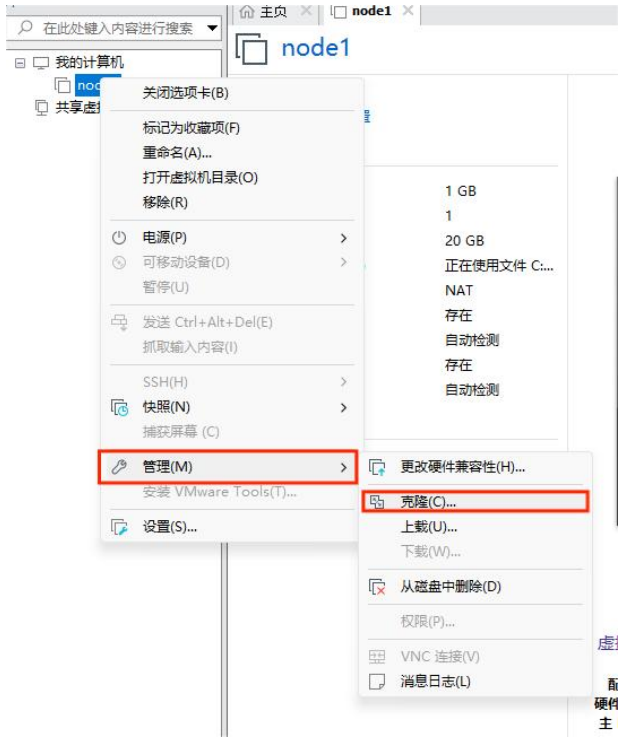
2. 克隆虚拟机
① 右键需要克隆的虚拟机 → 管理 → 克隆。
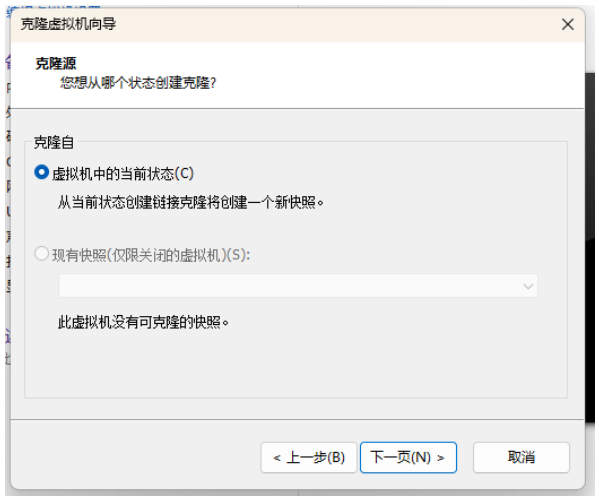
② 选择“虚拟机中的当前状态”,点击下一步。
③ 选择“创建完整克隆”,点击下一步。
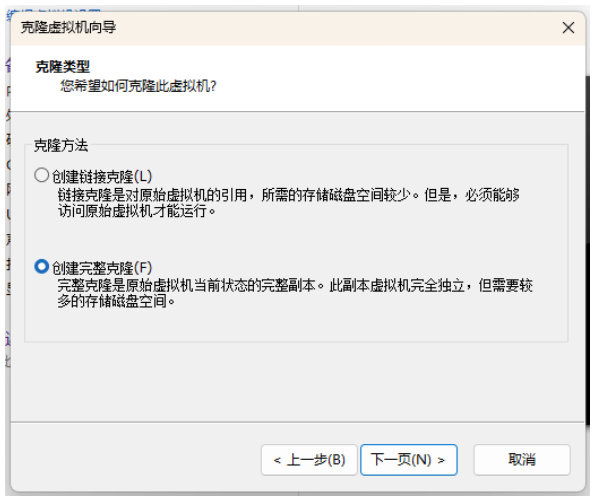
④ 更改虚拟机名称以及位置,点击下一步
⑤ 创建完成后关闭即可。
3. 修改虚拟机为静态 IP
① 查看虚拟网卡信息
输入
ifconfig,看到可以正常使用的网卡以及相关信息。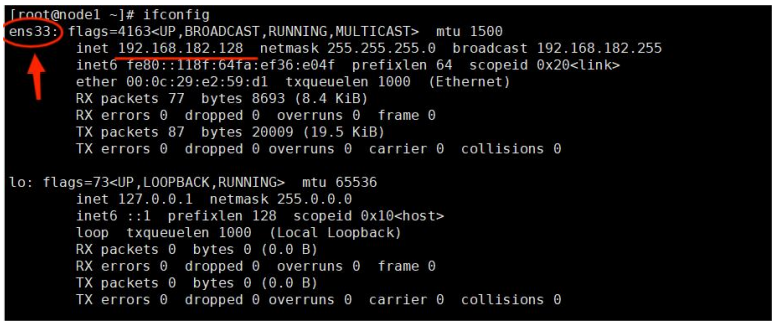
可以看到我们这里的网卡是 ens33。
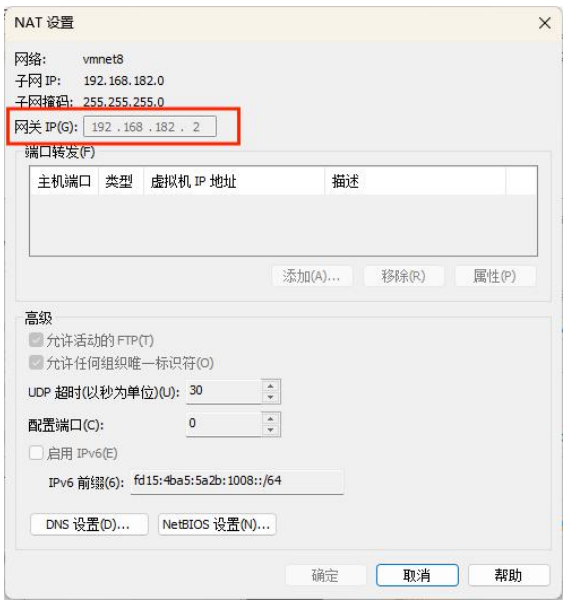
② 查看网关
在 VMware 中的虚拟网络编辑器中可以看到。
③ 修改网卡配置
输入以下命令,即可编写网卡配置。
vim /etc/sysconfig/network-scripts/ifcfg-网卡名- 1
我这里的网卡名是 ens33,则命令如下:
vim /etc/sysconfig/network-scripts/ifcfg-ens33- 1
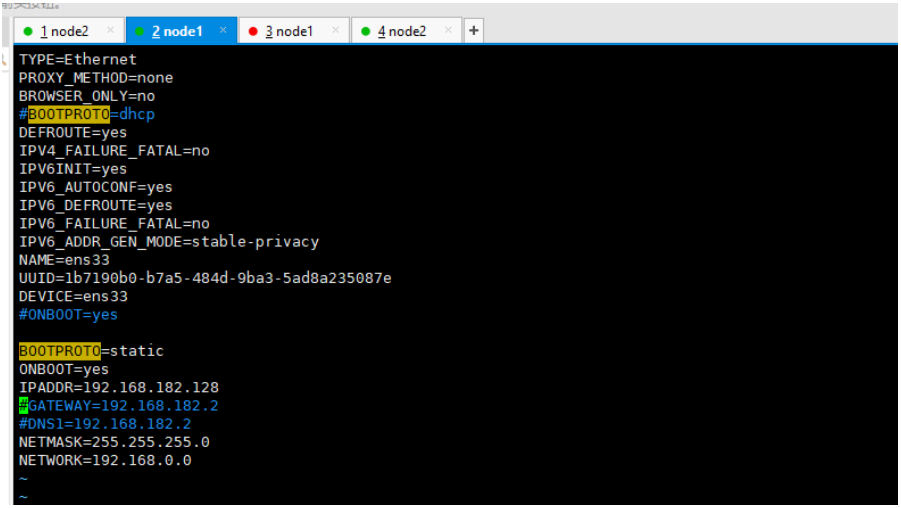
把有的部分注释掉,没有的部分在最后加上。
# 要配制的部分 BOOTPROTO=static ONBOOT=yes IPADDR=192.168.182.128 #IP地址 NETMASK=255.255.255.0 #子网掩码 NETWORK=192.168.0.0- 1
- 2
- 3
- 4
- 5
- 6
④ 修改网关配置
输入以下命令,编写网关配置。
vim /etc/sysconfig/network- 1
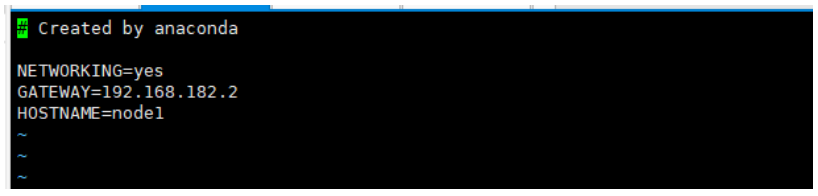
编写以下内容。
NETWORKING=yes GATEWAY=192.168.182.2 #网关- 1
- 2
⑤ 修改 DNS 配置
输入以下内容,编写 DNS 配置。
vim /etc/resolv.conf- 1
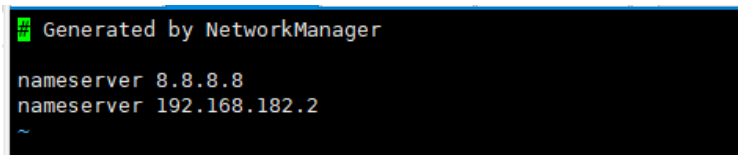
编写以下内容。
search localdomain nameserver 8.8.8.8 nameserver 192.168.182.2- 1
- 2
- 3
⑥ 重启网络服务
service network restart- 1
4. 修改主机名
① 查看本机主机名
查看本机主机名使用
hostname即可。hostname- 1
② 修改主机名(CentOS 7)
使用下面的命令修改主机名。
hostnamectl set-hostname 主机名- 1
示例:
hostnamectl set-hostname node1- 1
③ 修改主机名(通用,CentOS7 与 非 CentOS7)
NETWORKING=yes NETWORKING_IPV6=no GATEWAY=192.168.182.2 #网关 HOSTNAME=node1 #主机名- 1
- 2
- 3
- 4

④ 修改 CentOS 的 hosts
使用下面的命令编辑 hosts。
vim /etc/hosts- 1
在每个虚拟机的 hosts 文件后面增加自己所安装的虚拟机的 IP 地址以及主机名。
192.168.182.133 master 192.168.182.128 node1 192.168.182.129 node2- 1
- 2
- 3
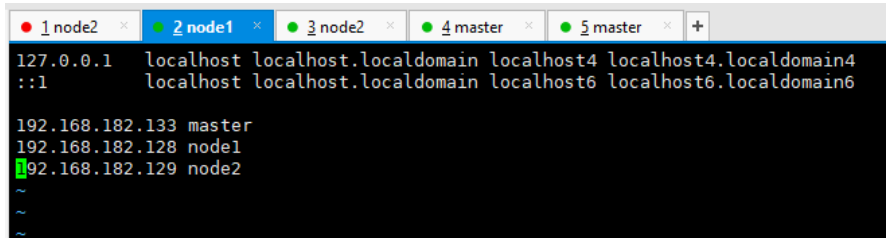
将 hosts 文件拷贝到 node1 和 node2 节点命令:
scp /etc/hosts node1:/etc/hosts # 拷贝到 node1 scp /etc/hosts node2:/etc/hosts # 拷贝到 node2- 1
- 2
- 3
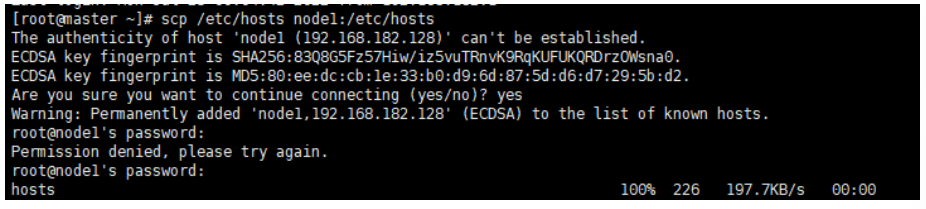
⑤ 修改 Windows 的 hosts
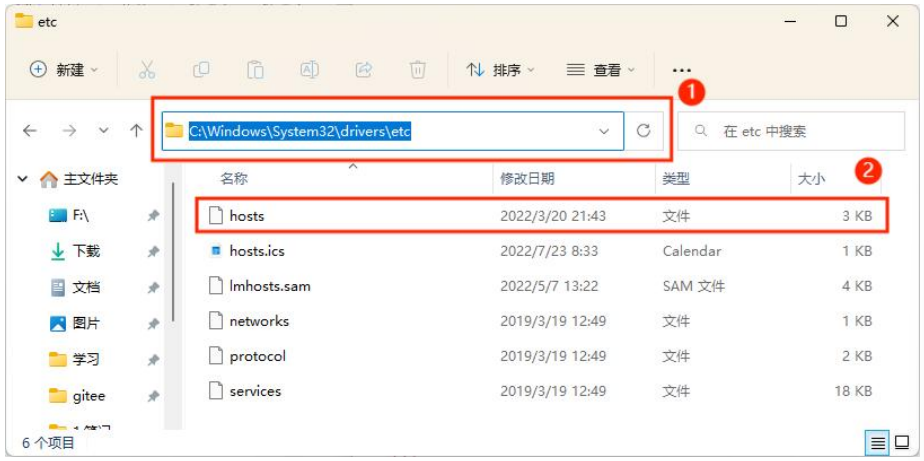
进入 C:\Windows\System32\drivers\etc 路径
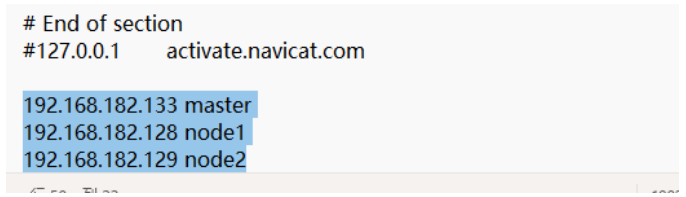
打开 hosts 文件,填写如下内容:
192.168.182.133 master 192.168.182.128 node1 192.168.182.129 node2- 1
- 2
- 3
保存文件,如果不行的话可以先移出来,再移回去。
5. 关闭防火墙
① 查看防火墙状态
systemctl status firewalld.service- 1
绿的running表示防火墙开启
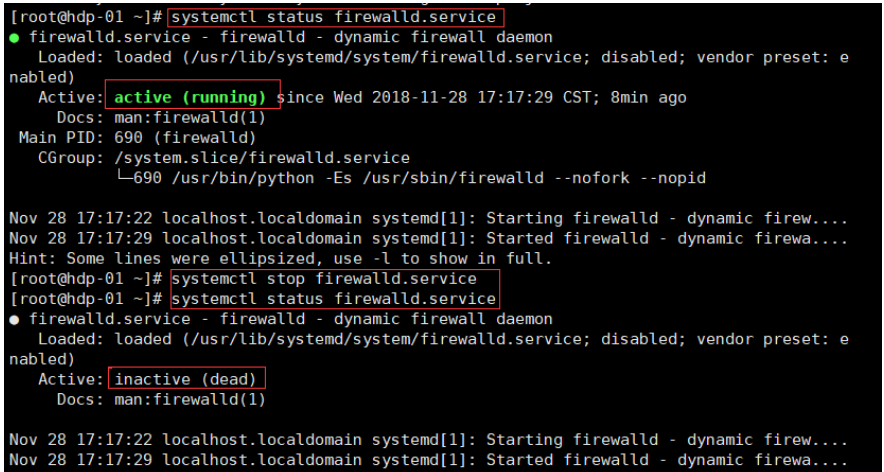
② 关闭防火墙
systemctl stop firewalld.service- 1
或
service iptables stop- 1
③ 开机禁用防火墙自启
systemctl disable firewalld.service- 1
或
chkconfig iptables off- 1
④ 启动防火墙
systemctl start firewalld.service- 1
⑤ 防火墙随系统开启启动
systemctl enable firewalld.service- 1
6. 设置 ssh 免密码登录(只在 Master 这台主机操作)
① 生成密钥并拷贝到子节点
主节点执行命令
ssh-keygen -t rsa产生密钥,一直回车执行命令。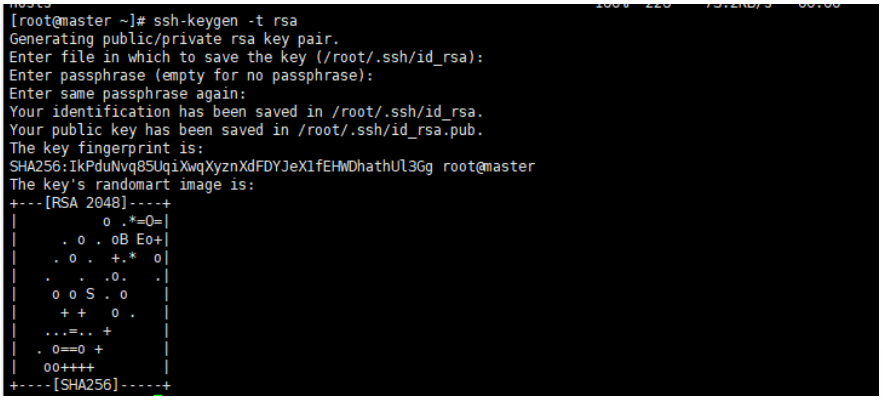
将密钥拷贝到其他两个子节点,命令如下:
ssh-copy-id -i node1 ssh-copy-id -i node2- 1
- 2
- 3
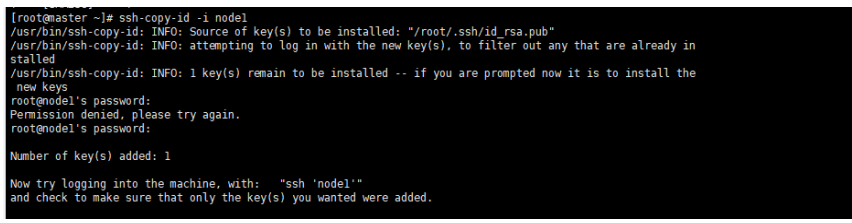
② 实现主节点 master 本地免密码登录
首先进入到
/root命令:cd /root- 1
在进入到
./.ssh目录下cd ./.ssh/- 1
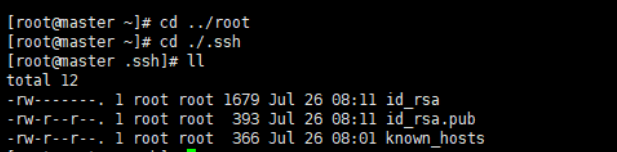
将公钥写入本地执行命令
cat ./id_rsa.pub>> ./authorized_keys- 1

二、用户及文件权限配置
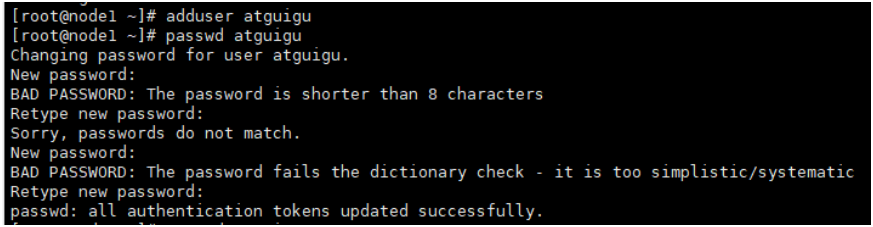
1. 创建用户
adduser atguigu #添加用户 passwd atguigu #修改密码- 1
- 2
- 3
2. 配置用户具有 root 权限
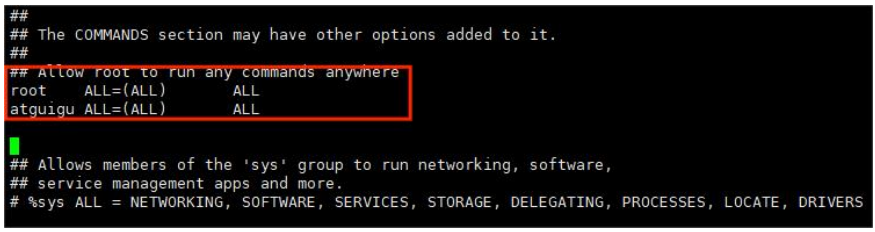
输入以下命令进行配置:
vi /etc/sudoers- 1
配置 atguigu 用户的信息:
## Allow root to run any commands anywhere root ALL=(ALL) ALL atguigu ALL=(ALL) ALL- 1
- 2
- 3
3. 在 /opt 目录下创建文件夹
① 在 /opt 目录下创建 module、software 文件夹
mkdir module # 创建 module 文件夹 mkdir software # 创建 software 文件夹- 1
- 2
- 3
② 修改 module、software 文件夹的所有者 cd
chown atguigu:atguigu module chown atguigu:atguigu software- 1
- 2
- 3
③ 查看文件归属
ls -al- 1

三、JDK 安装
1. 卸载现有 jdk
① 查询是否安装 Java
rpm -qa|grep java- 1
② 如果安装的版本低于 1.7,则卸载该 jdk
sudo rpm -e 软件包- 1
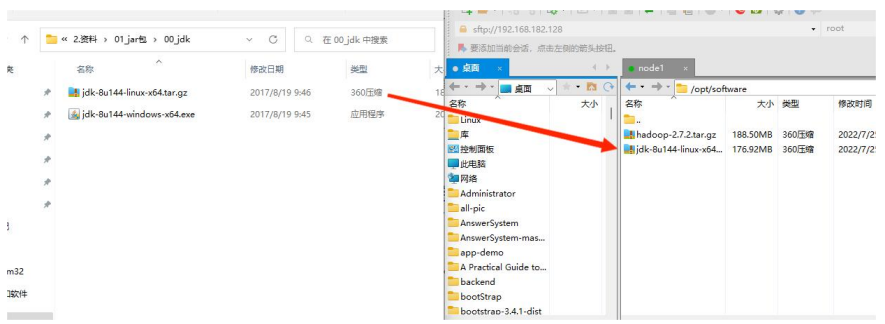
2. 将 jdk、Hadoop 导入到 opt 目录的 software 文件夹下
① 导入 jdk 安装包
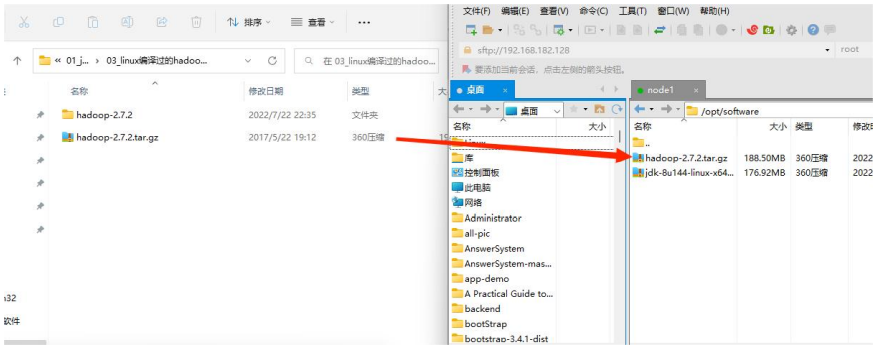
② 导入 Hadoop 安装包
3. 查看软件包是否导入成功
cd software/- 1
ls- 1

4. 解压 jdk 到 /opt/module 目录下
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/- 1
5. 配置 jdk 环境变量
① 获取 jdk 路径
进入 jdk 的解压路径,输入以下命令即可查看 jdk 路径:
pwd- 1

② 打开 /etc/profile 文件:
输入以下命令打开 profile 文件。
sudo vi /etc/profile- 1
输入以下命令配置 Java 环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin- 1
- 2
- 3
保存退出
③ 配置 jdk 环境生效
source /etc/profile- 1
④ 测试 jdk 是否安装成功
java -version- 1

⑤ 重启(如果 java -version 可以用就不用重启)
sync sudo reboot- 1
- 2
- 3
四、Hadoop 安装(master 主机)
1. 进入 Hadoop 安装包路径下
cd /opt/software/- 1
2. 解压安装文件到 /opt/module 目录下
tar -zxf hadoop-2.7.2.tar.gz -C /opt/module/- 1
3. 查看是否解压成功
ls /opt/module/- 1

4. 将 Hadoop 添加到环境变量下
① 获取 Hadoop 安装路径
进入 Hadoop 路径,输入以下命令查看 Hadoop 安装路径。
pwd- 1

② 打开 /etc/profile 文件
使用 vim 打开 profile 文件
sudo vi /etc/profile- 1
编辑 Hadoop 环境
##HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin- 1
- 2
- 3
- 4
- 5
- 6
- 7
保存退出。
③ Hadoop 环境生效
source /etc/profile- 1
④ 测试 Hadoop 是否安装成功
hadoop version- 1

⑤ 重启(如果 hadoop version 可以用就不用重启)
sync sudo reboot- 1
- 2
- 3
5. 修改 Hadoop 相关配置文件
(1) 修改 Hadoop 的 slaves 文件
① 进入 /opt/module/hadoop-2.7.2/etc/hadoop 目录
cd /opt/module/hadoop-2.7.2/etc/hadoop- 1
② 修改该目录下的 slaves 文件
使用 vim 编辑 slaves 文件。
vim slaves- 1
删除原来的内容,修改为如下内容。
node1 node2- 1
- 2

(2) 修改 Hadoop 的 hadoop-env.sh 文件
① 进入 /opt/module/hadoop-2.7.2/etc/hadoop 目录
cd /opt/module/hadoop-2.7.2/etc/hadoop- 1
② 修改该目录下的 hadoop-env.sh 文件
添加 JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_144- 1

(3) 修改 Hadoop 的 core-site.xml 文件
① 进入 /opt/module/hadoop-2.7.2/etc/hadoop 目录
cd /opt/module/hadoop-2.7.2/etc/hadoop- 1
② 修改该目录下的 core-site.xml 文件
<configuration> <property> <name>fs.defaultFSname> <value>hdfs://master:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/opt/module/hadoop-2.7.2/tmpvalue> property> <property> <name>fs.trash.intervalname> <value>1440value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

(4) 修改 Hadoop 的 hdfs-site.xml 文件
① 进入 /opt/module/hadoop-2.7.2/etc/hadoop 目录
cd /opt/module/hadoop-2.7.2/etc/hadoop- 1
② 修改该目录下的 hdfs-site.xml 文件
<configuration> <property> <name>dfs.replicationname> <value>1value> property> <property> <name>dfs.permissionsname> <value>falsevalue> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

(5) 修改 Hadoop 的 yarn-site.xml 文件
① 进入 /opt/module/hadoop-2.7.2/etc/hadoop 目录
cd /opt/module/hadoop-2.7.2/etc/hadoop- 1
② 修改该目录下的 yarn-site.xml 文件
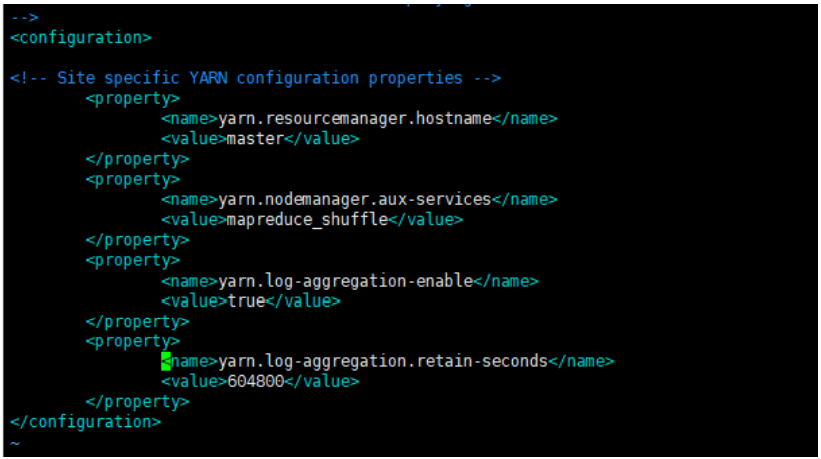
<configuration> <property> <name>yarn.resourcemanager.hostnamename> <value>mastervalue> property> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.log-aggregation-enablename> <value>truevalue> property> <property> <name>yarn.log-aggregation.retain-secondsname> <value>604800value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(6) 修改 Hadoop 的 mapred-site.xml 文件
① 进入 /opt/module/hadoop-2.7.2/etc/hadoop 目录
cd /opt/module/hadoop-2.7.2/etc/hadoop- 1
② 复制 mapred-site.xml.template 为 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml- 1
③ 修改该目录下的 mapred-site.xml 文件
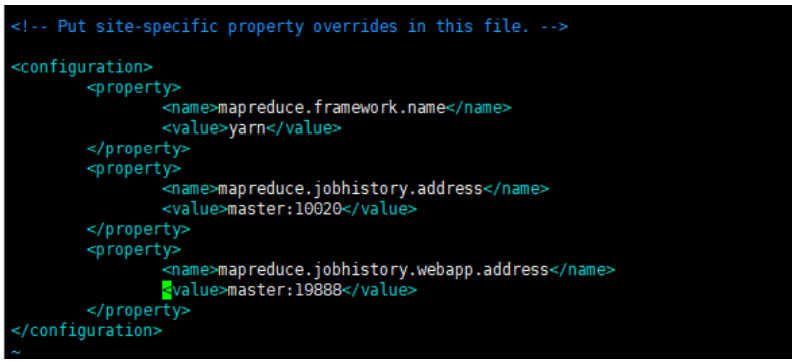
<configuration> <property> <name>mapreduce.framework.namename> <value>yarnvalue> property> <property> <name>mapreduce.jobhistory.addressname> <value>master:10020value> property> <property> <name>mapreduce.jobhistory.webapp.addressname> <value>master:19888value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(7) 复制 Hadoop 的安装目录到其它子节点
scp -r /opt/module/hadoop-2.7.2 node1:/opt/module/hadoop-2.7.2 scp -r /opt/module/hadoop-2.7.2 node2:/opt/module/hadoop-2.7.2- 1
- 2
- 3
6. 验证(启动 Hadoop)
① 首先看下 hadoop-2.7.2 目录下有没有 tmp 文件夹。 如果没有执行一次格式化命令:
cd /opt/module/hadoop-2.7.2 #进入 hadoop 安装目录 ./bin/hdfs namenode -format # 格式化命令- 1
- 2
- 3
执行完格式化命令会生成 tmp 文件
② 启动 Hadoop
输入以下命令启动 Hadoop
cd /opt/module/hadoop-2.7.2 #进入 hadoop 安装目录 ./sbin/start-all.sh #启动程序- 1
- 2
- 3
③ 验证主节点进程
输入以下命令查看进程:
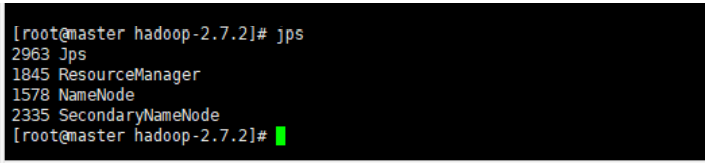
jps #显示所有 java 进程 pid- 1
主节点进程:
- ResourceManager
- NameNode
- SecondaryNameNode
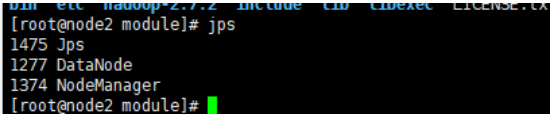
子节点进程
- DataNode
- NodeManager
④ 验证 HDFS:
浏览器登录地址:192.168.182.133:50070(ip 地址是 master 节点的地址)
出现以下界面则证明 HDFS 安装成功:
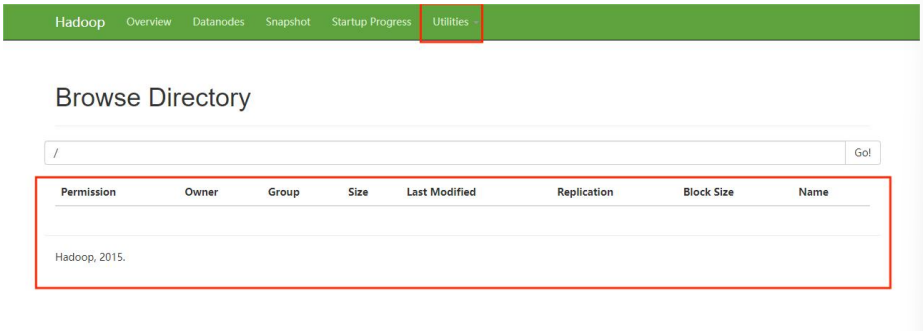
刚搭建完成,什么都没有。
PS:
如果第一次启动失败了,请重新检查配置文件或者哪里步骤少了。 再次重启的时候 需要手动将每个节点的 tmp 目录删除:
rm -rf /opt/module/hadoop-2.7.2/tmp- 1
然后在主节点执行以下命令格式化 namenode。
./bin/hdfs namenode -format- 1
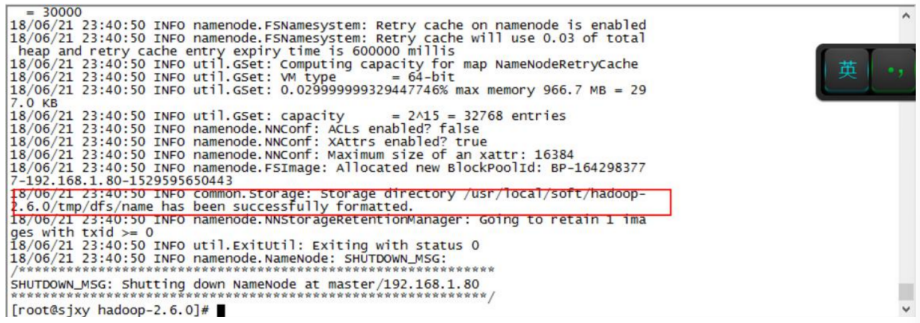

-
相关阅读:
【LeetCode 每日一题】53. 最大子数组和
物联网边缘-物联网准入或接入安全防护产品及解决方案
rust闭包
Java并发技术基础
堪称经典,一个非常适合初学者的机器学习实战案例
RDD编程进阶自定义累加器_大数据培训
Java的类中属性的使用
不容易解的题10.7
据采集的三种方式-如何获取数据
使用RestSharp和C#编写程序
- 原文地址:https://blog.csdn.net/qq_21484461/article/details/126672017
