-
K8S-Service
Service
kubernetes中的三种IP
- Node IP:Node节点IP地址
- Pod IP:Pod的IP地址
- Cluster IP:Service的IP地址

-
Node IP是Kubernetes集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通讯,不管他们中间是否含有不属于Kubernetes集群中的节点。想Kubernetes之外的节点访问Kubernetes集群内的节点或者TCP/IP服务时,必须通过Node IP。
-
Pod IP是每个Pod的IP地址,它是Docker Engine 根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,Kubernetes要求位于不同Node上的Pod能够彼此直接通讯,所以Kubernetes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出。
- 同Service下的pod可以直接根据PodIP相互通信
- 不同Service下的pod在集群间pod通信要借助于 cluster ip
- pod和集群外通信,要借助于node ip
-
Cluster IP,它是一个虚拟IP,但更像是一个伪造的IP网络
(1)Cluster IP仅仅作用于Kubernetes Service对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)
(2)Cluster IP无法被Ping,因为没有一个"实体网络对象"来影响
(3)在Kubernetes集群内,Node IP、Pod IP、Cluster IP之间的通信,采用的是Kubernetes自己设计的特殊路由规则如下图所示,外网访问物理IP,然后将访问请求映射到service VIP上,service VIP从etcd上获取endpoints中pod的IP,然后使用负载均衡策略选择一个pod进行调用

kubernetes的四种端口
- nodeport。nodePort是外部访问k8s集群中service的端口,通过nodeIP: nodePort可以从外部访问到某个service;
- port。port是k8s集群内部访问service的端口,即通过clusterIP: port可以访问到某个service;
- targetPort。targetPort是pod的端口,从port和nodePort来的流量经过kube-proxy流入到后端pod的targetPort上,最后进入容器;
- containerPort。containerPort是pod内部容器的端口,targetPort映射到containerPort。

kube-proxy和service介绍
kube-proxy每个node都有一个,负责Pod网络代理,负责为Service提供cluster内部的服务发现和负载均衡。它是K8s集群内部的负载均衡器,也是一个分布式代理服务器。
- 监控pod,通过 pod的标签( lables)去判断这个断点信息是否写入到 Endpoints里,pod如果发生了变化,及时修改映射关系,修改映射关系的同时,修改路由规则,以便在负载均衡时可以选择到新的pod;
- 监控service,定时从etcd服务获取到service信息来做相应的策略,维护网络规则和四层负载均衡工作;
- 负责写入规则至 IPTABLES、IPVS;
- 对每个 Service,它都为其在本地节点开放一个端口,作为其服务代理端口;发往该端口的请求会采用一定的策略转发给与该服务对应的后端 Pod 实体。
endpoint是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址。service配置selector,endpoint controller才会自动创建对应的endpoint对象;否则,不会生成endpoint对象。
【例如】k8s集群中创建一个名为hello的service,就会生成一个同名的endpoint对象,ENDPOINTS就是service关联的pod的ip地址和端口。
service是一组pod的服务抽象,负责将请求分发给对应的pod。service是K8S的资源对象,service资源对象运行在每一个node节点上,每一个node节点都有一个service进程,service有自己的IP地址(虚拟IP),而service VIP相当于一个网关,所有的请求都要经过service VIP,通过service VIP进行转发,从而实现负载均衡。
service VIP一旦被创建,是不会被修改的,除非删除service后重新创建service;同时由于service信息存储在高可用的etcd中,且service实例运行在多个node节点上,因此Service VIP不存在单点故障的问题;由于service VIP中使用的是虚拟IP,因此Service VIP只能在局域网内部进行访问,不能通过外网进行访问,如果想要进行外网访问,则需要借助物理网卡进行端口映射转发。
kube-proxy的作用主要是负责service的实现,具体来说,就是实现了内部从pod到service和外部的从node port向service的访问。
Service 能够提供负载均衡的能力,但是在使用上有以下限制:只提供 4 层负载均衡能力,而没有 7 层功能。但是可以通过增加
Ingress来添加一个 7 层的负载均衡能力。负载均衡分类
二层负载均衡:**负载均衡服务器对外依然提供一个VIP(虚IP),集群中不同的机器采用相同IP地址,但是机器的MAC地址不一样。**当负载均衡服务器接受到请求之后,通过改写报文的目标MAC地址的方式将请求转发到目标机器实现负载均衡。
三层负载均衡:和二层负载均衡类似,负载均衡服务器对外依然提供一个VIP(虚IP),但是集群中不同的机器采用不同的IP地址。当负载均衡服务器接受到请求之后,根据不同的负载均衡算法,通过IP将请求转发至不同的真实服务器。
四层负载均衡:四层负载均衡工作在OSI模型的传输层,由于在传输层,只有TCP/UDP协议,这两种协议中除了包含源IP、目标IP以外,还包含源端口号及目的端口号。四层负载均衡服务器在接受到客户端请求后,以后通过修改数据包的地址信息(IP+端口号)将流量转发到应用服务器。
七层负载均衡:七层负载均衡工作在OSI模型的应用层,应用层协议较多,常用http、radius、dns等。七层负载就可以基于这些应用层协议来负载。这些应用层协议中会包含很多有意义的内容。比如同一个Web服务器的负载均衡,除了根据IP加端口进行负载外,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。
service代理方式
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种VIP(虚拟 IP)的形式,而不是 ExternalName 的形式。
在 Kubernetes v1.0 版本,代理完全在 userspace。
在 Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。从 Kubernetes v1.2 起,默认就是 iptables 代理。
在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理,在 Kubernetes 1.14 版本开始默认使用 ipvs 代理。
Q:为什么使用服务代理而不使用 DNS 轮询?
A:
- DNS 实现的历史由来已久,它不遵守记录 TTL,并且在名称查找结果到期后对其进行缓存。
- 有些应用程序仅执行一次 DNS 查找,并无限期地缓存结果。
- 即使应用和库进行了适当的重新解析,DNS 记录上的 TTL 值低或为零也可能会给 DNS 带来高负载,从而使管理变得困难。

- 在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程
- apiserver 通过监控 kube-proxy 去进行对服务和端点的监控
- iptables 是 Service 代理方式的一种,其中保存地址映射及规则,通过 kube-proxy 写入的
- 客户端访问节点时通过 iptables 来实现
- kube-proxy 通过 pod 的标签(lables)是否匹配去判断这个断点信息是否写入到 Endpoints(包含服务选择器(通过标签匹配)匹配到的所有 Pod 的引用) 里去。
- kube-proxy 通过不同的负载均衡策略,访问对应的 Pod。
userspace
userspace是在用户空间,通过kube-proxy来实现service的代理服务。

userspace这种mode最大的问题是,service的请求会先从用户空间进入内核iptables,然后再回到用户空间,由kube-proxy完成后端Endpoints的选择和代理工作,这样流量从用户空间进出内核带来的性能损耗是不可接受的。这也是k8s v1.0及之前版本中对kube-proxy质疑最大的一点,因此社区就开始研究iptables mode。
userspace这种模式下,kube-proxy 持续监听 Service 以及 Endpoints 对象的变化;对每个 Service,它都为其在本地节点开放一个端口,作为其服务代理端口;发往该端口的请求会采用一定的策略转发给与该服务对应的后端 Pod 实体。kube-proxy 同时会在本地节点设置 iptables 规则,配置一个 Virtual IP,把发往 Virtual IP 的请求重定向到与该 Virtual IP 对应的服务代理端口上。其工作流程大体如下:

由此分析: 该模式请求在到达 iptables 进行处理时就会进入内核,而 kube-proxy 监听则是在用户态, 请求就形成了从用户态到内核态再返回到用户态的传递过程, 一定程度降低了服务性能。
iptables
该模式完全利用内核iptables来实现service的代理和LB。


kube-proxy 持续监听 Pod 以及 service 变化,发生变化后,修改地址映射和路由规则,写入iptables中,由iptables完成反向代理;即 iptables 采用NAT直接将对 VIP 的请求转发给后端 Pod,通过 iptables 设置转发策略。其工作流程大体如下:

由此分析: 该模式相比 userspace 模式,克服了请求在用户态-内核态反复传递的问题,性能上有所提升,但使用 iptables NAT 来完成转发,存在不可忽视的性能损耗,而且在大规模场景下,iptables 规则的条目会十分巨大,性能上还要再打折扣。而且iptables主要是专门用来做主机防火墙的,而不是专长做负载均衡的。
ipvs(常用)

与iptables、userspace 模式一样,kube-proxy 依然监听Service以及Endpoints对象的变化, 不过它并不创建反向代理, 也不创建大量的 iptables 规则, 而是通过netlink 创建ipvs规则,并使用k8s Service与Endpoints信息,对所在节点的ipvs规则进行定期同步; netlink 与 iptables 底层都是基于 netfilter 钩子,但是 netlink 由于采用了 hash table 而且直接工作在内核态,在性能上比 iptables 更优。
ipvs与iptables的区别:①ipvs为大型集群提供了更好的可扩展性和性能;②ipvs支持比iptables更复杂的负载均衡算法;③ipvs支持服务器的健康检查和连接重试等。
与 iptables 类似,ipvs 于 netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 ipvs 可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs 为负载均衡算法提供了更多选项,例如:
- rr:轮询调度
- lc:最小连接数
- dh:目标哈希
- sh:源哈希
- sed:最短期望延迟
- nq:不排队调度
注意:要在 IPVS 模式下运行 kube-proxy,必须在启动 kube-proxy 之前确保 IPVS 内核模块已安装。当 kube-proxy 以 IPVS 代理模式启动时,它将验证节点上 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将退回到以 iptables 代理模式运行。
其工作流程大体如下:

**由此分析:**ipvs 是目前 kube-proxy 所支持的最新代理模式,相比使用 iptables,使用 ipvs 具有更高的性能。
参考:
👉 Kubernetes(k8s)kube-proxy、Service详解 - 掘金 (juejin.cn)
service的类型
ClusterIp
默认类型,自动分配一个仅
Cluster内部可以访问的vip,只能被集群内部的应用程序所访问。一个Service可能对应多个EndPoint(Pod),client访问的是Cluster IP,通过iptables规则转到某个Pod,从而达到负载均衡的效果。
ClusterIP:ServicePort→PodIP:containerPort
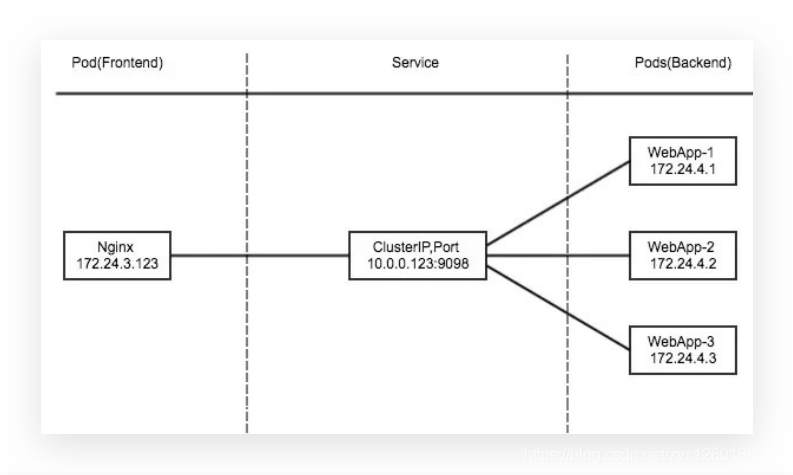
- apiserver:用户通过 kubectl 命令向 apiserver 发送创建 service 的命令,apiserver 接收到请求后将数据存储到 etcd 中
- kube-proxy:kubernetes 的每个节点中都有一个叫做 kube-porxy 的进程,这个进程负责感知 service,pod 的变化,并将变化的信息写入本地的 iptable 规则中
- iptable:使用 NAT 等技术将 virtualIP 的流量转至 endpoint 中
实例:
创建一个 Deployment(后面几种 Service 类型都使用的这个 Deployment),先写一个 svc-deployment.yaml 资源清单:
apiVersion: apps/v1 kind: Deployment metadata: name: myapp-deploy # Deployment 名称 namespace: default spec: replicas: 3 selector: matchLabels: app: myapp release: stable template: metadata: name: myapp # Pod 名 labels: app: myapp release: stable spec: containers: - name: myapp # 容器名 image: wangyanglinux/myapp:v2 # nginx imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
创建 Service 资源清单,来代理上面创建的三个 Pod。myapp-svc.yaml:
apiVersion: v1 kind: Service metadata: name: myapp-svc # Service名称 spec: type: ClusterIP # Service 类型,不写默认就是 ClusterIP selector: # 用于匹配后端的 Pod 资源对象,需和上面 Pod 的标签一致 app: myapp release: stable ports: - name: http port: 80 # Service端口号 targetPort: 80 # 后端 Pod 端口号 protocol: TCP # 使用的协议- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
访问:
[root@k8s-master01 yaml]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myapp-deploy-6998f78dfc-nt28j 1/1 Running 0 11m 10.244.1.29 k8s-node01- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
NodePort
在
ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过NodeIp:NodePort来访问该服务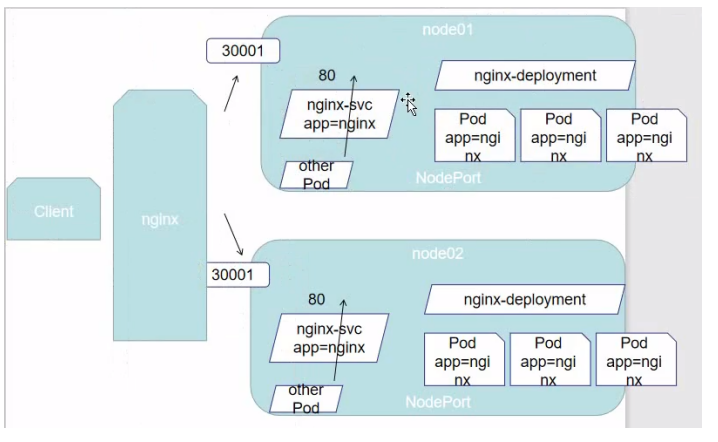
Client→NodeIP:NodePort→ClusterIP:ServicePort→PodIP:containerPort
实例:
创建一个 NodePort Service,匹配 ClusterIP 实例中创建的 Deployment:
apiVersion: v1 kind: Service metadata: name: myapp #service对象名 spec: type: NodePort selector: app: myapp #匹配上面定义的pod资源 release: stable ports: - port: 80 #service端口 targetPort: 80 #后端pod端口 nodePort: 30001 #节点端口,物理机上暴露出来的端口 protocol: TCP #协议- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
查看svc:
[root@k8s-master01 yaml]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE myapp NodePort 10.97.100.171- 1
- 2
- 3
可以从外部访问到
30001端口(每个 k8s 集群的节点都可以该端口):
LoadBalancer
loadBalancer 和 nodePort 其实是同一种方式。区别在于 loadBalancer 在 nodePort 的基础上,借助 cloud provider 创建了 LB 来向节点导流(外部负载均衡器),并将请求转发到 NodeIp:NodePort
- LB 是供应商提供的,是收费的
- 服务器必须是云服务器

ClusterIP、NodePort、LoadBalancer每一个都是前者的加强版,也就意味着ClusterIP是最基础的,如果一个service没有IP,那么就叫Headless
Service(无头服务),可以直接解析到后端的PodIP,如果不是无头service那么解析的是ServiceIPHeadless Service(无头服务)
有时不需要或不想要负载均衡,以及单独的 Service IP 。遇到这种情况,可以通过指定 ClusterIP(spec.clusterIP)的值为 “None” 来创建 Headless Service 。这类 Service 并不会分配 Cluster IP, kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由。主要用来解决 Hostname 与 Podname 变化问题。在创建 StatefulSet 时,必须先创建一个 Headless Service。
使用场景:
- 第一种:自主选择权,有时候 client 想自己来决定使用哪个 Real Server,可以通过查询 DNS 来获取 Real Server 的信息;
- 第二种:Headless Services 还有一个用处(PS:也就是我们需要的那个特性)。Headless Service 的对应的每一个 Endpoints,即每一个 Pod,都会有对应的 DNS 域名。当删除 Pod 时,Pod 的 IP 会变,但是 Pod 的名字不会改变,这样各 Pod 之间就可以通过 Pod 名来互相访问。
实例:
创建一个 Headless Service,还是匹配上面创建的 Deployment(ClusterIP 实例) 下的 Pod:
apiVersion: v1 kind: Service metadata: name: myapp-headless #service对象名 spec: clusterIP: None #将ClusterIP字段设置为None,即表示为headless类型的service资源对象 selector: app: myapp #匹配上面定义的pod资源 ports: - port: 80 #service端口 targetPort: 80 #后端pod端口 protocol: TCP #协议- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
查看 svc:
# 可以看到,Cluster-IP 对应位置的值为 None [root@k8s-master01 yaml]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE myapp-headless ClusterIP None <none> 80/TCP 8s- 1
- 2
- 3
- 4
在 DNS 中查询域名的 A 记录:
# 查看 k8s coredns 的ip [root@k8s-master01 yaml]# kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES coredns-5c98db65d4-5ztqn 1/1 Running 6 21d 10.244.0.11 k8s-master01 <none> <none> coredns-5c98db65d4-pc62t 1/1 Running 6 21d 10.244.0.10 k8s-master01 <none> <none> # 使用 dig 解析域名(没有 dig 要安装:yum -y install bind-utils):dig -t A 域名 @DNS服务器IP # DNS服务器IP:上面获取的两个 coredns ip 中选取一个 # 默认域名:SVC_NAME.NAMESPACE.svc.cluster.local [root@k8s-master01 yaml]# dig -t A myapp-headless.default.svc.cluster.local. @10.244.0.11 ;; ANSWER SECTION: myapp-headless.default.svc.cluster.local. 30 IN A 10.244.1.30 myapp-headless.default.svc.cluster.local. 30 IN A 10.244.1.29 myapp-headless.default.svc.cluster.local. 30 IN A 10.244.2.25 # 可以看到解析的结果和前面创建的 Pod 是对应的,因此可以通过域名访问这几个 Pod- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
ExternalName
**把集群外部的服务引入到集群内部来,在集群内部直接使用。**没有任何类型代理被创建,这只有 kubernetes 1.7 或更高版本的 kube-dns 才支持。
这种类型的 Service 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如私有仓库:hub.zyx.com)。ExternalName Service 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
实例:
apiVersion: v1 kind: Service metadata: name: my-service-1 namespace: default spec: type: ExternalName externalName: hub.zyx.com- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
当查询主机 my-service.defalut.svc.cluster.local ( SVC_NAME.NAMESPACE.svc.cluster.local )时,集群的 DNS 服务将返回一个值 hub.zyx.com 的 CNAME(别名) 记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。
ingress
K8s集群对外暴露服务的方式目前只有三种:
Loadblancer;Nodeport;ingress。ingress其实是一种Nodeport类型的service。Ingress-Nginx github 地址:https://github.com/kubernetes/ingress-nginx
Ingress-Nginx 官方网站:https://kubernetes.github.io/ingress-nginx/

ingress具体的工作原理如下:
- ingress contronler通过与k8s的api进行交互,动态的去感知k8s集群中ingress服务规则的变化,然后读取它,并按照定义的ingress规则,转发到k8s集群中对应的service;
- 而这个ingress规则写明了哪个域名对应k8s集群中的哪个service,然后再根据ingress-controller中的nginx配置模板,生成一段对应的nginx配置;
- 然后再把该配置动态的写到ingress-controller的pod里,该ingress-controller的pod里面运行着一个nginx服务,控制器会把生成的nginx配置写入到nginx的配置文件中,然后reload一下,使其配置生效,以此来达到域名分配置及动态更新的效果。
作用:
- 动态配置服务。如果按照传统方式, 当新增加一个服务时, 我们可能需要在流量入口加一个反向代理指向我们新的k8s服务. 而如果用了Ingress, 只需要配置好这个服务, 当服务启动时, 会自动注册到Ingress的中, 不需要而外的操作。
- 减少不必要的端口暴露。配置过k8s的都清楚, 第一步是要关闭防火墙的, 主要原因是k8s的很多服务会以NodePort方式映射出去, 这样就相当于给宿主机打了很多孔, 既不安全也不优雅,而Ingress可以避免这个问题, 除了Ingress自身服务可能需要映射出去, 其他服务都不要用NodePort方式。
Ingress Controller 用 Deployment 方式部署,给它添加一个 Service,类型为 NodePort,部署完成后查看会给出一个端口,通过
kubectl get svc我们可以查看到这个端口,这个端口在集群的每个节点都可以访问,通过访问集群节点的这个端口就可以访问 Ingress Controller 了。但是集群节点这么多,而且端口又不是 80和443,太不爽了,一般我们会在前面自己搭个负载均衡器,比如用 Nginx,将请求转发到集群各个节点的那个端口上,这样我们访问 Nginx 就相当于访问到 Ingress Controller 了部署
官方网址:https://kubernetes.github.io/ingress-nginx/deploy/#bare-metal
官方给的方法:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.0.3/deploy/static/provider/baremetal/deploy.yaml- 1
我先下载 .yaml 文件,然后再创建:
# 先获取 yaml 文件,可以用这个文件来创建或者删除 Ingress wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.0.3/deploy/static/provider/baremetal/deploy.yaml # 安装 Ingress kubectl apply -f deploy.yaml # 删除 Ingress kubectl delete -f deploy.yaml- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可能出现的问
-
yam文件版本报错
# 安装时发现 yaml 文件中 ValidatingWebhookConfiguration 版本报错,先获取版本 # 没有报错可以不用管这条命令 [root@k8s-master01 yaml]# kubectl explain ValidatingWebhookConfiguration KIND: ValidatingWebhookConfiguration VERSION: admissionregistration.k8s.io/v1beta1 # 修改下载 yaml 中 ValidatingWebhookConfiguration 对应的 pod 的版本,再重新安装- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
镜像下载不下来
查看 pod 日志,找到是哪个镜像下载不下来,然后到 DockerHub 上找到相应替代的镜像,修改
yaml文件中对应的镜像,再重新启动这是我找到的两个替代镜像,(注意版本对应):
- https://registry.hub.docker.com/r/liangjw/kube-webhook-certgen/tags
- https://registry.hub.docker.com/r/liangjw/ingress-nginx-controller/tags
image: k8s.gcr.io/ingress-nginx/controller:v1.0.3@sha256:4ade87838eb8256b094fbb5272d7dda9b6c7fa8b759e6af5383c1300996a7452 替换为: image: liangjw/ingress-nginx-controller:v1.0.3@sha256:4ade87838eb8256b094fbb5272d7dda9b6c7fa8b759e6af5383c1300996a7452- 1
- 2
- 3
image: k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.0@sha256:f3b6b39a6062328c095337b4cadcefd1612348fdd5190b1dcbcb9b9e90bd8068 替换为: image: liangjw/kube-webhook-certgen:v1.0@sha256:f3b6b39a6062328c095337b4cadcefd1612348fdd5190b1dcbcb9b9e90bd8068- 1
- 2
- 3
Ingress HTTP 代理访问示例
(1)先创建两个
Pod和ClusterIP Service,提供 Nginx 内部访问:# vim deployment-nginx.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-dm spec: replicas: 2 selector: matchLabels: name: nginx template: metadata: labels: name: nginx spec: containers: - name: nginx image: wangyanglinux/myapp:v1 ports: - name: http containerPort: 80 --- # 定义nginx 的 svc apiVersion: v1 kind: Service metadata: name: nginx-svc annotations: kubernets.io/ingress.class: "nginx" spec: ports: - port: 80 targetPort: 80 protocol: TCP selector: name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
(2)再创建 Ingress 将服务暴露到外部
官方文档:https://kubernetes.io/docs/concepts/services-networking/ingress/
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: nginx-test spec: rules: # 规则,List,可配置多个域名。 - host: "www.zyx.com" # 主机域名 http: paths: # 路径 - path: / backend: serviceName: nginx-svc # 这里链接的是上面创建的 svc 的名称 servicePort: 80 # svc 的端口- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
# 查看 ingress kubectl get ingress- 1
- 2
Ingress 资源清单中的 spec.rules 最终会转换为 nginx 的虚拟主机配置,进入到 ingress-nginx 容器中查看配置:
kubectl exec ingress-nginx-controller-78fd88bd5-sbrz5 -n ingress-nginx -it -- /bin/bash cat nginx.conf- 1
- 2
- 3
(3)修改 hosts 文件,设置上面的域名解析
192.168.66.10 www.zyx.com- 1
(4)查看端口
[root@k8s-master01 ingress]# kubectl get svc -n ingress-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress-nginx-controller NodePort 10.96.189.184 <none> 80:31534/TCP,443:31345/TCP 10h- 1
- 2
- 3
(5)域名访问

Ingress HTTPS 代理访问示例
(1)创建证书,以及 cert 存储方式
# 生成私钥和证书 openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc/O=nginxsvc" # kubectl 创建 secret 资源,这个 secret 后面要用 kubectl create secret tls tls-secret --key tls.key --cert tls.crt # 查看kubectl 的 secret 资源 kubectl get secret tls-secret- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(2)创建 Deployment 和 Service,这里仍使用上面创建的 Deployment
(3)创建Ingress
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: nginx-test-https spec: tls: - hosts: - www.zyx3.com # host 主机 secretName: tls-secret # 与上面创建的 secret 要对应上 rules: # 规则,List,可配置多个域名。 - host: www.zyx3.com # 主机域名 http: paths: # 路径 - path: / # 域名的根路径 backend: serviceName: nginx-svc # 这里链接的是上面创建的 svc 的名称 servicePort: 80 # svc 的端口- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
(4)获取 https 连接的端口
[root@k8s-master01 https]# kubectl get svc -n ingress-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress-nginx-controller NodePort 10.96.189.184 <none> 80:31534/TCP,443:31345/TCP 11h- 1
- 2
- 3
(5)配置 hosts,然后访问域名
Nginx 进行 BasicAuth
(1)创建秘钥文件
yum install -y httpd # 创建密钥文件 # -c 创建,创建文件为 auth,用户名为 foo htpasswd -c auth foo # 然后连输两次密码,这个密码为为之后认证使用 # 构建基础权限认证,根据文件 kubectl create secret generic basic-auth --from-file=auth- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(2)创建Ingress
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: ingress-with-auth annotations: # 身份验证类型 nginx.ingress.kubernetes.io/auth-type: basic # secret 的名字(上面定义好了) nginx.ingress.kubernetes.io/auth-secret: basic-auth # 要显示的信息,说明为什么需要认证 nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo' spec: rules: - host: auth.zyx.com http: paths: - path: / backend: serviceName: nginx-svc servicePort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(3)添加 hosts 域名解析,然后访问就可以看到 BasicAuth 已经成功
Nginx 进行重写
名称 描述 值 nginx.ingress.kubernetes.io/rewrite-target 必须重定向流量的目标URI 串 nginx.ingress.kubernetes.io/ssl-redirect 指示位置部分是否仅可访问SSL(当Ingress包含证书时默认为True) 布尔 nginx.ingress.kubernetes.io/force-ssl-redirect 即使Ingress未启用TLS,也强制重定向到HTTPS 布尔 nginx.ingress.kubernetes.io/app-root 定义Controller必须重定向的应用程序根,如果它在’/'上下文中 串 nginx.ingress.kubernetes.io/use-regex 指示Ingress上定义的路径是否使用正则表达式 布尔 重定向:
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: nginx-test annotations: nginx.ingress.kubernetes.io/rewrite-target: https://auth.zyx.com:31345 spec: rules: - host: re.zyx.com # 访问这个地址,就会被重定向到 https://auth.zyx.com:31345 http: # 这里配置不配置均可 paths: - path: / backend: serviceName: nginx-svc servicePort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
相关阅读:
2023年tiktok自动化运营软件新排名看这里!
算法-排序算法
IP路由策略1
IPv6地址基础理论讲解
CRD2 值得一读的知识蒸馏与对比学习结合的paper 小陈读paper
HCNP Routing&Switching之RSTP保护
抖音小店开店最新一套运营教程,低成本的风口项目,直接套用就行
C++IO流
Java数据结构—链表与LinkedList
【回溯算法】leetcode 784. 字母大小写全排列
- 原文地址:https://blog.csdn.net/qq_44766883/article/details/126549131
