-
【ChatIE】论文解读:Zero-Shot Information Extraction via Chatting with ChatGPT
论文:Zero-Shot Information Extraction via Chatting with ChatGPT
作者:Xiang Wei, Xingyu Cui, Ning Cheng, Xiaobin Wang, Xin Zhang, Shen Huang, Pengjun Xie, Jinan Xu, Yufeng Chen, Meishan Zhang, Yong Jiang, Wenjuan Han
时间:2023zero-shot information extraction 的目是从未注释的文本中构建信息提取(IE)系统,由于大模型发展迅速,其下游任务效果有了质的提升,文章中考虑采用prompt技巧进行信息提取,观察zero-shot 提取信息的可取性;
为此创建了一个二阶段的多回合问答框架ChatIE,并在三个IE任务上广泛地评估:整体关系三重提取、命名实体识别和事件提取。在两种语言的6个数据集上的经验结果表明,ChatIE取得了令人印象深刻的性能;

介绍
首先information extration 的目的是从非结构化的文本中提取出结构化的信息,并将结构化的信息转化为结构化的数据格式,信息提取主要由三块任务构成:三元组提取,实体命名识别,事件提取 entity-relation triple extract (RE), named entity recognition (NER), event extraction (EE);
在一般的处理工作中,以RE任务中PURE模型举例子[2010.12812] A Frustratingly Easy Approach for Entity and Relation Extraction (arxiv.org),首先识别出两个实体,然后再预测两个实体之间的关系,虽然说效果很好,但是这只适用于特别的任务并且是监督训练的,需要大量的标注数据;
由于一般IE方法的特殊性和昂贵性,这里转向研究ChatGPT的prompt来进行IE任务处理;
作者提出了一个两阶段的多轮问答框架,在第一阶段找出相应的元素类型,在第二阶段对每个元素类型进行链式信息提取;利用该框架进行信息提取的效果很明显;
ChatIE
这是一个两阶段框架:在第一阶段,目标是在三个任务中分别找出句子中的实体、关系或事件的现有类型。这样,我们就可以过滤掉不存在的元素类型,以减少搜索空间和计算复杂度,从而提取信息。然后在第二阶段,我们根据第一阶段提取的元素类型以及相应的任务特定方案,进一步提取相关信息。

如果没有提取任何内容,每个阶段都将生成无token的回答;
Entity-Relation Triple Extration (RE)
三元组提取任务也就是在文本中提取 ( s , r , o ) (s,r,o) (s,r,o):
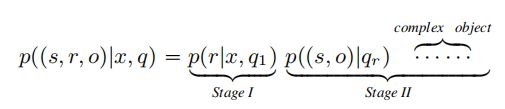
这里的r指的是第一阶段提取到的关系,q1指第一阶段的问题,qr指根据第一阶段得到的关系提出的第二阶段的问题,也就得到 ( s , r , o ) (s,r,o) (s,r,o)
Named Entity Recognition (NER)
第一阶段我们先去获得实体类型,第二阶段根据实体类型获得实体的名字;
例如:第一阶段得到人物,地点,导演;第二阶段得到人物是谁,地点在哪,导演是谁;
Event Extraction (EE)
第一阶段我们先去获得事件类型并进行分类,第二阶段再根据每个类型的事件去获得类型;
实验
数据
RE数据:NYT11-HRL 包含12个预定义的关系类型,DuIE2.0 该行业中最大的基于模式的中国RE数据集,包含48种预定义的关系类型。三元组中的一些对象具有多个属性;
NER数据:The conllpp dataset conll2003的修改版本包含4种实体类型,MSRA 一个针对新闻字段的中文命名实体识别数据集,其中包含3种实体类型。
EE数据:DuEE1.0 百度发布的中文事件提取数据集,The ACE05 corpus 来自新闻通讯社和在线论坛等各种领域的文档和句子级别的事件注释。
评价指标
micro F1
结果
可以看到ChatIE的效果很突出;同时观察下表:

可以发现,基于聊天的Chat-based prompt 要比 一般的prompt得到的更准确;
结论
ChatIE 在 zero-shot information extration 任务中效果表现突出;
-
相关阅读:
并发编程(三)原子性(2)
嵌入式养成计划-42----QT 创建项目--窗口界面--常用类及组件
ChatGPT 国内快速上手指南
Git clone时报错: OpenSSL SSL_read: Connection was reset, errno 10054
【Linux】环境变量
论文精读:Medical Transformer: Gated Axial-Attention forMedical Image Segmentation
集合类不安全
Hive安装配置 - 内嵌模式
[附源码]java毕业设计停车场管理系统
静态工厂模式,抽象工厂模式,建造者模式
- 原文地址:https://blog.csdn.net/m0_72947390/article/details/136139702