-
go中的map
map的特点
- 键不能重复
- 键必须可哈希
- 无序
哈希表存储原理
取模+拉链
假如有一个map: {“name”:“白小白”,“age”:“18”}
- 计算键的哈希值,如name的哈希值为:1239837243423,age的哈希值为:982399934424
- 假设一个空间分为四份,那么根据哈希值取模,1239837243423%4=3,那么name就存储到索引为3的地方,982399934424%4=0,那么age就存储到索引为0的地方,如果此时map中又有一个kv:sex:男,取模后为0,那么这个kv就存放到age的右边,如下图所示:
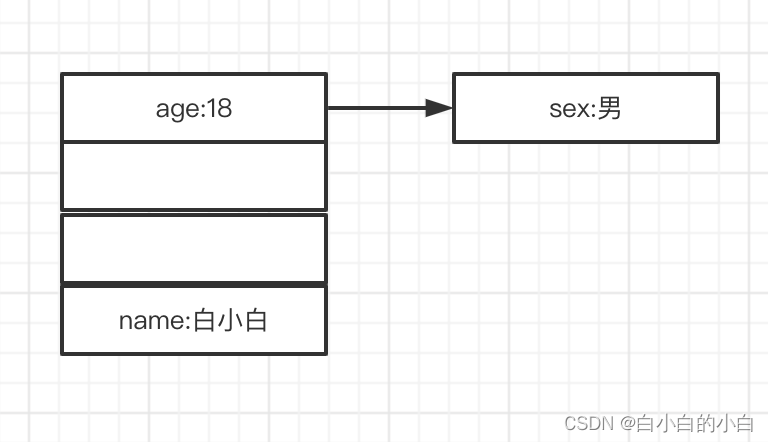
- 而age、sxe组成的就是拉链,这就是哈希表的存储原理,不管是python的字典还是go中的map都是在此基础上优化出来的
声明/初始化
package main import ( "fmt" ) func main() { // 第一种定义方法,并初始化十个位置 // m := make(map[string]string, 10) // 第二种定义map m := map[string]string{"name": "baixiaobai", "sex": "男"} // 修改变量 m["sex"] = "女" // 新增变量 m["age"] = "20" // 删除变量 delete(m, "sex") // 查看 for key, val := range m{ fmt.Println(key) fmt.Println(val) } fmt.Printf("m is %s\n", m) // 第三种,这种适用于整体赋值,引用 // var row map[string]string row := m row["name"] = "白小黑" fmt.Printf("m is %s\n", m) fmt.Printf("row is %s\n", row) // 第四种,这种适用于整体赋值,引用 // m := new(map[string]string) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
go map
go种的map有自己的一套实现原理,其核心是hmap和bmap两个结构体实现
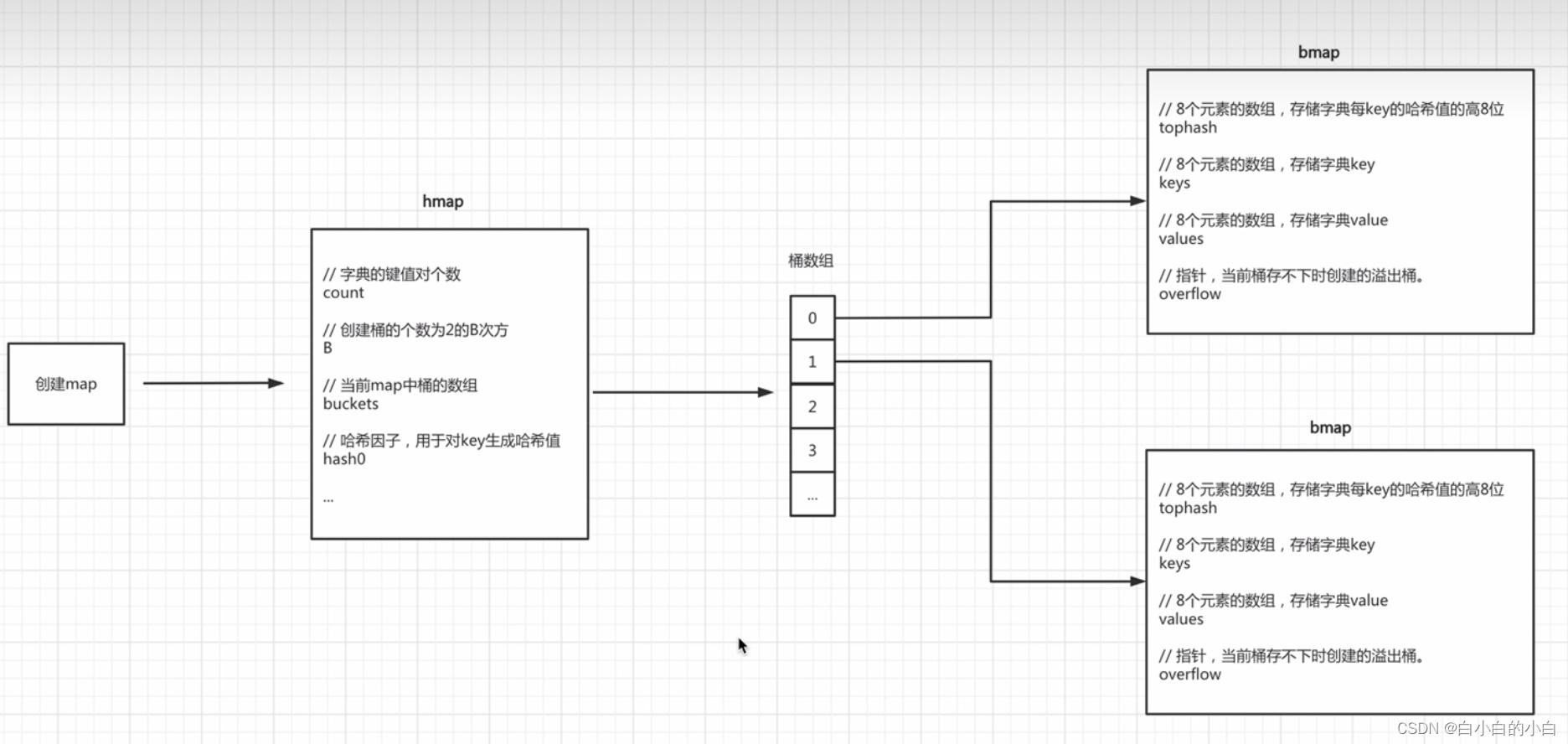
hmap结构体不存放具体的kv,具体的kv是放在bmap中,我们通常称之为桶初始化
- 创建一个hmap结构体对象 info = make(map[string]string,10)
- 生成一个哈希因子hash0并赋值到hamp对象中
- 根据hint=10,并根据算法规则来创建B,当前B应该为1
hint. B 0-8 0 9-13 1 14-26 2- 1
- 2
- 3
- 4
-
由此可知,这次创建的桶数组为2个,可以存放16个kv,注意,这个B也不是一成不变的,有一定的规则
- 当B<4时,为2的B次方
- 当B>=4时,为2的B次方 + 2的(B-4次方) 标准桶+溢出桶
-
注意:每个bmap中可以存储8个键值对,当不够存储是需要使用溢出桶,并将当前bamp中的overflow字段指向溢出桶的位置
放入数据
- 放入数据info[“name”] = “baixiaobai”
- 结合哈希因子和键name生产哈希值,如01111011010101010101
- 获取哈希值的后B位(低B位),并根据后B位的值来决定将此键值对放入那个桶中,如上面的例子中,B为1,那么产生2个桶,那么取后一位,那么此键值对以及高8位(前8位)将放入第二个桶中
- 将hmap的count的值加1
读取数据
- 读取数据value := info[“name”]
- 结合哈希因子和键name生产哈希值,如01111011010101010101
- 获取哈希值的后B位,并根据后B位来查找存放到那个桶中
- 确定桶后,在根据哈希值的高8位来查找所处的具体位置
- 如果当前桶没有找到,则根据overflow再去溢出桶去查找
map扩容
在向map中添加数据时,当达到一定条件后,则会发生扩容
扩容条件:- map中数据的总个数/桶个数>6.5,引发翻倍扩容
- 使用了太多的溢出桶时(溢出桶太多会导致map的处理速度降低)
- B <= 15,已使用的溢出桶个数>=2的B次方时,引发等量扩容
- B > 15,已使用的溢出桶个数>=2的15次方时,引发等量扩容

线程安全
- map默认是并发不安全的,同时对map进行并发读写时,程序会panic,原因如下:
Go 官方在经过了长时间的讨论后,认为 Go map 更应适配典型使用场景(不需要从多个 goroutine 中进行安全访问),而不是为了小部分情况(并发访问),导致大部分程序付出加锁代价(性能),决定了不支持 - map本身不是线程安全的,当然go语言已经内置提供了线程安全 map,即 sync.Map
import "sync" type SafeDict struct { data map[string]int *sync.RWMutex } func NewSafeDict(data map[string]int) *SafeDict { return &SafeDict{data, &sync.RWMutex{}} } func (d *SafeDict) Len() int { d.RLock() defer d.RUnlock() return len(d.data) } func (d *SafeDict) Put(key string, value int) (int, bool) { d.Lock() defer d.Unlock() old_value, ok := d.data[key] d.data[key] = value return old_value, ok } func (d *SafeDict) Get(key string) (int, bool) { d.RLock() defer d.RUnlock() old_value, ok := d.data[key] return old_value, ok } func (d *SafeDict) Delete(key string) (int, bool) { d.Lock() defer d.Unlock() old_value, ok := d.data[key] if ok { delete(d.data, key) } return old_value, ok }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
map遍历为什么是无序的
- map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的cell开始遍历
- map遍历时,是按序遍历bucket,同时按需遍历bucket中和其overflow bucket中的cell。但是map在扩容后,会发生key的搬迁,这造成原来落在一个bucket中的key,搬迁后,有可能会落到其他bucket中了,从这个角度看,遍历map的结果就不可能是按照原来的顺序了
-
相关阅读:
u16 转为 int
基于行为树的高级游戏AI教程
无涯教程-Android - List fragments函数
C进阶--字符函数和字符串函数介绍
阿里云云原生一体化数仓 — 分析服务一体化新能力解读
style样式优先级问题【display:block依旧无法显示DOM元素】
GPT-5技术突破预测:革新NLP的未来
彻底搞懂Mybatis
【Spring】使用xml配置AOP
CLIP模型原理
- 原文地址:https://blog.csdn.net/qq_42874635/article/details/126637500
