-
知识图谱从入门到应用——知识图谱的知识表示:向量表示方法
分类目录:《知识图谱从入门到应用》总目录
相关文章:
· 知识图谱的知识表示:基础知识
· 知识图谱的知识表示:符号表示方法
· 知识图谱的知识表示:向量表示方法
前文已经介绍过,向量化的表示已经在人工智能的其他领域非常常见,例如在自然语言处理中,可以为句子中的每个词学习一个向量表示(Word Embedding),在图像视频中也可以为每个视觉对象学习一个向量表示。对于知识图谱,也可以为其中的每一个实体和关系学习一个向量表示,并利用向量、矩阵或张量之间的计算,实现高效的推理计算。
词向量
在传统的词向量表示中,比如One-hot Encoding,每个词向量的大小是整个词典的大小。在这个向量中,除了与该词对应的位置为1外,其他位置均为0,如下图所示。这种方法的一个显然的缺点是空间消耗比较大。扩展出去,给定一个文档,可以用这个文档中出现的所有词的个数来组成这个文档的向量表示,这种向量的大小也是整个词典的大小。这种表示方法的另外一个缺点是实际上无法有效地表示词的语义。

这里有一个值得思考的问题,就是词的语义到底是由什么决定的。事实上,一个词的含义是很难精确定义的,特别是中文词的语义。例如关于“徒”字,起初的词义是“空的、没有凭借的”,逐步引申变化为“步行”,再引申为“步兵”“同伙”“门徒”等。这里并不想陷入深奥的语言学讨论。从计算的视角,有一种观点是词的语义可以由它的上下文来确定。人在运用语言时,其实也没有记住每个词的精确语义定义,大脑里面其实也没有什么精确定义的词典,而是更多的类比一个词出现的上下文来理解这个词的语义。这就是所谓的分布式语义概念的来源。One-hot Encoding模型显然没有办法捕获词的上下文这种语义。所以,希望通过统计词在大量语料中的上下文规律,并通过词的上下文计算词的这种分布式向量表示。和One-hot Encoding不一样,这种分布式向量的每一个维度都有数值,且它的维度远远低于词库的大小,并且是通过语料统计学习出来的,称为低维稠密的向量表示,也称为词向量表示(Word Embedding)。例如,通过对大量语料进行统计学习,可以为“蝴蝶”“瓢虫”“飞”“爬”等词学习它们的向量表示,会发现这些词在向量表示空间有一些规律,比如蝴蝶和飞比较接近,而瓢虫则和爬比较接近,如下图所示:
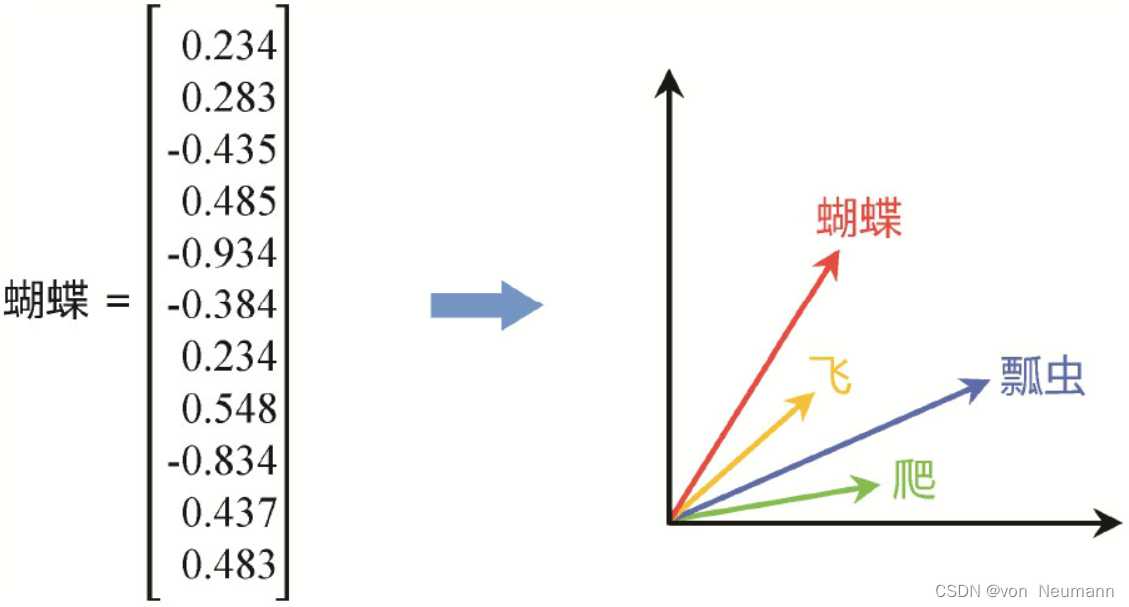
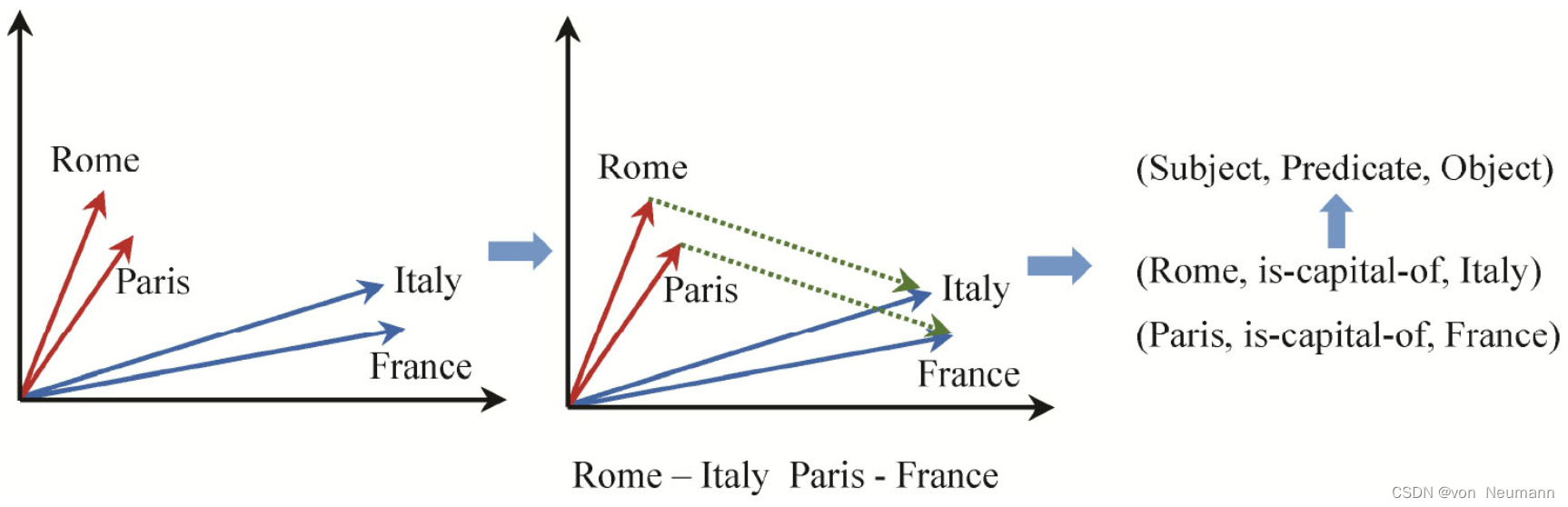
有很多种学习这类词向量的方法,比如传统的Word2vector模型CBOW(Continuous Bag of Words)是通过一个词的前几个词和后几个词作为该词的上下文,并通过引导模型预测中间那个词作为监督训练信号学习每个词的表示。SKIP-Gram则是反过来利用中间词预测前后几个词学习每个词的表示。不论是传统Word2vector,还是当下流行的预训练模型,本质都是基于词的上下文共现规律来近似地捕获词的语义,有兴趣的读者可以查阅自然语言处理相关资料进一步了解。这种词的分布式语义表示有很多有趣的特性。通过探究几个词的维度数值,可以发现同种语义的词在很多维度上具有相似性,例如Rome和Paris都是首都,而Italy和France都是国家,所以它们在某些维度上数值非常接近,如下图所示。再比如,Rome之于Italy,Paris之于France都存在首都关系,所以它们在某些维度上也有类似的相似性或相关性。然而对于One-hot Encoding,则无法利用这种向量计算得到这种隐含的语义关系。例如Rome和Paris直接计算相似度为0。

从词向量到实体向量
接下来从词的向量表示过渡到知识图谱的向量表示。有一类词是代表实体的,假如对这类实体词的向量做一些计算,比如用Rome向量减去Italy的向量,会发现这个差值和用Paris的向量减去France的向量比较接近。这里的原因是Rome和Italy之间,以及Paris和France之间都存在
is-capital-of的关系,如下图所示。这里看到了熟悉的知识图谱<主语, 谓语, 宾语>三元组结构。这启发可以利用三元组结构来学习知识图谱中实体和关系的向量表示,就像可以利用句子中词的上下文共现关系来学习词的向量表示一样。
知识图谱向量表示学习模型
有很多这样利用主谓宾三元组结构来学习知识图谱中实体和关系的向量表示的模型。其中一个比较简单但有效的模型是TransE。它的想法很简单,给定一个三元组
h代表head,即主语(subject),r代表relation,即关系谓词,t代表tail,即宾语(Object),如果它所代表的事实是客观存在的,那么h、r、t的向量表示应该满足加法关系h+r=t。例如Rome+is-capital of应该在向量空间接近于Italy;Paris+is-capital-of的结果也应该接近于France,如下图所示:
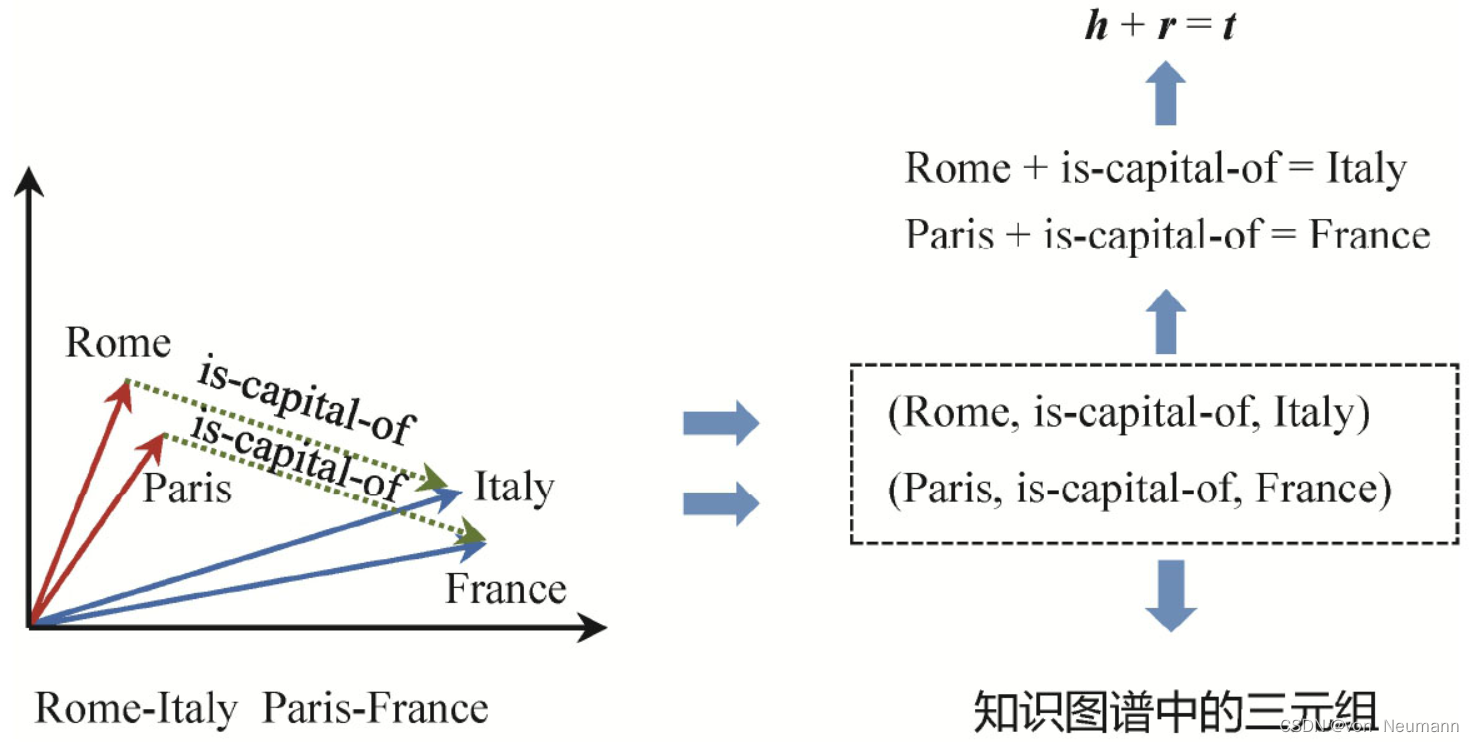
对于每一个三元组,可以定义一个评分函数 f r ( h , t ) fr(h,t) fr(h,t),然后对所有的三元组累加计算损失函数 L L L,如下图所示。例如给定Margin Loss的定义,这里的优化目标就是让真实存在的三元组得分尽可能高,而让不存在的三元组的得分尽可能低。可以采用简单的梯度下降优化方法,例如,可以随机初始化所有实体和关系的向量表示,然后一轮一轮地优化这些向量中的参数。如果优化目标能够收敛,最后学习到的绝大部分实体和关系的向量表示就应该满足h+r=t的假设。这里的负样本,也就是不存在的三元组可以有很多种方法构建,一种方法是随机地替换真实三元组的头尾实体,这些新生成的三元组大部分是不存在的,因而可以作为模型的负样本。

另外一类知识图谱嵌入表示学习模型是以DistMult为代表的基于线性变换的学习模型。与TransE采用加法不同,DistMult采用乘法,并用一个矩阵而非一个向量来表示关系,如果一个三元组(h,r,t)存在,那么 h h h的向量乘以 r r r的矩阵,应该接近于 t t t的向量表示,如下图所示。其他关于评分函数和损失函数的定义都和TransE一样:

那么评估这些实体和关系的向量表示的好坏最简单的方法是给定 h h h、 r r r、 t t t中的两个,来计算未知的一个,然后看预测的结果是否准确。例如,可以给定 h h h、 r r r,预测尾实体 t t t,将 h h h、 r r r与知识图谱中的所有候选实体计算得分,如果待预测的实体t得分最高,则说明向量表示学习的效果非常好,反之则学习得不好。有很多影响实体关系向量表示学习好坏的因素,例如一个影响比较大的因素是稀疏性问题。给定某个实体或关系,它们的向量表示学习的好坏依赖于知识图谱中是否存在足够多的包含它们的三元组,如果某个实体是一个孤立实体,自然就很难学习到比较好的表示。关于这些问题,将在知识图谱表示学习与推理的文章中进一步展开介绍。知识图谱向量表示的局限性
有非常多的知识图谱嵌入学习模型。当深入考察一个知识图谱的结构特性时,就会发现单纯地依赖三元组提供的信号是远远不够的。人脑的知识结构比语言还复杂,如果希望向量表示能像符号表示一样更加精准地刻画知识结构中的逻辑和语义,并且支持推理,就需要对向量学习的过程增加更多的约束。例如,为了刻画一对多、多对一等关系语义,就需要对增加能存储和捕获这种一对多、多对一的关系的额外参数。但这势必又会增加学习的负担,且对训练语料的要求也会更高。这就陷入两难:一方面,客观问题要求刻画更加复杂的知识逻辑,另一方面,又受到训练代价以及训练语料不充分的约束。所以,知识图谱的表示学习其实是一个比文本表示学习更复杂的问题。关于这个问题,将在知识图谱表示学习与推理、图表示学习及图神经网络的文章再进一步展开探讨。
参考文献:
[1] 陈华钧.知识图谱导论[M].电子工业出版社, 2021
[2] 邵浩, 张凯, 李方圆, 张云柯, 戴锡强. 从零构建知识图谱[M].机械工业出版社, 2021 -
相关阅读:
C/C++语言100题练习计划 78——括号序列(前缀和实现)
每个前端都要学的【前端自动化部署】,Devops,CI/CD
[附源码]计算机毕业设计JAVAjsp-室内田径馆预约管理系统
Flutter——自适应设计
企业数字化成功转型的关键,从这三方面出发
vim字符串全局替换
python播放声音库playsound以及获取路径以及修改库源码
算法专题-单调栈
【合集】Redis——Redis的入门到进阶 & 结合实际场景的Redis的应用
python:绘制回归预测结果真实值和预测值之间的散点密度图
- 原文地址:https://blog.csdn.net/hy592070616/article/details/126472948