-
Dubbo基本操作
dubbo之SPI
Dubbo使用了SPI理念,通过扫描META-INF/dubbo的以全限定类名命名的接口文件来找到想要调用的接口,这里重写JDK的SPI目的在于:
- JDK会加载所有的扩展点,浪费资源。
- 如果扩展点加载失败,所有扩展点则会全部无法使用。
- 提供了Adaptive
<dependency> <groupId>org.apache.dubbogroupId> <artifactId>dubboartifactId> dependency>- 1
- 2
- 3
- 4
- 5
//在编写接口层和实现层之后 //在接口层添加@SPI注解 @SPI public interface HelloService { String say(); }- 1
- 2
- 3
- 4
- 5
- 6
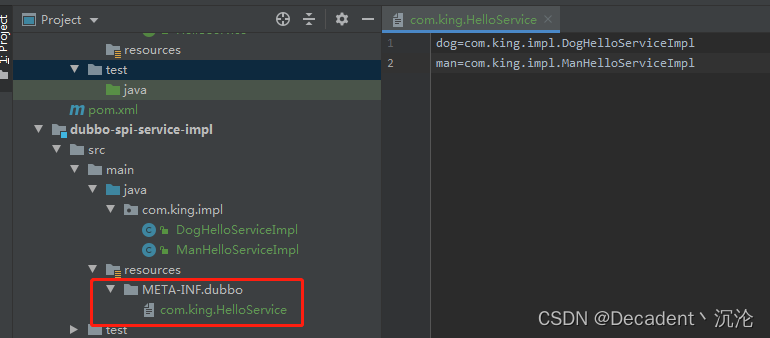
在实现层的resources文件夹下继续创建META-INF/dubbo然后再里创建文件,如图
最后在main函数中编写一下代码即可测试public class SPIMain { public static void main(String[] args) { //获取加载器 ExtensionLoader<HelloService> loader = ExtensionLoader.getExtensionLoader(HelloService.class); //获取支持的加载项 Set<String> supportedExtensions = loader.getSupportedExtensions(); for (String name : supportedExtensions) { HelloService extension = loader.getExtension(name); String say = extension.say(); System.out.println(say); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
dubbo之Adaptive
Adaptive特性,动态加载扩展点,通过对URL请求参数解析来找到对应的实现类。
一下代码是添加Adaptive功能,其中注解@Adaptive下的方法,URL参数比传,否则会因为not fount url 报错。@SPI注解中的value则是设置请求的默认参数。@SPI("dog") public interface HelloService { String say(); @Adaptive String speak(URL url); }- 1
- 2
- 3
- 4
- 5
- 6
下面代码中,因为我们是测试,所以地址随便写,但是 ? 后面必须是接口的名字的转义加上扩展点的名字。其中getAdaptiveExtension()方法中实现了Adaptive,通过loadDirectory()方法,按照META-INF/dubbo路径找到我们的适配实现类,然后根据META-INF/dubbo路径下的文件进行解析,创建实现类实例,封装到Map中。
public class AdaptiveMain { public static void main(String[] args) { URL url = URL.valueOf("agreement://aaa.bbb.ccc?hello.service=dog"); HelloService adaptiveExtension = ExtensionLoader.getExtensionLoader(HelloService.class).getAdaptiveExtension(); String say = adaptiveExtension.speak(url); System.out.println(say); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
dubbo之Filter
Dubbo也和其他框架一样,也有自己的Fiter,实现Dubbo的jar包下的Filter接口,可以做成独立的jar,然后其他使用了Dubbo的工程引用该jar即可。可以通过该机制实现白名单、统计执行时间、日志等功能。
//group中配置该过滤器作用在提供者还是消费者上 @Activate(group = {CommonConstants.CONSUMER,CommonConstants.PROVIDER}) public class DubboSPIFilter implements Filter { @Override public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException { long startTime = System.currentTimeMillis(); try { return invoker.invoke(invocation); } finally { System.out.println("time:" + (System.currentTimeMillis() - startTime)); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
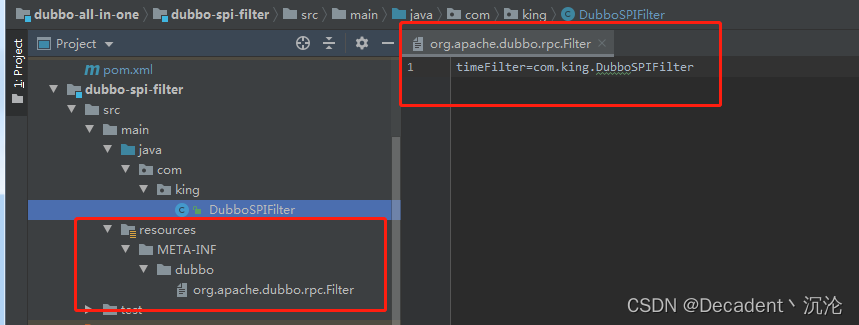
实现了org.apache.dubbo.rpc.Filter 之后,还需要引入SPI机制的配置文件
Dubbo之负载均衡(默认是随机)
- Random LoadBalance 随机
- RoundRobin LoadBalance 轮询
- LeastActive LoadBalance 最少活跃调用数
- ConsistentHash LoadBalance 一致性Hash:包含了虚拟节点的概念
Dubbo在消费者调用生产者时,有一个loadbalance机制,也就是负载均衡。可以通过xml或者@reference(“负载均衡模式”)配置,如轮训、随机、权重、一致性哈希等,也可通过实现LoandBalance接口自定义负载均衡模式。
@Component public class ConsumerCall { @Reference(loadbalance = "roundrobin") HelloService helloService; public String sayHello(String name) { return helloService.sayHello(name); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Dubbo异步
Dubbo亦有异步调用使用方式,类似于ajax。因为有些服务可能处理时间较长,然后dubbo的默认超时时间是1000ms。如果消费者在超过1000ms没有返回,则会出现异常。所以我们需要修改超时时间或者通过异步方式。
可以再调用该服务后,不需要等待服务返回结果,直接进行后续操作,然后通过RpcContext.getContext().getFuture()获取异步调用服务的返回值。该配置只能通过xml方式实现,需要在xml的 < dubbo:referrnce >标签中添加 < dubbo:method method = “sayHello” async=“true”>即可。异步调用以后,消费者会出现返回null的情况。其他
Dubbo提供了线程池概念,可以防止服务线程过多将服务器资源打满
Dubbo提供了路由概念,可以根据请求url中的condition来判断什么条件的服务去向
Dubbo也提供了服务降级以及熔断策略:- FailoverCluster 失败自动切换,失败时会尝试其它服务器
- Failfast Clustere 快速失败,请求失败后快速返回异常结果,不重试
- Failsage Cluster 失败安全,出现异常直接忽略,会对请求多负载均衡
- Failback Cluster 失败自动回复,请求失败后,会自动记录请求到失败队列中
- Forking Cluster 并行调用多个服务提供者,其中有一个返回,则立刻返回结果
最后的概念还没实现,所以。。。
-
相关阅读:
Android-Service详解
智慧火灾应急救援:无人机、直升机航拍视角下的火灾应急救援检测数据集&代码
DP0001A高压差分探头具有哪些具体性能?
元宇宙 • 数学 • NFT
Xcode调试内存最新理解
【配送路径规划】基于matlab遗传算法求解静态外卖骑手路径规划问题【含Matlab源码 2248期】
计算机毕业设计之java+springboot基于vue的网吧管理系统
晶振分频【FPGA】
pytorch初学笔记(十三):神经网络基本结构之Sequential层的使用以及搭建完整的小型神经网络实战
基于Bert迁移学习点击未知弹框
- 原文地址:https://blog.csdn.net/Decembetion/article/details/125632354