-
PyTorch指定GPU(很受欢迎)
感觉这一篇博客是最具有代表性的博客了
参考链接:PyTorch指定GPU(转载+原创)_universe_R的博客-CSDN博客_pytorch 指定gpu
PyTorch中指定使用的GPU有两种方法:
- 终端运行时设定
- 代码中设定
首先需要设置可见的GPU
注意!!!!!!!!!!!!!!
os.environ[“CUDA_VISIBLE_DEVICES”] = "0, 1, 2"此条命令运行必须放在import torch之前,否则不能生效。- import os
- os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1, 2"
1、终端运行时设定
CUDA_VISIBLE_DEVICES=1,2,3 python train.py2、代码中设定
注意!!!!!!!!!!!!!!
os.environ[“CUDA_VISIBLE_DEVICES”] = "2, 3, 4,5"此条命令运行必须放在import torch之前,否则不能生效。
- import os
- os.environ["CUDA_VISIBLE_DEVICES"] = "2,3,4,5"
- #将模型放入GPU中
- if torch.cuda.device_count() > 1:
- model = torch.nn.DataParallel(model, device_ids=[0,1,2,3])
等价于
- if torch.cuda.device_count() > 1:
- model = torch.nn.DataParallel(model, device_ids=[2,3,4,5])
这是因为在第一段中已经设置了可见GPU为2,3,4,5,就是说假设我们有八块GPU,序号分别为0,1,2,3,4,5,6,7,本来他们的编号也分别为0,1,2,3,4,5,6,7,但是因为设置了可见GPU为2,3,4,5所以我们选取的GPU的序号为2,3,4,5,但是对于程序来说他们的编号分别为[0,1,2,3],如下图所示
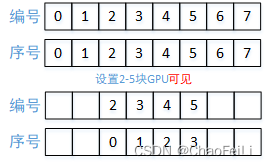
假设我只有[0,1]两块GPU。当我写的代码是用两块GPU的时候,如果有一个GPU被人占用了,那么我可以直接在开头设置 os.environ[“CUDA_VISIBLE_DEVICES”] = "1"或者 "0",这样后面的程序不用动,就可以直接采用一块GPU运行了
-
相关阅读:
2022年最新西藏机动车签字授权人模拟考试及答案
【电力负荷预测】模拟退火算法结合狮群算法优化Elman神经网络电力负荷预测【含Matlab源码 1454期】
猿创征文|我与开发工具的那些事
Hive的常用内置函数
IPM 鸟瞰图公式转换与推导
【外汇天眼】MT4 vs MT5:哪个更适合外汇初学者
Ubuntu中安装OpenSSL
2022年毕业生求职找工作青睐哪个行业?
NLP(5)--自编码器
【时空融合:改进MRA】
- 原文地址:https://blog.csdn.net/ChaoFeiLi/article/details/126540219