-
protobuf序列化和反序列化原理
实现原理
序列化是如何实现的?
message sku_feature {int64 sku_id =1;int32 cid1 =2;floatprice =3;int32 cid2 =4;int32 cid3 =5;}Tag - Length - Value(标识 - 长度 - 字段值)编码存储方式-
以 标识 - 长度 - 字段值 表示每个字段,所有字段拼接成一个 字节流,从而 实现 编码存储 的功能
- 示意图

tag
uint32 : field_number << 3 | wire type
例如:int64 sku_id = 1;
tag生成:1 << 3 | 0 = 8

length
可选字段:目前只有类型2需要,例如字符串,length会存储字符串长度。
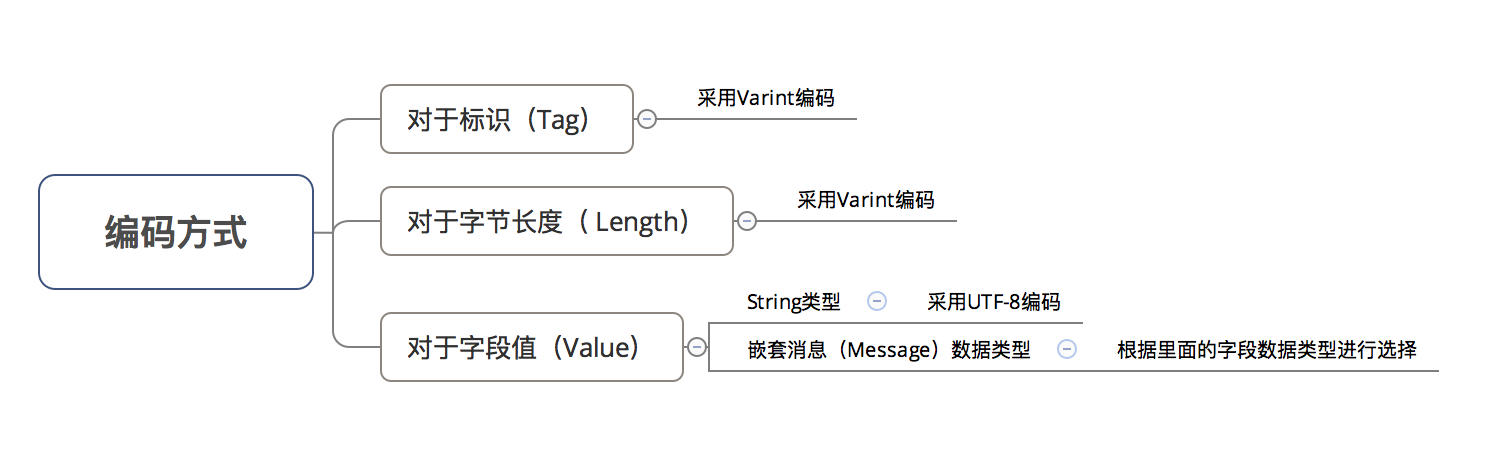
value
不同类型的value值会有不同的编码方式。下面对每种类型进行逐一讲解。
1 Wire Type = 0时的数据编码方式
采用了两种编码方式:
Varint&Zigzag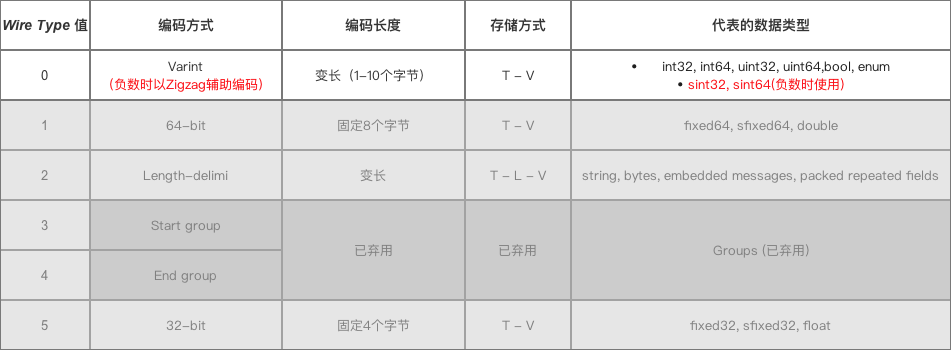
1.1
Varint编码方式介绍- 定义:一种变长的编码方式
- 原理:将数据按7个bit为一组进行分组, 每分组前加1bit标示是否有下一组数据
这样就可以用更少的字节表示数字,达到压缩的目的。
- 采用
Varint编码,对于很小的int32类型 数字,则可以用 1个字节来表示 - 虽然大的数字会需要 5 个 字节 来表示,但大多数情况下,消息都不会有很大的数字,所以采用
Varint方法总是可以用更少的字节数来表示数字
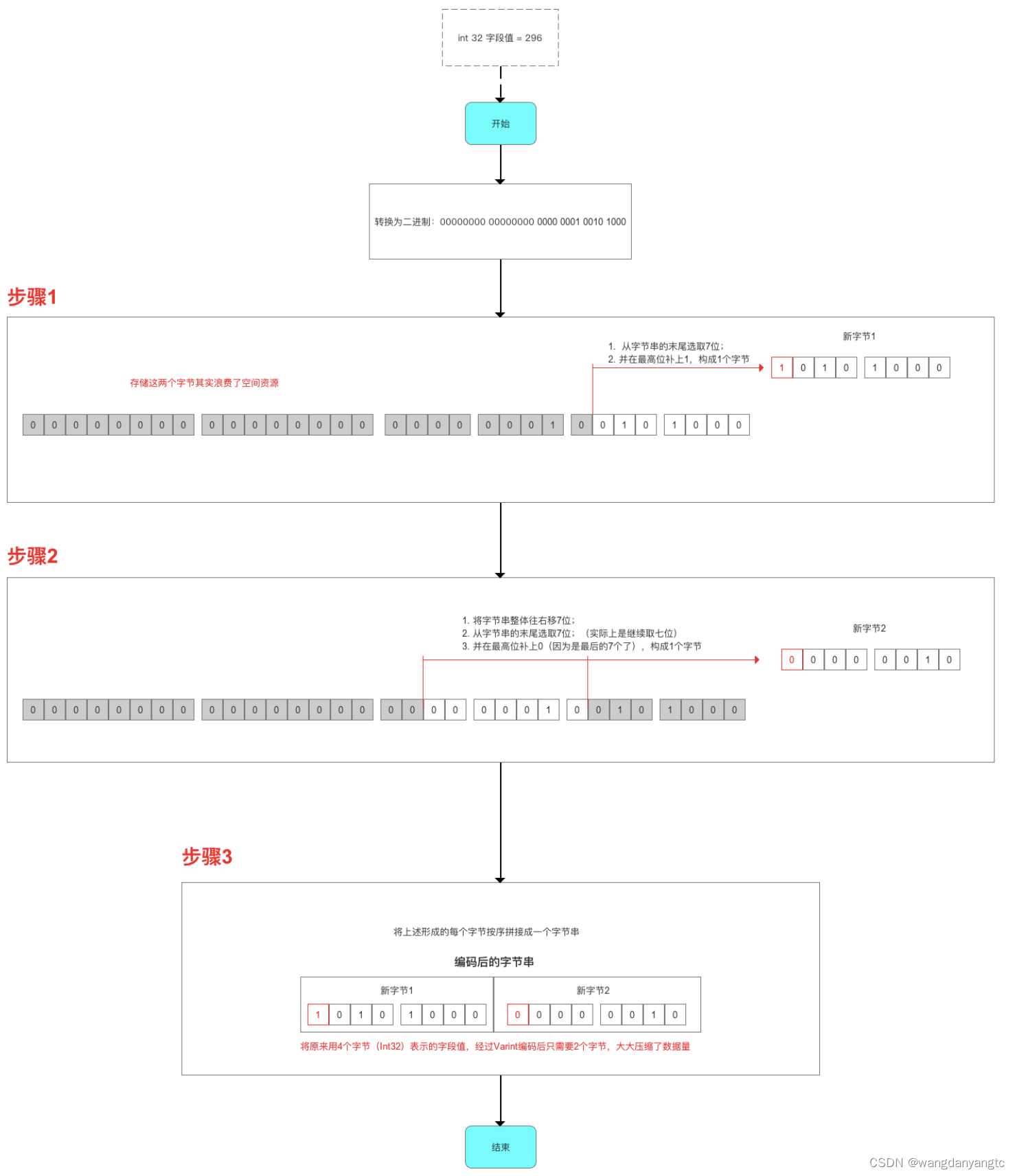
如何解析经过
Varint编码的字节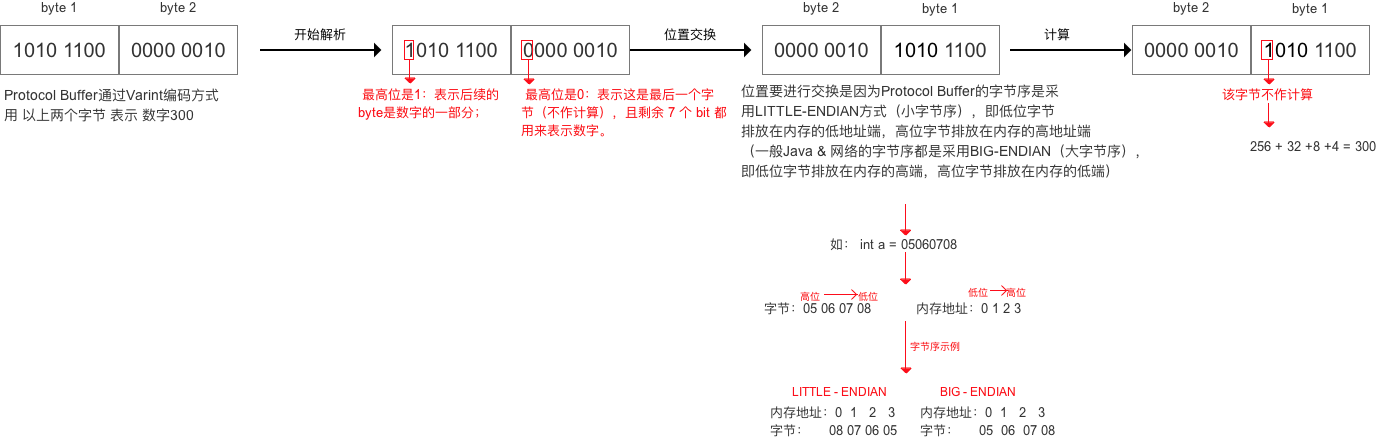
编码inline uint8* CodedOutputStream::WriteVarint64ToArray(uint64 value,uint8* target) {while(value >=0x80) {*target = static_cast(value | 0x80);value >>=7;++target;}*target = static_cast(value); returntarget +1;}解码bool CodedInputStream::ReadVarint64Slow(uint64* value) {// Slow path: This read might cross the end of the buffer, so we// need to check and refresh the buffer if and when it does.uint64 result =0;intcount =0;uint32 b;do{if(count == kMaxVarintBytes) {*value =0;returnfalse;}while(buffer_ == buffer_end_) {if(!Refresh()) {*value =0;returnfalse;}}b = *buffer_;result |= static_cast(b & 0x7F) << (7* count);Advance(1);++count;}while(b &0x80);*value = result;returntrue;}Varint编码方式的不足- 问题:如果采用
Varint编码方式 表示一个负数,那么一定需要 5 个 byte。
因为最高位bit是1,例如int32类型 -1: 100000000 00000000 00000000 00000001 ,使用varint编码 ceil(4*8/7) = 5
- 解决方案:
protobuf会先采用Zigzag编码,再采用Varint编码
1.2 Zigzag编码方式详解- 定义:一种变长的编码方式
- 原理:使用 无符号数 来表示 有符号数字;
- 作用:使得绝对值小的数字都可以采用较少 字节 来表示;
- 实例说明:将
-2进行Zigzag编码:
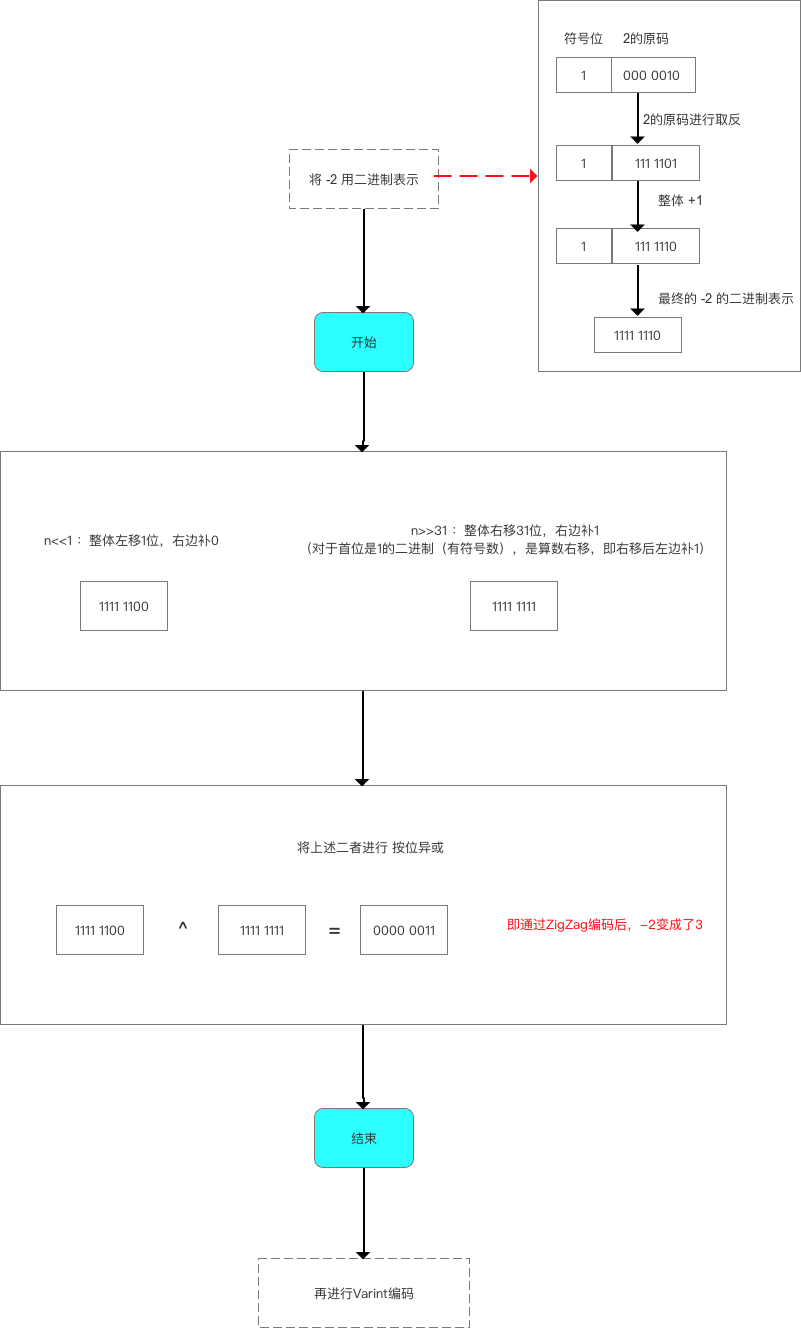
Zigzag编码 是补充Varint编码在 表示负数 的不足,从而更好的帮助Protocol Buffer进行数据的压缩- 所以,如果提前预知字段值是可能取负数的时候,记得采用
sint32 / sint64数据类型
inline uint32 WireFormatLite::ZigZagEncode32(int32 n) {// Note: the right-shift must be arithmetic// Note: left shift must be unsigned because of overflowreturn(static_cast(n) << 1) ^ static_cast(n >> 31);}inline int32 WireFormatLite::ZigZagDecode32(uint32 n) {// Note: Using unsigned types prevent undefined behaviorreturnstatic_cast((n >> 1) ^ (~(n &1) +1));}总结 :
Protocol Buffer通过Varint和Zigzag编码后大大减少了字段值占用字节数。
2 Wire Type = 1& 5时的编码&数据存储方式
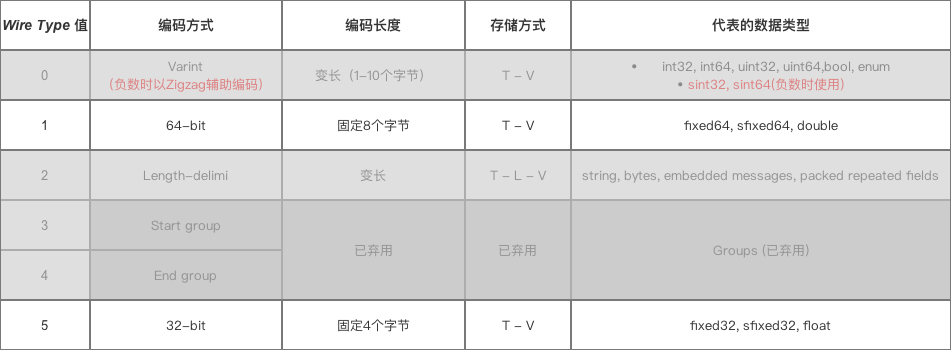
固定用4/8个字节表示inline uint64 WireFormatLite::EncodeDouble(doublevalue) {union {doublef; uint64 i;};f = value;returni;}inlinedoubleWireFormatLite::DecodeDouble(uint64 value) {union {doublef; uint64 i;};i = value;returnf;}3 Wire Type = 2时的 编码 & 数据存储方式
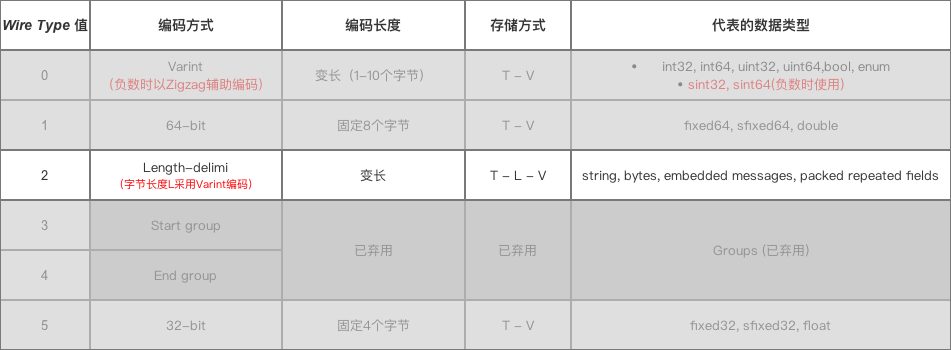
讲解三种数据类型:
String类型- 嵌套消息类型(
Message) - 通过
packed修饰的repeat字段(即packed repeated fields)
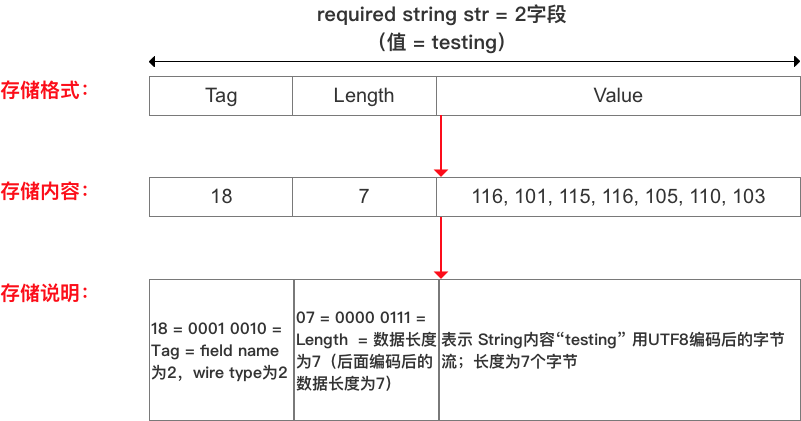
3.1 String类型
字段值(即
V) 采用UTF-8编码
- 例子:
- message Test2
- {
- required string str = 2;
- }
- // 将str设置为:testing
- Test2.setStr(“testing”)
- // 经过protobuf编码序列化后的数据以二进制的方式输出
- // 输出为:18, 7, 116, 101, 115, 116, 105, 110, 103
3.2 嵌套消息类型(Message)
- 存储方式:
T - L - V
内部消息编码的T - L -V组成外部消息的v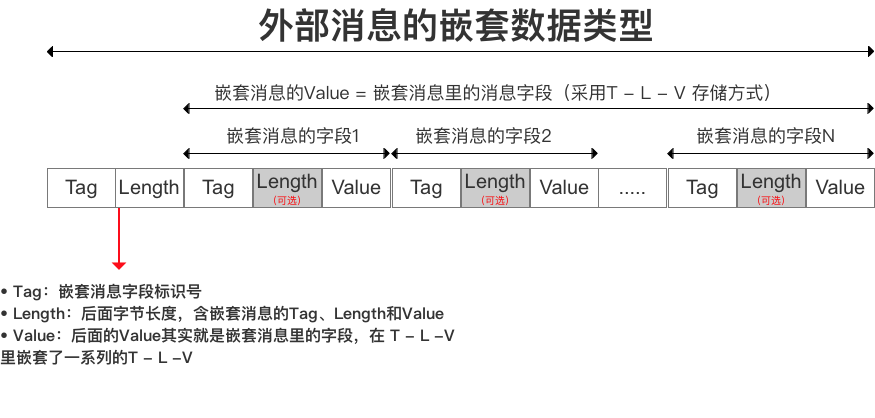
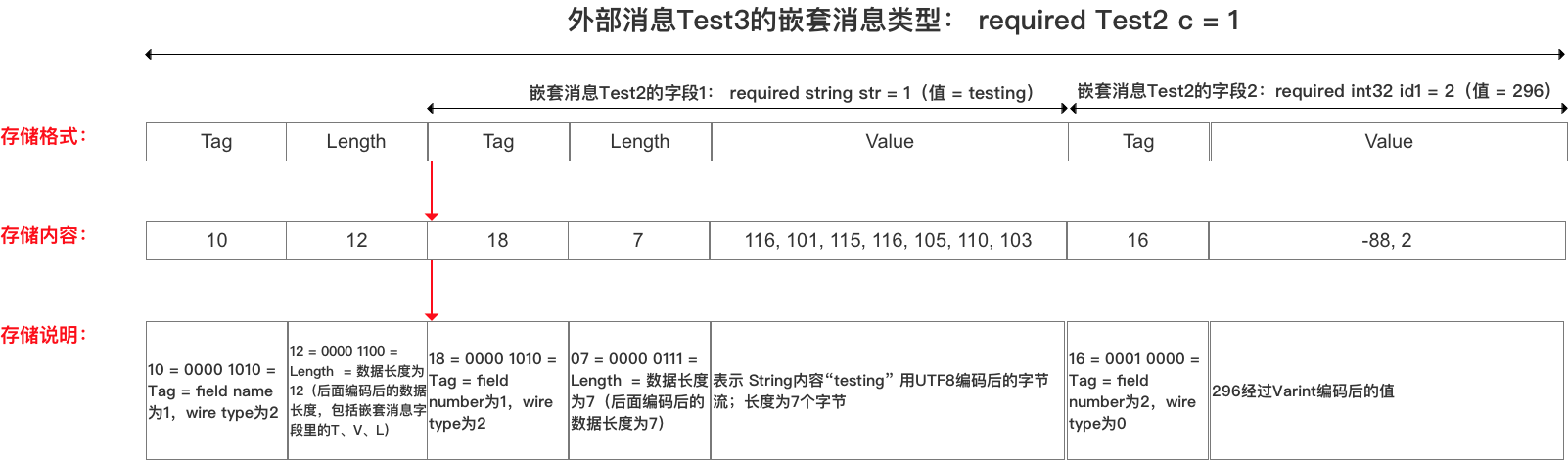
- 实例
定义如下嵌套消息:
- message Test2
- {
- required string str = 1;
- required int32 id1 = 2;
- }
- message Test3 {
- required Test2 c = 1;
- }
- // 将Test2中的字段str设置为:testing
- // 将Test2中的字段id1设置为:296
- // 编码后的字节为:10 ,12 ,18,7,116, 101, 115, 116, 105, 110, 103,16,-88,2
3.3 通过
packed修饰的repeat字段repeated修饰的字段有两种表达方式:- message Test
- {
- repeated int32 Car = 4 ;
- // 表达方式1:不带packed=true
- repeated int32 Car = 4 [packed=true];
- // 表达方式2:带packed=true
- // proto 2.1 开始可使用
- }
- // 在代码中给`repeated int32 Car`附上3个字段值:3、270、86942
- Test.setCar(3);
- Test.setCar(270);
- Test.setCar(86942);
- 背景:,即数据类型 & 标识号都相同

- 问题:对于同一个
repeated字段、多个字段值来说,他们的Tag都是相同的,会导致Tag的冗余,即相同的Tag存储多次;
- 解决方案:采用带
packed=true的repeated字段存储方式,即将相同的Tag只存储一次、记一个长度Length字段 :Tag - Length - Value -Value -Value。

通过采用带
packed=true的repeated字段存储方式,从而更好地压缩序列化后的数据长度。特别注意
packed修饰只用于基本类型的repeated字段- 用在其他字段,编译
.proto文件时会报错
总结
- protobuf编码/解码 方式简单,只需要简单的数学运算、位移等,序列化 & 反序列化速度很快
- protobuf采用了独特的编码方式,如
Varint、Zigzag编码方式等等,采用T - L - V的数据存储方式,数据存储得紧凑,数据压缩效果好
使用建议
根据上面的序列化原理分析,有以下使用建议:
-
建议1:字段标识号(
Field_Number)尽量只使用 1-15,且不要跳动使用
因为Tag里的Field_Number是需要占字节空间的。如果Field_Number>16时,Field_Number的编码就会占用2个字节,那么Tag在编码时也就会占用更多的字节;如果将字段标识号定义为连续递增的数值,将获得更好的编码和解码性能 -
建议2:若需要使用的字段值出现负数,请使用
sint32 / sint64,不要使用int32 / int64
因为采用sint32 / sint64数据类型表示负数时,会先采用Zigzag编码再采用Varint编码,从而更加有效压缩数据 -
建议3:对于
repeated字段,尽量增加packed=true修饰
因为加了packed=true修饰repeated字段采用连续数据存储方式,即T - L - V - V -V方式
动态序列化
dbproxy类型请求
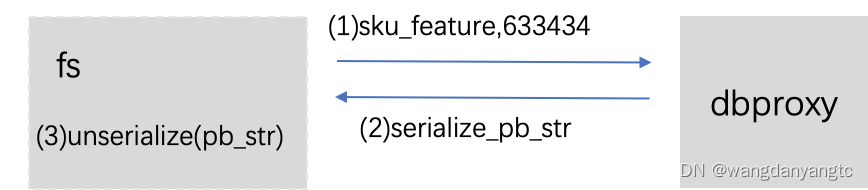
- fs使用表名,sku_id访问dbproxy
- dbproxy返回序列化的pb_str
- fs反序列化得到pb,根据pb获取相应字段(sku_feature.par)
message sku_feature {int64 sku_id =1;int32 cid1 =2;floatprice =3;int32 cid2 =4;int32 cid3 =5;}缺点:
-
- 只能支持pb级别的请求粒度,例如:只需要cid1字段,返回的是这个序列化的pb
- pb中增加一个字段,fs也需要代码层面修改pb文件,然后上线,比较繁琐。
能否支持字段粒度的请求级别?
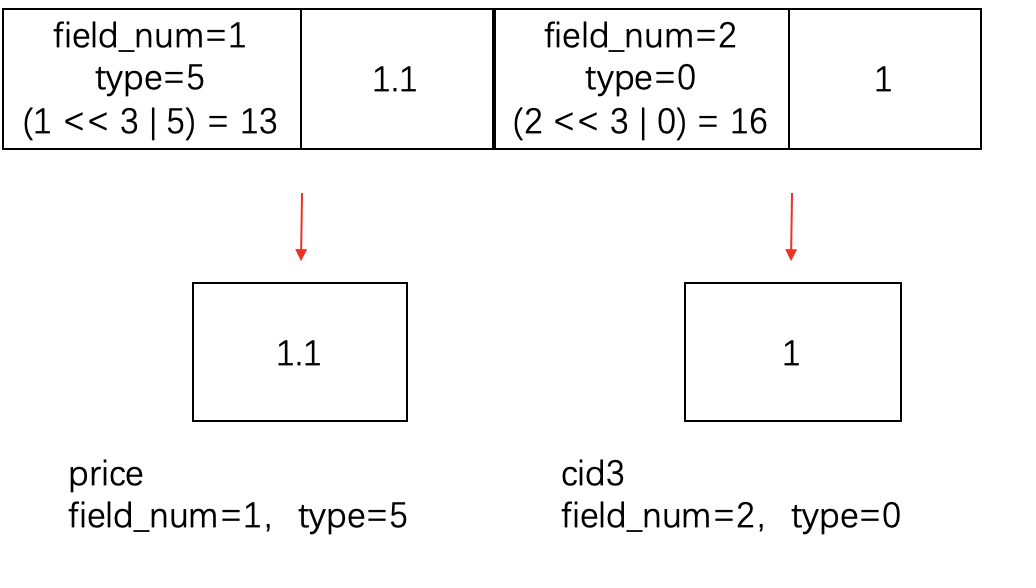
feature storage类型请求

例如storage中 price=1.1, cid3=1
feature storage端:

fs端:
效果:
-
- 支持字段级别的请求粒度,例如:只需要cid1字段,返回的序列化字符串中只包含cid1的内容
- feature storage中增加一个字段,fs无需上线。
目前进展:
feature stoage端已经完全支持
fs的ufa插件还是通过pb来反序列化,现在正在去除pb逻辑,实现根据字段动态反序列化。
-
-
相关阅读:
【洛谷题解/SDOI2008】P2158 仪仗队
unity tolua热更新框架教程(2)
Spring Boot 集成 EasyExcel 3.x 优雅实现Excel导入导出
TorchScript 解读(三):jit 中的 subgraph rewriter
SpringBoot的初步认识
淘宝详情API接口
基于JAVA食用菌菌棒溯源系统的开发与设计计算机毕业设计源码+系统+mysql数据库+lw文档+部署
清单的用法、配置文件的配置、临时命令的用法
centos6.5 搭建FTP服务器
Jenkins CLI二次开发工具类
- 原文地址:https://blog.csdn.net/wangdanyangtc/article/details/126480389
