-
torchvision.transforms.Compose输入类型是?处理过程中的数据类型转化又是什么样的呢?
1 输入数据的类型
这个输入类型很容易被人忽略且搞错,ToTensor这种操作的输入可以是numpy也可以是PIL.Image,但是其它与图片处理相关的操作比如旋转剪切的输入都需要是PIL.Image类型. PIL. Image.open的输出类型实际上是:


转化为RGB之后才是通常意义上的PIL. Image图片类型。2 PIL.Image.open读取的结果
PIL.Image.open函数读取的结果可以通过np.array或者np.asarray直接转化成矩阵类型。如果原图本身就是RGB图,那么转化得到的numpy矩阵就是三维的,且通道数是最后一个维度;如果原图本身就是灰度图,那么转化得到的numpy矩阵就是二维的,而convert(“RGB”)后的数据转化为numpy时则是三维的了。

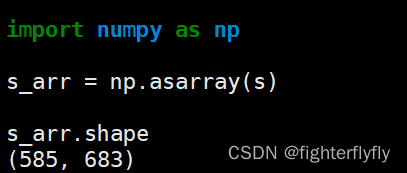
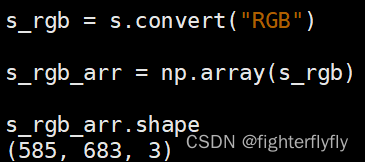

注意事项:
虽然PIL.Image.Image没有shape属性,但是其是具有size属性的,而且可以发现对于灰度图,即便是convert(“RGB”)了其size仍然是保持二维的,只有转化成numpy之后才变成三维的,为什么呢?继续往下看,可以发现即便输入是RGB彩色图,其size也是二维的。**
所以不妨可以这样理解,PIL.Image.Image的size只关注图片的宽度和高度,而不关注通道数,通道数应该由其他的属性来参与控制。
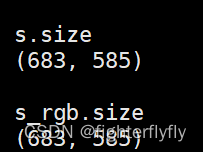
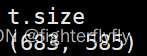
3 额外补充
【1】torchvision.transforms.Compose中只有遇到了toTensor操作之后输出结果才会变成Tensor类型,在没有遇到该操作之前的所有输出依旧是保持PIL.Image.Image数据类型。
【2】cv2.Canny函数无论输入是二维的灰度numpy数组还是三维的RGBnumpy数组,其输出都是二维的numpy.
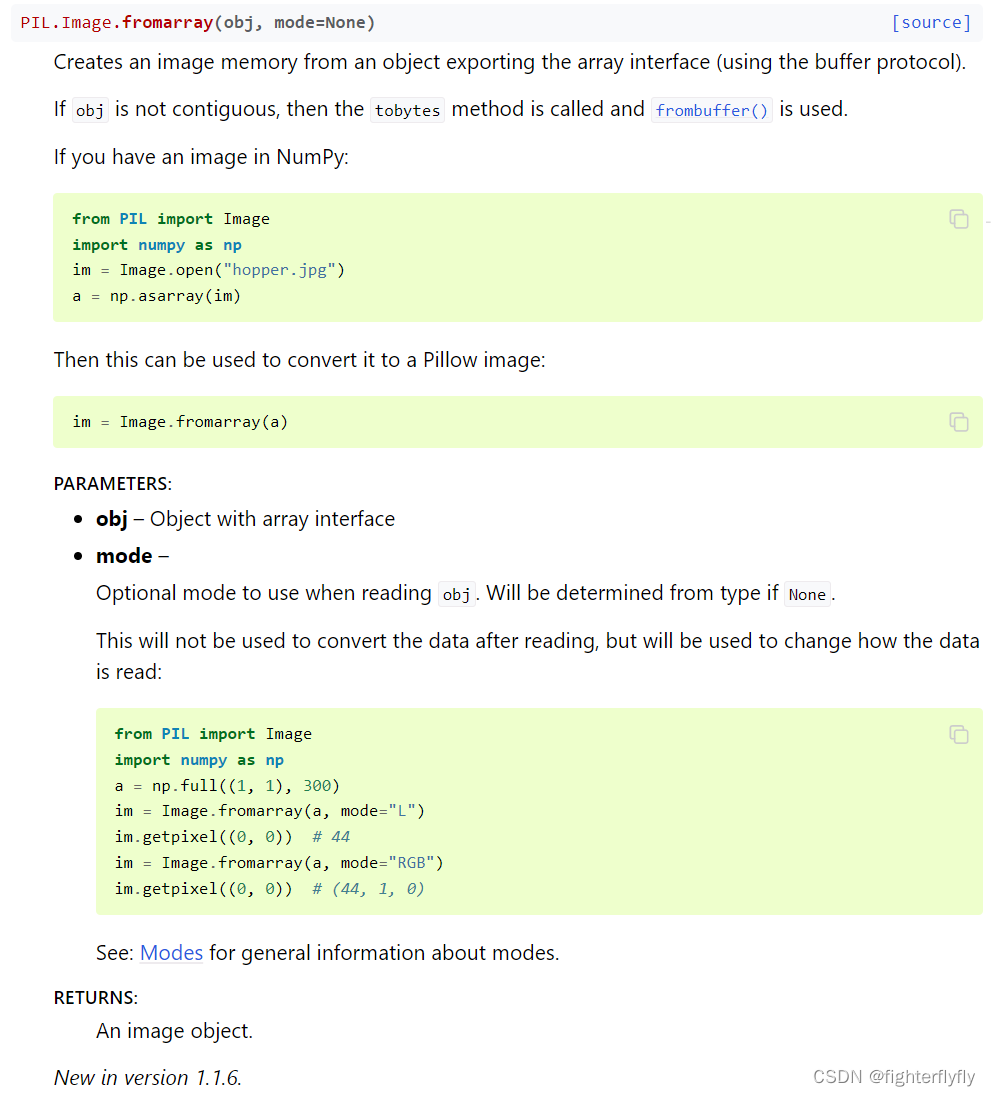
【3】Image.fromarray是有一个mode参数的,用来决定以何种方式来读取这个numpy数组。L代表以灰度方式进行读取,RGB代表以彩色方式进行读取,没有指定时会依据数据类型推断出来。PIL.Image.Image类型有get_pixel方法来获取指定几何位置的像素值。Image.fromarray传递的numpy矩阵必须是uint8类型,否则报错,x = x.astype(np.uint8).
【4】所有继承torch.utils.data.Dataset的数据集子类其__getitem__(self, i)的返回值中不能包含None类型的数据。

【5】https://pytorch.org/vision/main/generated/torchvision.transforms.Grayscale.html
GrayScale的转化不会将PIL.Image转化成Tensor,输出类型还是PIL.Image,并且也不会归一化,也不会进行阈值化(即把图片变成只有0和255的这两种灰度值)。
【6】ToTensor是将(H, W, C)转化为(C, H, W),注意H和W的相对顺序是没有发生改变的



-
相关阅读:
【C++】C++ 语言对 C 语言的加强 ④ ( C 语言中的三目运算符 - 不能作为左值 | C++ 语言中的三目运算符增强 | C 语言中三目运算符作为左值使用 )
数据治理之数据质量
稀疏矩阵的压缩存储
win32 python查找文字指定格式 win32com
宝塔配置tomcat
Nodejs安装及环境配置
@设计模式-工厂模式
如何在IDEA中创建Module、以及怎样在IDEA中删除Module?
VUE3 之 列表动画 - 这个系列的教程通俗易懂,适合新手
Mybatis日志系统
- 原文地址:https://blog.csdn.net/good18Levin/article/details/126564412