-
【CKA考试笔记】十九、master的负载均衡及高可用
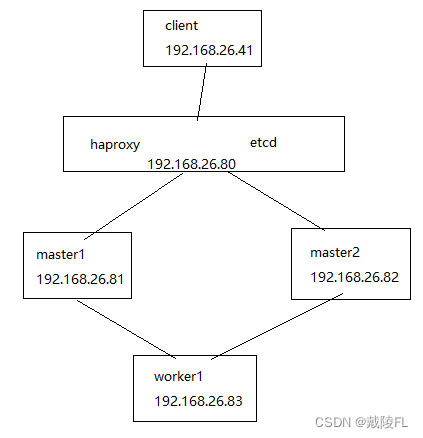
实验环境
(vms81)192.168.26.81——master1
(vms82)192.168.26.82——master2
(vms83)192.168.26.83——worker1
(vms80)192.168.26.80——haproxy + etcd
(vms41)192.168.26.41——client一、概述
在某k8s环境中,有一台master,两台worker node(worker1、worker2)
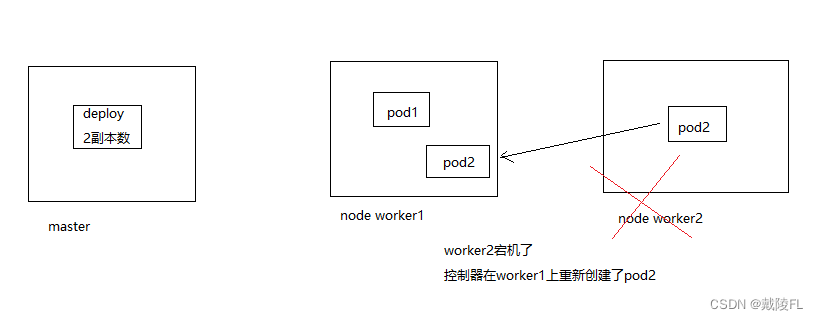
我们很少有机会去单独部署pod,一般都是使用控制器(不管是deployment还是StatefulSet)去部署pod,假设master上有一个deployment控制器,设置副本数为2个,则副本可能会在worker1上运行,也可能会在worker2上运行,假设在worker1上运行了pod1,在worker2上运行了pod2,这时候若某个pod副本出现了问题,那么deployment检测到需要的是两个副本,但是现在只有一个副本了,它便会去重新创建出一个副本,保证环境中设定的副本数,但假设现在不是某个副本出现问题,而是worker2这个node出现了问题,就会导致deployment检测不到worker2上的副本了,既然检测不到,deployment就会认为这个副本是有问题的,结果就会在其他节点上帮我们重新创建这个副本,以保证环境中的副本数,因此对于worker节点,并不需要保证它的高可用,就算它出现了问题,它上面的pod也会跑到其他节点上去运行(在其他节点重新创建pod),无非就是增加了其他worker的负载,并不影响继续对外提供服务
因此没必要对worker作高可用
但对于master来说,master上有一些核心的组件如kube-apiserver、kube-scheduler、kube-controller-manager,k8s用户都是连接到master上进行所有操作的(管理命名空间、管理pod等),所有的控制器都是由controller-manager来管理的
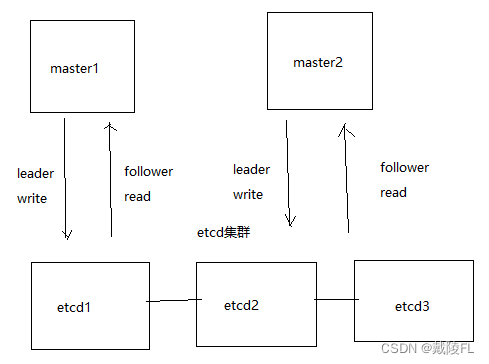
因此若master出现了问题,那么整个集群都停摆了,因此我们有必要对master作负载均衡、高可用k8s集群中,所有的配置都是保存在etcd数据库里的,在master上,etcd就是以pod、容器的方式运行的,因此我们可以考虑将etcd单独拿出来,搭建一个etcd集群,所有的etcd之间互相同步数据,便可供多个master读写数据,指定多个master都访问这个etcd集群,不用关心master访问的是哪一台具体的etcd主机,因为master会选择etcd集群中的leader进行写数据、选择
follower进行读数据因为多个master访问的是同一套etcd集群里的数据,因此多个master之间的数据是共享的,在master1上创建一个pod1,在master2上也能看见这个pod1,即使用了同一个数据库,数据共享,多个master之间的操作是同步的,当某个master出现了问题,在其他master上仍然可以继续工作
有多个master,我们应该连接到哪台master进行操作呢?
在master之上再增加一层——负载均衡层
使用haproxy负载均衡器来实现,由它来负载将请求转发给master
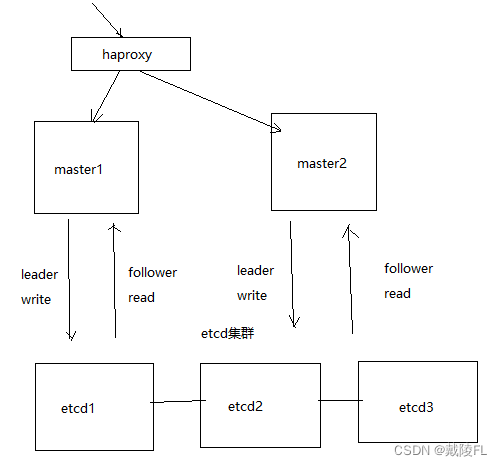
但是问题又来了,假设haproxy负载均衡器出现问题了怎么办(它也是有可能出现单点故障的)
可以再搭建一个haproxy,然后利用keepalived搭建一个高可用集群,会生成一个vip,用户连接的时候就连接到这个vip
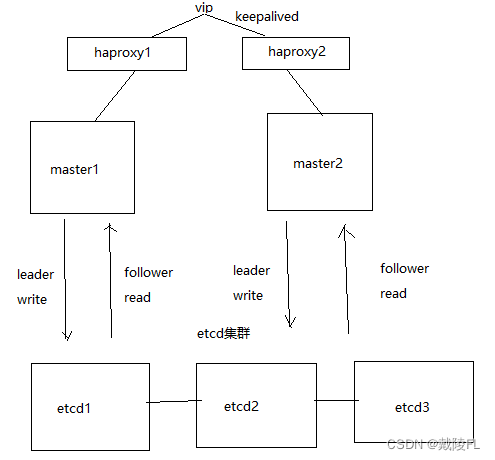
当haproxy1处于活跃时,vip就附着在haproxy1上运行,haproxy1出现了问题,vip就附着在haproxy2上运行这里我们关注master的高可用,因此搭建多个master并结合haproxy这样一个架构,暂且不讨论keepalived
二、实验
根据以上构架图,我们需要两台master、及每个master下至少一个worker节点、三台etcd组成的etcd集群,因此总共需要7台机器,为了节约机器,部署简化为如下:
(vms81)192.168.26.81——master1
(vms82)192.168.26.82——master2
(vms83)192.168.26.83——worker1
(vms80)192.168.26.80——haproxy + etcd
(vms41)192.168.26.41——client
一:vms80上安装和配置haproxy
1.vms80上安装haproxy
yum install haproxy -y- 1
2.修改haproxy的配置文件
配置负载均衡指定的master的服务器地址,weight代表权重
listen后的k8s-lb为名字,可随便取
listen k8s-lb *:6443就意为当接收到来自6443的请求后,会将请求分发到192.168.26.81:6443、192.168.26.82:6443
负载均衡所使用的算法即roundrobin(轮询)vim /etc/haproxy/haproxy.cfg #在最后面插入以下几行: listen k8s-lb *:6443 mode tcp balance roundrobin server s1 192.168.26.81:6443 weight 1 server s2 192.168.26.82:6443 weight 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.启动haproxy
systemctl enable haproxy --now- 1
检测是否启动
systemctl is-active haproxy #输出: active- 1
- 2
- 3
二:vms80上安装和配置etcd
1.vms80上安装etcd
yum install etcd -y- 1
2.编辑etcd配置文件
vim /etc/etcd/etcd.conf- 1
修改以下值为:
ETCD_DATA_DIR="/var/lib/etcd/cluster.etcd" ETCD_LISTEN_PEER_URLS="http://192.168.26.80:2380,http://localhost:2380" ETCD_LISTEN_CLIENT_URLS="http://192.168.26.80:2379,http://localhost:2379" ETCD_NAME="etcd-80" ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.26.80:2380" ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379,http://192.168.26.80:2379" ETCD_INITIAL_CLUSTER="etcd-80=http://192.168.26.80:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.启动etcd
systemctl enable etcd --now- 1
检查是否启动
systemctl is-active etcd #输出: active- 1
- 2
- 3
三:vms81、82、83上搭建k8s集群环境
1.参考二、kubernetes介绍及部署——安装K8S集群环境下的前置准备、安装k8s两章内容
2.做完以上步骤后,接下来要开始在master上进行初始化集群
在《二、kubernetes介绍及部署》中我们直接通过kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.24.2 --pod-network-cidr=10.244.0.0/16来初始化集群
但是这里我们部署的是多个master的集群,我们需要对多个master都配置指向一个外部的etcd的地址(默认的k8s环境中是把etcd集成在环境里,而现在需要改成连接外部的etcd)(1)这时,我们需要一个配置文件,这个配置文件可以从已完成初始化集群的环境中导出
kubectl get cm kubeadm-config -n kube-system -o yaml > k8s-config.yaml- 1
导出的k8s-config.yaml文件中只需要data.ClusterConfiguration下的内容,其他删去
最终得到的k8s-config.yaml文件内容如下:apiServer: extraArgs: authorization-mode: Node,RBAC timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: v1.24.2 networking: dnsDomain: cluster.local podSubnet: 10.244.0.0/16 serviceSubnet: 10.96.0.0/12 scheduler: {}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(2)修改k8s-config.yaml文件以下内容:
a.加上controlPlaneEndpoint的配置,值为haproxy的地址:192.168.26.80:6443
b.因为默认的k8s中,是把etcd集成到k8s环境中去了,因此可以看到etcd下以local来配置,我们需要改成使用external来配置,连接外部的etcd:etcd.external.endpoints=“http://192.168.26.80:2379”(etcd集群中有几台etcd机器,在endpoints下就写几个etcd地址)
得到:apiServer: extraArgs: authorization-mode: Node,RBAC timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki controlPlaneEndpoint: 192.168.26.80:6443 clusterName: kubernetes controllerManager: {} dns: {} etcd: external: endpoints: - "http://192.168.26.80:2379" imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: v1.24.2 networking: dnsDomain: cluster.local podSubnet: 10.244.0.0/16 serviceSubnet: 10.96.0.0/12 scheduler: {}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
(3)master1上使用k8s-config.yaml文件来初始化集群环境,master2上不要初始化
kubeadm init --config k8s-config.yaml- 1
根据提示创建kubeconfig文件
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config- 1
- 2
- 3
在提示中,有两个加入集群的命令,末尾带–control-plane指的是master加入集群的命令,而worker加入集群的命令除了末尾没有–control-plane,其他都一样
... kubeadm join 192.168.26.80:6443 --token 20ms66.0zyrz7t991o8gc0y \ --discovery-token-ca-cert-hash sha256:25bfbd15485b9ccb10a467e65799c83f29a2b25009ac24f207fdd29b859b6d25 \ --control-plane ... kubeadm join 192.168.26.80:6443 --token 20ms66.0zyrz7t991o8gc0y \ --discovery-token-ca-cert-hash sha256:25bfbd15485b9ccb10a467e65799c83f29a2b25009ac24f207fdd29b859b6d25 #若忘记了这个命令,可以用下面这个指令重新获取: kubeadm token create --print-join-command- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(4)将master2加入集群master1
将master1上的 “kubeadm join…–control-plane” 命令复制到master2上执行,但此时加入集群会报错
因为这里涉及到了一系列证书的问题
证书位置在/etc/kubernetes/pki/下
master1上此时有一系列证书,而master2上此时是没有证书的#master1上 ls /etc/kubernetes/pki/ #输出: apiserver.crt apiserver-kubelet-client.crt ca.crt front-proxy-ca.crt front-proxy-client.crt sa.key apiserver.key apiserver-kubelet-client.key ca.key front-proxy-ca.key front-proxy-client.key sa.pub #master2上 ls /etc/kubernetes/ #输出: manifests- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
因此,首先在master1上创建一个菜单文件cert.txt
cat > cert.txt <<EOF /etc/kubernetes/pki/ca.crt /etc/kubernetes/pki/ca.key /etc/kubernetes/pki/sa.key /etc/kubernetes/pki/sa.pub /etc/kubernetes/pki/front-proxy-ca.crt /etc/kubernetes/pki/front-proxy-ca.key EOF- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
cert.txt菜单文件里包含的这些文件就是我们要从master1上拷贝到master2上的文件
根据cert.txt文件菜单,将所需要的证书文件打包tar czf cert.tar.gz -T cert.txt- 1
将cert.tar.gz拷贝到master2上
scp cert.tar.gz 192.168.26.82:~- 1
在master2上将cert.tar.gz解压到根下(解压到根下,就会将包里的文件自动移动到相应路径中去)
tar zxf cert.tar.gz -C /- 1
此时master2上就有这些证书文件了
ls /etc/kubernetes/pki/ #输出: ca.crt ca.key front-proxy-ca.crt front-proxy-ca.key sa.key sa.pub- 1
- 2
- 3
此时就可以在master2上使用master1上的 “kubeadm join…–control-plane” 命令,将master2加入master1的集群了
加入后会有以下提示:This node has joined the cluster and a new control plane instance was created: * Certificate signing request was sent to apiserver and approval was received. * The Kubelet was informed of the new secure connection details. * Control plane label and taint were applied to the new node. * The Kubernetes control plane instances scaled up. To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
根据提示,我们也需要给master2创建kubeconfig文件
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config- 1
- 2
- 3
(5)将worker1加入集群master1
(6)master2、worker1都加入master1后,在master1上查看nodes,可以看到master2的ROLES也是control-planeNAME STATUS ROLES AGE VERSION vms81.rhce.cc NotReady control-plane 172m v1.24.2 vms82.rhce.cc NotReady control-plane 171m v1.24.2 vms83.rhce.cc NotReady <none> 11m v1.24.2- 1
- 2
- 3
- 4
(7)此时节点的状态都为NotReady,还需要安装calico网络
参考二、kubernetes介绍及部署——安装calico网络环境章节内容
(k8s-config.yaml中给pod设置的网段podSubnet为: 10.244.0.0/16)
(所有节点上下载calico所需镜像,在master1上安装calico网络)
安装好后,所有节点变为Ready四、测试master1与master2是否同步
测试master1上做一些操作,master2上是否会同步
master1上创建命名空间ns1kubectl create ns ns1- 1
master2上查看命名空间,也可以看到ns1
NAME STATUS AGE default Active 3h19m kube-node-lease Active 3h19m kube-public Active 3h19m kube-system Active 3h19m ns1 Active 11s- 1
- 2
- 3
- 4
- 5
- 6
五、client客户端连接k8s
master1上获取集群信息
kubectl cluster-info #输出: Kubernetes control plane is running at https://192.168.26.80:6443 CoreDNS is running at https://192.168.26.80:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.- 1
- 2
- 3
- 4
- 5
- 6
- 7
client客户端连接时指定haproxy地址便可:https://192.168.26.80:6443
-
相关阅读:
pair 是 C++ 标准库中的一个模板类,用于存储两个对象的组合
Linux服务器启动tomcat的三种方式
Nacos注册中心和服务方式
Docker容器命令
Hugging News #0414: Attention 在多模态情景中的应用、Unity API 以及 Gradio 主题构建器
PCIe系列专题之二:2.7 Flow Control的实现过程
flutter 使用texture实现Windows渲染视频
react事件系统(新版本)
自制操作系统日记(8):变量显示
天视通等小众冷门摄像机接入安防监控系统EasyCVR平台的常见兼容问题及解决方法
- 原文地址:https://blog.csdn.net/weixin_41755556/article/details/126487355
