-
hadoop集群,namenode启动,所有的datanode无法启动
Hadoop集群安装后观察datanode。
现象:
hadoop集群启动,namenode正常启动,datanode却没有启动
原因:
namenode的CLUSTERID和datanode的CLUSTERID不一致,导致namenode启动而datanode未启动
解决办法:
复制namenode的CLUSTERID 贴到datanode的CLUSTERID确认:
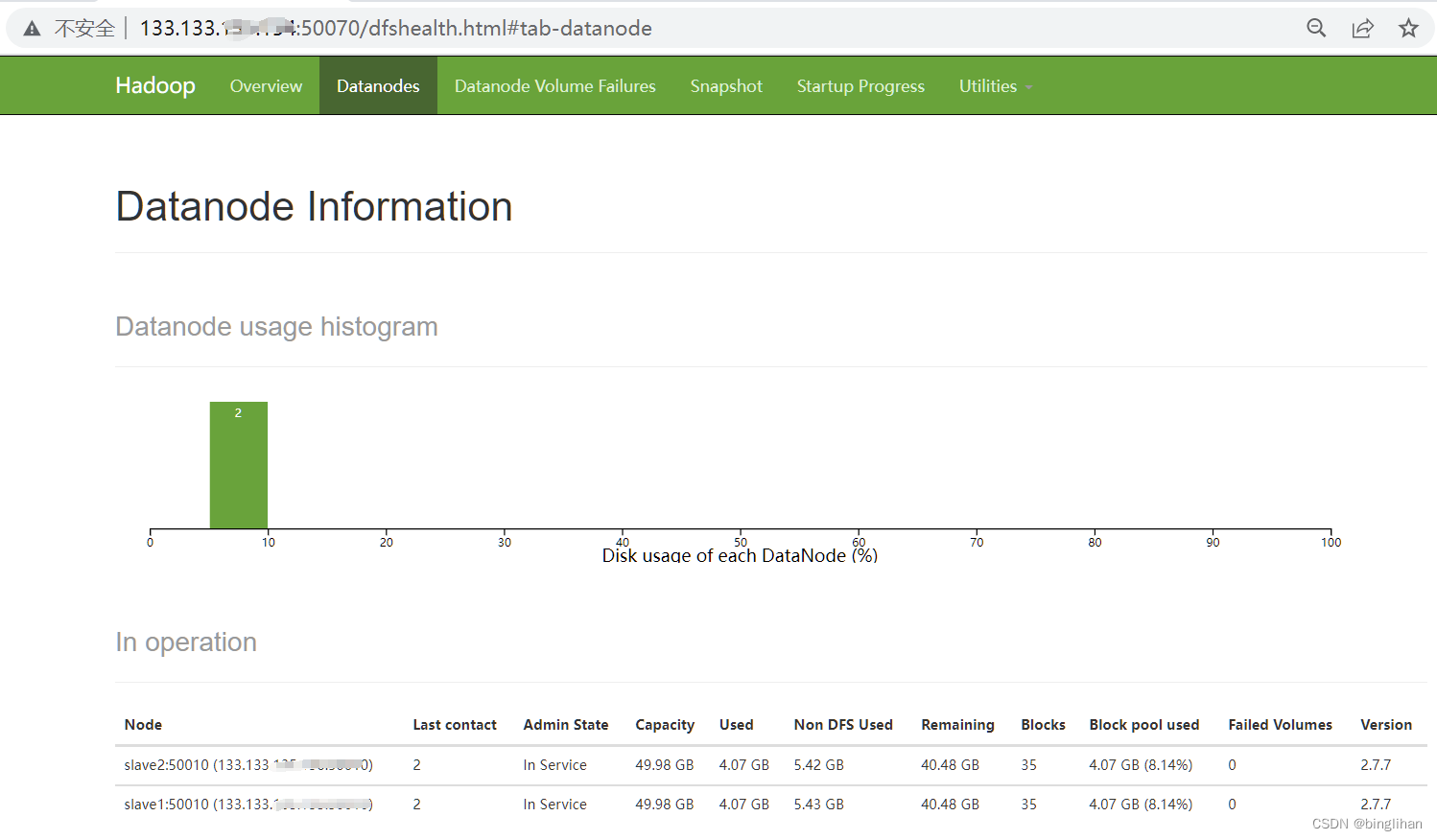
我们可以看到两个datanode中的slave1和slave2已经启动。
解决步骤:
查看hadoop的安装路径,这里以hadoop-2.7.2为例。#Hadoop安装路径 hadoop-2.7.2- 1
- 2
1. 查看slaves节点
进入到hadoop安装路径#vim etc/haoop/slaves 133.133.10.1 133.133.10.2- 1
- 2
- 3
2. 集群namenode格式化
集群首次使用时,需要格式化。bin/hdfs namenode -format- 1
3. 查看namenode和datanode的CLUSTERID
- 查找namenode和datanode的路径,namenode路径为/dataDisk/hadoop/hadoopdata/namemode
cat /etc/hadoop/hdfs-site.xml- 1

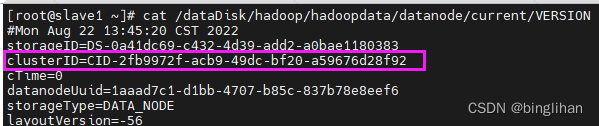
2) 查看namenode的CLUSTERID,替换datanode的CLUSTERID

登陆各个slaves,将该clusterID替换datanode上的clusterID
3)重启hdfssbin/start-all.sh- 1
注:通过http://localhost:50700查看hadoop集群状况,如果发现进程都能够启动,web页面HDFS 50070无法访问。解决办法如下:
vim etc/hadoop/core-site.xml- 1
将core-site.xml中的访问路径fs.default.name改成ip
<property> <name>fs.default.name</name> <value>hdfs://[主机名ip].Hadoop:9000</value> </property>- 1
- 2
- 3
- 4
-
相关阅读:
Python实现 Leecodet
设计模式-迭代器模式
YOLOv9改进策略 | 添加注意力篇 | LSKAttention大核注意力机制助力极限涨点 (附多个位置添加教程)
卫语句-前端应用
台湾IB国际学校介绍
【SCAU数据挖掘】数据挖掘期末总复习题库简答题及解析——上
modbusTCP【C#,socket】
面试突击61:说一下MySQL事务隔离级别?
石墨烯-壳聚糖-1-乙基-3-甲基咪唑四氟硼酸盐([BMIM])复合材料(Graphene-Chits-[BMIM])
MogDB如何兼容Oracle的管道函数
- 原文地址:https://blog.csdn.net/binglihan/article/details/126477052