-
flink sql 使用自定义的mysql source分片读取
最近遇到个场景,需要对大表进行 Table Scan,使用官方的 jdbc connect, 发现在执行的时候,如果表的数据量很大(百万级别),在 select 阶段会消耗大量的时间,如下:
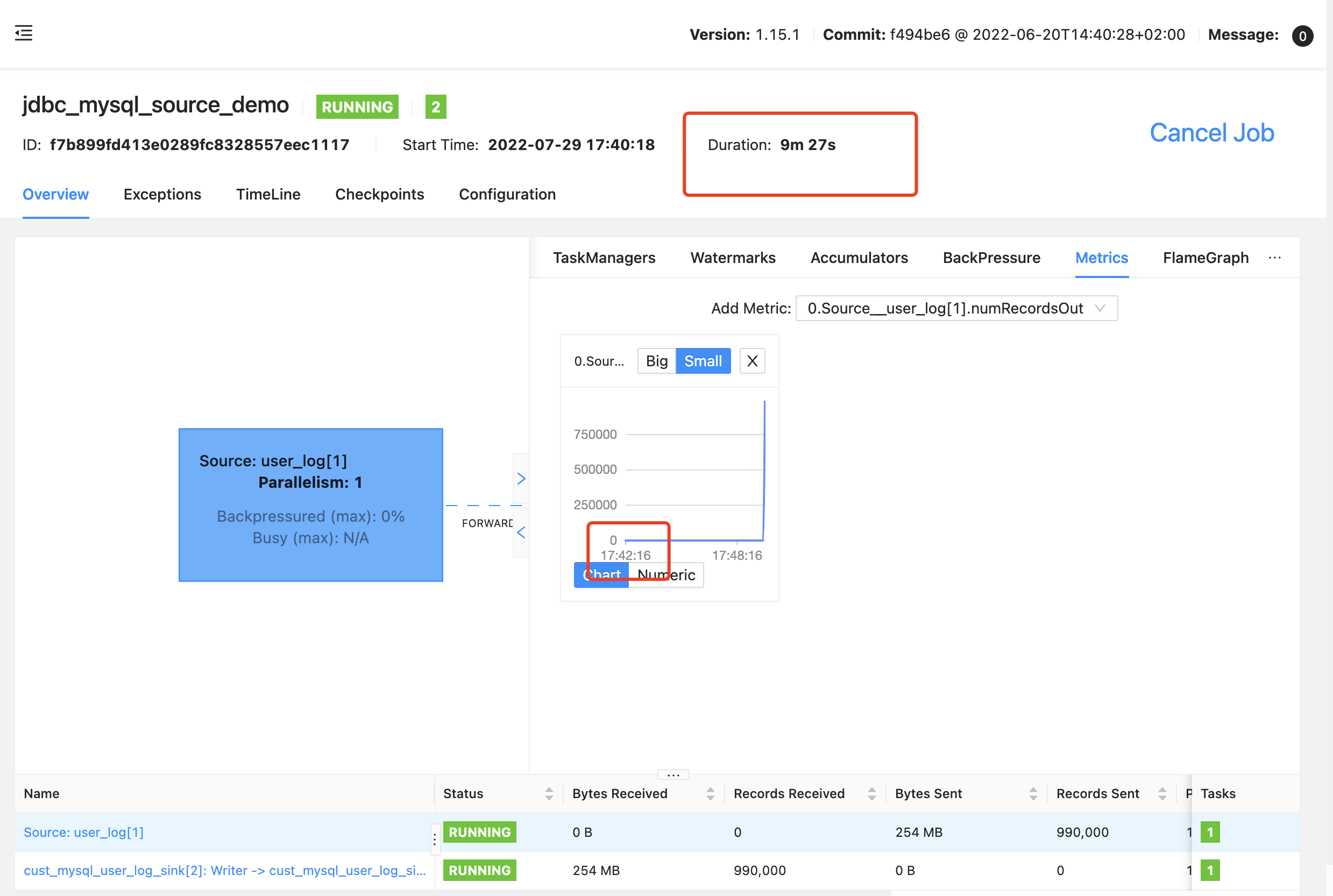
任务执行了 9 分钟多,数据才上来,数据上来后,差不多一批就全部上来了
差不多 10 分钟读完,还不能通过增加并行度的方式提高读取速度
并行 mysql source 实现
在自定义的 mysql lookup source 基础上添加 TableScan 的 Source
Source 继承 RichParallelSourceFunction
- 构造方法中接收配置参数
- open 方法中创建 jdbc 连接,基于主键查询表中的最大值,最小值
- run 方法中,基于任务的并行度,将数据按主键,均分给每个并行度
- 每个并行度分批次读取分给自己的数据
MysqlOption
并行 source,最重要的是基于键,将数据均分到每个并行度;同时在读取的时候,加入了批次概念,避免一次性读取太多数据(其实是抄的 flink cdc 的概念)
MysqlOption.javapublic static final Config -
相关阅读:
单例模式与反射创建对象
论文阅读笔记(十一)——BioInformatics Agent (BIA)
用HTML+CSS做一个漂亮简单的个人网页(第二篇)
猴子吃桃问题--c语言
Linux FrameBuffer(三)- struct fb_fix_screeninfo 和 struct fb_var_screeninfo 详解
误差卡尔曼中的四元数运动学-第二章
AIGC时代:未来已来
Linux Vi编辑器基础操作指南
c++ 之 socket udp与tcp client server实现
期末复习【微机原理】
- 原文地址:https://blog.csdn.net/Emperor_CJ/article/details/126503849