-
linux基础2
https://www.linuxcool.com/
1、inode
linux操作系统的文件权限与文件属性。
文件系统通常会将这两部分分别存放在inode和block中。
硬盘的最小存储单位叫做扇区sector,每个扇区存储512字节,操作系统读取硬盘的时候,一次性读取一个块block。块是文件存取的最小单位,由多个扇区组成的块。块的大小,最常见的是4KB,即连续八个sector组成一个block。
文件系统中的数据分为数据和元数据,
数据指的是普通文件中的实际数据。
元数据指用来描述一个文件的特征的系统数据,如访问权限、文件拥有者基于文件数据块的分布信息等等。
存储文件的元信息的区域就是inode。中文译名索引节点,也叫i节点,一个文件必须占用一个inode,至少占用一个Block。
inode包含很多的文件元信息,但不包含文件名,例如:字节数、属主UserID、属组GroupID、读写执行权限、时间戳等。而文件名存放在目录当中,但Linux系统内部不使用文件名,而是使用inode号码识别文件。对于系统来说文件名只是inode号码便于识别的别称。
df可以获取当前磁盘被占用多少空间,还剩下多少空间等信息,-h表示格式化输出数据,-i表示显示i节点信息。
2、文件类型和文件权限由10个字符组成:
第 1 位表示文件的类型;
第 2 - 4 位表示文件所有者对文件的权限;
第 5 - 7 位表示文件所有者所在组的用户对文件的权限;
第 8 - 10 位表示其他用户对文件的权限。其中 r 表示可读,w 表示可写,x 表示可执行,- 表示没有权限
3、linux下的进程有运行态、就绪态和等待态三种状态
4、route 命令用于显示和操作IP路由表;
tracert 为 Windows 路由跟踪实用程序,可以用于确定 IP 数据包访问目标时所选择的路径;
ping 命令用于检测主机;
netstat 命令用于显示网络状态,利用 netstat 指令可以得知整个 Linux 系统的网络情况。
5、大多数的 Linux(Red Hat、Slackware、Caldera)都以 bash 作为缺省的shell,并且运行 sh 时,其实调用的是 bash。
Bourne Again shell(bash)
Bourne shell(sh)
Korn shell(ksh)
C shell(csh)
6、文件句柄0,1,2分别是标准输入,标准输出,标准错误。
7、基本格式 :
* * * * * command
分 时 日 月 周 命令
第1列表示分钟1~59 每分钟用*或者 */1表示
第2列表示小时1~23(0表示0点)
第3列表示日期1~31
第4列表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令
8、-u 用户号 指定用户的用户号;因为系统用户的用户号为 0,故指定用户号为 0;
如果同时有 -o 选项,则可以重复使用其他用户的标识号,因为系统本身存在用户号为 0 的系统用户,故应该使用该参数。
9、rsync是中小型企业常用的同步工具是基于内容的同步,其他的也都可以,但是存在一些问题,
rsync结合inotify可以达到实时同步,最重要的是rsync是同步差异的内容,而不是同步差异的文件开销比其他的小,并且是基于ssh协议的,sshd服务都是服务器必备的,不需要额外装其他服务
wget 基于http/ftp协议的.ftp 需要其他服务 scp基于ssh协议 ,这些都是基于文件内容做同步开销大
10、find 命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则 find 命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
-newer file 表示查找修改比 file 文件更新的文件,! 表示取反,所以整个的意思是:查找更改时间比文件 file1 新但比文件 file2 旧的文件。
11、可移植可执行文件(Portable Executable,PE)是一种用于可执行、目标文件和动态链接库的文件格式,主要用于Windows,而使用于Linux和多数Unix系统中的是可执行与可链接格式(ELF),Mac OS中则主要使用Mach-O;
12、lseek()函数:移动文件的读写位置
read() write()读写文件
pread() pwrite()带偏移量的读写文件
都属于系统调用
feek() 库函数
13、cfdisk是用来磁盘分区的程序,类似DOS的fdisk,具有互动式操作界面而非传统fdisk的问答式界面,可以轻易地利用方向键来操控分区操作。
fdisk是一个创建和维护分区表的程序,它兼容DOS类型的分区表、BSD或者SUN类型的磁盘列表。
/etc/mtab记载的是现在系统已经装载的文件系统,包括操作系统建立的虚拟文件等;而/etc/fstab是系统准备装载的
etc/fstab记录了计算机上硬盘分区的相关信息,启动 Linux 的时候,检查分区的 fsck 命令,和挂载分区的 mount 命令,都需要 fstab 中的信息,来正确的检查和挂载硬盘。
14、ls>c会先生成c文件,然后ls的结果就是abc,重定向到c中,所以c中是abc.
15、/etc/fstab是系统分区的配置文件,开机后系统会自动挂载文件中制定的设备;
但是光驱U盘这些移动设备是无法开机自动挂起的,否则将造成系统启动失败。
noauto是非自动挂起;手动挂载的,也用于CD-ROW等移动设备
rw :读写;
ro :只读;
sw :交换分区;
defaults :默认设置;
16、Linux下进程间通信的几种主要手段简介:
a)管道(Pipe):即有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信;
b)信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数);
c)Message(消息队列):消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
d)共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
e)信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
f)套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
Linux线程间通信:互斥体,信号量,条件变量
Windows线程间通信:临界区(Critical Section)、互斥量(Mutex)、信号量(Semaphore)、事件(Event)
Windows 进程间通信:管道、内存共享、消息队列、信号量、socket
Windows 进程和线程共同之处:信号量和消息(事件)
用于进程间通讯(IPC)的四种不同技术:- 消息传递(管道,FIFO,posix和system v消息队列)
- 同步(互斥锁,条件变量,读写锁,文件和记录锁,Posix和System V信号灯)
- 共享内存区(匿名共享内存区,有名Posix共享内存区,有名System V共享内存区) 4. 过程调用(Solaris门,Sun RPC)
通信,指的进程/线程有交互,可以通过共享资源进行通知或数据传递。临界区则是一种概念,指的是访问公共资源的程序片段,并不是一种通信方式
17、子进程继承父进程
用户号UIDs和用户组号GIDs
环境Environment
堆栈
共享内存
打开文件的描述符
执行时关闭(Close-on-exec)标志
信号(Signal)控制设定
进程组号
当前工作目录
根目录
文件方式创建屏蔽字
资源限制
控制终端
子进程独有
进程号PID
不同的父进程号
自己的文件描述符和目录流的拷贝
子进程不继承父进程的进程正文(text),数据和其他锁定内存(memory locks)
不继承异步输入和输出
父进程和子进程拥有独立的地址空间和PID参数。子进程从父进程继承了用户号和用户组号,用户信息,目录信息,环境(表),打开的文件描述符,堆栈,(共享)内存等。
经过fork()以后,父进程和子进程拥有相同内容的代码段、数据段和用户堆栈,就像父进程把自己克隆了一遍。事实上,父进程只复制了自己的PCB块。而代码段,数据段和用户堆栈内存空间并没有复制一份,而是与子进程共享。只有当子进程在运行中出现写操作时,才会产生中断,并为子进程分配内存空间。由于父进程的PCB和子进程的一样,所以在PCB中断中所记录的父进程占有的资源,也是与子进程共享使用的。这里的“共享”一词意味着“竞争”
18、文件类型和权限由开头的 10 个字符表示,第一位表示文件的类型,有如下几种:- 普通文件类型
d 目录文件
b 块设备文件
c 字符设备文件
s 套接字文件
p 管道文件
l 链接文件
19、在crontab文件中如何输入需要执行的命令和时间。该文件中每行都包括六个域,其中前五个域是指定命令被执行的时间,最后一个域是要被执行的命令。每个域之间使用空格或者制表符分隔。格式如下: minute hour day-of-month month-of-year day-of-week commands 第一项是分钟,第二项是小时,第三项是一个月的第几天,第四项是一年的第几个月,第五项是一周的星期几,第六项是要执行的命令。这些项都不能为空,必 须填入。如果用户不需要指定其中的几项,那么可以使用代替。因为是统配符,可以代替任何字符,所以就可以认为是任何时间,也就是该项被忽略了。
crontab文件的格式:M H D m d cmd.
M:MIN
H:HOUR
D:DAY
m:MONTH
d:DAYOFFWEEK
cmd:COMMAND
通过crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell script脚本。
时间间隔的单位可以是分钟、小时、日、月、周及以上的任意组合。
这个命令非常适合周期性的日志分析或数据备份等工作。
20、snprintf 在stdio.h头文件中,其他的在string.h头文件中
首先,使用场景不同。除了snprintf之外,其他的都是用于两个字符串之间进行比较、拷贝、拼接等操作的,而snprintf最主要是,要把一个用户变量按照一个format打印到字符串中。
其次,函数参数类型不同。除了snprintf之外,其他的都是定长参数,而snprintf是接受变长参数的。
最后,定义位置也不同,除了snprintf位于stdio.h之外,其他的都是string.h中的。
因此,snprintf和其他的一定不是一类的,单从头文件的划分就能看出来。
P.S. glibc的头文件划分绝大多数都很有讲究。
21、关闭文件的目的之一是释放内存中的文件对象——正确的,因为要把这块内存空间标记,等待回收。
关闭文件的目的之一是保证将输出的数据写入硬盘文件——正确的,因为要关闭输入输出流。
很明显这是错的,文件读写过程中,要通过缓冲区buffer,程序不可能直接和硬盘文件交换数据的,不然要内存和缓存干嘛呢是吧。
打开文件的目的是使文件对象和磁盘文件建立联系——正确的,这是操作系统层面的问题,有寻址的过程。
22、$0 为脚本名, 1 为第一个参数名 . . . . . 所以把这条命令当做一个空格间隔的数组, 1为第一个参数名.....所以把这条命令当做一个空格间隔的数组, 1为第一个参数名.....所以把这条命令当做一个空格间隔的数组,n是取到对应下标n的字符串…
变量说明:
$$
Shell本身的PID(ProcessID)
$!
Shell最后运行的后台Process的PID
$?
最后运行的命令的结束代码(返回值)
$-
使用Set命令设定的Flag一览
∗ 所有参数列表。如 " * 所有参数列表。如" ∗所有参数列表。如"*“用「”」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。
@ 所有参数列表。如 " @ 所有参数列表。如" @所有参数列表。如"@“用「”」括起来的情况、以"$1" “ 2 " … " 2" … " 2"…"n” 的形式输出所有参数。
$#
添加到Shell的参数个数
$0
Shell本身的文件名
1 ~ 1~ 1~n
23、cat(concatenate)命令用于连接文件并打印到标准输出设备上;
| 是管道符,用于将两个命令隔开,管道符左边命令的输出会作为管道符右边命令的输入;
> 是输出重定向,将左边内容重定向到右边指定的文件中; cp(copy file)命令主要用于复制文件或目录。- 1
- 2
把 f1.txt 复制到 f2.txt 可以使用如下命令:
cat f1.txt > f2.txt
cp f1.txt f2.txt
24、:q 不保存退出
:q! 直接强制退出,不写入修改的数据
:wq 强制性写入文件并退出。即使文件没有被修改也强制写入,并更新文件的修改时间
:wq! 强制写入并退出(只有当操作者是文件所有者才可行)
:x 文件有变动时等同于 :wq,文件无变动时等同与 :q
ZZ 等同于 :x
25、缺省的Linux系统中,从后台启动进程,应在命令的结尾加上&
26、其中rpm是低级的RedHat软件包管理工具:
-ivh:安装显示安装进度–install–verbose–hash -Uvh:升级软件包–Update; -qpl:列出RPM软件包内的文件信息[Query Package list]; -qpi:列出RPM软件包的描述信息[Query Package install package(s)]; -qf:查找指定文件属于哪个RPM软件包[Query File]; -Va:校验所有的RPM软件包,查找丢失的文件[View Lost]; -e:删除包
27、tcpdump抓包命令:用于截取网络分组,并输出分组内容的工具
选项:
-A:以ASCII格式打印所有分组,常用于www的网页的数据抓取
-c:收到指定的数量的分组后,停止tcpdump
-C:将一个原始分组写入文件之前,检查文件的当前大小是否超过了file_size的指定大小,超过则关闭当前文件然后打开一个新文件,、
-d:将匹配信心包的代码以人们能够理解的汇编格式给出
-dd:将匹配信息的代码以C语言程序段的格式给出
-ddd :将匹配信息的代码以十进制的形式给出
-D:打印系统中所有的可以用tcpdump截包的网络接口
-e:输出行打印数据链路层的头部信息
-f:将外部的internet地址以数字的形式打印
-F:从指定的文件中读取表达式,忽略命令行中给出的表达式、
-i:指定监听的网络接口
-l:使标准输出变成缓冲形式,可以把数据导出到文件
-L:列出网络接口的已知数据链路
-b:在数据链路层选择协议:ip arp rarp ipx
-n:不把网络地址转成名字
-nn:不进行端口名称的转换
-N:不输出主机名中的域名部分
-t:输出的每一行不打印时间戳
-tt:在每一行中输出非格式化的时间戳
-ttt:输出本行和前面一行之间的时间差
-tttt:在每一行中输出由date处理的默认格式的时间戳
-O:不运行分组匹配代码优化程序
-P:不将网络接口设置成混杂模式
-q:快速输出,只输出较少的协议信息
-r:从指定文件中读取包
-S:将tcp的序列号以绝对值形式输出,而不是相对值
-s:从每个分组中读取最开始的snaplen个字节】
-T:将监听的包直接解释为指定类型的报文,常见有rpc远程过程调用,和snmp
-v:输出一个详细信息
-vv:输出详细的报文信息
-w:直接将分组写入文件中,而不是不分析打印
-x:可以列出16进制以及ASCII的数据包的内容
28、[ -z “” ] 命令判断双引号中变量的字符串长度是否为0,
[ -z “” ] && echo 0 || echo 1
^ ^ ^
命令1 命令2 命令3
先判断 “” 变量中是否无值,成功
然后根据 && 符特性,当命令1执行成功时执行命令2,也就是执行echo 0
然后根据 || 符特性,前一个命令不能执行才执行后一个,命令2 echo 0 执行成功,所以命令3 echo 1 不执行
命令结束
29、假设我有test1.c,test2.c两个源文件,先使用gcc -c *.c将源文件编译成目标文件,可以生成了test1.o,test2.o两个目标文件,然后,使用ar命令:ar crv libtest.a *.o将该目录下的所有目标文件打包生成了libtest.a文件。这样,你在编译的时候就可以直接使用这个静态库了。
30、CentOS、Ubuntu、Redhat属于Linux操作系统的发行版
31、top命令:
Linux下常用的性能分析工具。能够实时显示系统中各个进程对资源的占用状况。
free命令:
可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。
df命令:
用于显示当前在Linux系统上的文件系统的磁盘使用情况的统计信息。
TOP命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况。
TOP是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。
meminfo文件中,有以下信息(未完全列出)
MemTotal: 所有可用RAM大小 (即物理内存减去一些预留位和内核的二进制代码大小)
MemFree: LowFree与HighFree的总和 Buffers: 用来给块设备做的缓冲大小(只记录文件系统的metadata以及 tracking in-flight pages,就是说 buffers是用来存储,目录里面有什么内容,权限等等。) Cached: 用来给文件做缓冲大小(直接用来记忆我们打开的文件). 它不包括SwapCached- 1
- 2
- 3
- 4
- 5
SwapCached: 已经被交换出来的内存,但仍然被存放在swapfile中。用来在需要的时候很快的被替换而不需要再次打开I/O端口。
Active: 最近经常被使用的内存,除非非常必要否则不会被移作他用. Inactive: 最近不经常被使用的内存,非常用可能被用于其他途径.- 1
- 2
- 3
HighTotal:
HighFree: 高位内存是指所有在860MB以上的内存空间,该区域主要用于用户空间的程序或者是缓存页面。内核必须使用不同的手法使用该段内存,因此它比低位内存要慢一些。LowTotal: LowFree: 低位可以达到高位内存一样的作用,而且它还能够被内核用来记录一些自己的数据结构。 Among many other things, it is where everything from the Slab is allocated. Bad things happen when you're out of lowmem.- 1
- 2
- 3
- 4
SwapTotal: 交换空间的总和
SwapFree: 从RAM中被替换出暂时存在磁盘上的空间大小 Dirty: 等待被写回到磁盘的内存大小。- 1
- 2
- 3
Writeback: 正在被写回到磁盘的内存大小。
Mapped: 影射文件的大小。 Slab: 内核数据结构缓存- 1
- 2
- 3
32、从安装启动方式可以分为:软盘启动 光盘启动 U盘启动(红帽9还支持制作安装启动软盘的,只是软盘现在基本见不到了)
从软件安装来源可以分为:光盘、硬盘、nfs服务器、ftp服务器、http服务器
最简单的方式就是光盘引导,光盘安装。
其他安装方式还有KickStart无人值守安装等。
33、1.基本的linux操作系统:ext文件系统,ext2文件系统
2.日志文件系统:ext3文件系统,ext4文件系统,Reiser文件系统,JFS文件系统,XFS文件系统
3.写时复制文件系统:ZFS文件系统,Btrf文件系统
日志文件系统就是一种具有故障恢复能力的为文件系统,利用日志来记录尚未提交到文件系统的修改,防止元数据被破坏。
1,JFS2最早的日志文件系统。
2, XFS
3,ext3fs第三扩展文件系统,由ext2演化过来,ext2和ext3可以兼容,使用结构相同,仅仅多了一个日志,但是缺少一些其他日志文件系统所具备的高级特性,性能低,但所需的CPU和内存较少
4,Reiser4
5,ext4fs第四扩展文件系统,支持大容量,分区。
34、iptables -A INPUT -s !127.0.0.1 -p icmp -j DROP -A:添加一条***规则,append -s:源IP地址 -p:数据包协议,可以为tcp、udp、icmp -j :添加规则的行为,行为可以选ACCEPT、DROP(拒绝发来的数据包)、REJECT(收到请求后不发送响应)
linux防火墙iptabls拒绝所有客户端ping数据包的规则是
iptables -A INPUT -s ! 127.0.0.1 -p icmp -j DROP
iptables -A INPUT -s 0.0.0.0 -p icmp -j DROP
35、文件系统的文件数据读写性能与文件大小及读写数据块的大小有关
应用程序可以用内存映射的方式访问文件中的数据
文件的属性在创建时可以不指定,由系统通过umask的值得出,且以后可以修改
文件系统中可以创建的单个文件的大小还与分区簇有关,比如FAT16允许创建的最大单文件为2GB,剩余空间大小大于2GB也没用。
内存映射机制(mmap):即memory map,也就是内存映射。将一个文件或者其他对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现者应的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read、write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
如下图所示:
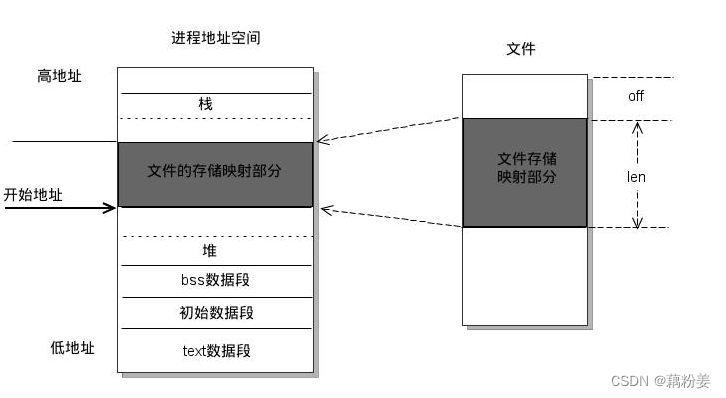
当CPU读取数据时,是由内存管理单元(MMU)管理的。MMU位于CPU与物理内存之间,它包含从虚拟地址向物理内存地址转化的映射信息。当CPU引用一个内存位置时,MMU决定哪些页需要驻留(通常通过移位或屏蔽地址的某些位)以及转化虚拟页号到物理页号。

当某个进程读取磁盘上的数据时,进程要求其缓冲通过read()系统调用填满,这个系统调用导致内核想磁盘控制硬件发出一条命令要从磁盘获取数据。磁盘控制器通过DMA直接将数据写入内核的内存缓冲区,不需要CPU协助。当请求read()操作时,一旦磁盘控制器完成了缓存的填写,内核从内核空间的临时缓存拷贝数据到进程指定的缓存中。
用户空间时常规进程所在的区域,该区域执行的代码不能直接访问硬件设备。内核空间时操作系统所在的区域,该区域可以与设备控制器通讯,控制用户区域进程的运行状态。

内存映射文件技术时操作系统提供的一种新的文件数据存取机制,利用内存映射文件技术,系统可以再内存空间中为文件保留一部分空间,并将文件映射到这块保留空间,一旦文件被映射后,操作系统将管理页映射缓冲以及高速缓冲等任务,而不需要调用分配,释放内存块和文件输入、输出的API函数,也不需要自己提供任何缓冲算法。
使用内存映射文件处理存储与磁盘上的文件时,将不必再对文件执行I\O操作,着意味着再对文件进行处理时不必再为文件申请并分配缓存,所有文件缓存操作均有系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
mmap将一个文件或者其他对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。munmap执行相反的操作,删除特定地址区域的对象映射。

linux内存映射机制void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offsize) int munmap(void *start, size_t length)- 1
- 2
返回说明:
成功执行时,mmap()返回被映射区的指针,munmap()返回0。失败时,mmap()返回MAP_FAILED(其为(void*)-1),munmap 返回-1。
参数:
start:映射区的开始地址。
length:映射区的长度。
prot:映射区域的保护方式。可以为以下几种方式的组合PROT_EXEC //页内容可以被执行 PROT_READ //页内容可以被读取 PROT_WRITE //页可以被写入 PROT_NONE //页不可访问- 1
- 2
- 3
- 4
- 5
lags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体
MAP_FIXED //使用指定的映射起始地址,如果由 start和len 参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。 MAP_SHARED //与其它所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到 msync()或者munmap() 被调用,文件实际上不会被更新。 MAP_PRIVATE //建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。 MAP_DENYWRITE //这个标志被忽略。 MAP_EXECUTABLE //同上 MAP_NORESERVE //不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。 MAP_LOCKED //锁定映射区的页面,从而防止页面被交换出内存。 MAP_GROWSDOWN //用于堆栈,告诉内核VM系统,映射区可以向下扩展。 MAP_ANONYMOUS //匿名映射,映射区不与任何文件关联。 MAP_ANON //MAP_ANONYMOUS 的别称,不再被使用。 MAP_FILE //兼容标志,被忽略。 MAP_32BIT //将映射区放在进程地址空间的低 2GB,MAP_FIXED 指定时会被忽略。当前这个标志只在 x86-64平台上得到支持。 MAP_POPULATE //为文件映射通过预读的方式准备好页表。随后对映射区的访问不会被页违例阻塞。 MAP_NONBLOCK //仅和MAP_POPULATE 一起使用时才有意义。不执行预读,只为已存在于内存中的页面建立页表入口。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
fd:有效的文件描述词。
offset:被映射对象内容的起点 -
相关阅读:
第三章:Express
瑞格心理咨询系统设置多个管理员的操作方法
OpenCV透视变换——将斜方向的图片转成正方向鸟瞰图
银河麒麟v10 服务器 和统信20 1050e 服务器 安装oracle 19c实战(适配成功)
lvm磁盘管理
VS2017 IDE 编译时的 X86、x64位 是干什么的
从感官沉浸到无边界互操作,细数元宇宙游戏的底层逻辑世界
力扣刷题记录(Java)(一)
美食杰项目(二)首页
数字化企业需要什么样的数据中心
- 原文地址:https://blog.csdn.net/weixin_46754666/article/details/126251288