-
【AI视野·今日Robot 机器人论文速览 第四十三期】Thu, 28 Sep 2023
AI视野·今日CS.Robotics 机器人学论文速览
Thu, 28 Sep 2023
Totally 37 papers
👉上期速览✈更多精彩请移步主页
Interesting:
📚****触觉力控学习策略,基于触觉的主动推理与力控用于小孔插入任务。提出了姿态控制与插入控制双策略模型。 (from 东京大学 )
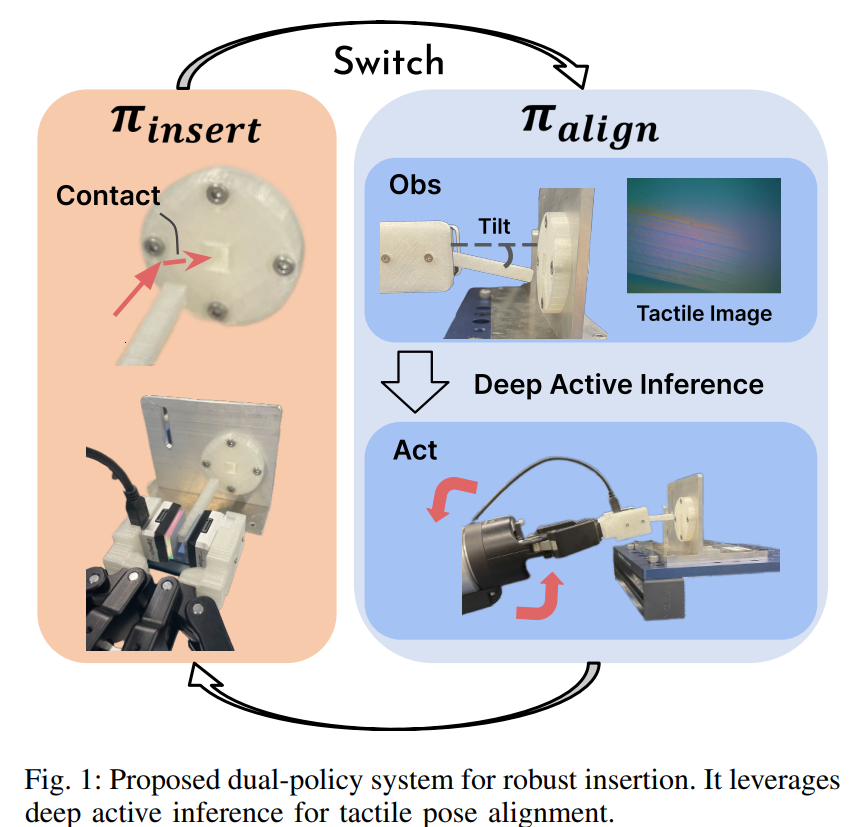
(编者:未来触觉也许可用于柔性电路等精密插入装配操作)
📚***人形机器人的感知综述,综述了状态估计、环境感知与人机交换三方面的内容。(from 波恩大学)

📚**HIRO,便于示教和操作的可穿戴机械手,视觉模仿学习控制器 (from 清华)

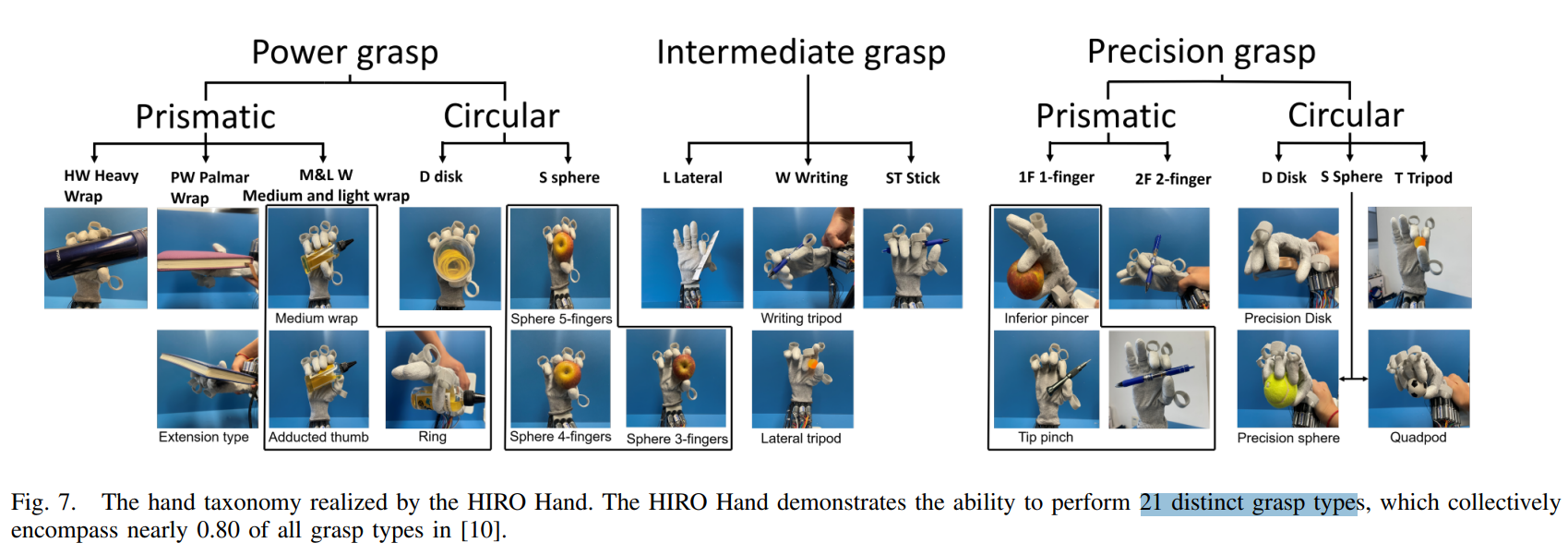

website:https://sites.google.com/view/hiro-hand/首页 Xuhuazhe组
📚柔性电路板集成的无人机, (from 东北大学 波士顿 )

Daily Robotics Papers
LGMCTS: Language-Guided Monte-Carlo Tree Search for Executable Semantic Object Rearrangement
Authors Haonan Chang, Kai Gao, Kowndinya Boyalakuntla, Alex Lee, Baichuan Huang, Harish Udhaya Kumar, Jinjin Yu, Abdeslam Boularias
我们引入了一种解决可执行语义对象重排问题的新方法。在这项挑战中,机器人试图创建一个可行的计划,根据自然语言描述所指示的模式重新排列场景内的对象。与 StructFormer 和 StructDiffusion 等现有方法不同,这些方法分两步解决问题,首先生成姿势,然后利用任务规划器制定行动计划,我们的方法同时解决姿势生成和行动规划。我们使用语言引导蒙特卡罗树搜索 LGMCTS 来实现这种集成。Gaussian Process-Enhanced, External and Internal Convertible (EIC) Form-Based Control of Underactuated Balance Robots
Authors Feng Han, Jingang Yi
基于外部和内部可转换EIC形式的运动控制,即基于EIC的控制是欠驱动平衡机器人的有效方法之一。通过顺序控制器设计,可以同时实现驱动子系统的轨迹跟踪和非驱动子系统的平衡。然而,在某些条件下,基于 EIC 的控制会存在不受控制的机器人运动。我们首先确定这些条件,然后提出一种基于 EIC 的增强型控制,采用高斯过程数据驱动的机器人动态模型。在新的增强型EIC控制下,保证了闭环系统的稳定性和性能。Generating Transferable Adversarial Simulation Scenarios for Self-Driving via Neural Rendering
Authors Yasasa Abeysirigoonawardena, Kevin Xie, Chuhan Chen, Salar Hosseini, Ruiting Chen, Ruiqi Wang, Florian Shkurti
自动驾驶软件管道包括从大量训练示例中学习的组件,但评估整个系统的安全性和泛化性能仍然具有挑战性。除了扩大自动驾驶汽车在现实世界的部署规模之外,自动找到驾驶策略失败的模拟场景至关重要。Development of a Whole-body Work Imitation Learning System by a Biped and Bi-armed Humanoid
Authors Yutaro Matsuura, Kento Kawaharazuka, Naoki Hiraoka, Kunio Kojima, Kei Okada, Masayuki Inaba
近年来,模仿学习得到了积极的研究。特别是,通过具有固定身体的机器人获得技能,其根连杆位置和姿势以及摄像机视角不改变,已经在许多情况下实现。另一方面,模仿具有浮动链接的机器人(例如人形机器人)的行为仍然是一项艰巨的任务。在这项研究中,我们使用带有浮动连杆的双足机器人开发了一个模仿学习系统。开发这样一个系统有两个主要问题。第一个是人形遥控设备,第二个是能够承受繁重工作量和长期数据收集的控制系统。对于第一点,我们使用全身控制装置TABLIS。它不仅可以控制手臂,还可以控制腿部,并且可以与机器人进行双边控制。通过将该TABLIS与高功率人形机器人JAXON连接,我们构建了一个用于模仿学习的控制系统。对于第二点,我们将构建一个可以基于姿势优化收集长期数据的系统,并且可以同时移动机器人的四肢。我们将高循环姿势生成与姿势优化方法相结合,包括全身关节扭矩最小化和接触力优化。我们设计了一个具有上述两个特征的集成系统,通过模仿学习来实现各种任务。Data-Driven Latent Space Representation for Robust Bipedal Locomotion Learning
Authors Guillermo A. Castillo, Bowen Weng, Wei Zhang, Ayonga Hereid
本文提出了一种新颖的框架,通过将数据驱动的状态表示与基于强化学习的运动策略相结合来学习稳健的双足行走。该框架利用自动编码器来学习低维潜在空间,从现有的运动数据中捕获双足运动的复杂动态。然后,这种降维状态表示被用作训练基于强化学习的稳健步态策略的状态,从而消除了启发式状态选择或使用模板模型进行步态规划的需要。结果表明,学习到的潜在变量是解开的,并直接对应于不同的步态或速度,例如向前、向后或原地行走。与传统的基于模板模型的方法相比,我们的框架在模拟中表现出卓越的性能和鲁棒性。Tracking Snake-like Robots in the Wild Using Only a Single Camera
Authors Jingpei Lu, Florian Richter, Shan Lin, Michael C. Yip
复杂环境中的机器人导航需要精确的状态估计和定位,以确保稳健和安全的操作。对于像机器蛇这样的移动移动机器人,传统的传感方法需要多个嵌入式传感器或标记,从而导致复杂性、成本和故障点增加。或者,在环境中部署外部摄像头非常容易,并且根据该摄像头的图像对机器人进行无标记状态估计是一种既简单又具有成本效益的理想解决方案。然而,这个过程中的挑战是在更大的环境下跟踪机器人,在这些环境中,相机可能会在没有外部校准的情况下移动,或者可能在运动中,例如跟随机器人的无人机。该场景本身提出了在噪声观测下机器人姿势的单图像重建的复杂挑战。在本文中,我们解决了从单个摄像机跟踪移动移动机器人的问题。该方法将可微渲染与卡尔曼滤波器相结合。这种协同作用允许同时估计机器人的关节角度和姿态,同时还提供状态不确定性,稍后可用于鲁棒控制。我们在静态和非静态移动摄像机中的蛇形机器人上展示了我们的方法的有效性,验证了其在结构化和非结构化场景中的性能。所取得的结果显示,机器人基本位置定位的平均误差为 0.05 m,关节状态估计的平均误差为 6 度。Improving Autonomous Driving Safety with POP: A Framework for Accurate Partially Observed Trajectory Predictions
Authors Sheng Wang, Yingbing Chen, Jie Cheng, Xiaodong Mei, Yongkang Song, Ming Liu
准确的轨迹预测对于安全高效的自动驾驶至关重要,但处理部分观测结果提出了重大挑战。为了解决这个问题,我们针对拥堵的城市道路场景提出了一种称为“部分观察预测 POP”的新型轨迹预测框架。该框架由自监督学习 SSL 和特征蒸馏两个阶段组成。在 SSL 中,重建分支使用掩模过程和重建头重建部分观测的隐藏历史。特征蒸馏阶段将知识从完全观察的教师模型转移到部分观察的学生模型,从而提高预测准确性。 POP 在开环实验中取得了与性能最佳的方法相当的结果,并且在闭环模拟(包括安全指标)中优于基线方法。Tactile-based Active Inference for Force-Controlled Peg-in-Hole Insertions
Authors Tatsuya Kamijo, Ixchel G. Ramirez Alpizar, Enrique Coronado, Gentiane Venture
强化学习 RL 在孔洞任务中有效学习力控制策略方面展现出了巨大的前景。然而,由于抓手的视觉遮挡以及钉子初始抓取姿势的不确定性,机器人经常面临困难。这些挑战通常将力控插入策略限制在钉牢牢固定到末端执行器的情况下。虽然基于视觉的触觉传感器提供了丰富的触觉反馈,有可能解决这些问题,但利用它们来学习有效的触觉策略既需要大量计算,又难以推广。在本文中,我们提出了一种强大的触觉插入策略,可以使用主动推理将倾斜的钉子与孔对齐,而无需对大型数据集进行大量训练。我们的方法采用双策略架构,一种策略专注于插入,集成力控制和强化学习以引导物体进入孔中,而另一种策略则基于触觉反馈执行主动推理,以将倾斜的钉子与孔对齐。在现实世界的实验中,我们的双策略架构在间隙小于 0.1 毫米的孔中实现了 90 的成功率,显着优于以前缺乏触觉反馈的方法 5 。Orientation Control with Variable Stiffness Dynamical Systems
Authors Youssef Michel, Matteo Saveriano, Fares J. Abu Dakka, Dongheui Lee
最近,有几种方法尝试将运动生成和控制结合在一个循环中,以使机器人具有反应行为,这是传统的时间索引跟踪控制器无法实现的。然而,这些方法主要关注位置,忽略了方向部分,这对于许多任务(例如,移动)至关重要。拧紧。在这项工作中,我们提出了一种控制算法,以闭环方式适应机器人的旋转运动和阻抗。给定代表方向运动计划和所需旋转刚度轮廓的一阶动力系统,我们的方法使机器人能够遵循参考运动,并具有由所需刚度指定的交互行为,同时始终了解当前方向,表示为单位四元数 UQ 。我们依靠李代数来制定我们的算法,因为与位置不同,UQ 特征约束应该在设计的控制器中得到尊重。Perception for Humanoid Robots
Authors Arindam Roychoudhury, Shahram Khorshidi, Subham Agrawal, Maren Bennewitz
审查目的在人形机器人领域,感知在使机器人与人类及其周围环境无缝交互方面发挥着基础作用,从而提高安全性、效率和用户体验。PolarNet: 3D Point Clouds for Language-Guided Robotic Manipulation
Authors Shizhe Chen, Ricardo Garcia, Cordelia Schmid, Ivan Laptev
机器人基于自然语言指令理解和执行操作任务的能力是机器人技术的长期目标。语言引导操作的主要方法使用 2D 图像表示,这在组合多视图相机和推断精确的 3D 位置和关系方面面临困难。为了解决这些限制,我们提出了一种基于 3D 点云的策略,称为 PolarNet,用于语言引导操作。它利用精心设计的点云输入、高效的点云编码器和多模态转换器来学习 3D 点云表示并将其与用于动作预测的语言指令集成。在 RLBench 基准测试上进行的各种实验中,PolarNet 被证明是有效且数据高效的。它在单任务和多任务学习方面都优于最先进的 2D 和 3D 方法。EDGAR: An Autonomous Driving Research Platform -- From Feature Development to Real-World Application
Authors Phillip Karle, Tobias Betz, Marcin Bosk, Felix Fent, Nils Gehrke, Maximilian Geisslinger, Luis Gressenbuch, Philipp Hafemann, Sebastian Huber, Maximilian H bner, Sebastian Huch, Gemb Kaljavesi, Tobias Kerbl, Dominik Kulmer, Tobias Mascetta, Sebastian Maierhofer, Florian Pfab, Filip Rezabek, Esteban Rivera, Simon Sagmeister, Leander Seidlitz, Florian Sauerbeck, Ilir Tahiraj, Rainer Trauth, Nico Uhlemann, Gerald W rsching, Baha Zarrouki, Matthias Althoff, Johannes Betz, Klaus Bengler, Georg Carle, Frank Diermeyer, J rg Ott, Markus Lienkamp
虽然当前自动驾驶的研究和开发主要集中在开发新功能和算法,但从孤立的软件组件到整个软件堆栈的转移却很少涉及。除此之外,由于自主软件堆栈和公共道路交通的复杂性,整个堆栈的最佳验证是一个开放的研究问题。我们的论文主要针对这两方面。我们展示了我们的自动研究车辆 EDGAR 及其数字孪生,即车辆的详细虚拟复制品。虽然车辆的设置与最先进的技术密切相关,但其虚拟复制是一个有价值的贡献,因为它对于从模拟到现实世界测试的一致验证过程至关重要。此外,不同的开发团队可以使用相同的模型,使软件堆栈的集成和测试变得更加容易,从而显着加快开发过程。还介绍了真实和虚拟车辆嵌入到综合开发环境中的情况。DTC: Deep Tracking Control -- A Unifying Approach to Model-Based Planning and Reinforcement-Learning for Versatile and Robust Locomotion
Authors Fabian Jenelten, Junzhe He, Farbod Farshidian, Marco Hutter
腿式运动是一个复杂的控制问题,需要准确性和鲁棒性来应对现实世界的挑战。传统上,腿式系统是使用逆动力学轨迹优化来控制的。这种基于分层模型的方法很有吸引力,因为它具有直观的成本函数调整、准确的规划,最重要的是,从十多年的广泛研究中获得的深刻理解。然而,模型不匹配和违反假设是错误操作的常见原因,并可能阻碍成功的模拟到实际的转移。另一方面,基于模拟的强化学习可以产生具有前所未有的鲁棒性和恢复技能的运动策略。然而,所有学习算法都在努力应对在有效立足点很少的环境中出现的稀疏奖励,例如间隙或踏脚石。在这项工作中,我们提出了一种混合控制架构,结合了两个领域的优点,同时实现了更高的鲁棒性、脚部放置精度和地形泛化。我们的方法利用基于模型的规划器在训练期间推出参考运动。深度神经网络策略在模拟中进行训练,旨在跟踪优化的立足点。我们评估稀疏地形上运动管道的准确性,在这些地形上,纯数据驱动的方法很容易失败。此外,与基于模型的同类产品相比,我们在湿滑或可变形地面的情况下表现出了卓越的鲁棒性。最后,我们展示了我们提出的跟踪控制器泛化了训练期间未见过的不同轨迹优化方法。GAMMA: Graspability-Aware Mobile MAnipulation Policy Learning based on Online Grasping Pose Fusion
Authors Jiazhao Zhang, Nandiraju Gireesh, Jilong Wang, Xiaomeng Fang, Chaoyi Xu, Weiguang Chen, Liu Dai, He Wang
移动操纵是机器人助手的一项基本任务,并在机器人界引起了极大的关注。移动操纵固有的一个关键挑战是在接近目标进行抓取时有效观察目标。在这项工作中,我们提出了一种可抓取性感知的移动操纵方法,该方法由在线抓取姿势融合框架提供支持,可以实现时间一致的抓取观察。具体来说,预测的抓取姿势是在线组织的,以消除冗余的异常抓取姿势,这些姿势可以被编码为抓取姿势观察状态以进行强化学习。In-Hand Re-grasp Manipulation with Passive Dynamic Actions via Imitation Learning
Authors Dehao Wei, Guokang Sun, Zeyu Ren, Shuang Li, Zhufeng Shao, Xiang Li, Nikos Tsagarakis, Shaohua Ma
重新掌握操纵利用人体工程学工具来帮助人类完成不同的任务。在某些情况下,人类经常利用外力来毫不费力地、精确地重新握住锤子等工具。先前对使用被动动态动作(例如重力)的抓取滑动运动的控制器的开发依赖于对手指物体接触信息的理解,并且需要针对具有不同几何形状和重量分布的单个物体进行定制设计。它限制了它们对不同物体的适应性。在本文中,我们提出了一种基于模仿学习 IL 的端到端滑动运动控制器,它只需要最少的物体力学先验知识,仅依赖于物体位置信息。为了加速训练收敛,我们利用数据手套收集专家数据轨迹,并通过生成对抗模仿学习 GAIL 训练策略。仿真结果证明了控制器在执行具有不同摩擦系数、几何形状和质量的物体的手动滑动任务方面的多功能性。Template Model Inspired Task Space Learning for Robust Bipedal Locomotion
Authors Guillermo A. Castillo, Bowen Weng, Shunpeng Yang, Wei Zhang, Ayonga Hereid
这项工作提出了一个双足运动的分层框架,它将基于强化学习 RL 的高级 HL 规划器策略(用于在线生成任务空间命令)与基于模型的低级 LL 控制器相结合,以跟踪所需的任务空间轨迹。与传统的端到端学习方法不同,我们的 HL 策略从基于角动量的线性倒立摆 ALIP 中汲取见解,精心设计了马尔可夫决策过程 MDP 的观察和行动空间。这种简单而有效的设计在有效捕获双足运动的复杂动态的低维状态与塑造机器人行走步态的一组任务空间输出之间创建了富有洞察力的映射。 HL 策略与任务空间 LL 控制器无关,这增加了框架设计的灵活性和对其他双足机器人的泛化。与基于 ALIP 模型的方法和基于最先进的双足运动学习框架相比,这种分层设计产生了一个基于学习的框架,该框架具有改进的性能、数据效率和鲁棒性。所提出的分层控制器在三种不同的机器人中进行了测试:Rabbit(五连杆欠驱动平面双足机器人 Walker2D)、七连杆全驱动平面双足机器人和 Digit(具有 20 个驱动关节的 3D 人形机器人)。Evaluation of Constrained Reinforcement Learning Algorithms for Legged Locomotion
Authors Joonho Lee, Lukas Schroth, Victor Klemm, Marko Bjelonic, Alexander Reske, Marco Hutter
对于腿式机器人来说,从传统控制策略转向深度强化学习 RL 会带来固有的挑战,特别是在训练期间解决现实世界的物理约束时。虽然高保真度模拟提供了显着的好处,但它们通常会绕过这些基本的物理限制。在本文中,我们针对机器人应用使用约束马尔可夫决策过程 CMDP 框架而不是传统的无约束强化学习进行实验。我们对不同的约束策略优化算法进行比较研究,以确定适合实际实施的方法。我们的机器人实验证明了结合物理约束、成功模拟真实传输以及减少物理系统操作错误的关键作用。 CMDP 公式通过单独处理约束和奖励来简化训练过程。Teach and Repeat Navigation: A Robust Control Approach
Authors Payam Nourizadeh, Michael Milford, Tobias Fischer
机器人导航需要一个能够适应环境变化并在不同条件下有效的自主管道。教学和重复 TR 导航在具有挑战性的环境下自主重复任务中表现出了高性能,但 TR 内的研究主要集中在运动规划而不是运动控制上。在本文中,我们提出了一种基于鲁棒运动控制技术的新型 TR 系统,用于使用滑模控制的滑移转向移动机器人,该系统有效地处理了 T R 任务中特别明显的不确定性,其中传感器噪声、参数不确定性和车轮地形互动是共同的挑战。我们首先从理论上证明,在考虑闭环系统的不确定性的同时,所提出的 T R 系统具有全局稳定和鲁棒性。当部署在 Clearpath Jackal 机器人上时,我们展示了所提出的系统在覆盖不同地形的室内和室外环境中的全局稳定性,在这些具有挑战性的环境中的平均轨迹误差和稳定性方面优于以前最先进的方法。MINS: Efficient and Robust Multisensor-aided Inertial Navigation System
Authors Woosik Lee, Patrick Geneva, Chuchu Chen, Guoquan Huang
IMU、车轮编码器、摄像头、激光雷达和 GPS 等多模态测量的鲁棒多传感器融合具有巨大的潜力,因为它具有提高传感器故障和测量异常值恢复能力的固有能力,从而实现强大的自主性。据我们所知,这项工作是第一个开发一致的紧密耦合多传感器辅助惯性导航系统 MINS 的工作,该系统能够通过解决计算复杂性的特殊挑战,将最常见的导航传感器融合在高效的过滤框架中,传感器异步性和传感器内校准。特别是,我们提出了一致的高阶流形插值方案,以实现高效的异步传感器融合和状态管理策略,即动态克隆。所提出的动态克隆利用运动引起的信息来自适应地选择插值顺序以控制计算复杂性,同时最小化轨迹表示误差。我们对所有机载传感器进行在线内在和外在时空校准,以补偿先前校准不佳和/或随时间变化而降低的校准。此外,我们开发了一种初始化方法,仅使用 IMU 和车轮编码器的本体感受测量,而不是外感受传感器,该方法受环境影响较小,并且在高动态场景中更稳健。我们在模拟和大规模具有挑战性的现实世界数据集中广泛验证了所提出的 MINS,在定位精度、一致性和计算效率方面优于现有的最先进方法。Adversarial Object Rearrangement in Constrained Environments with Heterogeneous Graph Neural Networks
Authors Xibai Lou, Houjian Yu, Ross Worobel, Yang Yang, Changhyun Choi
现实世界中的对抗性对象重新排列,例如厨房和商店中以前未见过或超大的物品可以从理解任务场景中受益,任务场景本质上需要异构组件,例如当前对象、目标对象和环境约束。这些组件之间的语义关系彼此不同,对于多技能机器人在日常场景中高效执行至关重要。我们提出了一种分层机器人操纵系统,该系统可以学习潜在的关系并最大化其不同技能的协作能力,例如在受限环境中选择位置、推动重新排列敌对对象。高级协调器采用异构图神经网络 HetGNN,它对当前对象、目标对象和环境约束进行推理,基于低级 3D 卷积神经网络的参与者执行动作原语。我们的方法完全在模拟中进行训练,在现实世界的实验中取得了 87.88 的平均成功率和 12.82 的规划成本,超过了所有基线方法。Human-robot Matching and Routing for Multi-robot Tour Guiding under Time Uncertainty
Authors Bo Fu, Tribhi Kathuria, Denise Rizzo, Matthew Castanier, X. Jessie Yang, Maani Ghaffari, Kira Barton
这项工作提出了一个在部分已知的不确定环境(例如博物馆)中进行多机器人导游的框架。提出了同步匹配和路由问题 SMRP,根据人类请求的兴趣点 POI 将人类与机器人向导进行匹配,并根据不确定的时间估计生成机器人的路线。开发了大邻域搜索算法来有效地找到 SMRP 的次优低成本解决方案。通过计算评估多机器人规划器的可扩展性和最优性。最大的测试案例涉及 50 个机器人、250 名人类和 50 个 POI。Analysis on Multi-robot Relative 6-DOF Pose Estimation Error Based on UWB Range
Authors Xinran Li, Shuaikang Zheng, Pengcheng Zheng, Haifeng Zhang, Zhitian Li, Xudong Zou
相对位姿估计是多机器人系统的基本要求,而在无基础设施的场景中这是一个具有挑战性的研究课题。在本研究中,我们分析了 GNSS 拒绝和无锚环境中多机器人系统的相对 6 DOF 位姿估计误差。假设节点之间的距离远大于机器人平台的尺寸,给出了位置和方向估计误差的解析下限。通过仿真,讨论了节点间距离、标签单纯形的高度和外接圆半径对位姿估计精度的影响,验证了分析结果。我们的分析预计将确定参数,例如Multimodal Dataset for Localization, Mapping and Crop Monitoring in Citrus Tree Farms
Authors Hanzhe Teng, Yipeng Wang, Xiaoao Song, Konstantinos Karydis
在这项工作中,我们介绍了 CitrusFarm 数据集,这是一个由在农业领域操作的轮式移动机器人收集的综合多模态感官数据集。该数据集提供带有深度信息的立体 RGB 图像以及单色、近红外和热图像,呈现对农业研究至关重要的多种光谱响应。此外,它还提供一系列导航传感器数据,包括车轮里程计、LiDAR、惯性测量单元 IMU 和 GNSS(以实时运动 RTK 作为厘米级定位地面实况)。该数据集包含在三个柑橘树田中收集的七个序列,具有不同生长阶段的各种树种、独特的种植模式以及不同的日照条件。总运行时间为1.7小时,覆盖距离为7.5公里,数据量为1.3TB。我们预计该数据集可以促进在农业树木环境中运行的自主机器人系统的开发,特别是用于定位、测绘和作物监测任务。此外,该数据集中提供的丰富的传感模式还可以支持一系列机器人和计算机视觉任务的研究,例如地点识别、场景理解、对象检测和分割以及多模态学习。Self-Supervised Terrain Representation Learning from Unconstrained Robot Experience
Authors Haresh Karnan, Elvin Yang, Daniel Farkash, Garrett Warnell, Joydeep Biswas, Peter Stone
地形感知,即识别和区分不同类型地形的能力,是机器人成功实现自主越野导航所必须具备的关键能力。目前为机器人提供这种意识的方法要么依赖于收集成本昂贵的标记数据,要么依赖于可能无法概括的工程特征和成本函数,要么依赖于可能无法获得的专家人类演示。为了赋予机器人不受这些限制的地形感知,我们引入了自监督地形表示学习 STERLING,这是一种学习地形表示的新颖方法,仅依赖于易于收集、不受约束(例如非专家和无标签的机器人经验),并且没有额外的约束数据采集。 STERLING 采用新颖的多模态自我监督目标,通过非对比表示学习来学习相关地形表示,以实现地形感知导航。通过越野环境中的物理机器人实验,我们评估了 STERLING 特征在偏好对齐视觉导航任务中的表现,发现 STERLING 特征的性能与完全监督的方法相当,并且在偏好对齐方面优于其他最先进的方法。Multi-Modal Planning on Regrasping for Stable Manipulation
Authors Jiaming Hu, Zhao Tang, Henrik I. Christensen
如今,已经提出了许多抓取算法,即使对于看不见的物体也可以预测候选抓取姿势。这使得机器人操纵器能够拾取和放置此类物体。然而,由于工作空间限制,一些稳定举起目标物体的预测抓取姿势可能无法直接接近。在这种情况下,机器人将需要重新抓取所需的物体才能成功抓取它。这涉及规划一系列连续动作,例如滑动、重新抓取和转移。为了解决这个多模态问题,我们提出了一种基于马尔可夫决策过程的多模态规划器,它可以将对象重新排列到适合稳定操纵的位置。Out of Sight, Still in Mind: Reasoning and Planning about Unobserved Objects with Video Tracking Enabled Memory Models
Authors Yixuan Huang, Jialin Yuan, Chanho Kim, Pupul Pradhan, Bryan Chen, Li Fuxin, Tucker Hermans
机器人需要对之前观察到但当前被遮挡的物体有记忆,才能在现实环境中可靠地工作。我们研究了将面向对象的内存编码到多对象操作推理和规划框架中的问题。我们提出了 DOOM 和 LOOM,它们利用变压器关系动力学来编码给定部分视点云和对象发现和跟踪引擎的轨迹历史。我们的方法可以执行多种具有挑战性的任务,包括用被遮挡的对象进行推理、新颖的对象出现和对象再现。在我们广泛的模拟和现实世界实验中,我们发现我们的方法在不同数量的物体和不同数量的干扰动作方面表现良好。Zero-Shot Constrained Motion Planning Transformers Using Learned Sampling Dictionaries
Authors Jacob J. Johnson, Ahmed H. Qureshi, Michael C. Yip
受限机器人运动规划是机器人与日常环境交互的普遍需求,但这是一个众所周知的难以解决的问题。基于样本的规划器中的许多采样点需要被拒绝,因为它们超出了约束流形,或者需要大量的迭代工作来纠正。鉴于此,很少有解决方案能够在合理的时间内以较低的路径成本提供满足机器人轨迹的约束。在这项工作中,我们提出了一种基于变压器的运动规划模型,具有操纵系统的任务空间约束。矢量量化运动规划转换器 VQ MPT 是一种最新的基于学习的模型,可减少基于采样的运动规划器的无约束规划的搜索空间。我们建议采用预先训练的 VQ MPT 模型来减少约束规划的搜索空间,而无需重新训练或微调模型。我们还建议更新神经网络输出,以使采样区域更接近约束流形。我们的实验表明,与模拟和现实环境中的传统规划器相比,VQ MPT 如何提高规划时间和准确性。与之前需要任务相关数据的学习方法不同,我们的方法使用预先训练的神经网络模型,不需要额外的数据来训练和微调模型,从而使该过程成为一个文本处理过程。我们还在具有真实世界传感器数据的弗兰卡熊猫物理机器人上测试了我们的方法,证明了我们算法的通用性。Kinematic Modularity of Elementary Dynamic Actions
Authors Moses C. Nah, Johannes Lachner, Federico Tessari, Neville Hogan
在本文中,提出了一种机器人控制的运动学模块化方法。该方法涉及称为基本动态动作的结构以及组合这些元素的网络模型。有了这个控制框架,可以通过基本运动学模块的组合来生成丰富的运动指令。每个模块都可以通过模仿学习来学习,从而形成机器人控制的模块化学习策略。介绍了理论基础及其实际的机器人实现。使用 KUKA LBR iiwa14 机器人,考虑三个任务:1 生成一系列离散运动,2 生成离散和有节奏运动的组合,以及 3 绘图和擦除任务。ObVi-SLAM: Long-Term Object-Visual SLAM
Authors Amanda Adkins, Taijing Chen, Joydeep Biswas
负责长时间尺度任务的机器人必须能够在几何、视角和外观变化的情况下进行一致且可扩展的定位。现有的视觉 SLAM 方法依赖于低级特征描述符,这些特征描述符对于此类环境变化并不稳健,并且会导致地图尺寸过大,在长期部署中扩展性较差。相比之下,对象检测对环境变化具有鲁棒性,并且可以实现更紧凑的表示,但大多数基于对象的 SLAM 系统都针对近距离对象的短期室内部署。在本文中,我们引入了 ObVi SLAM,通过利用这两种方法的优点来克服这些挑战。 ObVi SLAM 使用低级视觉功能来实现高质量的短期视觉里程计,并确保全局、长期的一致性,ObVi SLAM 构建持久性对象的不确定性感知长期地图,并在每次部署后更新它。Finding Biomechanically Safe Trajectories for Robot Manipulation of the Human Body in a Search and Rescue Scenario
Authors Elizabeth Peiros, Zih Yun Chiu, Yuheng Zhi, Nikhil Shinde, Michael C. Yip
人们越来越认识到在大规模伤亡事故(例如自然灾害造成的事故)中救援人员并从其中救出人员的困难。虽然平台的设计考虑到了救助伤员,甚至将他们带出危险,但将伤员从现有的配置重新定位到适合撤离的配置的挑战尚未得到明确探讨。此外,这个规划问题需要考虑伤员的生物力学安全因素。因此,我们提出了第一个生物力学安全轨迹生成解决方案,用于重新定位无意识的人类伤亡人员的肢体。我们将生物力学安全性描述为数学约束、机器人人体耦合系统动力学的机械描述,以及考虑该耦合和约束系统的规划和轨迹优化过程。最后,我们对问题的几种变体评估了我们的方法,并在真实的机器人和人类受试者上进行了演示。V2X-Lead: LiDAR-based End-to-End Autonomous Driving with Vehicle-to-Everything Communication Integration
Authors Zhiyun Deng, Yanjun Shi, Weiming Shen
本文提出了一种基于 LiDAR 的端到端自动驾驶方法,该方法具有车对万物 V2X 通信集成(称为 V2X Lead),以解决在混合自动驾驶交通条件下导航不受监管的城市场景的挑战。该方法旨在通过融合机载 LiDAR 传感器和 V2X 通信数据来处理不完美的部分观测结果。采用无模型且无策略的深度强化学习 DRL 算法来训练驾驶代理,该算法结合了精心设计的奖励函数和多任务学习技术,以增强跨不同驾驶任务和场景的泛化能力。实验结果证明了所提出的方法在提高混合自主交通中穿越无信号交叉口任务的安全性和效率方面的有效性,及其对以前未见过的场景(例如环岛)的普遍性。Multi-Robot Cooperative Socially-Aware Navigation Using Multi-Agent Reinforcement Learning
Authors Weizheng Wang, Le Mao, Ruiqi Wang, Byung Cheol Min
在与人类共享的公共空间中,确保多机器人系统在尊重社会规范的同时不发生碰撞导航是一项挑战,特别是在通信有限的情况下。尽管当前的机器人社交导航技术利用了强化学习和深度学习的进步,但它们经常忽视模拟中的机器人动力学,导致模拟与现实存在差距。在本文中,我们通过提出一个使用 Dec POSMDP 和多代理强化学习精心制作的新的多机器人社交导航环境来弥补这一差距。此外,我们还推出了 SAMARL ,这是一种用于协作多机器人社交导航的新颖基准。 SAMARL 采用独特的时空变换器与多智能体强化学习相结合。这种方法有效地捕捉了机器人和人类之间复杂的交互,从而促进了多机器人系统中的合作倾向。我们广泛的实验表明,SAMARL 在我们设计的环境中优于现有的基线和消融模型。Learning Optimal Trajectories for Quadrotors
Authors Yuwei Wu, Xiatao Sun, Igor Spasojevic, Vijay Kumar
本文提出了一种新颖的基于学习的四旋翼飞行器轨迹规划框架,它将基于模型的优化技术与深度学习相结合。具体来说,我们使用分段轨迹段通过安全飞行走廊 1 将轨迹优化问题表述为具有动态和无碰撞约束的二次规划 QP 问题。我们训练神经网络直接学习每个片段的时间分配,以生成最佳的平滑和快速的轨迹。此外,约束优化问题被用作网络中反向传播的单独隐式层,可以获得差分损失函数。我们引入了一个额外的惩罚函数来惩罚导致违反约束的解决方案的时间分配,以加速训练过程并提高原始优化问题的成功率。为此,我们通过在训练期间添加额外的句子结尾标记来启用灵活数量的分段轨迹序列。A Tutorial on Uniform B-Spline
Authors Yi ZhouDREAM-PCD: Deep Reconstruction and Enhancement of mmWave Radar Pointcloud
Authors Ruixu Geng, Yadong Li, Dongheng Zhang, Jincheng Wu, Yating Gao, Yang Hu, Yan Chen
毫米波毫米波雷达点云由于其在烟雾和低照度等挑战性条件下的鲁棒性,为 3D 传感提供了极具吸引力的潜力。然而,现有方法未能同时解决毫米波雷达点云重建中镜面信息丢失、角分辨率低、干扰和噪声强等三大挑战。在本文中,我们提出了 DREAM PCD,这是一种新颖的框架,它将信号处理和深度学习方法结合到三个精心设计的组件中,以解决密集点的非相干累加、用于提高角分辨率的合成孔径累加和真实降噪多帧网络的所有三个挑战用于消除噪声和干扰。此外,DREAM PCD 中的因果多帧和真实降噪机制显着增强了泛化性能。我们还推出了 RadarEyes,这是最大的毫米波室内数据集,超过 1,000,000 帧,采用独特的设计,融合了两个正交单芯片雷达、激光雷达和摄像头,丰富了数据集的多样性和应用。实验结果表明,DREAM PCD在重建质量上超越了现有方法,并表现出优越的泛化性和实时性,能够在各种参数和场景下实现雷达点云的高质量实时重建。Maximum Diffusion Reinforcement Learning
Authors Thomas A. Berrueta, Allison Pinosky, Todd D. Murphey
数据独立且同分布的假设是所有机器学习的基础。当从代理经验中顺序收集数据时,这种假设通常不成立,就像在强化学习中一样。在这里,我们推导出一种通过利用遍历过程的统计力学来克服这些限制的方法,我们将其称为最大扩散强化学习。通过解除代理体验的相关性,我们的方法可以证明代理能够在单次部署中持续学习,无论它们是如何初始化的。此外,我们证明我们的方法概括了众所周知的最大熵技术,并表明它在流行的基准测试中远远超过了最先进的性能。Chinese Abs From Machine Translation
-
相关阅读:
echarts 双向柱状图 共用y轴
chap14.all
绿联搭建rustdesk服务器
Java 最常见的 200+ 面试题:面试必备
Ansible自动化部署安装openGauss3.1企业版单机
猿创征文|【深度学习前沿应用】文本生成
Maven配置单仓库与多仓库(Nexus)
Linux自动化运维工具ansible详解
前端面试回答不好的问题总结
数电学习(六、时序逻辑电路)(三)
- 原文地址:https://blog.csdn.net/u014636245/article/details/133382018