-
tf_course4
神经网络八股功能扩展
第四讲 功能扩展
本讲目标;神经网络八股功能扩展
具体分为:
(1) 自制数据集,解决本领域应用(2) 数据增强,扩充数据集
(3) 断点续训,存取模型
(4)参数提取,把参数存入文本
(5)acc/loss可视化,查看训练效果
(6) 应用程序,给图识物
一、回顾:
1、tf.keras搭建神经网络八股–六步法
(1) import – 导入所需的各种库和包
(2) x_train, y_train – 导入数据集、自制数据集、数据增强
(3) model = tf.keras.models.sequential()
/class MyModel(Model) model = MyModel–定义模型(4) model.compile–配置模型
(5) model.fit – 训练模型、断点续训
(6) model.summary – 参数提取、acc/loss可视化,前向推理实现应用
2、 代码 mnist_train_baseline.py:
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['sparse_categorical_accuracy']) model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) model.summary()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Epoch 1/5 1875/1875 [==============================] - 2s 800us/step - loss: 0.2627 - sparse_categorical_accuracy: 0.9256 - val_loss: 0.1473 - val_sparse_categorical_accuracy: 0.9564 Epoch 2/5 1875/1875 [==============================] - 1s 722us/step - loss: 0.1136 - sparse_categorical_accuracy: 0.9661 - val_loss: 0.0986 - val_sparse_categorical_accuracy: 0.9708 Epoch 3/5 1875/1875 [==============================] - 1s 720us/step - loss: 0.0782 - sparse_categorical_accuracy: 0.9768 - val_loss: 0.0876 - val_sparse_categorical_accuracy: 0.9740 Epoch 4/5 1875/1875 [==============================] - 1s 718us/step - loss: 0.0593 - sparse_categorical_accuracy: 0.9812 - val_loss: 0.0802 - val_sparse_categorical_accuracy: 0.9755 Epoch 5/5 1875/1875 [==============================] - 1s 722us/step - loss: 0.0441 - sparse_categorical_accuracy: 0.9862 - val_loss: 0.0892 - val_sparse_categorical_accuracy: 0.9743 Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, 784) 0 dense (Dense) (None, 128) 100480 dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
二、 本讲用 tf.keras 完善功能模块
1、 自制数据集,应对特定应用
1.1、 观察数据集数据结构,配成特征标签对
mnist_image_label 文件夹:
四个文件分别对应为训练集图片、训练集标签、测试集图片、测试集标签
图片文件夹:
标签文件:

import tensorflow as tf from PIL import Image import numpy as np import os path = 'E:\BaiduNetdiskDownload\中国大学MOOCTF笔记2.1共享给所有学习者\class4\MNIST_FC\mnist_image_label\\' train_path = path + 'mnist_train_jpg_60000/' train_txt = path + 'mnist_train_jpg_60000.txt' x_train_savepath = path + 'mnist_x_train.npy' y_train_savepath = path + 'mnist_y_train.npy' test_path = path + 'mnist_test_jpg_10000/' test_txt = path + 'mnist_test_jpg_10000.txt' x_test_savepath = path + 'mnist_x_test.npy' y_test_savepath = path + 'mnist_y_test.npy' # def generateds(图片路径, 标签文件) def generateds(path, txt): f = open(txt, 'r') contents = f.readlines() f.close() x,y_ = [], [] for content in contents: value = content.split() # 以空格分开,图片路径为value[0] , 标签为value[1] , 存入列表 img_path = path + value[0] # 拼出图片路径和文件名 img = Image.open(img_path) # 读入图片 img = np.array(img.convert('L')) # 图片变为8位宽灰度值的np.array格式 img = img / 255.0 # 数据归一化 (实现预处理) x.append(img) # 归一化后的数据,贴到列表x y_append(value[1]) # 标签贴到列表y_ print('loading:' + content) #打印状态提示 x = np.array(x) #变成np.array格式 y_ = np.array(y_) #变成np.array格式 y_ = y_.astype(np.int64) #变为64整形 return x, y_ # 返回输入特征x,返回标签y_ if os.path.exists(x_train_savepath) and os.path.exists(y_train_savepath) and os.path.exists( x_test_savepath) and os.path.exists(y_test_savepath): print('-------------Load Datasets-----------------') x_train_save = np.load(x_train_savepath) y_train = np.load(y_train_savepath) x_test_save = np.load(x_test_savepath) y_test = np.load(y_test_savepath) x_train = np.reshape(x_train_save, (len(x_train_save), 28, 28)) x_test = np.reshape(x_test_save, (len(x_test_save), 28, 28)) else: print('-------------Generate Datasets-----------------') x_train, y_train = generateds(train_path, train_txt) x_test, y_test = generateds(test_path, test_txt) print('-------------Save Datasets-----------------') x_train_save = np.reshape(x_train, (len(x_train), -1)) x_test_save = np.reshape(x_test, (len(x_test), -1)) np.save(x_train_savepath, x_train_save) np.save(y_train_savepath, y_train) np.save(x_test_savepath, x_test_save) np.save(y_test_savepath, y_test) model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['sparse_categorical_accuracy']) model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) model.summary()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
-------------Load Datasets----------------- Epoch 1/5 1875/1875 [==============================] - 2s 805us/step - loss: 0.2624 - sparse_categorical_accuracy: 0.9248 - val_loss: 0.1434 - val_sparse_categorical_accuracy: 0.9582 Epoch 2/5 1875/1875 [==============================] - 1s 751us/step - loss: 0.1173 - sparse_categorical_accuracy: 0.9645 - val_loss: 0.1044 - val_sparse_categorical_accuracy: 0.9687 Epoch 3/5 1875/1875 [==============================] - 1s 735us/step - loss: 0.0810 - sparse_categorical_accuracy: 0.9759 - val_loss: 0.0811 - val_sparse_categorical_accuracy: 0.9738 Epoch 4/5 1875/1875 [==============================] - 1s 755us/step - loss: 0.0604 - sparse_categorical_accuracy: 0.9812 - val_loss: 0.0761 - val_sparse_categorical_accuracy: 0.9756 Epoch 5/5 1875/1875 [==============================] - 1s 733us/step - loss: 0.0474 - sparse_categorical_accuracy: 0.9851 - val_loss: 0.0724 - val_sparse_categorical_accuracy: 0.9762 Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten_1 (Flatten) (None, 784) 0 dense_2 (Dense) (None, 128) 100480 dense_3 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2、 数据增强,增大数据量
2.1、 数据增强(增大数据量)
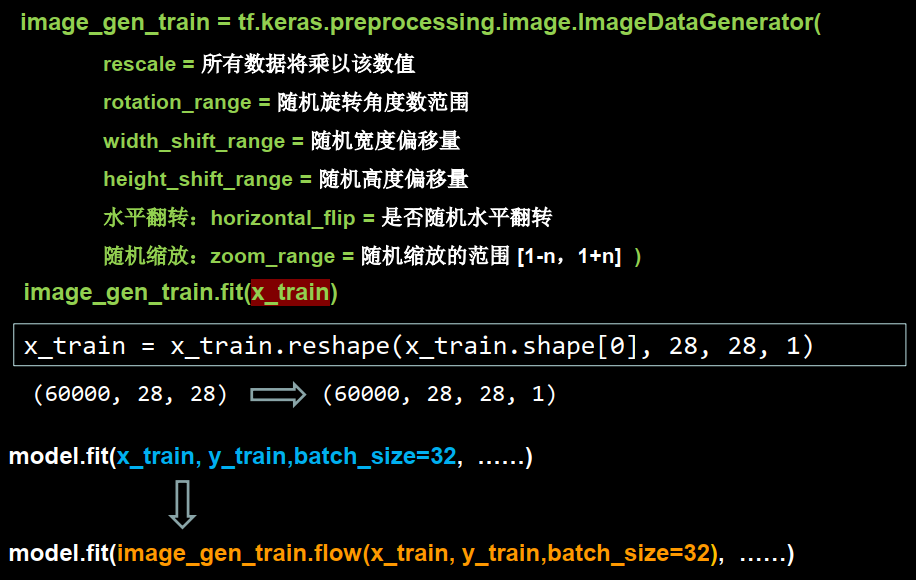
image_gen_train = tf.keras.preprocessing.image.ImageDataGenerator(增强方法)
image_gen_train.fit(x_train)
常用增强方法:
缩放系数:rescale = 所有数据将乘以相同的值随机旋转:rotation_range=随机旋转角度数范围
宽度偏移:width_shift_range = 随机宽度偏移量
高度偏移:height_shift_range = 随机高度偏移量
水平翻转: horizontal_flip = 是否水平随机翻转
随机缩放:zoom_range = 随机缩放的范围[1-n, 1+n]
image_gen_train = ImageDataGenerator(
rescale=1./255, #原像素值 0~255 归至 0~1 rotation_range=45, #随机 45 度旋转 width_shift_range=.15, #随机宽度偏移 [-0.15,0.15) height_shift_range=.15, #随机高度偏移 [-0.15,0.15) horizontal_flip=True, #随机水平翻转 zoom_range=0.5 #随机缩放到 [1-50%, 1+50%]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
)
2.2、 数据增强可视化 (代码 show_augmented _images.py)
# 代码 mnist_train_ex2.py: import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.keras.preprocessing.image import ImageDataGenerator import numpy as np mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) image_gen_train = ImageDataGenerator( rescale=1./255, #原像素值 0~255 归至 0~1 rotation_range=45, #随机 45 度旋转 width_shift_range=.15, #随机宽度偏移 [-0.15,0.15) height_shift_range=.15, #随机高度偏移 [-0.15,0.15) horizontal_flip=True, #随机水平翻转 zoom_range=0.5) #随机缩放到 [1-50%, 1+50%] image_gen_train.fit(x_train) print("xtrain",x_train.shape) x_train_subset1 = np.squeeze(x_train[:12]) print("xtrain_subset1",x_train_subset1.shape) print("xtrain",x_train.shape) x_train_subset2 = x_train[:12] # 一次显示12张图片 print("xtrain_subset2",x_train_subset2.shape) fig = plt.figure(figsize=(20,2)) plt.set_cmap('gray') #显示原始图片 for i in range(0, len(x_train_subset1)): ax = fig.add_subplot(1,12,i+1) ax.set_xticklabels([]) ax.set_yticklabels([]) ax.imshow(x_train_subset1[i]) fig.suptitle('Subset of Original Training Images', fontsize=20) plt.show() # 显示增强后的图片 fig = plt.figure(figsize=(20,2)) for x_batch in image_gen_train.flow(x_train_subset2, batch_size=12, shuffle=False): for i in range(0,12): ax = fig.add_subplot(1, 12, i+1) ax.set_xticklabels([]) ax.set_yticklabels([]) ax.imshow(np.squeeze(x_batch[i])) fig.suptitle('Augmented Images', fontsize=20) plt.show() break- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
xtrain (60000, 28, 28, 1) xtrain_subset1 (12, 28, 28) xtrain (60000, 28, 28, 1) xtrain_subset2 (12, 28, 28, 1)- 1
- 2
- 3
- 4

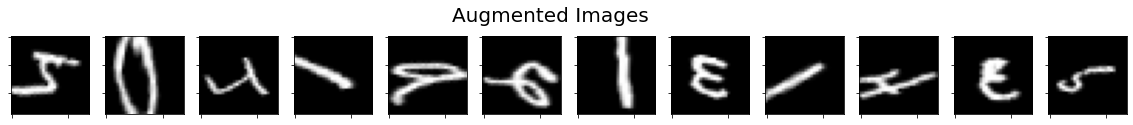
代码 mnist_train_ex2.py:
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) # 给数据增加一个维度,从(60000, 28, 28)reshape为(60000, 28, 28, 1) image_gen_train = ImageDataGenerator( rescale=1. / 1., # 如为图像,分母为255时,可归至0~1 rotation_range=45, # 随机45度旋转 width_shift_range=.15, # 宽度偏移 height_shift_range=.15, # 高度偏移 horizontal_flip=False, # 水平翻转 zoom_range=0.5 # 将图像随机缩放阈量50% ) image_gen_train.fit(x_train) model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['sparse_categorical_accuracy']) model.fit(image_gen_train.flow(x_train, y_train, batch_size=32), epochs=5, validation_data=(x_test, y_test), validation_freq=1) model.summary()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
Epoch 1/5 1872/1875 [============================>.] - ETA: 0s - loss: 1.4291 - sparse_categorical_accuracy: 0.5355WARNING:tensorflow:Model was constructed with shape (None, None, None, None) for input KerasTensor(type_spec=TensorSpec(shape=(None, None, None, None), dtype=tf.float32, name='flatten_input'), name='flatten_input', description="created by layer 'flatten_input'"), but it was called on an input with incompatible shape (None, 28, 28). 1875/1875 [==============================] - 13s 7ms/step - loss: 1.4285 - sparse_categorical_accuracy: 0.5358 - val_loss: 0.4884 - val_sparse_categorical_accuracy: 0.8748 Epoch 2/5 1875/1875 [==============================] - 12s 7ms/step - loss: 0.9640 - sparse_categorical_accuracy: 0.7053 - val_loss: 0.3590 - val_sparse_categorical_accuracy: 0.8994 Epoch 3/5 1875/1875 [==============================] - 13s 7ms/step - loss: 0.8529 - sparse_categorical_accuracy: 0.7433 - val_loss: 0.2719 - val_sparse_categorical_accuracy: 0.9287 Epoch 4/5 1875/1875 [==============================] - 13s 7ms/step - loss: 0.7817 - sparse_categorical_accuracy: 0.7643 - val_loss: 0.2645 - val_sparse_categorical_accuracy: 0.9284 Epoch 5/5 1875/1875 [==============================] - 13s 7ms/step - loss: 0.7268 - sparse_categorical_accuracy: 0.7808 - val_loss: 0.2317 - val_sparse_categorical_accuracy: 0.9351 Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, None) 0 dense (Dense) (None, 128) 100480 dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
3、断点续训,存取模型
3.1 读取模型
load_weights(路径文件名)- 1
例如:
checkpoint_save_path = './cheakpoint/mnist.ckpt' if os.path.exists(checkpoint_save_path + '.index'): print('------------------load the model-------------') model.load_weights(checkpoint_save_path)- 1
- 2
- 3
- 4
3.2、保存模型
借助tensorflow给出的回调函数,直接保存参数和网络
tf.keras.callbacks.ModelCheckpoint( filepath=路径文件名, save_weights_only=True, monitor='val_loss', # val_loss or loss save_best_only=True )- 1
- 2
- 3
- 4
- 5
- 6
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1, callbacks=[cp_callback])- 1
- 2
- 3
注:monitor配合save_best_only可以保存最优模型,包括:训练损失最小模型、测试损失最小模型、训练准确率最高模型、测试准确率最高模型等。
代码p18_mnist_train_ex2.py:
import tensorflow as tf import os mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test,y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation = 'softmax') ]) model.compile( optimizer = 'adam', loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits = False), metrics = ['sparse_categorical_accuracy'] ) checkpoint_save_path = './cheakpoint/mnist.ckpt' if os.path.exists(checkpoint_save_path + '.index'): print('------------------load the model-------------') model.load_weights(checkpoint_save_path) cp_callback = tf.keras.callbacks.ModelCheckpoint( filepath = checkpoint_save_path, save_weights_only = True, save_best_only = True ) history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,callbacks=[cp_callback]) model.summary()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
Epoch 1/5 1875/1875 [==============================] - 2s 798us/step - loss: 0.2644 - sparse_categorical_accuracy: 0.9248 - val_loss: 0.1471 - val_sparse_categorical_accuracy: 0.9566 Epoch 2/5 1875/1875 [==============================] - 2s 829us/step - loss: 0.1175 - sparse_categorical_accuracy: 0.9650 - val_loss: 0.1162 - val_sparse_categorical_accuracy: 0.9636 Epoch 3/5 1875/1875 [==============================] - 1s 786us/step - loss: 0.0801 - sparse_categorical_accuracy: 0.9757 - val_loss: 0.0957 - val_sparse_categorical_accuracy: 0.9696 Epoch 4/5 1875/1875 [==============================] - 2s 972us/step - loss: 0.0615 - sparse_categorical_accuracy: 0.9812 - val_loss: 0.0805 - val_sparse_categorical_accuracy: 0.9748 Epoch 5/5 1875/1875 [==============================] - 2s 905us/step - loss: 0.0472 - sparse_categorical_accuracy: 0.9854 - val_loss: 0.0737 - val_sparse_categorical_accuracy: 0.9781 Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten_2 (Flatten) (None, 784) 0 dense_4 (Dense) (None, 128) 100480 dense_5 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4、参数提取,写至文本
4.1、提取可训练参数
model.trainable_variables模型中可训练的参数
4.2、设置print输出格式np.set_printoptions( precision=小数点后按四舍五入保留几位, threshold=数组元素数量少于或等于门槛值,打印全部元素;否则打印门槛值+1个元素,中间用省略号补充 )- 1
- 2
- 3
- 4
np.set_printoptions(precision=5)
print(np.array([1.123456789]))
[1.12346]np.set_printoptions(threshold=5)
print(np.arange(10))
[0 1 2 … , 7 8 9]注:precision=np.inf打印完整小数位;threshold=np.nan打印全部数组元素。
代码p19_mnist_train_ex4.py:
import tensorflow as tf import os import numpy as np #设置显示全部内容,inf表示无穷大 np.set_printoptions(threshold = np.inf) mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test,y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation = 'softmax') ]) model.compile( optimizer = 'adam', loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits = False), metrics = ['sparse_categorical_accuracy'] ) path = 'E:\BaiduNetdiskDownload\中国大学MOOCTF笔记2.1共享给所有学习者\class4\MNIST_FC\mnist_image_label\\' checkpoint_save_path = 'cheakpoint/mnist.ckpt' if os.path.exists(checkpoint_save_path + '.index'): print('------------------load the model-------------') model.load_weights(checkpoint_save_path) cp_callback = tf.keras.callbacks.ModelCheckpoint( filepath = checkpoint_save_path, save_weights_only = True, save_best_only = True ) history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,callbacks=[cp_callback]) model.summary() #打印模型参数,存入文本 print(model.trainable_variables) file = open(path+ 'weight.txt', 'w') for v in model.trainable_variables: file.write(str(v.name) + '\n') file.write(str(v.shape) + '\n') file.write(str(v.numpy()) + '\n') file.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
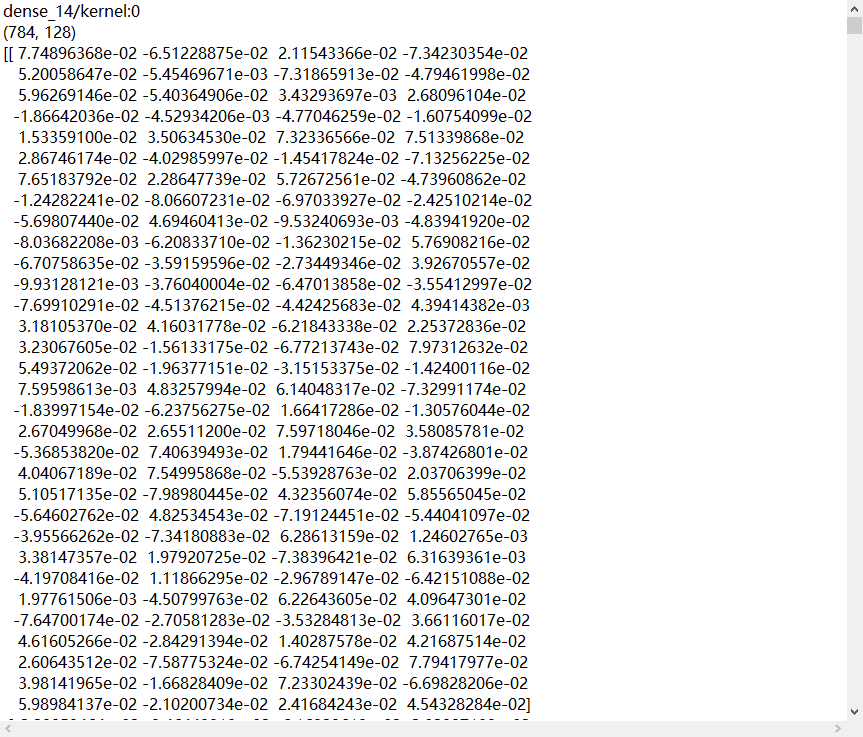
5、acc/loss可视化,查看效果
5.1、acc曲线与loss曲线
history=model.fit(训练集数据, 训练集标签, batch_size=, epochs=,
validation_split=用作测试数据的比例,validation_data=测试集, validation_freq=测试频率)
history:
loss:训练集loss
val_loss:测试集loss
sparse_categorical_accuracy:训练集准确率
val_sparse_categorical_accuracy:测试集准确率代码p20_mnist_trian_ex5.py
import tensorflow as tf import os import numpy as np np.set_printoptions(threshold = np.inf) mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test,y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation = 'softmax') ]) model.compile( optimizer = 'adam', loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits = False), metrics = ['sparse_categorical_accuracy'] ) path = 'E:\BaiduNetdiskDownload\中国大学MOOCTF笔记2.1共享给所有学习者\class4\MNIST_FC\mnist_image_label\\' checkpoint_save_path = 'cheakpoint/mnist.ckpt' if os.path.exists(checkpoint_save_path + '.index'): print('------------------load the model-------------') model.load_weights(checkpoint_save_path) cp_callback = tf.keras.callbacks.ModelCheckpoint( filepath = checkpoint_save_path, save_weights_only = True, save_best_only = True ) history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,callbacks=[cp_callback]) model.summary() print(model.trainable_variables) file = open(path + 'weight.txt', 'w') for v in model.trainable_variables: file.write(str(v.name) + '\n') file.write(str(v.shape) + '\n') file.write(str(v.numpy()) + '\n') file.close() # 显示训练集和验证集的acc和loss曲线 # history中读取所需数据 acc = history.history['sparse_categorical_accuracy'] val_acc = history.history['val_sparse_categorical_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] plt.subplot(1, 2, 1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.title('Training and Validation Accuracy') plt.legend() plt.subplot(1, 2, 2) plt.plot(loss, label='Training Loss') plt.plot(val_loss, label='Validation Loss') plt.title('Training and Validation Loss') plt.legend() plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
6、应用程序,给图识物
6.1、给图识物
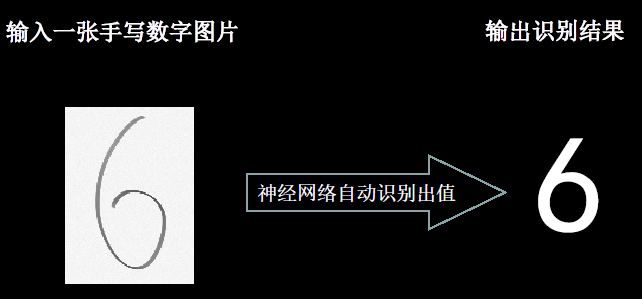
手写十个数,正确率90%以上合格
6.2、前向传播执行应用
predict(输入数据, batch_size=整数) 返回前向传播计算结果
注:predict参数详解。(1)x:输入数据,Numpy 数组(或者 Numpy 数组的列表,如果模型有多个输出);(2)batch_size:整数,由于GPU的特性,batch_size最好选用8,16,32,64……,如果未指定,默认为32;(3)verbose: 日志显示模式,0或1;(4)steps: 声明预测结束之前的总步数(批次样本),默认值 None;(5)返回:预测的 Numpy 数组(或数组列表)。
模型预测简单三步:
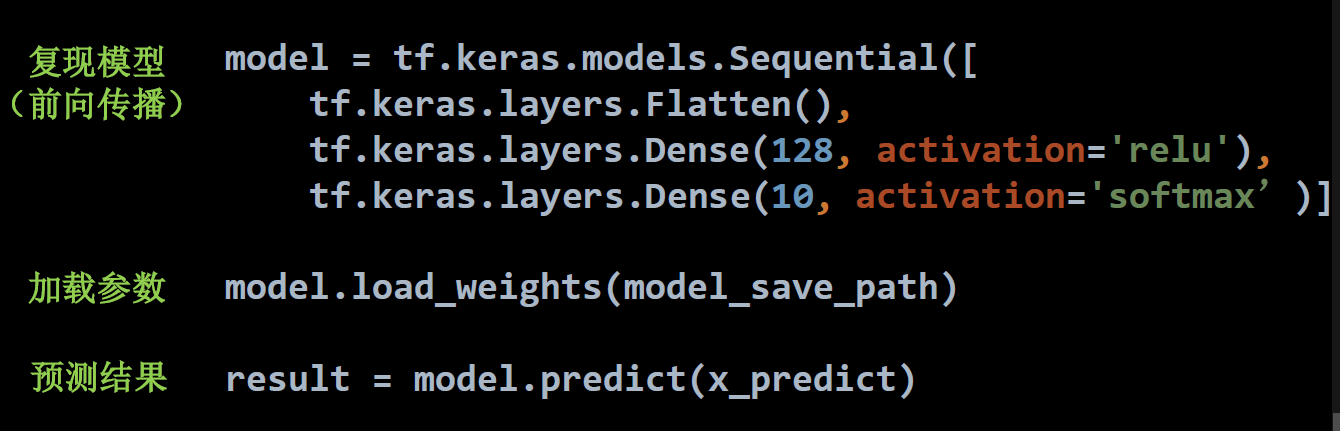
import tensorflow as tf import os import numpy as np from PIL import Image model_save_path = './checkpoint/mnist.ckpt' model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28,28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation = 'softmax') ]) # 加载模型 model.load_weights(model_save_path) # 预测图片数量 preNum = int(input("input the number of test pictures: ")) for i in range(preNum): # 预测图片打开路径 image_path = input("the path of test picture: ") img = Image.open(image_path) # 调整尺寸和类型 img = img.resize((28,28), Image.ANTIALIAS) img_arr = np.array(img.convert('L')) # 二值化 for i in range(28): for j in range(28): if img_arr[i][j] < 200: img_arr[i][j] = 255 else: img_arr[i][j] = 0 img_arr = img_arr / 255.0 x_predict = img_arr[tf.newaxis,...] # 预测 result = model.predict(x_predict) pred = tf.argmax(result, axis = 1) print('\n') tf.print(pred)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
-
相关阅读:
android布局
👍SpringSecurity单体项目最佳实践
vue3 ts中常用的类型推断
剪绳子(动态规划,贪心算法)
linux常用操作(vim & SSH服务)
最全指令系统详解
数据结构 树(第10-14天)
SAP角色描述-只能在Logon语言中修改问题解决 .
鸿蒙4.0真机调试踩坑
全网独有windows10安装hadoop2.2.0
- 原文地址:https://blog.csdn.net/wenxingxingxing/article/details/126574442
