1、背景
由于Oracle对外宣称Oracle JDK停止免费用于商用。公司法务部门评估之后担心后续会惹上光司,于是就开始了JDK升级-将所有服务Oracle修改为OpenJDK。上周开始微服务JDK升级原本只不过是一个基础组件的升级,由于没有涉及业务代码的变更觉得问题不大。但怎么也想不到开始升级之后便陆陆续续出现服务不断重启的异常想象。这到底是咋了?
2、问题暴露
升级镜像之后,java服务频繁重启,服务对外的接口处于半不可用状态,具体表现为接口请求失败率5-10%(该接口对应数据看板主要是内部人员使用,之所以没有第一时间进行止损)

3、异常排查
本次升级除了更新基础JDK镜像,既没有业务代码的变更也没有修改配置,到底是什么原因导致的呢?
带着十分困惑的心情,我和团队开启了漫长的异常排查之旅。
1) 当时出现服务重启,第一感觉是启动耗时长导致探测接口超时超过一定阈值导致重启。
于是在发生异常重启的第1个小时内,我把探测超时由30s调大为60s,发现没有效果,于是又调大到90s, 可惜还是不奏效,服务还是出现一直重启的想象。
2)接下来是怀疑pod所在的宿主机会不会是内存不足导致的呢?于是登陆宿主机查看内存
$ free -m

总内存128g, 可用内存有60g以上,宿主机的物理内存是足够的。
3)主机内存也是正常的,不知道JVM的监控是否有明显的异常提示呢?
到这个时候,距离升级已经过去2小时了。于是打开业务jvm的heap和gc次数监控看板,发现full gc还是比较规律的,没有明细的异常信息。

此时距离升级已经过去将近3小时了。实在找不到任何头绪了,难道只能回滚了吗?
4)最后的最后,我们想到检查系统级别日志看看是否有异常提示,结果终于发现OOM的错误日志。
1 | dmesg -T |
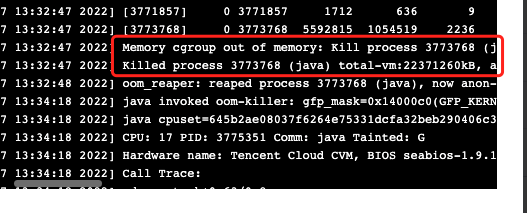
结论:
到这里问题已经比较明显了,pod内部的Java服务异常申请内存超过内存上限(该pod配置的的内存limit值是4g)触发了系统的killer保护进程将pod进程kill掉。
4、根因定位
虽然定位到是OOM原因导致的,但是为什么升级了JDK就导致OOM呢?
经过jinfo命令查看JVM启动参数终于发现根本原因。原来服务反复OOM被kill掉是因为“-XX:MaxHeapSize”参数失效导致Java进程使用默认值32g(物理机的1/4)超出了pod分配的limit上限8g。那为什么“-XX:MaxHeapSize”参数失效呢?那是因为新镜像给JAVA_OPS进行默认赋值,覆盖了之前启动参数JAVA_OPS的值。想要解决这个问题,需要取消OpenJDK镜像对于JAVA_OPS的默认赋值。
1 | jinfo -flags 1 |


再次确认MaxHeapSize的默认值,通过执行以下命令可以看到MaxHeapSize默认值确实是系统总内存的1/4。
1 | java -XX:+PrintFlagsFinal -version | grep MaxHeapSize |
5、总结复盘
结合本次发布引起的异常做一次复盘,主要包含问题发生和修复完成的时间点以及故障原因分析与优化措施。见如下表格:
