-
【Java】笔试-知识点复习
https://blog.csdn.net/if_icanfly/article/details/120863608
1.强引用(Strong Reference)
java中默认声明的就是强引用,只要引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足,jvm抛出OutOfMemoryError也不会回收;如果想中断强引用与对象之间的联系,可以显示的将强引用赋值为null,这样一来,JVM就可以适时的回收对象了
2.软引用(Soft Reference)
用来描述一些非必须但是有用的对象,在内存足够的情况下,引用不会被回收,只有在内存不足的情况下,系统会回收软引用对象 ,如果回收之后任然没有足够的内存,才会抛出OutOfMemoryError;
3.弱引用(Weak Reference)
无论内存足够与否,只要jvm进行垃圾回收,那些被弱引用关联的对象都会被回收.
4.虚引用(Phantom Reference)
虚引用是最弱的一种引用关系,它随时可能会被回收.
关键字final
1.关键字final表示最终的,不可变的。
2.关键字final可以修饰变量、方法,还有类
3.final修饰的类无法被继承
4.final修饰的方法无法被覆盖,无法被重写
5.final控制不了能不能调用的问题,表示的是最后的,不能变的,不能改的。
6.final修饰的变量只能赋一次值
7.final修饰的引用:
该引用只能指向1个对象,并且它只能永远指向该对象,并且无法指向其他对象。
并且在该方法执行过程中,该引用指向对象之后,该对象不会被垃圾回收期回收
直到当前方法结束,才会释放空间。
8.虽然final的引用指向对象A后,不能再重新指向对象B,
但是对象A内部的数据可以被修改。
9.final修饰的实例变量,只能赋值一次。结论:因为实例变量没有手动赋值,系统会赋默认值。
因而要求final修饰的实例变量必须手动赋值。这个手动赋值,在变量后面赋值可以,在构造器
中赋值也可以。(显示赋值、构造器赋值、代码块赋值)
10.final修饰的实例变量一般添加 static修饰
终极结论:static final联合修饰的变量称为“常量”,常量名建议大写,每个单词间用下划线衔接。
常量和静态变量一样,区别在于:常量的值不能变。相同点在于:都是储存在方法区,并且都是
在类的加载时初始化。常量一般都是公共的,public修饰。
接口和抽象类的区别
一、类方法和实例方法的调用:
下列哪种说法是正确的( D )A. 实例方法可直接调用超类的实例方法
B. 实例方法可直接调用超类的类方法
C. 实例方法可直接调用其他类的实例方法
D. 实例方法可直接调用本类的类方法
解析:
在本题中,如果是私有的,ABC都不能访问 所以选D类方法(static方法):
在类方法中:-
不能引用实例变量
-
不能使用super、this关键字
-
不能调用类方法
-
不考虑访问修饰符的话,
实例方法可以通过super.方法名,对象名.方法名调用父类的实例方法
实例方法可以通过类名.方法名,super.方法名调用父类的静态方法
实例方法通过this.方法名调用本类的其他方法
本类的静态方法还可以用类名.方法名调用。
二、java中super关键字
1.在子类构造器中显示调用父类构造器(super必须出现在子类构造器的第一行)2。可以在子类中充当临时父类对象,super.方法名调用父类的方法
三、java中this关键字
1.代表当前对象,指向成员变量和成员方法
2.指向某个构造方法,通过this调用其他构造方法。
this();//代表无参构造方法
四、访问控制符
访问级别 访问控制修饰符 同类 同包 子类 不同的包
公开级别: public y y y y
受保护 protected y y y
默认 没有访问控制符 y y
私有 private y
五、AOP术语
术语
Advice (增强/通知) 表示需要扩展的功能。
JoinPoint (连接点) 表示允许使用增强的地方。基本每个方法的前、后或异常等都是连接点。
Pointcut (切入点) 表示实际增强的方法。
Aspect (切面) 表示扩展功能的过程。
Introduction( 引入) 表示向现有的类中添加新方法、新属性。
Target (目标对象) 表示被增强的对象。
Proxy (代理) 表示实现AOP的机制。
Weaving (织入) 表示把增强应用到目标对象的过程。
补充知识:
AOP称为面向切面编程。
AOP的本质是过滤器。
AOP的实现原理是代理模式。https://blog.csdn.net/Bronze5/article/details/106746705/

若某链表最常用的操作是在最后一个结点之后插入一个结点或者删除最后一个结点,则采用带头结点的双循环链表存储方法最节省。、
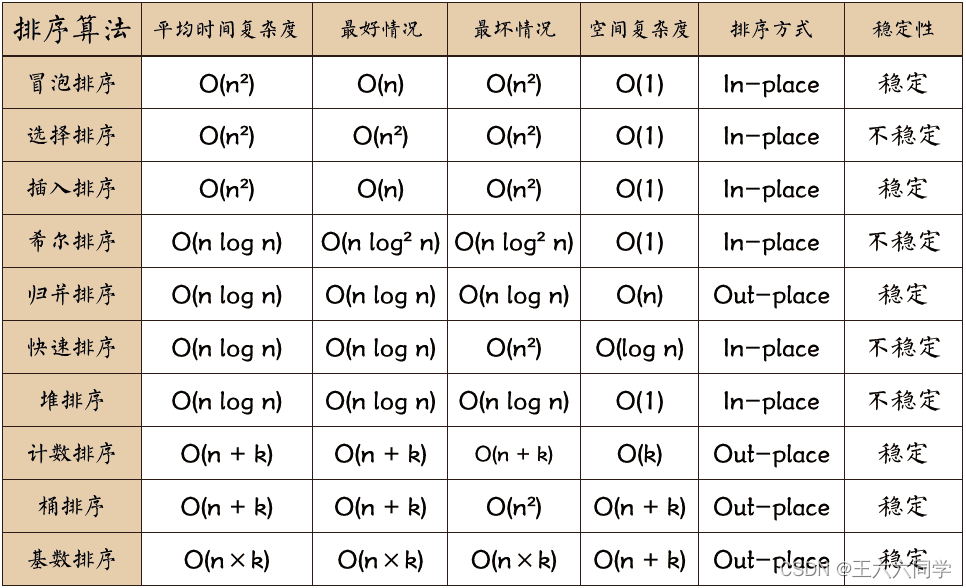
排序算法:
https://www.runoob.com/w3cnote/ten-sorting-algorithm.html

索引
如果需要对磁盘上的1000W条记录构建索引,你认为下面哪种数据结构来存储索引最合适?(C)
A、HashTableB、AVL-TreeC、B-TreeD、List解析:
AVL-Tree 检索速度是很快的,这是因为二分检索是树结构的一个本质特性。但是最大的缺点是他的存储利用率太低。每个树节点仅仅有一个数据项,有2个指针和每个数据项的控制信息。
Hash Table当溢出发生时可以分裂成2个节点。目录以2的指数倍增长,只要一个节点溢出而且目录已经达到了指定的最大目录深度,他就会加倍。一个问题就是任何一个节点都能引起目录分裂,因此如果Hash函数不是很随机的话,目录可能增长的很大。
List优点是存取方便,但不便于动态维护,进行插入删除等操作时需要移动大量的数据。
B-tree是比较合适用于磁盘的数据结构,由于他是一个宽而浅的树,查找一个数需要访问很少的节点。内存利用率是比较好的,所以他用于内存数据库比较合适;搜索速度比较快(用二分查找时,只访问很少一部分节点);而且更新速度也比较快(数据移动通常只涉及到一个节点)
追问
针对这句话:1000W条记录构建索引 该如何解释?
追答
1000W数据量根大,AVL-Tree存储利用率太低,也很难找到一个完美的hash函数。list就不用说了,每次插入删除操作可能移动几百万数据。https://blog.csdn.net/qq_41403559/article/details/104923796

c
shell命令
用shell命令给同组用户赋予test.txt的读权限
chmod g+rw test.txtdubbo原理和机制:应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和Spring框架无缝集成。
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。
监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示。
服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销。
服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销。
socket connect java_java网络编程学习笔记(二):socket详解
https://blog.csdn.net/weixin_35988836/article/details/114446783一维数组与二维数组的声明:
1.先声明再初始化
例如://1.声明 int[] nums; //初始化 nums = new int[5];- 1
- 2
- 3
- 4
- 5
2.声明并初始化
例如://2.声明、初始化 int[] nums = new int[10];- 1
- 2
3.创建数组同时赋值
例如:
//3.创建数组同时赋值 String[] names=new String[]{"大名","小米","夏雨荷"}; int[] ages=new int[]{21,22,21,56,13};- 1
- 2
- 3
一维数组的形式:
(1),int a[]; a = new int[5];- 1
- 2
等同于
int a[] = new int[5];- 1
(2),
int[] a; a = new int[5];- 1
- 2
等同于
int[] a = new int[5];- 1
-
-
相关阅读:
服务注册发现_actuator微服务信息完善
洛谷P3327 莫比乌斯反演,约数函数结论
B-2:Linux系统渗透提权
mysql面试题9:MySQL中的SQL常见的查询语句有哪些?有哪些对SQL语句优化的方法?
【MyBatis笔记05】MyBatis中常见的几种查询结果类型介绍
Kafka中的数据本身就是倾斜的,使用FlinkSQL该如何处理
php图片素材网毕业设计源码110907
Discuz IIS上传附件大于28M失败报错Upload Failed.修改maxAllowedContentLength(图文教程)
echarts插件-liquidFill(水球图)
4D毫米波雷达硬件系统架构
- 原文地址:https://blog.csdn.net/m0_58058653/article/details/126542729