-
ubuntu虚拟机中安装Hadoop全过程(单机分布方式+伪分布方式)
使用的虚拟机软件是:VMWare Workstation Pro 14
虚拟机系统:Ubuntu 18.04
注:涉及到的内容比较多,可直接点击相应链接查看对应内容
目录
创建新账户
参考文章:Ubuntu16.04系统中创建新用户
*使用adduser命令
1. 切换为root用户
su root- 1
注:若提示“su: Authentication failure”,原因应该是没有设置root账户的密码
在终端输入:
sudo passwd root- 1
设置完root密码后重新切换为root用户即可
2. 添加新用户hadoop
adduser hadoop- 1
设置密码信息

退出当前账户登录hadoop账户
3. 允许该用户以管理员身份执行指令
-
切换到root
su root
2)执行visudo命令
visudo- 1
-
该命令实际上打开的是/etc/sudoers文件,修改该文件,在“root ALL=(ALL:ALL) ALL”这一行下面加入一行:
hadoop ALL=(ALL:ALL) ALL
ctrl+o(然后再按enter)保存,ctrl+c取消,ctrl+x退出
退出root账户
exit- 1
安装ssh
1. 更新apt源
sudo apt-get update- 1
2. 安装ssh服务端
sudo apt-get install openssh-server- 1
3. 安装后使用如下命令登录本机
ssh localhost- 1
输入yes后输入对应的密码即可登录
4. 输入exit退出ssh
5. 配置免密登录
参考文章:Ubuntu18配置ssh免密登录
cd ~/.ssh/ # 若没有该目录,请先执行一次 ssh localhost ssh-keygen -t rsa # 会有提示,都按回车就可以 cat id_rsa.pub >> authorized_keys # 加入授权 使用ssh localhost试试能否直接登录- 1
- 2
- 3
- 4
- 5
- 6
- 7
安装vim
sudo apt-get install vim- 1
在虚拟机中安装JDK并配置环境变量
参考文章:Ubuntu 18.04安装JDK并配置环境变量 |?Ubuntu18.04 安装Jdk1.8
1. 下载JDK,网址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html

根据系统版本选择下载
2. 解压
解压到本目录下,将文件名换成对应的即可
sudo tar -zxvf jdk-8u171-linux-x64.tar.gz- 1
3. 移动到自己的java目录
sudo mv jdk1.8.0_201 /usr/local/jdk1.8- 1
4. 配置环境变量
使用全局设置方法,是所有用户的共用的环境变量
sudo vim ~/.bashrc- 1
把以下命令复制到最底部,其中,export JAVA_HOME=后面要填写自己解压后的jdk的路径
export JAVA_HOME=/usr/local/jdk1.8 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH- 1
- 2
- 3
- 4
5. 使配置立即生效
source ~/.bashrc- 1
6. 测试是否安装成功
java -version- 1
安装Eclipse(可选)
1. 官网下载:https://www.eclipse.org/downloads/packages/

2. 解压
sudo tar -zxvf eclipse-jee-2018-09-linux-gtk-x86_64.tar.gz- 1
3. 移动到自己的文件夹下
sudo mv eclipse /usr/local/- 1
4. 建立jre软链接,先进入到eclipse的安装目录,打开终端
sudo ln -s /usr/local/jdk1.8/jre jre- 1
5. 添加eclipse桌面图标
cd /usr/share/applications sudo vim eclipse.desktop- 1
- 2
复制如下代码:其中Exec=填写eclipse的安装路径,Icon=填写图标路径
[Desktop Entry] Encoding=UTF-8 Name=Eclipse Comment=Eclipse Exec=/usr/local/eclipse/eclipse Icon=/usr/local/eclipse/icon.xpm Terminal=false StartupNotify=true Type=Application Categories=Application;Development;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
赋予可执行权限:
sudo chmod u+x /usr/share/applications/eclipse.desktop- 1
最后将eclipse图标复制到桌面或固定到dock栏即可
注:打开eclipse报错

-
首先查看jdk版本是否为1.7及以下,安装旧版本eclipse
打开eclipse.ini文件,可以看到:

因为安装的是最新版本的eclipse,可能是内存不足的原因
点击虚拟机-设置-内存,将内存改为2048MB,问题解决

安装Hadoop
参考文章:Ubuntu16.04安装Hadoop单机和伪分布式环境超详细
1. 自行选择版本下载,地址:http://archive.apache.org/dist/hadoop/core/
2. 解压
sudo tar -zxvf hadoop-2.7.1.tar.gz- 1
3. 重命名为hadoop
sudo mv hadoop-2.7.1 hadoop- 1
4. 移动到自己的文件夹下
sudo mv hadoop /usr/local/- 1
5. 授予访问权限
sudo chmod 777 -R /usr/local/hadoop //-R:对目前目录下的所有档案与子目录进行相同的权限变更(即以递回的方式逐个变更) //777:高权限(读、写、执行)- 1
- 2
- 3
6. 配置环境变量
sudo vim ~/.bashrc- 1
添加如下代码
#HADOOP VARIABLES START export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
执行如下代码使其立即生效
source ~/.bashrc- 1
Hadoop伪分布模式修改
1.配置hadoop-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh- 1
添加如下代码,注意JAVA_HOME路径
# The java implementation to use. export JAVA_HOME=/usr/local/jdk1.8 export HADOOP=/usr/local/hadoop export PATH=$PATH:/usr/local/hadoop/bin- 1
- 2
- 3
- 4
2.配置yarn-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/yarn-env.sh- 1
添加如下代码,注意JAVA_HOME路径
# export JAVA_HOME JAVA_HOME=/usr/local/jdk1.8- 1
- 2
3.配置core-site.xml,(这里的tmp.dir不用改,是缓存目录)
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml- 1
插入如下内容
hadoop.tmp.dir file:/usr/local/hadoop/tmp Abase for other temporary directories. fs.defaultFS hdfs://localhost:9000 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
*core-site.xml中原来的有的 < /configuration >一定要删除掉,不然后面格式化的时候会出错。即.xml文件中只有一个 < /configuration >对就可以。
4.修改配置文件 hdfs-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml- 1
插入如下内容,只保留一个 < /configuration >对
dfs.replication 1 dfs.namenode.name.dir file:/usr/local/hadoop/tmp/dfs/name dfs.datanode.data.dir file:/usr/local/hadoop/tmp/dfs/data - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.配置yarn-site.xml,只保留一个 < /configuration >对
sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml- 1
插入如下内容:
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.address 127.0.0.1:8032 yarn.resourcemanager.scheduler.address 127.0.0.1:8030 yarn.resourcemanager.resource-tracker.address 127.0.0.1:8031 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
6. 重启系统
7. 验证Hadoop是否安装成功
输入如下指令
hadoop version- 1
显示如下说明安装成功 若不成功请检查环境变量配置是否正确

启动HDFS伪分布式模式
参考文章:Ubuntu16.04安装Hadoop单机和伪分布式环境超详细
1. 格式化namenode
hdfs namenode -format- 1
成功:

2.启动hdfs
start-all.sh- 1
3.显示进程
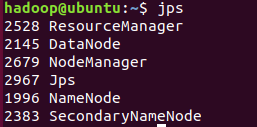
jps- 1
有6个进程表示正确:
4. 打开浏览器,输入http://localhost:50070/
显示:

显示:

至此,Hadoop所需环境全部搭建完毕!
感谢以上参考中提到的各位大佬的文章!
-
相关阅读:
【算法】【分数的加减和减法】Fractions Addition And Subtraction
喜茶奶茶技术培训哪里学?
全志R128应用开发案例——获取真随机数
【相机坐标系、ORB_SLAM2坐标系】
如何计算Renko大小,FPmarkets用ATR3步计算
拼多多助农 商业之外的底色
Windows 安装 chromedriver 和 Python 调试
Java进阶之路-目录
java 手写KMP算法
React Native Webview 中input type=file accept=“image/*“ 无法调起相机问题排查及解决
- 原文地址:https://blog.csdn.net/m0_61083409/article/details/126540519