-
数据库学习之B-树
常见的搜索结构–引入
内查找:

外查找:B树系列
内外区分:内:内存如果数据量很大,比如有100G数据,无法一次放进内存中,那就只能放在磁盘上了,如果放在磁盘上,有需要搜索某些数据,那么如何处理呢?那么我们可以考虑将存放关键字及其映射的数据的地址放到一个内存中的搜索树的节点中,那么要访问数据时,先取这个地址去磁盘访问数据。
磁盘中的数据是挨着存储的,不方便搜索。使用平衡二叉树搜索树的缺陷:
平衡二叉树搜索树的高度是logN,这个查找次数在内存中是很快的。但是当数据都在磁盘中时,访问磁盘速度很慢,在数据量很大时,logN次的磁盘访问,是一个难以接受的结果。
使用哈希表的缺陷:
哈希表的效率很高是O(1),但是一些极端场景下某个位置冲突很多,导致访问次数剧增,也是难以接受的。
那如何加速对数据的访问呢?- 提高IO的速度(SSD相比传统机械硬盘快了不少,但是还是没有得到本质性的提升)
- 降低树的高度—多叉树平衡树
B树概念
平衡搜索树基础上找优化空间:
1.压缩高度,二叉变多叉
2.一个节点里面有多个关键字及映射的值1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树(后面有一个B的改进版本B+树,然后有些地方的B树写的的是B-树,注意不要误读成"B减树")。一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
- 根节点至少有两个孩子
- 每个分支节点都包含k-1个关键字和k个孩子,其中 ceil(m/2) ≤ k ≤ m ceil是向上取整函数
- 每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m
- 所有的叶子节点都在同一层
- 每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
- 每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)其中,Ki(1≤i≤n)为关键字,且Ki
- 每个节点关键字的数量比孩子少一个
插入图解
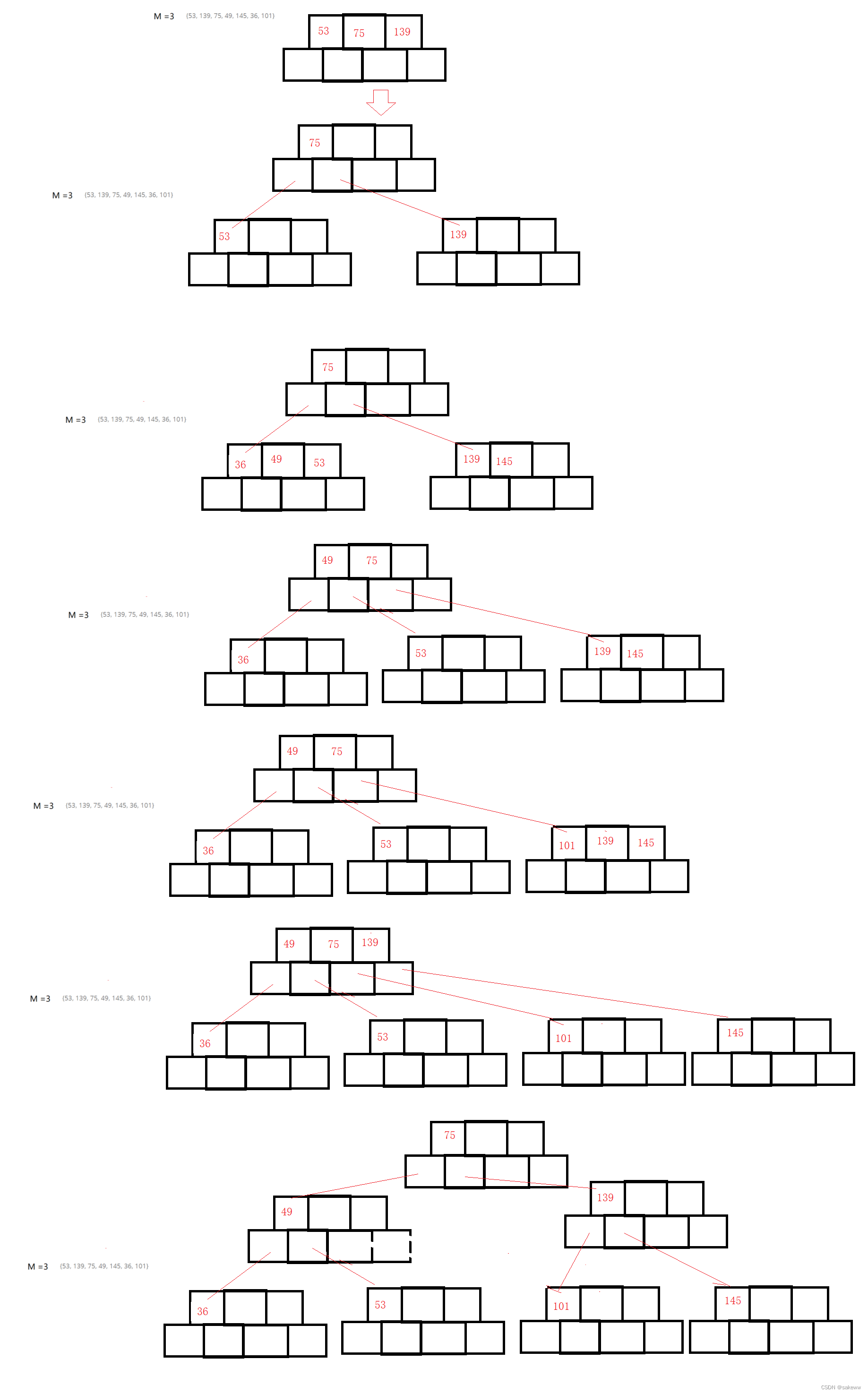
总结一些点:
1.每次插入的位置最开始一定是叶子节点,然后根据规则进行调整关于删除
节点数量小于m/2-1,则优先找父亲借,父亲找兄弟借
找父亲兄各地借不到节点了,再借他们也不满足条件了m/2-1,合并兄弟节点关于遍历
中序是因为是顺序的
顺序是:

代码实现:
#pragma once #includeusing namespace std; #include #include template<class K, size_t M> struct BTreeNode { //K _keys[M - 1]; //BTreeNode - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
B+树和B*树
B+树
B+树是B树的变形,是在B树基础上优化的多路平衡搜索树,B+树的规则跟B树基本类似,但是又在B树的基础上做了以下几点改进优化:
- 分支节点的子树指针与关键字个数相同
- 分支节点的子树指针p[i]指向关键字值大小在[k[i],k[i+1])区间之间
- 所有叶子节点增加一个链接指针链接在一起
- 所有关键字及其映射数据都在叶子节点出现
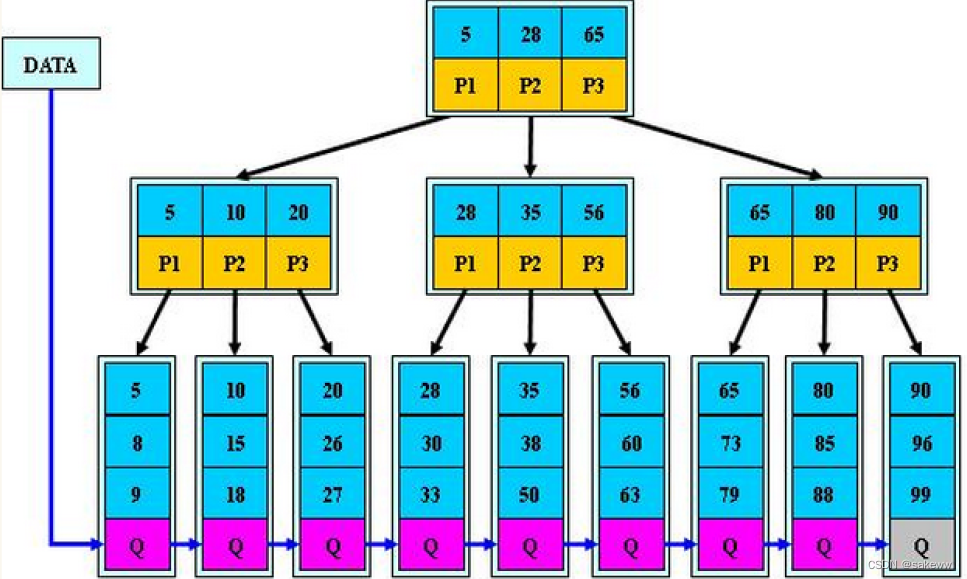
B+树的特性:
1.所有关键字都出现在叶子节点的链表中,且链表中的节点都是有序的。
2.不可能在分支节点中命中。
3.分支节点相当于是叶子节点的索引,叶子节点才是存储数据的数据层。插入

总结:
相比较于B树
简化了B树孩子比关键字多一个的规则,变成相等!
所有的值都在叶子上,方便遍历查找所有值B*树
B*树是B+树的变形,在B+树的非根和非叶子节点再增加指向兄弟节点的指针。

B+树的分裂:
当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。B*树的分裂:
当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;总结:
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
B*树:一棵更丰满的,空间利用率更高的B+树。B树系列劣势:
1.空间利用率低,消耗高
2.插入删除数据时,需要分裂和合并节点,必然要移动数据
3.虽然高低更低,但是在内存中而言,和哈希和平衡搜索树还是一个量级
即:B树系列在内存中体现不出优势内存中搜索三次和三十次差别不是很大
磁盘中凑所三次和三十次差别非常大树的应用
数据库的引擎
B+做主键索引相比B树的优势:
1.B+树所有值都在叶子节点,遍历方便,方便区间查找。
2.对于没有建立索引的字段,全表扫描的遍历很方便。
3.分支节点只存储key,一个分支节点空间占用更小,可以尽可能的加载到缓存B树不用叶子就能找到值,B+树一定要到叶子,这是B树的优势,但是B+树高度足够低所以差别不大。 -
相关阅读:
死锁的3种死法
Spring MVC 高级框架的核心
高并发系统如何保护系统?
7-155 字符转换
华为云Stack南向开放框架,帮助生态伙伴高效入云
ssm好乐买超市管理系统毕业设计-附源码111743
基于DJYOS的SPI驱动编写指导手册
高性能 低功耗Cortex-A53核心板 | i.MX8M Mini
工业智能网关BL110应用之四十七: 数据上传云平台 MQTT Client One的配置
轻量级模型NanoDet基于自己的数据集【接打电话检测】从零构建模型超详细教程
- 原文地址:https://blog.csdn.net/sakeww/article/details/126478287
