-
从一道算法题到Map再到for...of的执行原理
hey🖐! 我是pino😊😊。一枚小透明,期待关注➕ 点赞,共同成长~
事情是这样的,前几天在做一道算法题的时候看到了别人的一种解法,但是其中有一句写法一开始并没有弄明白,后来查阅了好多资料,又重新看了阮一峰老师关于es6的Map那一章节,才弄明白是怎么回事。
这道算法题题目是这样的:
题目 🦀️
146. LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现
LRUCache类:LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。函数
get和put必须以 O(1) 的平均时间复杂度运行。示例:
//输入 ["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"] [[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]] //输出 [null, null, null, 1, null, -1, null, -1, 3, 4] 解释 LRUCache lRUCache = new LRUCache(2); lRUCache.put(1, 1); // 缓存是 {1=1} lRUCache.put(2, 2); // 缓存是 {1=1, 2=2} lRUCache.get(1); // 返回 1 lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3} lRUCache.get(2); // 返回 -1 (未找到) lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3} lRUCache.get(1); // 返回 -1 (未找到) lRUCache.get(3); // 返回 3 lRUCache.get(4); // 返回 4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
提示:
- 1 <= capacity <= 3000
- 0 <= key <= 10000
- 0 <= value <= 105
- 最多调用 2 * 105 次 get 和 put
本题其实是数据的一种更新策略,即保证活跃的数据始终保持在最新的位置,每次当用户访问某一数据的时候说明这个数据为活跃的数据,就可以将它移动到最新的位置,相反,如果一个数据一直没有被访问过,那么他的位置就会越来越靠后,如果我们的存储空间超出长度,那么将会优先删除这部分不活跃的数据。
思路 ✨
实现一个
LRUCache类,用于初始化缓存结构和接收容量长度 实现一个get函数,用于获取值,并更新数据位置 实现一个put函数,用于更改和插入值,需要注意的是:如果大于容量长度,需要删除最早的一个值解答 😷
/** * @param {number} capacity */ // 初始化缓存结构定义长度 var LRUCache = function(capacity) { // 使用map来保存数据 this.cache = new Map() this.max = capacity }; /** * @param {number} key * @return {number} */ // 获取操作 LRUCache.prototype.get = function(key) { // 判断是否有相对应的值 if(this.cache.has(key)) { let temp = this.cache.get(key) // 将值从map中删除掉,然后重新添加一遍,保证刚使用的的值始终处于最新的位置 this.cache.delete(key) this.cache.set(key, temp) return temp } return -1 }; /** * @param {number} key * @param {number} value * @return {void} */ // 更新/添加值 LRUCache.prototype.put = function(key, value) { // 删除查找到的值 if(this.cache.has(key)) { this.cache.delete(key) // 判断是否超出长度 } else if (this.cache.size >= this.max) { // 获取第一个添加的key this.cache.delete(this.cache.keys().next().value) } // 对值进行更新 this.cache.set(key, value) }; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
疑问 ❓
至此,这个算法题目就完成了,但是!相信有很多人可能会有我刚开始的疑问,来看一下
put方法的实现// 更新/添加值 LRUCache.prototype.put = function(key, value) { // 删除查找到的值 if(this.cache.has(key)) { this.cache.delete(key) // 判断是否超出长度 } else if (this.cache.size >= this.max) { // 获取第一个添加的key this.cache.delete(this.cache.keys().next().value) } // 对值进行更新 this.cache.set(key, value) };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
主要是判断长度是否超出后删除第一个元素的写法:
this.cache.delete(this.cache.keys().next().value) this.cache.keys().next().value // 这个next()是哪来的??- 1
- 2
- 3
可以看到我们并没有向任何数据项上定义任何
next()方法,那么它是如何被调用的呢?它上面的value方法又是怎么得来的?它是如果获取到第一个位置的元素的?这一切都要从
Map这个数据结构说起。Map的方法
Map中有三个遍历方法有三个,他们分别返回Map数据的遍历器map.keys()-> Map Iterator 返回map的键遍历器。map.values()-> Map Iterator 值遍历器。map.entries(o)-> Map Iterator 键值对遍历器。
那么遍历器
(Iterator)是啥?遍历器其实就是部署在某些数据结构上的一个方法,而部署了遍历器的对象也被叫做可迭代对象。
可迭代对象就是一个对象在内部部署了遍历器
(Iterator),这就代表这个对象是可以被遍历的。Iterator的作用:一是为各种数据结构,提供一个统一的、简便的访问接口;二是使得数据结构的成员能够按某种次序排列;Iterator的遍历过程是这样的。(1)创建一个指针对象,指向当前数据结构的起始位置。也就是说,遍历器对象本质上,就是一个指针对象。
(2)第一次调用指针对象的
next方法,可以将指针指向数据结构的第一个成员。(3)第二次调用指针对象的
next方法,指针就指向数据结构的第二个成员。(4)不断调用指针对象的
next方法,直到它指向数据结构的结束位置。每一次调用
next方法,都会返回数据结构的当前成员的信息。具体来说,就是返回一个包含value和done两个属性的对象。其中,value属性是当前成员的值,done属性是一个布尔值,表示遍历是否结束。 ES6 规定,默认的Iterator接口部署在数据结构的Symbol.iterator属性,或者说,一个数据结构只要具有Symbol.iterator属性,就可以认为是“可遍历的”(iterable)。Symbol.iterator属性本身是一个函数,就是当前数据结构默认的遍历器生成函数。例如:
const obj = { // 直接在对象中定义迭代器函数 [Symbol.iterator] : function () { return { next: function () { return { value: 1, done: true }; } }; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
使用
object对象结构来创建Symbol.iterator属性实现遍历对象:const obj = { // 定义数据 a: 1, b: 2, c: 3, // 定义迭代器函数 [Symbol.iterator]: function() { // 初始化遍历次数 let index = 0 // 获取对象值 let data = Object.keys(this) return { // 返回遍历函数,每次判断是否已经遍历完成(index是否大于等于长度) next(value) { return { done: index >= data.length, value: data[index++] } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
for(let i of obj){ console.log(i) } // a b c- 1
- 2
- 3
- 4
而原生具备
Iterator接口的数据结构如下:Array Map Set String TypedArray 函数的 arguments 对象 NodeList 对象- 1
- 2
- 3
- 4
- 5
- 6
- 7
而
Map就是js原生部署了遍历器的数据结构之一。 所以就可以看一下keys()方法到底是返回的什么:let map = new Map() map.set(1, '1') console.log(map.keys())- 1
- 2
- 3
- 4
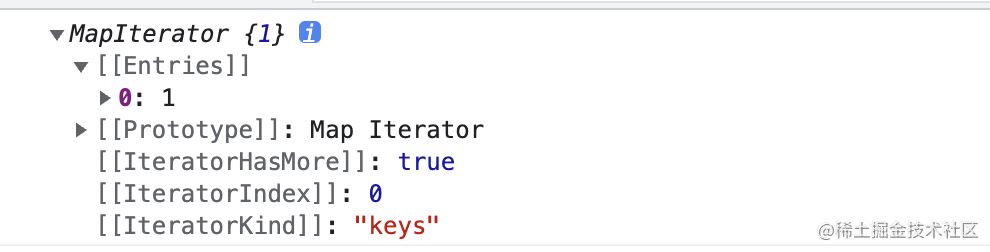
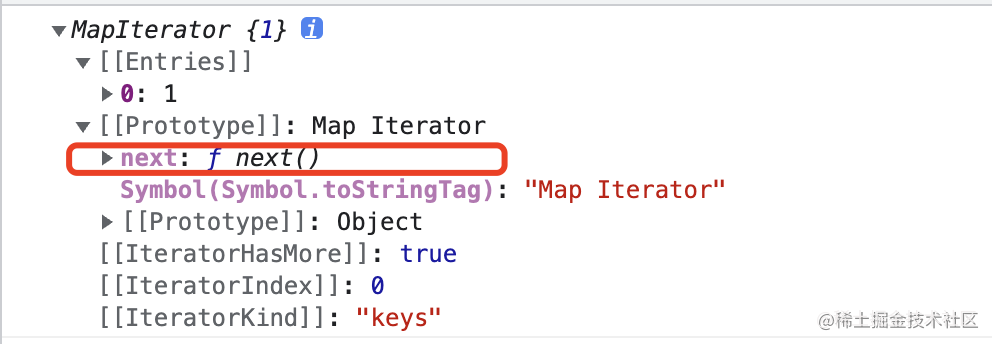
可以看到调用
keys方法之后返回了一个遍历器,里面存在一个next方法,不断的调用next方法就会遍历整个数据结构,通过访问返回的value就可以获取到本次遍历的值。那么为什么就一定能获取第一个元素呢?
Map对象保存键值对,并且能够记住键的原始插入顺序。任何值(对象或者基本类型)都可以作为一个键或一个值。所以通过调用第一次
keys().next().value,就一定可以获取到第一个元素的值。for…of
for...of这种方法就是为了遍历任何部署了遍历器的数据结构,只要部署了遍历器(也就是存在[Symbol.iterator]函数),那么它就可以被for...of进行遍历。那么
for...of是如何实现的呢?其实只需要循环调用
next方法就可以了:function forOf(obj, cb) {let iterable, result;// 首先判断是否存在遍历器,如果不存在就直接抛出错误if (typeof obj[Symbol.iterator] !== "function")throw new TypeError(result + " is not iterable");if (typeof cb !== "function") throw new TypeError("cb must be callable");// 先执行一次[Symbol.iterator]函数得到next函数iterable = obj[Symbol.iterator]();result = iterable.next();// 遍历调用next方法while (!result.done) {cb(result.value);result = iterable.next();} }- 1
- 2
彩蛋 🎉
Map的几种遍历方式:
1.
forEach()方法map.forEach(function(value, key) {console.log(key, value); })- 1
- 2
2.
for..of循环keys = map.keys(); for (key of keys) {console.log(key);// map.get(key)可得value值。 } values = map.values(); for (value of values) {console.log(value); } entries = map.entries(); for ([key, value] of entries) {console.log(key, value); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.利用
Map Iterator对象的next()方法遍历(遍历次数为map.size)。keys = map.keys(); for (i = 0; i < map.size; i++) {key = keys.next().value; // obj.propertyName// key = keys.next()[value]; // obj[propertyName]console.log(key); } values = map.values(); for (i = 0; i < map.size; i++) {value = values.next().value;console.log(value); } entries = map.entries(); for (i = 0; i < map.size; i++) {entry = entries.next().value;console.log(entry[0], entry[1]);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
相关阅读:
让你的相册变成私有云!Synology Photos 的公网访问功能指南
【Spring】Day16
Java SpringBoot VII
网络安全笔记3——双钥密码体制
运维的操作红线
通过matlab实现水产养殖鱼类成熟度自动分析系统
简单的CNN实现——MNIST手写数字识别
UE4 通过按键切换不同的HUD
ArcGIS绘制地球
面试的经历
- 原文地址:https://blog.csdn.net/web22050702/article/details/126541732
