-
第03章 Xpath 入门
序言
1. 内容介绍
本章详细介绍了 XPath 安装创建方法、XPath 路径的获取方法及节点选择方法等内容。
2. 理论目标
- 了解 XPath 安装方法
- 了解 XPath 创建方法及相关元素
- 了解 XPath 路径的获取方法及节点选择方法
3. 实践目标
- 能掌握 XPath 的安装和创建方法,完成网页关键信息提取
4. 实践案例
无
5. 内容目录
-
1.XPath 基本使用
-
2.XPath 节点选择
-
3.XPath 路径获取
第1节 XPath 基本使用
1. XPath概述
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。
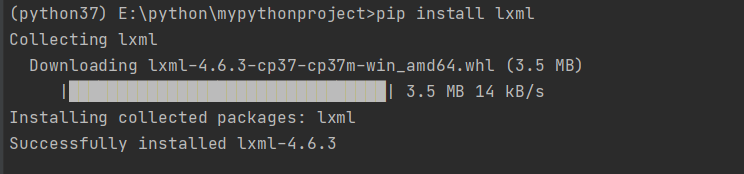
XPath 安装:
pip install lxml安装BeautifulSoup 时已安装。
2. XPath 对象创建
通过字符串创建XPath 解析对象
导入lxml 库
from lxml import etree读取字符串构造XPath 解析对象,调用 HTML 类进行初始化,成功构造一个 XPath 解析对象。
webdata = ''' '''html = etree.HTML(webdata) print(html)<Element html at 0x1e7e8fc8280>修正HTML 代码,调用tostring() 方法修正HTML 代码:li 节点标签被补全,并且还自动添加了 body、html 节点。
补充完但结果是 bytes 类型,可以用 decode() 方法将其转化为 str 类型result = etree.tostring(html) print(result) print(result.decode("utf-8"))b'\n'通过文件创建XPath 解析对象
导入lxml 库
from lxml import etree读取HTML文档构造XPath 解析对象,文档内容(和前面字符串一样):

## 读取html 文档,构造XPath 解析对象 html = etree.parse('example.html', etree.HTMLParser(encoding='utf-8')) #指定文件编码 print(html)<lxml.etree._ElementTree object at 0x000001E7E8FC4D40>修正HTML 代码
result = etree.tostring(html) print(result) print(result.decode("utf-8"))b'\n'3. XPath 节点选择示例及常用规则
XPath 节点选择常用规则
表达式 描述 nodename 选取此节点的所有子节点 / 从当前节点选取直接子节点 // 从当前节点选取子孙节点 . 选取当前节点 … 选取当前节点的父节点 @ 选取属性 XPath 节点选择示例
## 从XPath 解析对象html 选择所有标签 a,返回列表 XPathdata = html.xpath('//a') print(XPathdata)[<Element a at 0x1e7e90da040>, <Element a at 0x1e7e90da900>, <Element a at 0x1e7e90ca280>, <Element a at 0x1e7e90cadc0>, <Element a at 0x1e7e8fc2640>, <Element a at 0x1e7e8fe8180>]
第2节 XPath 节点选择
1. 选择所有节点
//* 选择所有节点,其中:
- // 选取所有符合要求的节点
- * 代表匹配所有节点
## 选择当前节点下的所有节点 result = html.xpath('//*') print(result)[<Element html at 0x1e7e90ca540>, <Element body at 0x1e7e90da5c0>, <Element div at 0x1e7e90dad40>, <Element div at 0x1e7e90dae80>, <Element div at 0x1e7e90da100>, <Element div at 0x1e7e90dadc0>, <Element a at 0x1e7e90da040>, <Element span at 0x1e7e90e95c0>, <Element a at 0x1e7e90da900>, <Element a at 0x1e7e90ca280>, <Element a at 0x1e7e90cadc0>, <Element a at 0x1e7e8fc2640>, <Element a at 0x1e7e8fe8180>]## 选择当前节点下的所有标签名为a 的节点 result = html.xpath('//a') print(result)[<Element a at 0x1e7e90da040>, <Element a at 0x1e7e90da900>, <Element a at 0x1e7e90ca280>, <Element a at 0x1e7e90cadc0>, <Element a at 0x1e7e8fc2640>, <Element a at 0x1e7e8fe8180>]2. 选择子节点
/nodename 或 //nodename,用来获取直接子节点 或 所有子孙节点
## 选择直接子节点 html result = html.xpath('/html') print(result)[<Element html at 0x1e7e90ca540>]## 选择所有子孙节点 result = html.xpath('//div') print(result)[<Element div at 0x1e7e8f84f40>, <Element div at 0x1e7e90ef380>, <Element div at 0x1e7e90efa00>, <Element div at 0x1e7e90ef3c0>]3. 选择父节点
/… 知道子节点,查询父节点可以用 … 来实现
## 选择 a 节点的父节点 result = html.xpath('//a/..') print(result)[<Element div at 0x1e7e8fa5880>]4. 匹配属性
nodename[@attname=“value”] 匹配时进行属性过滤,其中:nodename 标签名称、attname 属性名称、value 属性值
## 选择 a 节点且属性name="tj_trnews"的节点 result = html.xpath('//a[@name="tj_trnews"]') print(result)[<Element a at 0x1e7e90da040>]5. 获取属性
@name,直接获取节点的属性值
## 选择所有 a 子节点属性"href" 的值 result = html.xpath('//a/@href') print(result)['http://news.baidu.com', 'https://www.hao123.com', 'http://map.baidu.com', 'http://v.baidu.com', 'http://tieba.baidu.com', '//www.baidu.com/more/']6. 匹配属性多值
nodename[contains(@attname, “str”)] 匹配一个属性值中包含的字符串,而不是某个值。其中:nodename 标签名称、attname 属性名称、str 属性值串
## 选择所有 a 子节点属性"class"值="bri"的节点 result = html.xpath('//a[contains(@class, "bri")]') print(result)[<Element a at 0x1e7e8fe8180>]7. 匹配多属性
nodename[contains(@attname1, “str1”) and/or contains(@attname2, “str2”)] 节点有多个属性时,同时匹配多个属性。
## 选择所有 a 子节点(属性"class"值="mnav") 且 (属性"name"值*"tj_trnews")的节点 result = html.xpath('//a[contains(@class, "mnav") and @name="tj_trnews"]') print(result)[<Element a at 0x1e7e90da040>]8. 选择匹配结果
nodename[1] 匹配结果有多个节点,可以通过中括号内加索引或其他相应语法获得
result = html.xpath('//a[1]/text()') print("获取第一个:", result) result = html.xpath('//a[last()]/text()') print("\n获取最后一个:", result) result = html.xpath('//a[position()<3]/text()') print("\n获取前两个:", result) result = html.xpath('//a[last()-2]/text()') print("\n获取倒数第三个:", result)- 获取第一个: []
- 获取最后一个: ['更多产品 ']
- 获取前两个: ['hao123 ']
- 获取倒数第三个: ['视频 ']
9. 获取文本
/text() 或 //text()
/text():获取文本所在节点后直接获取文本,推荐此方法,保证获取的结果是整洁的
//text():会获取到补全代码时换行产生的特殊字符## 选择所有 a 子节点的文本 result = html.xpath('//a/text()') print(result)['hao123 ', '地图 ', '视频 ', '贴吧 ', '更多产品 ']## 选择所有 a 子节点的文本 result = html.xpath('//a//text()') print(result)['first item', 'hao123 ', '地图 ', '视频 ', '贴吧 ', '更多产品 ']10. 选择节点轴
通过XPath的节点轴,可获取祖先节点,父节点、子节点、兄弟节、属性值等
result = html.xpath('//a/ancestor::*') print("获取所有祖先节点:", result) result = html.xpath('//a/ancestor::div') print("\n获取祖先节点div:", result) result = html.xpath('//a[1]/attribute::*') print("\n获取当前节点所有属性值:", result) result = html.xpath('//div/child::a[@href="https://www.hao123.com"]/text()') print("\n获取 href 属性值为 link1.html 的直接子节点:", result) result = html.xpath('//a[1]/descendant::span/text()') print("\n获取所有的的子孙节点中包含 span 节点:", result) result = html.xpath('//a[1]/following::*[2]/text()') print("\n获取当前所有节点之后的第二个节点:", result) result = html.xpath('//a[1]/following-sibling::*/text()') print("\n获取当前节点之后的所有同级节点:", result)- 获取所有祖先节点: [<Element html at 0x1e7e90ca540>, <Element body at 0x1e7e90fb040>, <Element div at 0x1e7e90fb080>, <Element div at 0x1e7e90fb0c0>, <Element div at 0x1e7e90fb100>, <Element div at 0x1e7e90fb180>]
- 获取祖先节点div: [<Element div at 0x1e7e90fb080>, <Element div at 0x1e7e90fb0c0>, <Element div at 0x1e7e90fb100>, <Element div at 0x1e7e90fb180>]
- 获取当前节点所有属性值: ['mnav', 'http://news.baidu.com', 'tj_trnews']
- 获取 href 属性值为 link1.html 的直接子节点: ['hao123 ']
- 获取所有的的子孙节点中包含 span 节点: ['first item']
- 获取当前所有节点之后的第二个节点: ['地图 ']
- 获取当前节点之后的所有同级节点: ['hao123 ', '地图 ', '视频 ', '贴吧 ', '更多产品 ']
XPath的节点轴如下:
轴名称 结果 ancestor 选取当前节点的所有先辈(父、祖父等)。 ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 attribute 选取当前节点的所有属性。 child 选取当前节点的所有直接子元素。 descendant 选取当前节点的所有后代元素(子、孙等)。 descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 following 选取文档中当前节点的结束标签之后的所有节点。 following-sibling 选取当前节点之后的所有同级节点。 namespace 选取当前节点的所有命名空间节点。 parent 选取当前节点的父节点。 preceding 选取文档中当前节点的开始标签之前的所有同级节点及同级节点下的节点。 preceding-sibling 选取当前节点之前的所有同级节点。 self 选取当前节点。
开始实验
第3节 XPath 路径获取
1. XPath helper获取
XPath helper介绍
XPath helper 是一款 Chrome 浏览器的开发者插件,安装了 XPath helper 后就能轻松获取 HTML元素的 XPath,程序员就再也不需要通过搜索 html 源代码,定位一些 id 去找到对应的位置去解析网页了。

XPath helper安装
step1.下载并修改文件类型
XPath helper下载地址,链接: https://pan.baidu.com/s/1A4Li8e15jNHFhPfTcubGQQ 提取码: b2pb
下载好的文件名“XPath-helper.crx”,修改为:“XPath-helper.rar”,然后解压。

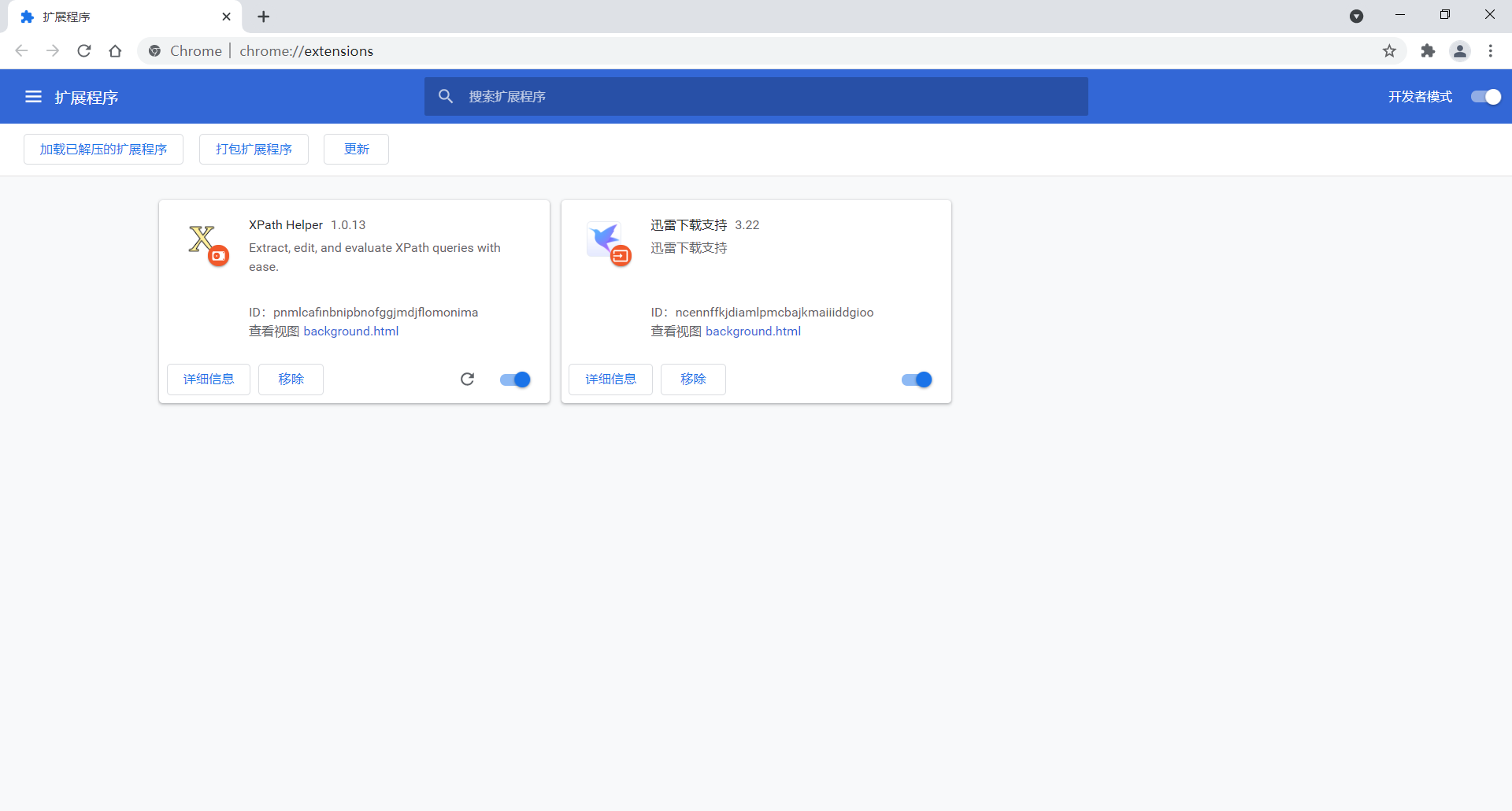
step2.启动浏览器安装XPath helper
打开“扩展程序”页面

选择“加载已解压的扩展程序”

选择解压的目录

加载成功
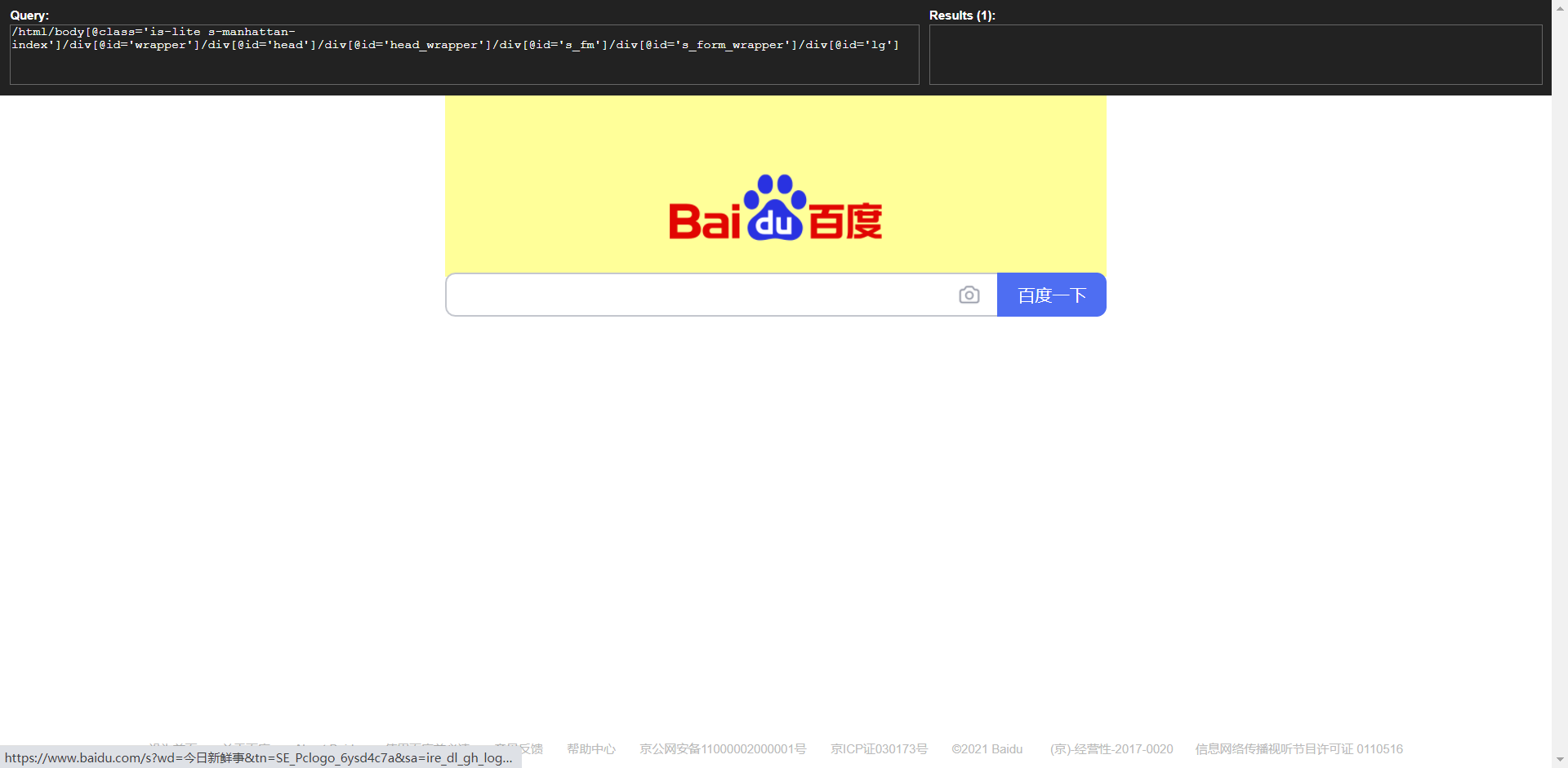
XPath helper使用
step1.启动XPath:Ctrl + Shift + X,再按一次即可关闭

step2.选择元素,查看元素XPath的值
同时按住“Ctrl + Shift”,移动鼠标,被选中的元素会显示不同的颜色。
- query 窗口中显示的就是XPath的值;
- result 窗口有显示对应的内容(部分文字内容、链接属性)。
可以把写好的XPath值粘贴到query 窗口,result 窗口不显示null,标识准确
将以上获得的XPath的值粘贴到 .XPath()里面即可拿到相应的元素值
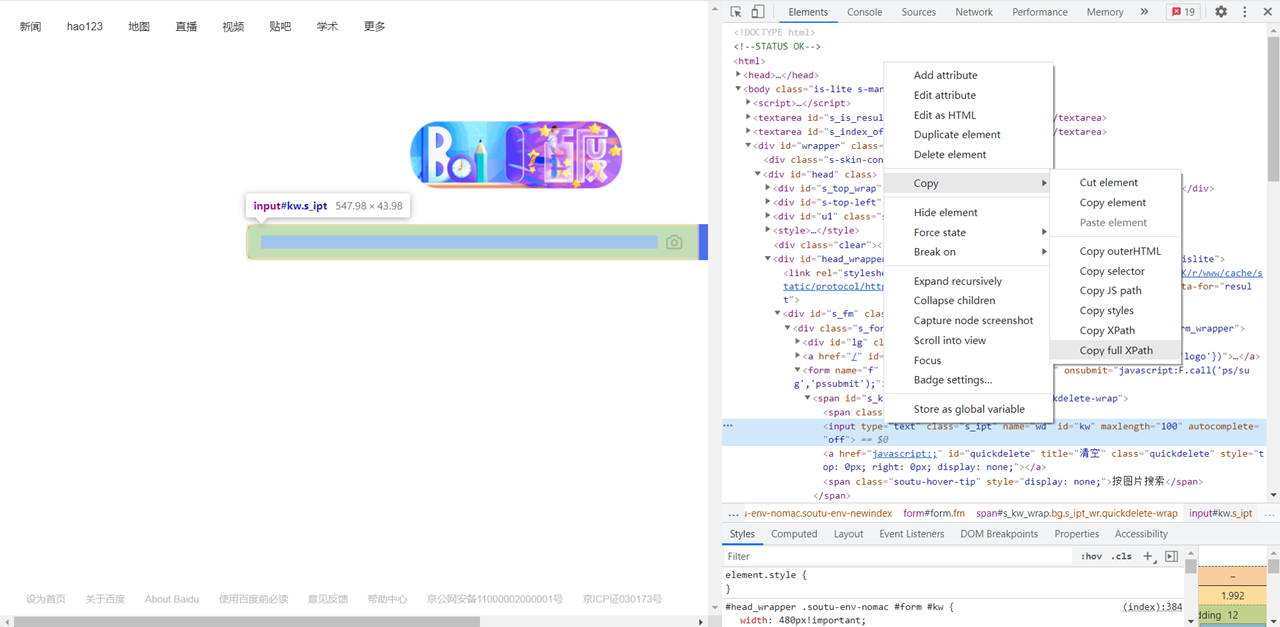
2. 浏览器获取
浏览器获取XPath 路径步骤
- 在爬取页面,打开“开发者工具”;
- 找到待提取信息的源代码处,右击“copy-copy full XPath”,即获取XPath值;
若“copy-copy XPath”,则获取到的值是最短路径,不是包含全路径
开始实验
第4节 附录
-
相关阅读:
区块链是如何实现与现实相连接的?
JavaWeb JSTL标签库
C和C++关键字
汇编语言(第三版)第二章 寄存器 笔记
JDBC中execute、executeQuery和executeUpdate的区别
腾讯配合监管机构:未经批准不得发布新应用或更新版本
GEO生信数据挖掘(五)提取临床信息构建分组,分组数据可视化(绘制层次聚类图,绘制PCA图)
van-popup滑动卡顿并且在有时候在ios上经常性滑动卡顿的情况
关于git hooks
Linux权限
- 原文地址:https://blog.csdn.net/a1234556667/article/details/126447419