-
【推荐系统】推荐系统基础算法-基于矩阵分解的推荐方法、隐语义模型
目录
奇异值分解(Singular Value Decomposition,SVD)
矩阵分解
首先我们需要知道特征值和特征向量的含义,基本定义如下:
Ax=λx
矩阵A是一个nxn矩阵,x是一个n维向量,则入是矩阵A的一个特征值,而ェ是矩阵A的特征值入所对应的特征向量。
特征向量的几何含义是:特征向量x通过方阵A变换只进行缩放,而方向并不会变化。
如果我们可以求到矩阵A的n个特征值,则可以得到对角矩阵Σ,其展开为以下形式:
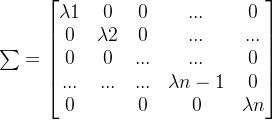
则矩阵A就可以用下式的特征分解表示:

其中U是这n个特征向量所生成的nxn维矩阵,而Σ为这n个特征值为主对角线的nxn维矩阵。
一般我们会把U的这n个特征向量标准化,即满足
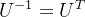 ,此时矩阵A的特征分解表达式可以进一步写成:
,此时矩阵A的特征分解表达式可以进一步写成: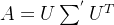
)那么如果A不是方阵,即行和列数目不相同时,我们还可以对矩阵进行分解吗?答案是可以。其中最常用的分解方法是奇异值分解(Singular Value Decomposition,SVD)
奇异值分解(Singular Value Decomposition,SVD)
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵A是一个mxn的矩阵,那么我们定义矩阵A 的SVD为
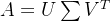
其中U是一个mx的矩阵,是一个mxn的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个的nxn 矩阵。
SVD在推荐系统中的应用
假设矩阵A的维度是10x11维,行代表用户,列代表物品,值代表用户对物品的评分,当没有评分时,分数为0,该矩阵加载到变量 myMat 中,在Python 中调用 linalg.svd 即可获得分解后的U、Σ、V三个矩阵:
加载用户评分矩阵,进行矩阵分解
- from numpy import*
- #定义用户评分矩阵A
- def loadExData():
- return[ [0,0,1,0,0,2,0,0,0,0,5],
- [0,0,0,5,0,3,0,0,0,0,3],
- [0,0,0,0,4,1,0,1,0,4,0],
- [3,3,4,0,0,0,0,2,2,0,0],
- [5,4,2,0,0,0,0,5,5,0,0],
- [0,0,0,0,5,0,1,0,0,0,0],
- [4,1,4,0,0,0,0,4,5,0,1],
- [0,0,0,4,0,4,0,0,0,0,4],
- [0,0,0,2,0,2,5,0,0,1,2],
- [1,0,0,4,0,0,0,1,2,0,0]]
- #加载用户对物品的评分矩阵
- myMat=mat(loadExData())
- #矩阵分解
- U,Sigma,VT=linalg.svd(myMat)
- print(Sigma)
- '''
- [14.2701248 11.19808631 7.13480024 5.13612006 4.68588496 3.09682859
- 2.72917436 2.55571761 1.05782196 0.185364 ]'''
Sigma 为奇异值向量,可以奇异值按照从大到小排序而且奇异值的减小特别地快,在很多高维的情况下,前10%的奇异值之和就占了全部奇异值之和的80%以上的比例。本例中k的选择主要依据奇异值的能量占比,原矩阵能量值为sum(Sigma**2)=452,降低到 k=3维后能量值sum(Sigma[0:3]**2)=380,能量占比达84.4%。也就是说我们可以用最大的k个奇异值和对应u和v中的向量来描述矩阵A。
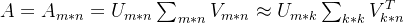
矩阵降维
- #这里取k = 4,利用矩阵分解将原来的评分矩阵降维
- NewData = U[:,:4] * mat(eye(4)* Sigma[:4]) * VT[:4,:]
- NewData
对比两个矩阵,发现高分值都十分接近,说明可以用
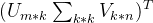 这三个矩阵表征原始的矩阵A。
这三个矩阵表征原始的矩阵A。将物品的评分矩阵
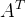 映射到低维空间
映射到低维空间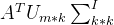 ,其中维度由nxm降到nxk,然后再计算物品item间的相似度,每个item的维度由m降到n,从而提升了计算效率。
,其中维度由nxm降到nxk,然后再计算物品item间的相似度,每个item的维度由m降到n,从而提升了计算效率。一般来说,m代表样本的用户数,维度会很高,而k<
计算相似度
- #基于SVD的评分估计
- ##dataMat是输入矩阵
- #simMeas是相似度计算函数
- #user和item是待打分的用户和item对
- #userData是输入矩阵dataMat的子集
- #xformedItem是对原始评分矩阵进行降维后的物品评分矩阵
- def svdEst(userData,xformedItems,user,simMeas,item):
- n = shape(xformedItems)[0]#用户数量
- simTotal = 0.0 #初始化相似度的总和
- ratSimTotal = 0.0 #初始化相似度及评分值的乘积(预测的评分)求和
- #对给定的用户,for 循环所有物品,计算与item相似度
- for j in range(n):
- #每个物品的不同用户的评分
- userRating = userData[:,j]
- if userRating == 0 or j == item:
- continue
- #计算物品间的相似度
- similarity = simMeas(xformedItems[item , :].T,xformedItems[j , :].T)
- print('the %d and %d similarity is :%f' %(item,j,similarity))
- #对相似度求和
- simTotal += similarity
- #对相似度及评分值的乘积求和
- ratSimTotal += similarity*userRating
- if simTotal == 0 :
- return 0
- else:
- return ratSimTotal/simTotal
对用户未评分过的物品进行预测
- #余弦相似度
- def cosSim(U_k,W_t):
- num = float(U_k.T * W_t)
- denom = linalg.norm(U_k)* linalg.norm(W_t)
- return 0.5 + 0.5 * (num/denom)
- # 寻找未评级的物品,对给定用户建立一个未评分的物品列表
- def recommend(dataMat,user,N = 3,simMeas = cosSim,estMethod = svdEst):
- U,Sigma,VT = linalg.svd(dataMat)
- #使用奇异值构建一个对角矩阵
- Sig4 = mat(eye(4) * Sigma[:4])
- #利用U矩阵将物品转换到低维空间中
- xformedItem = dataMat.T * U[:,:4] * Sig4.I
- print('xformedItem =',xformedItem)
- print('xformedItem维度:',shape(xformedItem))
- unratedItems = nonzero(dataMat[user:].A==0)[1]#未评分的物品
- print('dataMat[user:].A = ',dataMat[user:].A)
- print('nonzero(dataMat[user:].A==0)结果为',nonzero(dataMat[user:].A==0))
- #如果不存在未评分物品,退出函数,否则在所有未评分物品上进行循环
- if len(unratedItems) == 0:
- return ('you rated everyting')
- itemScores = []
- for item in unratedItems:
- print('items = ',item)
- #对于每个未评分物品,通过调用standEst() 来产生该物品基于相似度的预测评分
- estimatedScore = estMethod(dataMat[user,:],xformedItem,user,simMeas,item)
- #该物品的编号和估计得分值会放在一个元素列表itemScores
- itemScores.append((item,estimatedScore))
- #寻找前N个未评级物品
- return sorted(itemScores,key = lambda jj:jj[1],reverse = True)[:N]
- myMat = mat(loadExData())
- result = recommend(myMat,1,estMethod = svdEst)
- print(result)
流程总结:
- 加载用户对物品的评分矩阵
- 矩阵分解,求奇异值,根据奇异值的能量占比确定降维至k的数值
- 使用矩阵分解对物品评分矩阵进行降维
- 使用降维后的物品评分矩阵计算物品相似度,对用户未评分过得物品进行预测
- 产生前n个评分值高的物品,返回物品编号以及预测评分值
隐语义模型
SVD计算前会把评分矩阵A的缺失值补全,补全之后的稀疏矩阵A表示成稠密矩阵,然后将A分解成A'=
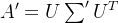 ,这种方法有缺点:
,这种方法有缺点:- 耗费巨大的存储空间,在实际中,用户对物品的行为信息何止千万,对这样的稠密矩阵进行存储是不现实的:
- SVD的计算复杂度很高,更不用说这样的大规模稠密矩阵了。
所以关于SVD的研究很多都是在小数据集上进行的。隐语义模型也是基于矩阵分解的,但是和SVD不同,它是把原始矩阵分解成两个矩阵相乘而不是三个。
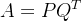
现在的问题就变成了确定P和Q,我们把P叫作用户因子矩阵,Q叫作物品因子矩阵。通常上式不能达到精确相等的程度,我们要做的就是要最小化它们之间的差距,这又变成了一个最优化问题。通过优化损失函数来找到P和Q中合适的参数,其中行为用户i对物品j的评分。
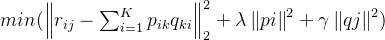 式一
式一推荐系统中用户和物品的交互数据分为显性反馈和隐性反馈数据。隐式模型多了一个置信参数,这就涉及ALS中对于隐式反馈模型的处理方式——有的文章称为“加权的正则化矩阵分解”,它的损失函数如下:
 式二
式二隐式反馈模型中是没有评分的,所以在式子中Tij并不是具体分数,而仅为1,仅仅表示用户和物品之间有交互,而不表示评分高低或者喜好程度。函数中还有一个Cij的项,它 用来表示用户偏爱某个商品的置信程度,比如交互次数多的权重就会增加。如果我们用dij来表示交互次数的话,那么就可以把置信程度表示成如下公式:
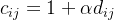
这样,协同过滤就成功转化成了一个优化问题。为了求得以上损失函数最优解,最常用的是ALS算法,即交替最小二乘法(Alternating Least Squares)。算法的基础计算流程 是:
(1)随机初始化Q,对式一中的Pi求偏导,令导数为0,得到当前最优解
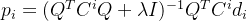
2)固定p,对式一中的qj求偏导,令导数为0,得到当前最优解qj;
3) 固定q,对式一中的pj求偏导,令导数为0,得到当前最优解pj;
4) 循环2)和3),直到指定的迭代次数或收敛,对于大数据集,可以用spark进行ALS的计算
实际问题中,由于待分解的矩阵通常非常稀疏,与SVD相比,ALS能有效地解决过拟合问题。基于ALS的矩阵分解的协同过滤算法的可拓展性也优于SVD。
-
相关阅读:
C++ 编译器中对 use after free 的检查示例
【数据结构-树】线索二叉树
【C++学习笔记】内联函数
深入理解注解驱动配置与XML配置的融合与区别
【软考学习14】绝对路径和相对路径的区别和联系
python自动更新pom文件
Java JDK下载与安装教程
OpenCV使用教程-读取图像imread使用说明
【技术积累】Vue.js中的核心知识【五】
20220915使用python3下载ts格式的视频切片文件
- 原文地址:https://blog.csdn.net/m0_51933492/article/details/126647931
