-
Keyword2Text: 一种即插即用的可控文本生成方法

背景
本次分享一篇可控文本生成方面的论文。提到文本生成,可能很多人的第一印象都是不靠谱,不就是复制粘贴,模型只是将训练语料记住了而已,谈创造性都是瞎扯emem…。这趟浑水总该有人趟吧,如果对ai充满悲观的人,可以去瞧瞧cv那边文本到图片的生成,或者能让你对ai有所改观。闲话少说,直接切入文本生成主题。
谈到文本生成,可能会想到很多模型,如GPT系列、T5系列、UniLM、Bart等等。但这些模型在可控方面做的都不够好,文本生成的主题主要还是依赖于训练语料的分布。
谈到解码,也有很多种,从最开始的Greedy Search, 到后来的Beam Search,以及为了考虑多样性,引入的top-k、top-p的采样解码,还有今年从信息量角度考虑的typical-decoder。这些方法基本上克服了重复、以及多样性问题。但在文本生成中,还有一个比较重要的问题: 生成文本主题的可控性。
本文主要提出了一种即插即用的可控生成方法,可以适配到各种生成模型上,而且不需要重新训练模型,只是作用在推理阶段的解码器上。下面看看具体的方法。
模型
生成模型
首先,回顾一下文本生成模型:
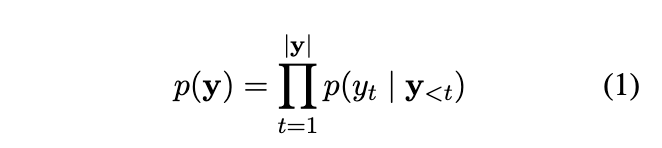
即:知道前t-1个词,然后预测第t个词的概率分布。
如何在这上面做可控呢?一个很自然的想法就是对这个概率分布做干预。
可控方法
本文给出的方法:
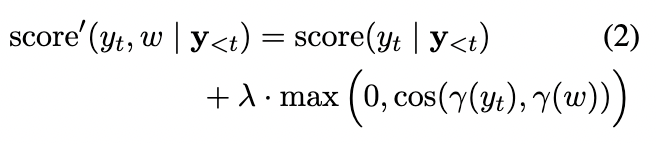
上面(2)式中右边加法的第二部分是本文提出的,其中w是先验的一些关键词(也就是主题词), γ ( ⋅ ) \gamma(·) γ(⋅)是取出对应词的词向量(按道理只要能衡量两个词相关性的向量都行)。 λ \lambda λ是一个超参数。简而言之,就是每一步生成的时候,都去计算一下当前预测词和主题词之间的相似度,然后将这种相似度和预测词的概率分布进行加权和,最后得到当前词重整之后的概率分布。
如果和top-k算法结合,那就是取前top-k个预测词,进行上式的计算,接着进行采样。这样就显性加大了靠近主题词的预测词的采样概率。就达到了可控的目的。
多个关键词
上面讲的方法,可以理解为只有一个主题词,那如果有多个主题词呢? 有多个主题词,可能又会分两种情况:
- 多个主题词之间是有顺序关系的
- 多个主题词之间无顺序的
如果多个主题词之间有顺序,并且我们希望这些主题词都在文章中出现,那就依次指向每个单词 w n w_n wn,即从n = 1开始,并以 s c o r e ( y t , w 1 ∣ y < t ) score(y_t, w_1 | y\lt t) score(yt,w1∣y<t)作为评分函数,
直到单词w1出现在生成的文本中。然后,切换到评分 s c o r e ( y t , w 2 ∣ y < t ) score(y_t, w_2 | y \lt t) score(yt,w2∣y<t),直到单词 w 2 w_2 w2出现在生成的文本中。我们重复这个过程,直到生成的文本中出现所有的N个单词。如果多个主题词之间没有顺序,那每一次预测词的向量和所有主题词进行相似度计算,选最大的。
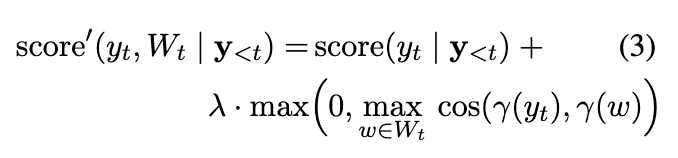
λ \lambda λ参数设置
这篇文章的可控性基本就是这样子,很简单。下面我们看一下本文 λ \lambda λ参数的设置。从上面的式子可以看出, λ \lambda λ参数的调节范围可以从不受控制的生成到迫使下一个词成为引导词。
本文建议以指数的方式逐渐增大 λ \lambda λ,随着生成序列的长度增加,语义变化的强度也会增大,直到生成我们的引导词。
具体如下公式:
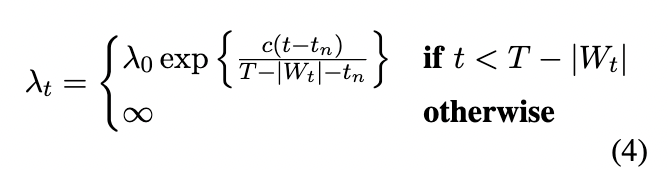
其中t代表时间步。 t n t_n tn代表最近一次出现引导词的位置位置。 ∣ W t ∣ |W_t| ∣Wt∣代表到当前时间步总共出现了几个引导词,T为文本生成的最大长度。 c为超参数。 也就是随着时间步的推进, λ t \lambda_t λt逐渐变大,直到最后变成无穷大,强制生成引导词。 这里的引导词可以理解为上面说的主题词。
实验
在看实验结果之前,先看一下本文使用的几个评价指标: Perplexity(困惑度)、Repetition(重复度)、Success Rate(正确率)
- Perplexity(困惑度): 联合概率负对数的平均值。越小越好(也不是很绝对,一般意义上认为)。
- Repetition(重复率): 人类正常说话的重复率为0.6%。然后统计生成文本的重复率,和人类正常重复率做对比。
- Success Rate(正确率): 预测token的正确个数占比,肯定越高越好。
首先作者在top-p=0.9的情况下,用了本文的方法,但 λ \lambda λ没有采用退火的算法逐渐增大,是采用固定的值。可以发现随着 λ \lambda λ的增大,正确率SR是有大幅提高,但也能很好的解释PPL随着 λ \lambda λ的增大而增大。因为你对模型的干预越大,岂不是预测的概率就不是模型本身的概率分布了。也就导致PPL变大了


然后,作者也尝试了不同的引导方法:
Guide All: 和所有引导词做相似度计算,然后加和。一次将分数转移到所有的指导词上。
Guide Random(随机引导): 在每一步,从剩余的引导词中均匀随机地选择下一个引导词,并将分数移向这个词。

另外作者也将本文的方法与之前不同的解码方法结合,做了对比,其中NS就是核采样的方法,也就是top-p。 BS为BeamSearch。
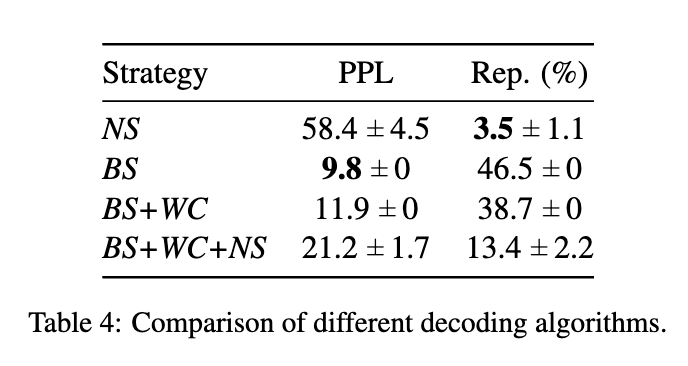
基于ROC数据集与其他集中方法进行了对比,结果如下:


-
相关阅读:
C++ 内存模型
技术内幕 | StarRocks Pipeline 执行框架(下)
Python实现基于Optuna超参数自动优化的xgboost回归模型(XGBRegressor算法)项目实战
selenium模块
maven高级
卷积神经网络的训练过程,卷积神经网络如何训练
华为P系列“砍了”,三角美学系列全新登场
基于JAVA-酒店疫情防控系统-计算机毕业设计源码+系统+mysql数据库+lw文档+部署
1072 Gas Station
C++语法基础
- 原文地址:https://blog.csdn.net/shawroad88/article/details/126549098