-
分布式事务中的那些事——微服务总结(二)
前言
分布式事物是微服务中最重要的一点,同时也是最复杂的一个环节
当单体服务拆分为多个微服务并且运行在不同的网络不同的机器上时,将会出现各种各样的问题:
分布式服务有一句非常出名的话就是:永远不要相信网络是安全的。
之前对于单体应用很简单的一个事物逻辑,移植到到微服务上将会变得具有挑战性。
本文将先对分布式事物做个简单的介绍,然后总结下导致数据不一致的问题,以及业界常用的对应的解决方案,最后将介绍下消息队列MQ以及主要使用到的RQ。
分布式事物是一个很有挑战且有趣的问题,不是几句话或者一片文章能够将清楚的,其中涉及到大量的专业知识,这里仅仅对自己所学的内容做一个总结并在此分享下
事务和分布式事务
事务概念
- 一组sql语句操作单元,组内所有SQL语句完成一个业务,如果整组成功:意味着全部SQL都实现;如果其中任何一个失败,意味着整个操作都失败。失败,意味着整个过程都是没有意义的。应该是数据库回到操作前的初始状态。这种特性,就叫“事务”。
为什么要存在事务
- 失败后,可以回到开始位置
- 没都成功之前,别的用户(进程,会话)是不能看到操作内的数据修改的
事务4大特征ACID
-
原子性[atomicity]
功能不可再分,要么全部成功,要么全部失败
-
一致性[consistency]
一致性是指数据处于一种语义上的有意义且正确的状态。一致性是对数据可见性的约束,保证在一个事务中的多次操作的数据中间状态对其他事务不可见的。因为这些中间状态,是一个过渡状态,与事务的开始状态和事务的结束状态是不一致的。
举个例子,张三给李四转账100元。事务要做的是从张三账户上减掉100元,李四账户上加上100元。一致性的含义是其他事务要么看到张三还没有给李四转账的状态,要么张三已经成功转账给李四的状态,而对于张三少了100元,李四还没加上100元这个中间状态是不可见的。
我们来看一下转账过程中可能存在的状态:
- 张三未扣减、李四未收到
- 张三已扣减、李四未收到
- 张三已扣减,李四已收到
上述过程中: 1. 是初始状态、2是中间状态、3是最终状态,1和3是我们期待的状态,但是2这种状态却不是我们期待出现的状态。 - 锁
那么反驳的声音来了:
要么转账操作全部成功,要么全部失败,这是原子性。从例子上看全部成功,那么一致性就是原子性的一部分咯,为什么还要单独说一致性和原子性?
你说的不对。在未提交读的隔离级别下是事务内部操作是可见的,明显违背了一致性,怎么解释?
好吧,需要注意的是:
原子性和一致性的的侧重点不同:原子性关注状态,要么全部成功,要么全部失败,不存在部分成功的状态。而一致性关注数据的可见性,中间状态的数据对外部不可见,只有最初状态和最终状态的数据对外可见
-
隔离性[isolation]
事务的隔离性是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离。
隔离性是多个事务的时候, 相互不能干扰,一致性是要保证操作前和操作后数据或者数据结构的一致性,而我提到的事务的一致性是关注数据的中间状态,也就是一致性需要监视中间状态的数据,如果有变化,即刻回滚
如果不考虑隔离性,事务存在3种并发访问数据问题,也就是事务里面的脏读、不可重复读、虚度/幻读
mysql的隔离级别:读未提交、读已提交、可重复读、串行化
-
持久性[durability]
是事务的保证,事务终结的标志(内存的数据持久到硬盘文件中)
分布式事务
分布式事务顾名思义就是要在分布式系统中实现事务,它其实是由多个本地事务组合而成。
对于分布式事务而言几乎满足不了 ACID,其实对于单机事务而言大部分情况下也没有满足 ACID,不然怎么会有四种隔离级别呢?所以更别说分布在不同数据库或者不同应用上的分布式事务了。
导致数据不一致的问题
导致数据不一致主要分为两大类:
- 网络问题
- 硬件故障,网络抖动、网络拥塞等
- 服务方没有发送出去,发送出去了,没有收到客户端的返回,导致以为出错了
- 程序问题
- 程序代码异常
- 服务器宕机了
CAP和BASE理论
CAP理论
cap理论是分布式系统的理论基石
Consistency (一致性):
“all nodes see the same data at the same time”,即更新操作成功并返回客户端后,所有节点在同一时间的数据完全一致,这就是分布式的一致性。一致性的问题在并发系统中不可避免,对于客户端来说,一致性指的是并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
Availability (可用性):
可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。
Partition Tolerance (分区容错性):
即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,对于用户而言并没有什么体验上的影响。
如果你你是一个分布式系统,那么你必须要满足一点:分区容错性取舍策略
分布式系统不可能同时满足CAP , 最多满足其中的两个
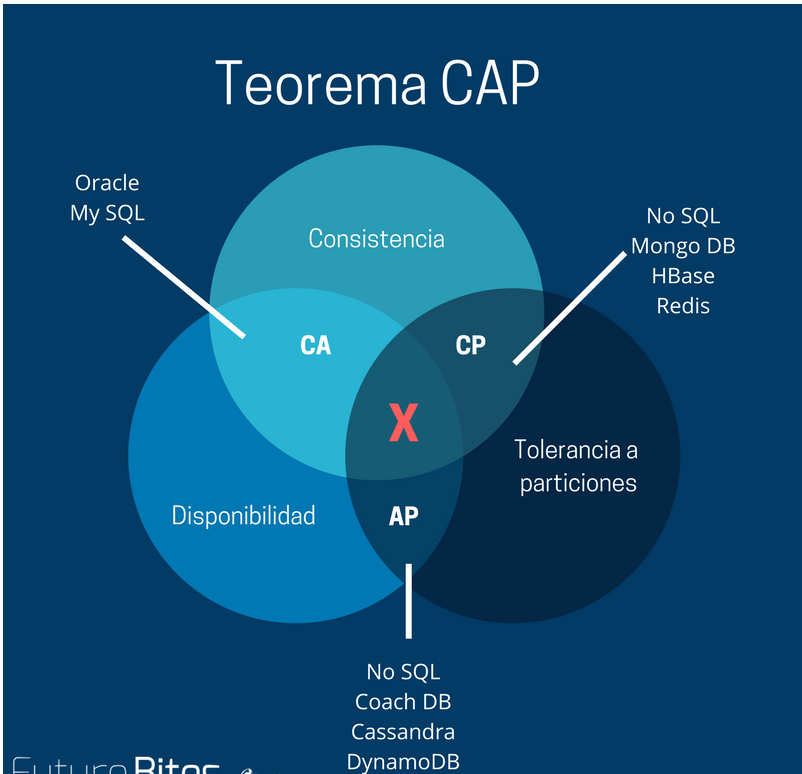
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。
CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。
设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
AP wihtout C: 要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
典型的应用就如抢购场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。
Base理论
布式系统中的一致性是 弱一致性 单数据库 mysql的一致性 强一致性
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。BASE理论是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结, 是基于CAP定理逐步演化而来的。BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。接下来看一下BASE中的三要素:
1、基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性—-注意,这绝不等价于系统不可用。比如:
(1)响应时间上的损失。正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了1~2秒
(2)系统功能上的损失:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面
2、软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时
3、最终一致性
最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID特性是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起。
一句话:CAP就是告诉你:想要满足C、A、P就是做梦,BASE才是你最终的归宿
常见的分布式事务解决方案
两阶段提交(2PC)
-
两阶段提交又称2PC(2PC, Two-phase Commit),2PC是一个非常经典的
中心化的原子提交协议。 -
这里所说的中心化是指协议中有两类节点:一个是中心化
协调者节点(coordinator)和N个参与者节点(partcipant)。 -
第一阶段:投票阶段
第二阶段:提交/执行阶段
eg: 订单服务A,需要调用 支付服务B 去支付,支付成功则处理购物订单为待发货状态,否则就需要将购物订单处理为失败状态。
-
第一阶段:投票阶段
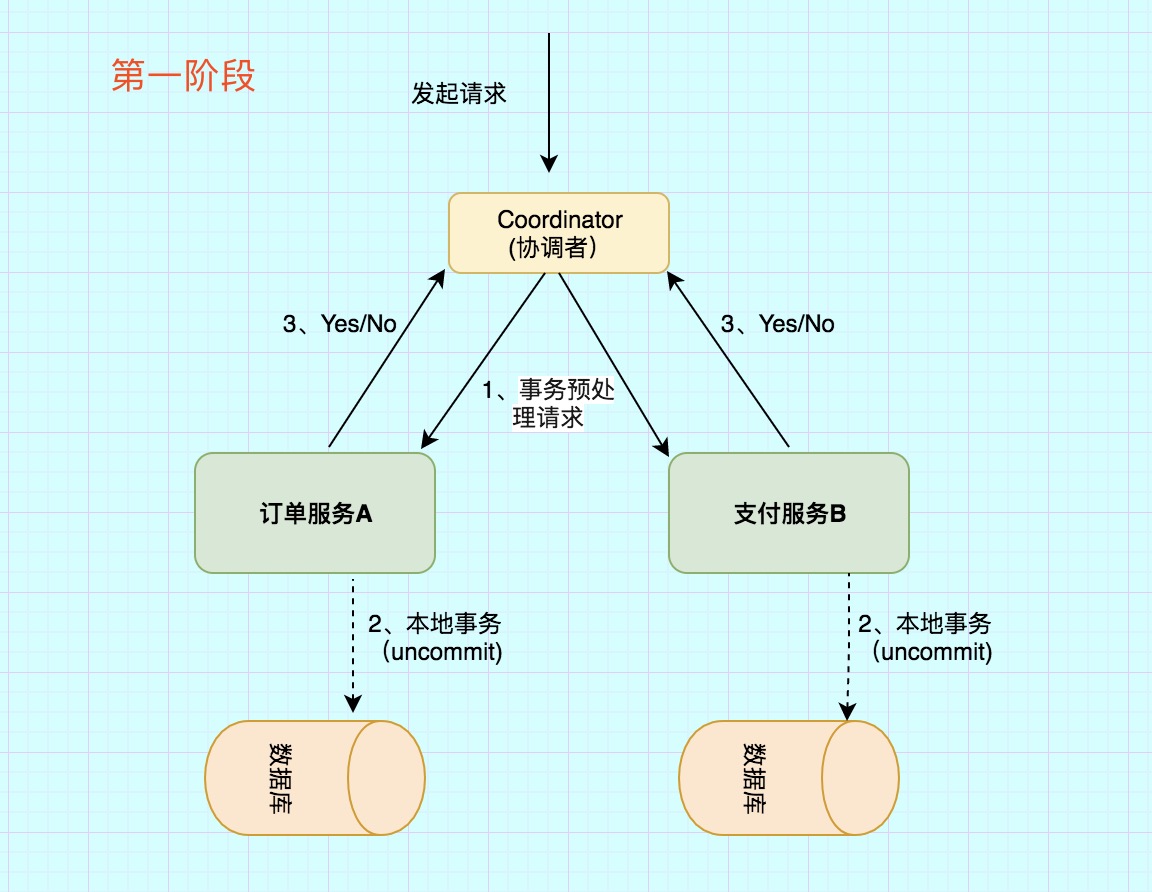
第一阶段主要分为3步
-
事务询问
协调者 向所有的 参与者 发送事务预处理请求,称之为Prepare,并开始等待各 参与者 的响应。
-
执行本地事务
各个 参与者 节点执行本地事务操作,但在执行完成后并不会真正提交数据库本地事务,而是先向 协调者 报告说:“我这边可以处理了/我这边不能处理”。
-
各参与者向协调者反馈事务询问的响应
如果 参与者 成功执行了事务操作,那么就反馈给协调者 Yes 响应,表示事务可以执行,如果没有 参与者 成功执行事务,那么就反馈给协调者 No 响应,表示事务不可以执行。
第一阶段执行完后,会有两种可能。1、所有都返回Yes. 2、有一个或者多个返回No
-
-
第二阶段:提交/执行阶段(成功流程)
成功条件:所有参与者都返回Yes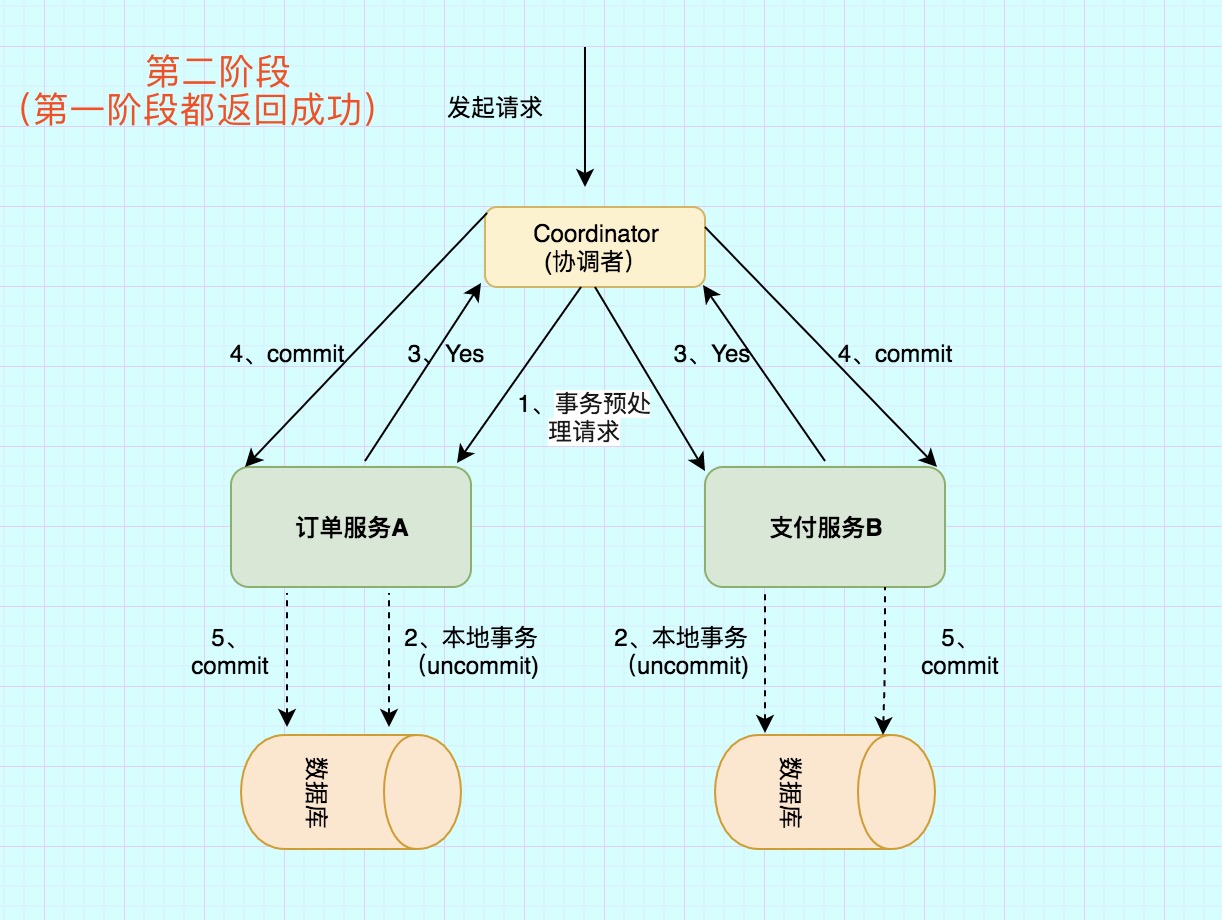
第二阶段主要分为两步:
1)
所有的参与者反馈给协调者的信息都是Yes,那么就会执行事务提交协调者 向 所有参与者 节点发出Commit请求.
2)
事务提交参与者 收到Commit请求之后,就会正式执行本地事务Commit操作,并在完成提交之后释放整个事务执行期间占用的事务资源
-
第二阶段:提交/执行阶段(异常流程)
异常条件:任何一个 参与者 向 协调者 反馈了 No 响应,或者等待超时之后,协调者尚未收到所有参与者的反馈响应。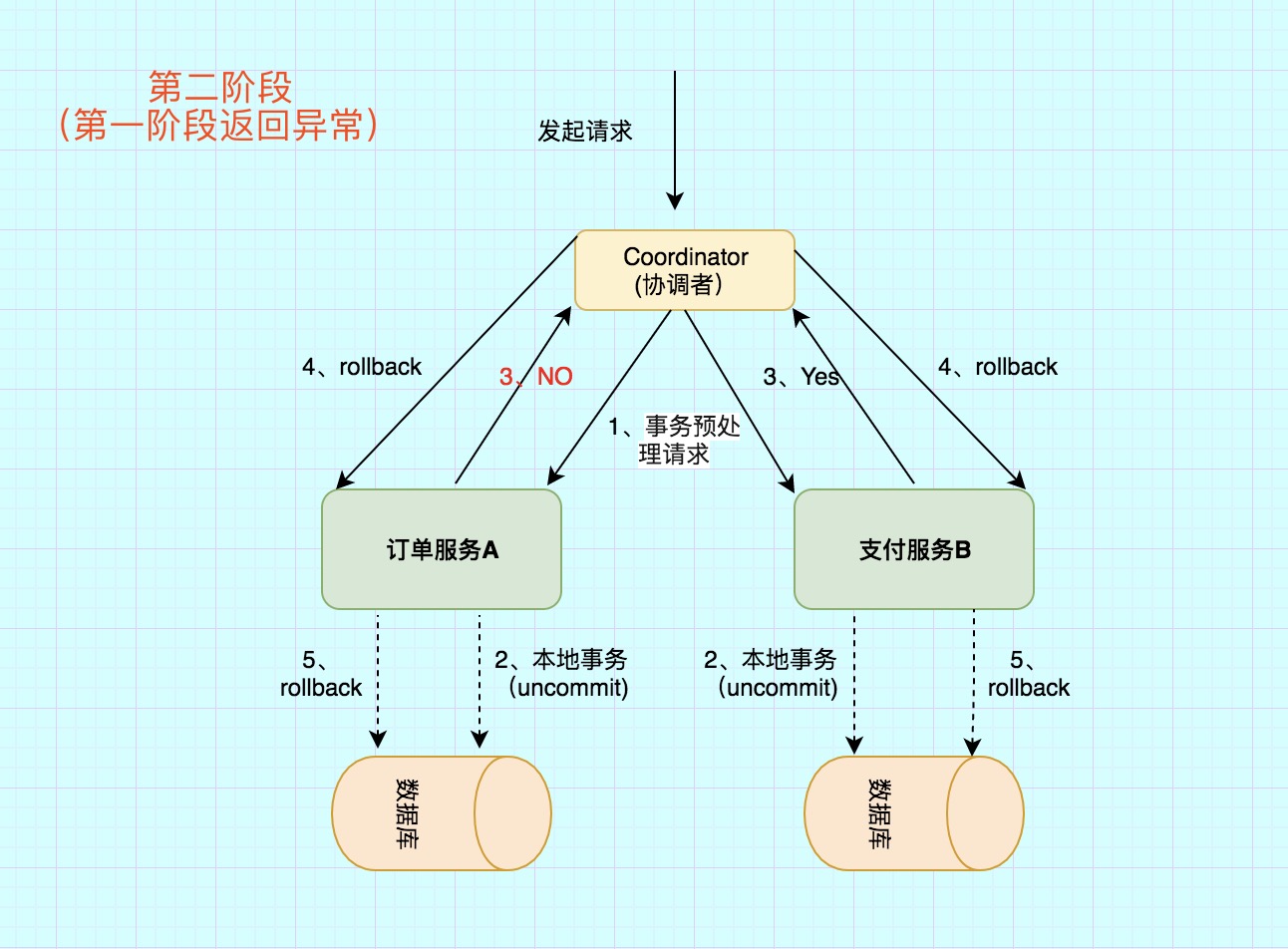
异常流程第二阶段也分为两步
1)
发送回滚请求协调者 向所有参与者节点发出 RoollBack 请求.
2)
事务回滚参与者 接收到RoollBack请求后,会回滚本地事务。
-
2PC缺点
通过上面的演示,很容易想到2pc所带来的缺陷
1)
性能问题-
无论是在第一阶段的过程中,还是在第二阶段,所有的参与者资源和协调者资源都是被锁住的,只有当所有节点准备完毕,事务 协调者 才会通知进行全局提交,
-
参与者 进行本地事务提交后才会释放资源。这样的过程会比较漫长,对性能影响比较大。
2)
单节点故障-
由于协调者的重要性,一旦 协调者 发生故障。参与者 会一直阻塞下去。尤其在第二阶段,协调者 发生故障,那么所有的 参与者 还都处于
-
锁定事务资源的状态中,而无法继续完成事务操作。(虽然协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
2PC出现单点问题的三种情况
(1)
协调者正常,参与者宕机- 由于 协调者 无法收集到所有 参与者 的反馈,会陷入阻塞情况。
解决方案:引入超时机制,如果协调者在超过指定的时间还没有收到参与者的反馈,事务就失败,向所有节点发送终止事务请求。
(2)
协调者宕机,参与者正常- 无论处于哪个阶段,由于协调者宕机,无法发送提交请求,所有处于执行了操作但是未提交状态的参与者都会陷入阻塞情况.
解决方案:引入协调者备份,同时协调者需记录操作日志.当检测到协调者宕机一段时间后,协调者备份取代协调者,并读取操作日志,向所有参与者询问状态。
(3)
协调者和参与者都宕机-
发生在第一阶段: 因为第一阶段,所有参与者都没有真正执行commit,所以只需重新在剩余的参与者中重新选出一个协调者,新的协调者在重新执行第一阶段和第二阶段就可以了。
-
发生在第二阶段 并且 挂了的参与者在挂掉之前没有收到协调者的指令。也就是上面的第4步挂了,这是可能协调者还没有发送第4步就挂了。这种情形下,新的协调者重新执行第一阶段和第二阶段操作。
-
发生在第二阶段 并且 有部分参与者已经执行完commit操作。就好比这里订单服务A和支付服务B都收到协调者 发送的commit信息,开始真正执行本地事务commit,但突发情况,Acommit成功,B确挂了。这个时候目前来讲数据是不一致的。虽然这个时候可以再通过手段让他和协调者通信,再想办法把数据搞成一致的,但是,这段时间内他的数据状态已经是不一致的了! 2PC 无法解决这个问题。
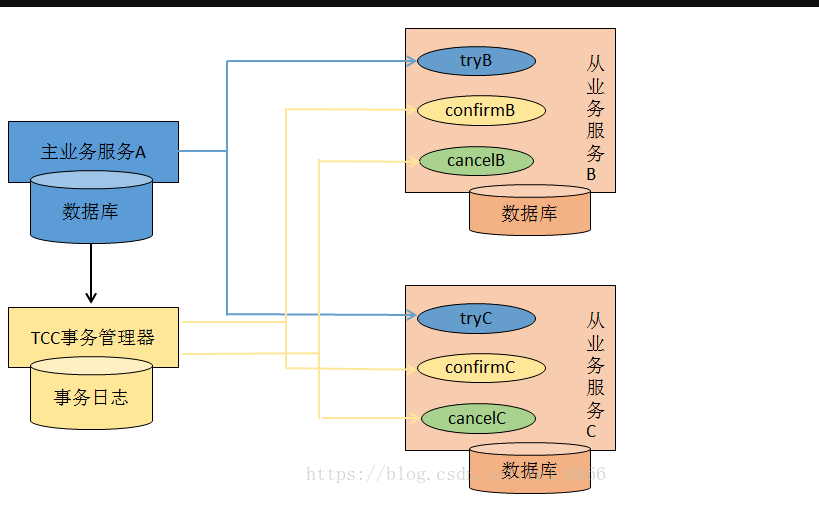
TCC分布式事务
业务场景模拟
一个订单支付之后,我们需要做下面的步骤:
- 更改订单的状态为“已支付”
- 扣减商品库存
- 给会员增加积分
- 创建销售出库单通知仓库发货
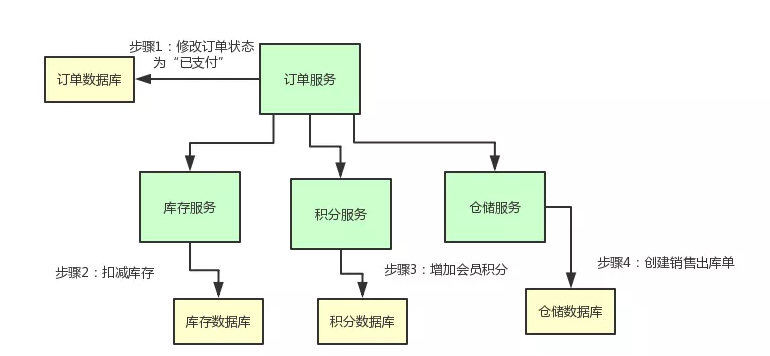
好,业务场景有了,现在我们要更进一步,实现一个 TCC 分布式事务的效果。
什么意思呢?也就是说:
[1] 订单服务-修改订单状态
[2] 库存服务-扣减库存
[3] 积分服务-增加积分
[4] 仓储服务-创建销售出库单。
上述这几个步骤,要么一起成功,要么一起失败,必须是一个整体性的事务。
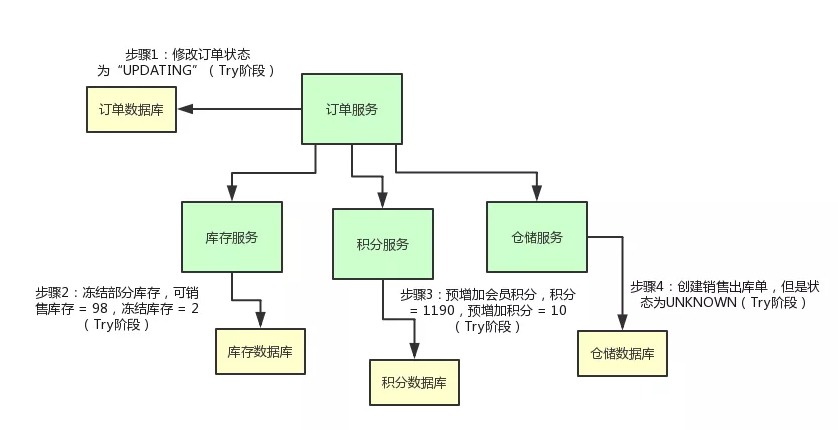
举个例子,现在订单的状态都修改为“已支付”了,结果库存服务扣减库存失败。那个商品的库存原来是 100 件,现在卖掉了 2 件,本来应该是 98 件了。
结果呢?由于库存服务操作数据库异常,导致库存数量还是 100。这不是在坑人么,当然不能允许这种情况发生了!
但是如果你不用 TCC 分布式事务方案的话,就用个 go开发这么一个微服务系统,很有可能会干出这种事儿来。
我们来看看下面的这个图,直观的表达了上述的过程:
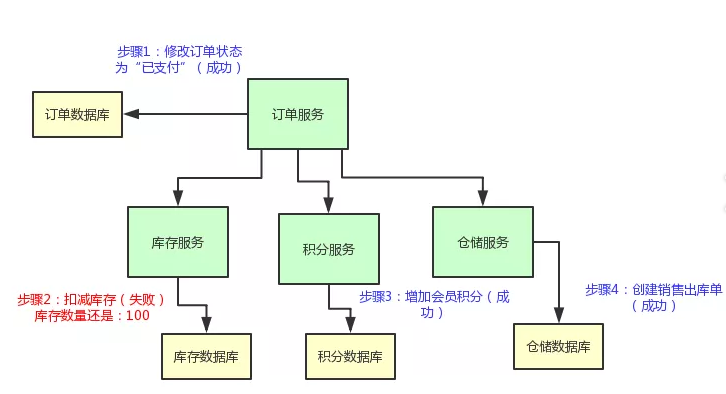
所以说,我们有必要使用 TCC 分布式事务机制来保证各个服务形成一个整体性的事务。
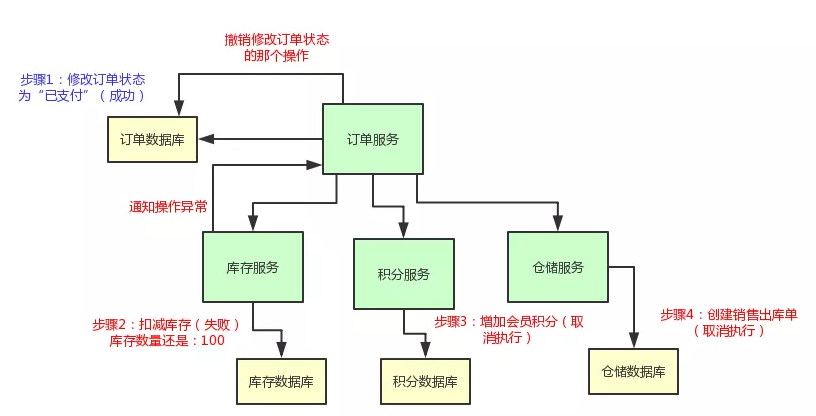
上面那几个步骤,要么全部成功,如果任何一个服务的操作失败了,就全部一起回滚,撤销已经完成的操作。
比如说库存服务要是扣减库存失败了,那么订单服务就得撤销那个修改订单状态的操作,然后得停止执行增加积分和通知出库两个操作。
说了那么多,老规矩,给大家上一张图,大伙儿顺着图来直观的感受一下:
实现 TCC 分布式事务
-
TCC 实现阶段一:Try
首先,订单服务那儿,它的代码大致来说应该是这样子的:
class OrderService: def __init__(self, inv_srv, credit_srv, wms_srv): #库存服务 self.inv_srv = inv_srv #积分服务 self.credit_srv = credit_srv #仓储服务 self.wms_srv = wms_srv def update_order_status(self, status): pass def notify(self): #1. 本地订单状态修改为 “已支付” self.update_order_status("TRADE_SUCCESS") self.inv_srv.reduce_stock() #扣减库存 self.credit_srv.add_credit() #新增积分 self.wms_srv.sale_delivery() #通知仓库发货- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
其实就是订单服务完成本地数据库操作之后,通过grpc 来调用其他的各个服务罢了。
首先,上面那个订单服务先把自己的状态修改为TRADE_SUCCESS。
也就是说,在 pay() 那个方法里,你别直接把订单状态修改为已支付啊!你先把订单状态修改为 UPDATING,也就是修改中的意思。
这个状态是个没有任何含义的这么一个状态,代表有人正在修改这个状态罢了。
然后呢,库存服务直接提供的那个 reduce_stock() 接口里,也别直接扣减库存,可以是冻结掉库存。
举个例子,本来你的库存数量是 100,别直接 100 - 2 = 98,扣减这个库存!
可以把可销售的库存:100 - 2 = 98,设置为 98 没问题,然后在一个单独的冻结库存的字段里,设置一个 2。也就是说,有 2 个库存是给冻结了。
积分服务的 add_credit() 接口也是同理,别直接给用户增加会员积分。可以先在积分表里的一个预增加积分字段加入积分。
比如:用户积分原本是 1190,现在要增加 10 个积分,别直接 1190 + 10 = 1200 个积分啊!
你可以保持积分为 1190 不变,在一个预增加字段里,比如说 prepare_add_credit 字段,设置一个 10,表示有 10 个积分准备增加。
仓储服务的 sale_delivery() 接口也是同理啊,你可以先创建一个销售出库单,但是这个销售出库单的状态是“UNKNOWN”。
也就是说,刚刚创建这个销售出库单,此时还不确定它的状态是什么呢!
上面这套改造接口的过程,其实就是所谓的 TCC 分布式事务中的第一个 T 字母代表的阶段,也就是 Try 阶段。
总结上述过程,如果你要实现一个 TCC 分布式事务,首先你的业务的主流程以及各个接口提供的业务含义,不是说直接完成那个业务操作,而是完成一个 Try 的操作。
这个操作,一般都是锁定某个资源,设置一个预备类的状态,冻结部分数据,等等,大概都是这类操作。
咱们来一起看看下面这张图,结合上面的文字,再来捋一捋整个过程:
-
TCC 实现阶段二:Confirm
然后就分成两种情况了,第一种情况是比较理想的,那就是各个服务执行自己的那个 Try 操作,都执行成功了,Bingo!
这个时候,就需要依靠 TCC 分布式事务框架来推动后续的执行了。这里简单提一句,如果你要玩儿 TCC 分布式事务,必须引入一款 TCC 分布式事务框架,比如java国内开源的 seata、ByteTCC、Himly、TCC-transaction。
否则的话,感知各个阶段的执行情况以及推进执行下一个阶段的这些事情,不太可能自己手写实现,太复杂了。
如果你在各个服务里引入了一个 TCC 分布式事务的框架,订单服务里内嵌的那个 TCC 分布式事务框架可以感知到,各个服务的 Try 操作都成功了。
此时,TCC 分布式事务框架会控制进入 TCC 下一个阶段,第一个 C 阶段,也就是 Confirm 阶段。
为了实现这个阶段,你需要在各个服务里再加入一些代码。比如说,订单服务里,你可以加入一个 Confirm 的逻辑,就是正式把订单的状态设置为“已支付”了,大概是类似下面这样子:
class OrderServiceConfirm: def pay(): orm.update_status("TRADE_SUCCESS")- 1
- 2
- 3
库存服务也是类似的,你可以有一个 InventoryServiceConfirm 类,里面提供一个 reduce_stock() 接口的 Confirm 逻辑,这里就是将之前冻结库存字段的 2 个库存扣掉变为 0。
这样的话,可销售库存之前就已经变为 98 了,现在冻结的 2 个库存也没了,那就正式完成了库存的扣减。
积分服务也是类似的,可以在积分服务里提供一个 CreditServiceConfirm 类,里面有一个 addCredit() 接口的 Confirm 逻辑,就是将预增加字段的 10 个积分扣掉,然后加入实际的会员积分字段中,从 1190 变为 1120。
仓储服务也是类似,可以在仓储服务中提供一个 WmsServiceConfirm 类,提供一个 sale_delivery() 接口的 Confirm 逻辑,将销售出库单的状态正式修改为“已创建”,可以供仓储管理人员查看和使用,而不是停留在之前的中间状态“UNKNOWN”了。
好了,上面各种服务的 Confirm 的逻辑都实现好了,一旦订单服务里面的 TCC 分布式事务框架感知到各个服务的 Try 阶段都成功了以后,就会执行各个服务的 Confirm 逻辑。
订单服务内的 TCC 事务框架会负责跟其他各个服务内的 TCC 事务框架进行通信,依次调用各个服务的 Confirm 逻辑。然后,正式完成各个服务的所有业务逻辑的执行。
同样,给大家来一张图,顺着图一起来看看整个过程:

-
TCC 实现阶段三:Cancel
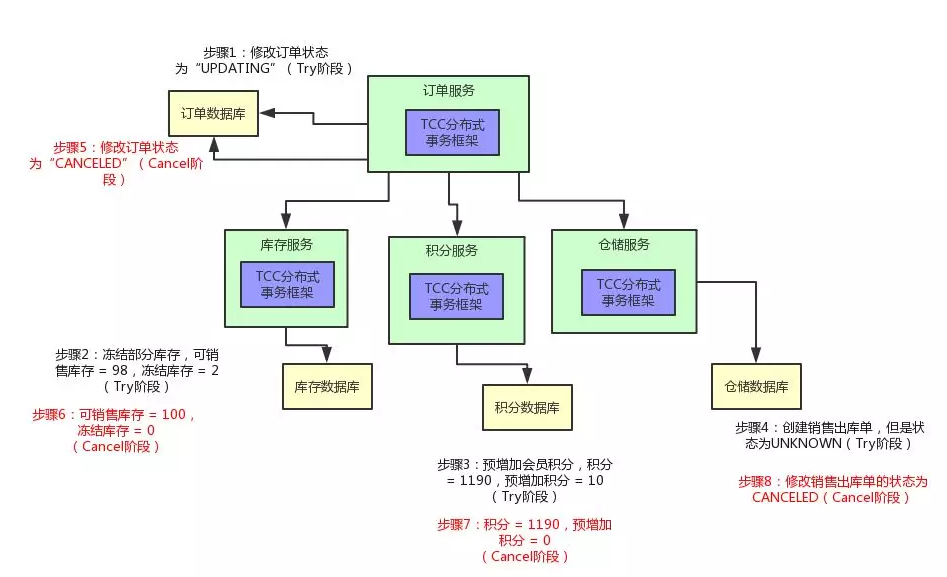
上边为比较正常的一种情况,那如果是异常的一种情况呢?
举个例子:在 Try 阶段,比如积分服务吧,它执行出错了,此时会怎么样?
那订单服务内的 TCC 事务框架是可以感知到的,然后它会决定对整个 TCC 分布式事务进行回滚。
也就是说,会执行各个服务的第二个 C 阶段,Cancel 阶段。同样,为了实现这个 Cancel 阶段,各个服务还得加一些代码。
首先订单服务,它得提供一个 OrderServiceCancel 的类,在里面有一个 pay() 接口的 Cancel 逻辑,就是可以将订单的状态设置为“CANCELED”,也就是这个订单的状态是已取消。
库存服务也是同理,可以提供 reduce_stock() 的 Cancel 逻辑,就是将冻结库存扣减掉 2,加回到可销售库存里去,98 + 2 = 100。
积分服务也需要提供 addCredit() 接口的 Cancel 逻辑,将预增加积分字段的 10 个积分扣减掉。
仓储服务也需要提供一个 sale_delivery() 接口的 Cancel 逻辑,将销售出库单的状态修改为“CANCELED”设置为已取消。
然后这个时候,订单服务的 TCC 分布式事务框架只要感知到了任何一个服务的 Try 逻辑失败了,就会跟各个服务内的 TCC 分布式事务框架进行通信,然后调用各个服务的 Cancel 逻辑。
大家看看下面的图,直观的感受一下:
总结与思考
-
首先需要选择某种TCC分布式事务框架,各个服务里就会有这个TCC分布式事务框架在运行
-
然后你原本的一个接口,要改造为3个逻辑,Try-Confirm-Cancel
-
先是服务调用链路依次执行Try逻辑
如果都正常的话,TCC分布式事务框架推进执行Confirm逻辑,完成整个事务
如果某个服务的Try逻辑有问题,TCC分布式事务框架感知到之后就会推进执行各个服务的Cancel逻辑,撤销之前执行的各种操作。
-
TCC分布式事务的核心思想,说白了,就是当遇到下面这些情况时:
- 某个服务的数据库宕机了
- 某个服务自己挂了
- 那个服务的redis、elasticsearch、MQ等基础设施故障了
- 某些资源不足了,比如说库存不够这些
先来Try一下,不要把业务逻辑完成,先试试看,看各个服务能不能基本正常运转,能不能先冻结我需要的资源
如果Try都ok,也就是说,底层的数据库、redis、elasticsearch、MQ都是可以写入数据的,并且你保留好了需要使用的一些资源(比如冻结了一部分库存)。
接着,再执行各个服务的Confirm逻辑,基本上Confirm就可以很大概率保证一个分布式事务的完成了。
那如果Try阶段某个服务就失败了,比如说底层的数据库挂了,或者redis挂了,等等
此时就自动执行各个服务的Cancel逻辑,把之前的Try逻辑都回滚,所有服务都不要执行任何设计的业务逻辑。保证大家要么一起成功,要么一起失败
-
-
如果有一些意外的情况发生了,比如说订单服务突然挂了,然后再次重启,TCC分布式事务框架是如何保证之前没执行完的分布式事务继续执行的呢?
- TCC事务框架都是要记录一些分布式事务的活动日志的,可以在磁盘上的日志文件里记录,也可以在数据库里记录。保存下来分布式事务运行的各个阶段和状态。
-
万一某个服务的Cancel或者Confirm逻辑执行一直失败怎么办
- 举个例子,比如发现某个服务的Cancel或者Confirm一直没成功,会不停的重试调用他的Cancel或者Confirm逻辑,务必要他成功!
- 当然了,如果你的代码没有写什么bug,有充足的测试,而且Try阶段都基本尝试了一下,那么其实一般Confirm、Cancel都是可以成功的!
- 如果实在解决不了,那么这个一定是很小概率的事件,这个时候发邮件通知人工处理
- TCC框架: seata、 go-seata
-
TCC优缺点
优点:
- 解决了跨服务的业务操作原子性问题,例如组合支付,订单减库存等场景非常实用
- TCC的本质原理是把数据库的二阶段提交上升到微服务来实现,从而避免了数据库2阶段中锁冲突的长事务低性能风险。
- TCC异步高性能,它采用了try先检查,然后异步实现confirm,真正提交的是在confirm方法中。
缺点:
- 对微服务的侵入性强,微服务的每个事务都必须实现try,confirm,cancel等3个方法,开发成本高,今后维护改造的成本也高。
- 为了达到事务的一致性要求,try,confirm、cancel接口必须实现幂等性操作(定时器+重试)
- 由于事务管理器要记录事务日志,必定会损耗一定的性能,并使得整个TCC事务时间拉长,建议采用redis的方式来记录事务日志。
- tcc需要通过锁来确保数据的一致性,会加锁导致性能不高
基于本地消息表的最终一致性
本地消息表这个方案最初是eBay提出的,此方案的核心是通过本地事务保证数据业务操作和消息的一致性,然后通过定时任务将消息发送至消息中间件,待确认消息发送给消费方成功再将消息删除。
下面以注册送积分为例来说明 :
下例共有两个微服务交互,用户服务和积分服务,用户服务负责添加用户,积分服务负责增加积分。
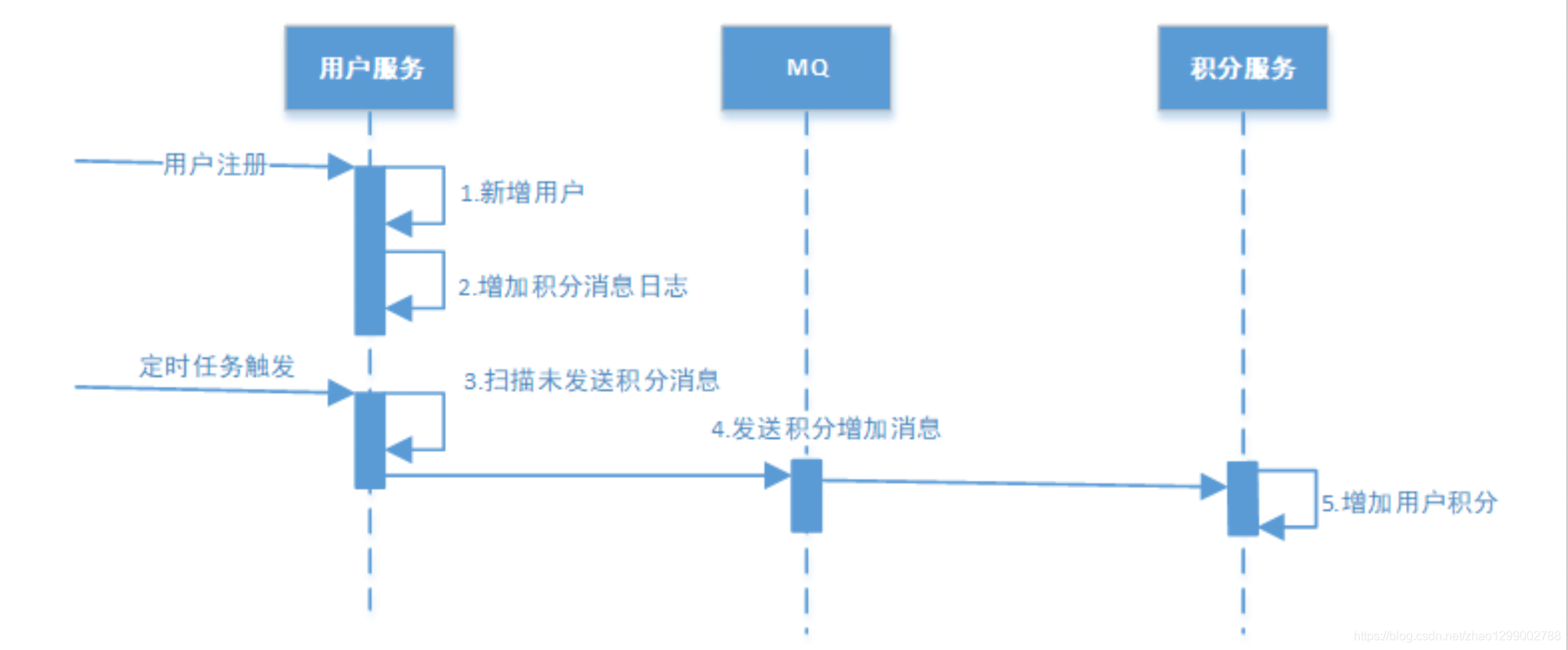
交互流程如下 :
1、用户注册
用户服务在本地事务新增用户和增加“积分消息日志”。(用户表和消息表通过本地事务保证一致)
下表是伪代码
begin transaction; // 1.新增用户 // 2.存储积分消息日志 commit transation;- 1
- 2
- 3
- 4
这种情况下,本地数据库操作与存储积分消息日志处于同一事务中,本地数据库操作与记录消息日志操作具备原子性。
2、定时任务扫描日志
如何保证将消息发送给消息队列呢?
经过第一步消息已经写到消息日志表中,可以启动独立的线程,定时对消息日志表中的消息进行扫描并发送至消息中间件,在消息中间件反馈发送成功后删除该消息日志,否则等待定时任务下一周期重试。
3、消费消息
如何保证消费者一定能消费到消息呢?
这里可以使用MQ的ack(即消息确认)机制,消费者监听MQ,如果消费者接收到消息并且业务处理完成后向MQ发送ack(即消息确认),此时说明消费者正常消费消息完成,MQ将不再向消费者推送消息,否则消费者会不断重试向消费者来发送消息。
积分服务接收到“增加积分”消息,开始增加积分,积分增加成功后消息中间件回应ack,否则消息中间件将重复投递此消息。
由于消息会重复投递,积分服务的“增加积分”功能需要实现幂等性。
总结:上诉的方式是一种非常经典的实现,基本避免了分布式事务,实现了“最终一致性”。但是,关系型数据库的吞吐量和性能方面存在瓶颈,频繁的读写消息会给数据库造成压力。所以,在真正的高并发场景下,该方案也会有瓶颈和限制的
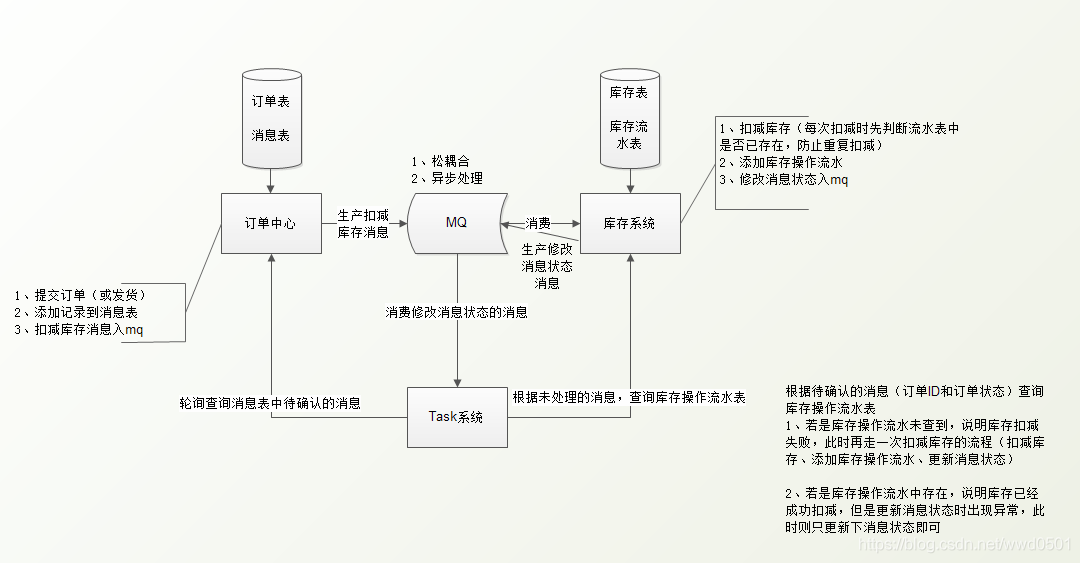
下单扣除库存案例
-
基于本地事务消息表的最终一致性实现下单扣除库存的流程图如下:
基于可靠消息的最终一致性- 最常用
RocketMQ是一个来自阿里巴巴的分布式消息中间件,于2012年开源,并在2017年正式成为Apache顶级项目。据了解,包括阿里云上的消息产品以及收购的子公司在内,阿里集团的消息产品全线都运行在RocketMQ之上,并且最近几年的双十一大促中,RocketMQ都有抢眼表现。Apache RocketMQ 4.3之后的版本正式支持事务消息,为分布式事务实现提供来便利性支持。
RocketMQ事务消息设计则主要是为了解决Producer端的消息发送与本地事务执行的原子性问题,RocketMQ的设计中broker与producer端的双向通信能力,使得broker天生可以作为一个事务协调者存在;
而RocketMQ本身提供的存储机制为事务消息提供了持久化能力;RocketMQ的高可用机制以及可靠消息设计则为事务消息在系统发生异常时依然能够保证达成事务的最终一致性。
在RocketMQ 4.3后实现了完整的事务消息,实际上其实是对本地消息表的一个封装,将本地消息表移动到了MQ内部,解决Producer端的消息发送与本地事务执行的原子性问题。
发送RQ的事物消息
https://help.aliyun.com/document_detail/43348.html
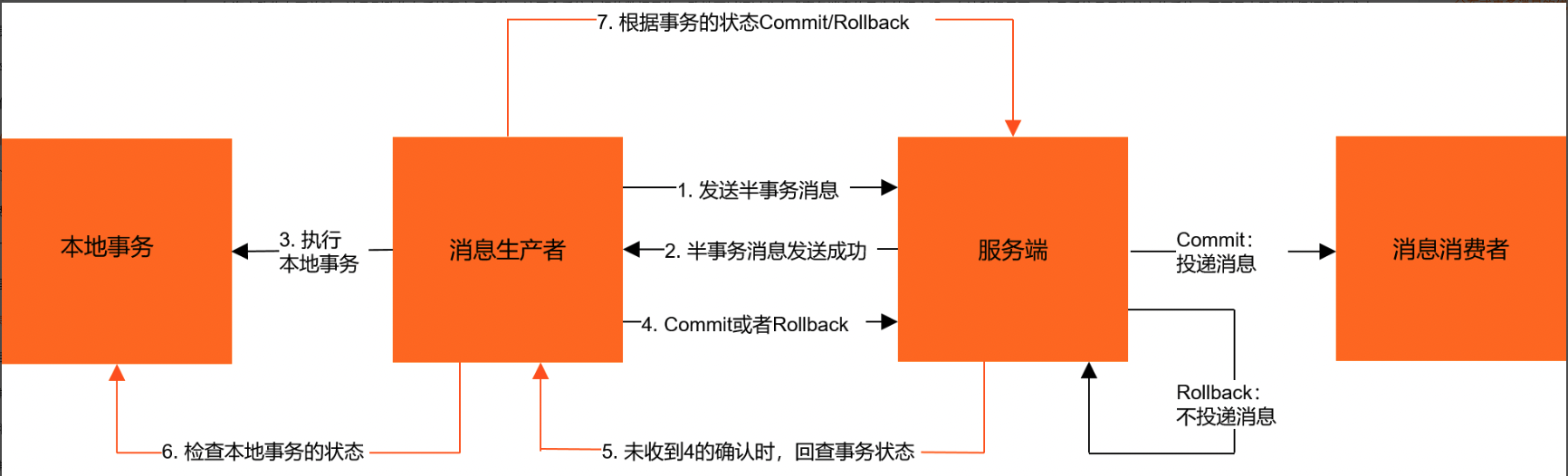
事务消息发送步骤如下:
-
生产者将半事务消息发送至消息队列RocketMQ版服务端。
-
消息队列RocketMQ版服务端将消息持久化成功之后,向生产者返回Ack确认消息已经发送成功,此时消息为半事务消息。
-
生产者开始执行本地事务逻辑。
-
生产者根据本地事务执行结果向服务端提交二次确认结果(Commit或是Rollback),服务端收到确认结果后处理逻辑如下:
- 二次确认结果为Commit:服务端将半事务消息标记为可投递,并投递给消费者。
- 二次确认结果为Rollback:服务端将回滚事务,不会将半事务消息投递给消费者。
-
在断网或者是生产者应用重启的特殊情况下,若服务端未收到发送者提交的二次确认结果,或服务端收到的二次确认结果为Unknown未知状态,经过固定时间后,服务端将对消息生产者即生产者集群中任一生产者实例发起消息回查。
事务消息回查步骤如下:
- 生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 生产者根据检查得到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半事务消息进行处理
下单扣除库存场景
-
下单需要与库存服务和商品服务交互,当下单服务异常,或者与外部服务交互异常,导致生成订单流水号失败,都需要执行回退库存操作
-
借助RQ发送回退库存事务消息,当出现异常情况时就回退库存
-
并且解耦了订单服务与外部服务的交互,订单服务在发送事务消息后,RQ将回调执行消费者(订单服务)本地事务逻辑,也就是生成订单流水号的事务逻辑
该事务逻辑将返回一个事务状态,当返回CIMMIT 状态时表示提交RQ消息,库存服务将消费回退库存消息
当返回ROLLBACK状态时,表示取消提交RQ消息, 库存服务将不会执行回滚操作
当事务逻辑代码异常时,将返回UNKONW状态,这时RQ将回调执行消费者事先写好的回调检查方法,回调检查方法将再次确认事务状态
下单流程中,回调检查方法就是查询订单服务库中的订单流水号是否生成,如果生成就返回ROLLBACK 不执行库存回滚,如果未生成就返回COMMIT执行回滚
如果回调检查代码异常,或者主动返回的是UNKONW 状态,RQ将默认每隔30s回调一次检查方法确认状态,直至接收到COMMIT或者ROLLBACK状态,最多持续12小时
-
订单服务需要准备两个回调方法:
- 本地执行生成订单流水号事务逻辑方法
- 回调检查事务状态方法
订单服务在发送完事务消息后,就不需要执行其他逻辑,在本地阻塞看是否正常生成流水号就行(这里为了简单就直接使用了一个全局变量来确认变量是否生成)
流程图

订单服务伪代码
class OrderService: def check_callback(self, msg): """ RQ 回调检查方法: 查询订单流水号是否生成,生成表示订单已入库无需库存回滚,构造库存回滚 """ # 解析RQ 回调的消息内容,获取对应订单号 msg_body = json.loads(msg.body.decode("utf-8")) order_sn = msg_body["orderSn"] # 查询本地数据库 看一下order_sn的订单是否已经入库了 orders = OrderInfo.select().where(OrderInfo.order_sn == order_sn) if orders: return TransactionStatus.ROLLBACK else: return TransactionStatus.COMMIT def local_execute(self, msg): """ 下单业务逻辑 1. 查询购物车记录 2. 获取需要下单的购物车商品信息 3. 扣减库存 4. 创建订单流水号 """ # 下单的整个流程都必选保证在同一个数据库事务中 with DB.session() as txn: # 获取购物车中需要下单的商品记录 # 如果没有获取到表示没有需要下单的的商品 # 因为还没有执行扣减库存的逻辑,所以这里直接返回RQ ROLLBACK(无需库存回滚) goods_ids = ShoppingCart.get_goods_ids() if not goods_ids: return TransactionStatus.ROLLBACK # 调用商品服务查询商品的信息 # 这一步也还没有执行扣减库存的逻辑,所以当获取商品信息异常时,直接返回ROLLBACK try: res = GoodsService.get_goods_info(goods_ids) goods_infos = res.goods_infos if not goods_infos: return TransactionStatus.ROLLBACK except Exception: print('获取商品信息失败') return TransactionStatus.ROLLBACK # 扣减库存 # 扣减库存异常需要异常类型,判断库存是否已经扣除 # 如果异常发生在扣除之前,不需要回滚,如果异常发生在扣除之后需要回滚 try: res = InvService.Sell(goods_infos) if res.err == '扣除库存前库存服务发生异常': return TransactionStatus.ROLLBACK elif res.err == '扣除库存后库存服务发生异常': return TransactionStatus.COMMIT except Exception: print('扣减库存异常') return TransactionStatus.ROLLBACK # 创建订单 # 生成订单流水号,并且同步本地下单事务逻辑执行结果 # 订单流水号生成成功后,发送订单超时延时消息 try: order_sn = OrderService.create_order_sn() local_execute_dict.order_sn = order_sn # 发送延时消息 msg = Message("order_timeout") msg.set_delay_time_level(5) # 设置为超时时间1min msg.set_keys("imooc") msg.set_tags("cancel") msg.set_body(json.dumps({"orderSn": order_sn})) sync_producer = Producer("cancel") # 此处的groupid不能和之前的重复 sync_producer.set_name_server_address(f"{settings.ROCKETMQ_HOST}:{settings.ROCKETMQ_PORT}") sync_producer.start() ret = sync_producer.send_sync(msg) if ret.status != SendStatus.OK: raise Exception("发送延时消息失败") print(f"发送时间:{datetime.now()}") sync_producer.shutdown() except Exception: # 生成订单流水号失败,订单服务数据库回滚 # 提交库存回滚 txn.rollback() local_execute_dict.order_sn.status = FAILED return TransactionStatus.COMMIT return TransactionStatus.ROLLBACK def create_order(self, request): """ 下单流程, 这里使用RQ发送事务消息的方式,下单业务逻辑写在回调本地执行代码中 1. 实例化一个发送RQ生产者 2. 发送事务消息 3. 阻塞获取本地事务执行结果返回 """ # 实例化一个RQ生产者 producer = TransactionMQProducer("mxshop", self.check_callback) # 构造需要发送的消息, 基本订单信息 order_sn = generate_order_sn(request.userId) msg_body = { "orderSn": order_sn, "userId": request.userId, "address": request.address, "name": request.name, "mobile": request.mobile, "post": request.post } msg.set_body(json.dumps(msg_body)) # 发送半事务消息 ret = producer.send_message_in_transaction(msg, self.local_execute, user_args=None) # 检查半事务消息是否发送成功 if ret.status != OK: print('生成订单失败') return # 阻塞获取本地执行事务逻辑结果 while True: if order_sn in local_execute_dict: # 如果订单流水号生成,表示本地事务逻辑执行完毕,关闭RQ生产者 producer.shutdown() # 判断订单流水号状态,返回下单结果 if local_execute_dict.order_sn.status == OK: print('下单成功') else: print('下单失败') time.sleep(0.1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
最大努力通知
最大努力通知也是一种解决分布式事务的方案,下边是一个是充值的例子:
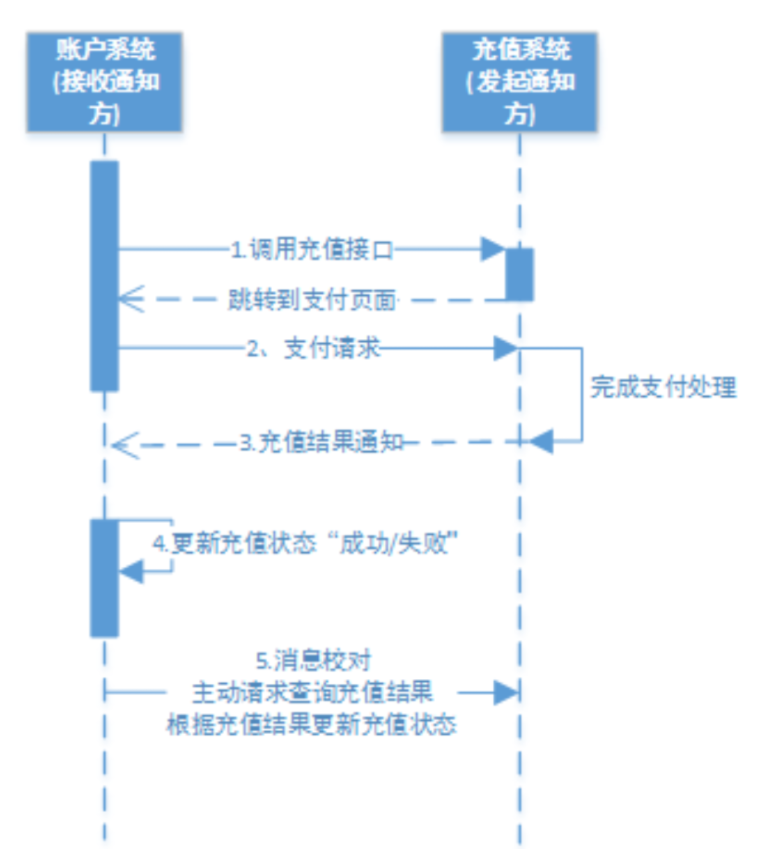
交互流程
- 账户系统调用充值系统接口
- 充值系统完成支付处理向账户系统发起充值结果通知,若通知失败,则充值系统按策略进行重复通知
- 账户系统接收到充值结果通知修改充值状态。
- 账户系统未接收到通知会主动调用充值系统的接口查询充值结果。
目标
发起通知方通过一定的机制最大努力将业务处理结果通知到接收方。
具体包括:
- 有一定的消息重复通知机制。因为接收通知方可能没有接收到通知,此时要有一定的机制对消息重复通知。
- 消息校对机制。如果尽最大努力也没有通知到接收方,或者接收方消费消息后要再次消费,此时可由接收方主动向通知方查询消息信息来满足需求。
最大努力通知与可靠消息一致性有什么不同?
- 解决方案思想不同
- 可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发到接收通知方,消息的可靠性关键由发起通知方来保证。
- 最大努力通知,发起通知方尽最大的努力将业务处理结果通知为接收通知方,但是可能消息接收不到,此时需要接收通知方主动调用发起通知方的接口查询业务处理结果,通知的可靠性关键在接收通知方。
- 两者的业务应用场景不同
- 可靠消息一致性关注的是交易过程的事务一致,以异步的方式完成交易。
- 最大努力通知关注的是交易完成事后的通知事务,即将交易结果可靠的通知出去。
- 技术解决方向不同
- 可靠消息一致性要解决消息从发出到接收的一致性,即消息发出并且被接收到。
- 最大努力通知无法保证消息从发出到接收的一致性,只提供消息接收的可靠性机制。可靠机制是,最大努力的将消息通知给接收方,当消息无法被接收方接收时,由接收方主动查询消息(业务处理结果)。
解决方案
通过对最大努力通知的理解,采用MQ的ack机制就可以实现最大努力通知:
-
方案1 利用MQ的ack机制由MQ向接收通知方发送通知:

-
发起通知方将通知发给MQ。使用普通消息机制将通知发给MQ。
如果消息没有发出去可由接收通知方主动请求发起通知方查询业务执行结果。
-
接收通知方监听 MQ。
-
接收通知方接收消息,业务处理完成回应ack。
-
接收通知方若没有回应ack则MQ会重复通知。
MQ会按照间隔1min、5min、10min、30min、1h、2h、5h、10h的方式,逐步拉大通知间隔 (如果MQ采用rocketMq,在broker中可进行配置),直到达到通知要求的时间窗口上限。
-
接收通知方可通过消息校对接口来校对消息的一致性。
-
-
方案2 利用MQ的ack机制,与方案1不同的是应用程序向接收通知方发送通知:
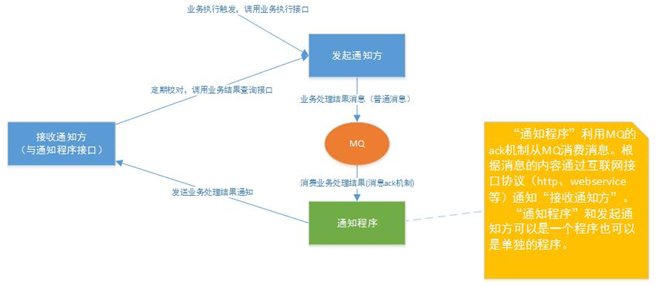
-
发起通知方将通知发给MQ
使用可靠消息一致方案中的事务消息保证本地事务与消息的原子性,最终将通知先发给MQ。
-
通知程序监听 MQ,接收MQ的消息。
方案1中接收通知方直接监听MQ,方案2中由通知程序监听MQ。
通知程序若没有回应ack则MQ会重复通知。
-
通知程序通过互联网接口协议(如http、webservice)调用接收通知方案接口,完成通知。
通知程序调用接收通知方案接口成功就表示通知成功,即消费MQ消息成功,MQ将不再向通知程序投递通知消息。
-
接收通知方可通过消息校对接口来校对消息的一致性。
-
-
方案1主要是应用于内部应用之间通知
方案2 主要是外部应用之间的通知,例如支付宝、微信的支付结果通知
消息队列在微服务中的作用和选型
什么是mq
消息队列是一种“先进先出”的数据结构

应用场景(优点)
-
应用解耦:
解耦前系统交互流程:
解耦后系统交互流程:

优点:
当消费者系统发生故障后,可能需要几分钟来修复,这段时间内,消费者系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成。
当故障系统恢复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到故障时间。
-
流量削峰
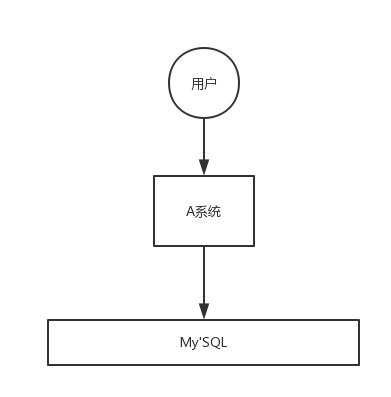
应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮。有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提到系统的稳定性和用户体验。
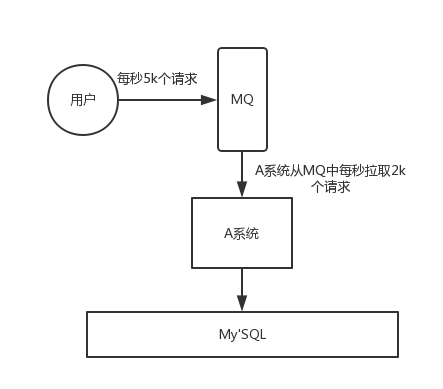
一般情况,为了保证系统的稳定性,如果系统负载超过阈值,就会阻止用户请求,这会影响用户体验,而如果使用消息队列将请求缓存起来,等待系统处理完毕后通知用户下单完毕,这样总不能下单体验要好。
处于经济考量目的:
业务系统正常时段的QPS如果是1000,流量最高峰是10000,为了应对流量高峰配置高性能的服务器显然不划算,这时可以使用消息队列对峰值流量削
-
数据分发
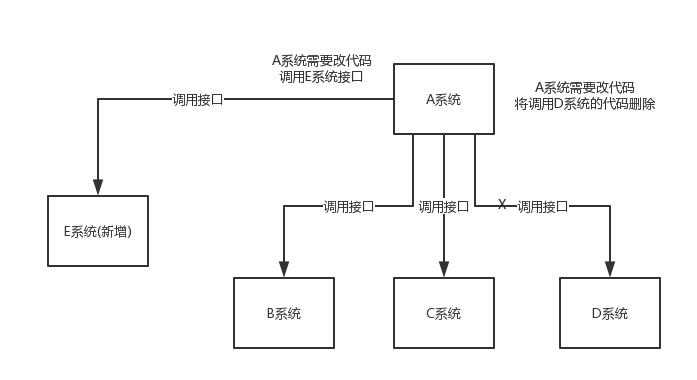
通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可。
缺点
-
系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。
如何保证MQ的高可用? -
系统复杂度提高
MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。
如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性? -
一致性问题
A系统处理完业务,通过MQ给B、C、D三个系统发消息数据,如果B系统、C系统处理成功,D系统处理失败。
如何保证消息数据处理的一致性?
mq 技术选型
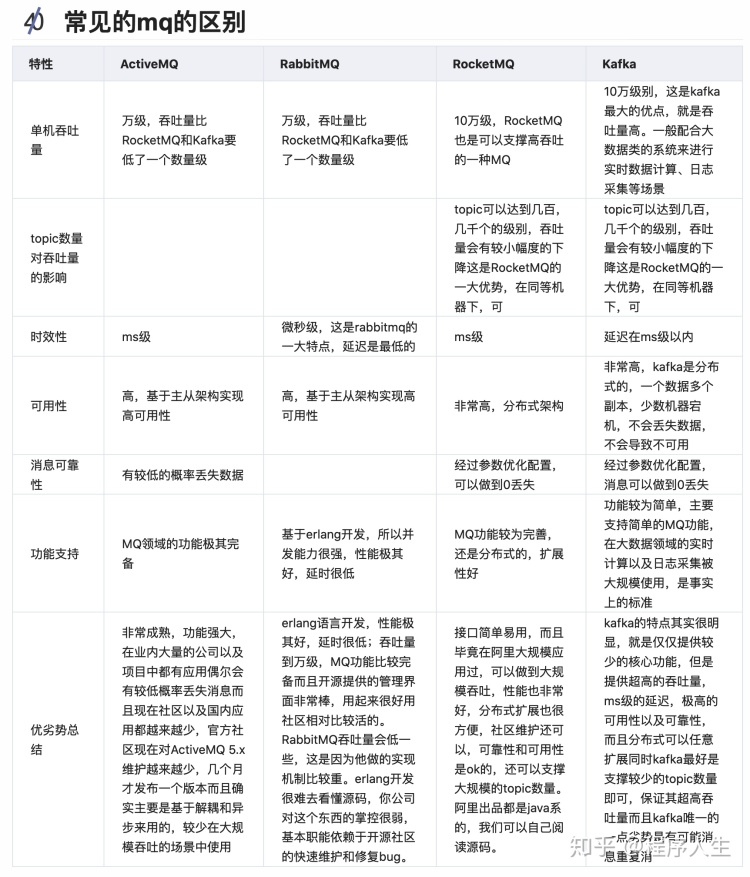
结论:
(1)中小型软件公司,建议选RabbitMQ.一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便。正所谓,成也萧何,败也萧何!他的弊端也在这里,虽然RabbitMQ是开源的,然而国内有几个能定制化开发erlang的程序员呢?所幸,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug,这点对于中小型公司来说十分重要。不考虑rocketmq和kafka的原因是,一方面中小型软件公司不如互联网公司,数据量没那么大,选消息中间件,应首选功能比较完备的,所以kafka排除。但是rocketmq已经交给apache管理,所以rocketmq的未来发展趋势看好。
(2)大型软件公司,根据具体使用在rocketMq和kafka之间二选一。一方面,大型软件公司,具备足够的资金搭建分布式环境,也具备足够大的数据量。针对rocketMQ,大型软件公司也可以抽出人手对rocketMQ进行定制化开发,毕竟国内有能力改JAVA源码的人,还是相当多的。至于kafka,根据业务场景选择,如果有日志采集功能,肯定是首选kafka了。具体该选哪个,看使用场景。
幂等性机制
背景
不符合幂等性案例场景
- 扫码支付的时候,扫完码并且支付了,但是由于网络问题,当前页面一直没有刷新,用户以为没有支付,就再次扫码支付,完蛋:扣除两次钱
- 用户添加购物车数量,点击加一,原本的值从10变为11,但是返回的时候由于网络抖动,触发服务的重试机制导致第二次发送,从11变为12, 返回的时候网络再次抖动,再次触发重试机制从12变为13。。。
不同请求方法的幂等性
- GET请求:查询请求一般都符合幂等性设计,即使由于网络问题导致多次查询,结果也是正确的
- POST请求:
该请求方法涉及到更新或者添加数据,服务端接口和代码很容易设计的不符合幂等性,在涉及到重要的逻辑时,一定要考虑意外情况多次重复提交请求会造成什么样的结果
- PUT 请求:
指定值更新:这种指定值更新的方式符合幂等性操作,即使多次请求,但是最终结果是正确的
累加更新:不指定值,而是请求一次更新一点,是不符合幂等性的
- DELETE 请求:
符合幂等性的请求方式,删除同一个最终效果一样
幂等性概念
- 幂等性是数学与计算机的一个抽象概念,常用语抽象代数中
- 对于开发人员来说,幂等特点就是任意多次执行所产生的影响均与一次执行的影响相同
幂等函数,幂等方法:指相同参数,重复执行多次,结果相同
- 简单来说,幂等就是不论执行多少次,产生的效果和返回的结果都是一样的
技术方案
删除和查询操作一般都是符合幂等性操作的,我们需要在更新和插入操作的时候设计出符合幂等性的接口
虽然有多种设计幂等性接口的方式,比如说唯一索引确定、token 机制、锁机制等,但是它们的本质都是一样的:
那就是通过唯一确定值来保证此次更新或者插入是正确的,而这个唯一确定值,需要根据我们服务的设计(单机服务还是分布式服务),以及具体的业务场景来决定
-
唯一索引,防止新增脏数据
新建用户的时候 将手机号设置为唯一索引,那么即使重试,也只会新建一个用户,不会因为重试导致当前用户注册了两个用户
- 唯一索引或者唯一联合索引,可以防止新增数据存在脏数据
-
token 机制,防止重复提交
业务要求:
页面的数据只能被点击提交一次
发生原因:
由于重复提交或者网络重试,或者nginx 重发等情况导致数据被重复提交
解决方法:
采用token 加 redis (redis单线程,处理需要排队)
- 数据提交前向服务申请token,token保存在内存或者redis 中
- 数据提交至后台后,后台校验token, 同时删除token,生成新的token 返回
在使用redis 保存token的时候,可以直接通过删除redis 的token 来判断,删除成功表示token校验通过,如果使用 elect+delete 来校验token 存在并发问题
token 特点:
要申请,一次有效性,可以限流
-
悲观锁
获取数据的时候加锁获取
select * from table_xxx where id=‘xxx’ for update;**注意:id字段一定是主键或者唯一索引,不然是锁表,会死人的
**悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用关于悲观锁使用的详细介绍:https://blog.csdn.net/claram/article/details/54023216
-
乐观锁
乐观锁只是在更新数据那一刻锁表,其他时间不锁表,所以相对于悲观锁,效率更高。
乐观锁的实现方式多种多样可以通过version或者其他状态
- 通过版本号实现
update table_xxx set name=#name#,version=version+1 where version=#version#
如下图(来自网上):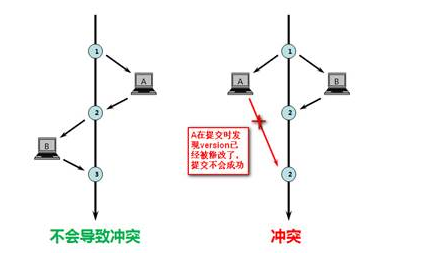
- 通过条件限制
update table_xxx set avai_amount=avai_amount-#subAmount# where avai_amount-#subAmount# >= 0
要求:quality-#subQuality# >= ,这个情景适合不用版本号,只更新是做数据安全校验,适合库存模型,扣份额和回滚份额,性能更高
注意:乐观锁的更新操作,最好用主键或者唯一索引来更新,这样是行锁,否则更新时会锁表,上面两个sql改成下面的两个更好
pdate table_xxx set name=#name#,version=version+1 where id=#id# and version=#version#
update table_xxx set avai_amount=avai_amount-#subAmount# where id=#id# and avai_amount-#subAmount# >= 0 -
分布式锁
还是拿插入数据的例子,如果是分布是系统,构建全局唯一索引比较困难,例如唯一性的字段没法确定,这时候可以引入分布式锁,通过第三方的系统(redis或zookeeper),在业务系统插入数据或者更新数据,获取分布式锁,然后做操作,之后释放锁,这样其实是把多线程并发的锁的思路,引入多多个系统,也就是分布式系统中得解决思路。
要点:某个长流程处理过程要求不能并发执行,可以在流程执行之前根据某个标志(用户ID+后缀等)获取分布式锁,其他流程执行时获取锁就会失败,也就是同一时间该流程只能有一个能执行成功,执行完成后,释放分布式锁(分布式锁要第三方系统提供)
-
select + insert
并发不高的后台系统,或者一些任务JOB,为了支持幂等,支持重复执行,简单的处理方法是,先查询下一些关键数据,判断是否已经执行过,在进行业务处理,就可以了
注意:核心高并发流程不要用这种方法
-
-
对外提供接口的api如何保证幂等
如银联提供的付款接口:需要接入商户提交付款请求时附带:source来源,seq序列号
source+seq在数据库里面做唯一索引,防止多次付款,(并发时,只能处理一个请求)
**重点:
** 对外提供接口为了支持幂等调用,接口有两个字段必须传,一个是来源source,一个是来源方序列号seq,这个两个字段在提供方系统里面做联合唯一索引,这样当第三方调用时,先在本方系统里面查询一下,是否已经处理过,返回相应处理结果;没有处理过,进行相应处理,返回结果。注意,为了幂等友好,一定要先查询一下,是否处理过该笔业务,不查询直接插入业务系统,会报错,但实际已经处理了。
RocketMQ
安装和配置
docker-compose 文件
-
JAVA_OPT_EXT 为设置服务启动需要的最小内存,根据实际情况配置
version: '3.5' services: rmqnamesrv: image: foxiswho/rocketmq:server container_name: rmqnamesrv ports: - 9876:9876 volumes: - ./logs:/opt/logs - ./store:/opt/store networks: rmq: aliases: - rmqnamesrv rmqbroker: image: foxiswho/rocketmq:broker container_name: rmqbroker ports: - 10909:10909 - 10911:10911 volumes: - ./logs:/opt/logs - ./store:/opt/store - ./conf/broker.conf:/etc/rocketmq/broker.conf environment: NAMESRV_ADDR: "rmqnamesrv:9876" JAVA_OPTS: " -Duser.home=/opt" JAVA_OPT_EXT: "-server -Xms256m -Xmx256m -Xmn256m" command: mqbroker -c /etc/rocketmq/broker.conf depends_on: - rmqnamesrv networks: rmq: aliases: - rmqbroker rmqconsole: image: styletang/rocketmq-console-ng container_name: rmqconsole ports: - 8080:8080 environment: JAVA_OPTS: "-Drocketmq.namesrv.addr=rmqnamesrv:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false" depends_on: - rmqnamesrv networks: rmq: aliases: - rmqconsole networks: rmq: name: rmq driver: bridge- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
broker conf 文件
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # 所属集群名字 brokerClusterName=DefaultCluster # broker 名字,注意此处不同的配置文件填写的不一样,如果在 broker-a.properties 使用: broker-a, # 在 broker-b.properties 使用: broker-b brokerName=broker-a # 0 表示 Master,> 0 表示 Slave brokerId=0 # nameServer地址,分号分割 # namesrvAddr=rocketmq-nameserver1:9876;rocketmq-nameserver2:9876 # 启动IP,如果 docker 报 com.alibaba.rocketmq.remoting.exception.RemotingConnectException: connect to <192.168.0.120:10909> failed # 解决方式1 加上一句 producer.setVipChannelEnabled(false);,解决方式2 brokerIP1 设置宿主机IP,不要使用docker 内部IP brokerIP1=127.0.0.1 # 在发送消息时,自动创建服务器不存在的topic,默认创建的队列数 defaultTopicQueueNums=4 # 是否允许 Broker 自动创建 Topic,建议线下开启,线上关闭 !!!这里仔细看是 false,false,false autoCreateTopicEnable=true # 是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭 autoCreateSubscriptionGroup=true # Broker 对外服务的监听端口 listenPort=10911 # 删除文件时间点,默认凌晨4点 deleteWhen=04 # 文件保留时间,默认48小时 fileReservedTime=120 # commitLog 每个文件的大小默认1G mapedFileSizeCommitLog=1073741824 # ConsumeQueue 每个文件默认存 30W 条,根据业务情况调整 mapedFileSizeConsumeQueue=300000 # destroyMapedFileIntervalForcibly=120000 # redeleteHangedFileInterval=120000 # 检测物理文件磁盘空间 diskMaxUsedSpaceRatio=88 # 存储路径 # storePathRootDir=/home/ztztdata/rocketmq-all-4.1.0-incubating/store # commitLog 存储路径 # storePathCommitLog=/home/ztztdata/rocketmq-all-4.1.0-incubating/store/commitlog # 消费队列存储 # storePathConsumeQueue=/home/ztztdata/rocketmq-all-4.1.0-incubating/store/consumequeue # 消息索引存储路径 # storePathIndex=/home/ztztdata/rocketmq-all-4.1.0-incubating/store/index # checkpoint 文件存储路径 # storeCheckpoint=/home/ztztdata/rocketmq-all-4.1.0-incubating/store/checkpoint # abort 文件存储路径 # abortFile=/home/ztztdata/rocketmq-all-4.1.0-incubating/store/abort # 限制的消息大小 maxMessageSize=65536 # flushCommitLogLeastPages=4 # flushConsumeQueueLeastPages=2 # flushCommitLogThoroughInterval=10000 # flushConsumeQueueThoroughInterval=60000 # Broker 的角色 # - ASYNC_MASTER 异步复制Master # - SYNC_MASTER 同步双写Master # - SLAVE brokerRole=ASYNC_MASTER # 刷盘方式 # - ASYNC_FLUSH 异步刷盘 # - SYNC_FLUSH 同步刷盘 flushDiskType=ASYNC_FLUSH # 发消息线程池数量 # sendMessageThreadPoolNums=128 # 拉消息线程池数量 # pullMessageThreadPoolNums=128- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
基本概念
- Producer:消息的发送者;举例:发信者
- Consumer:消息接收者;举例:收信者
- Broker:暂存和传输消息;举例:邮局
- NameServer:管理Broker;举例:各个邮局的管理机构
- Topic:区分消息的种类;一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息
- Message Queue:相当于是Topic的分区;用于并行发送和接收消息
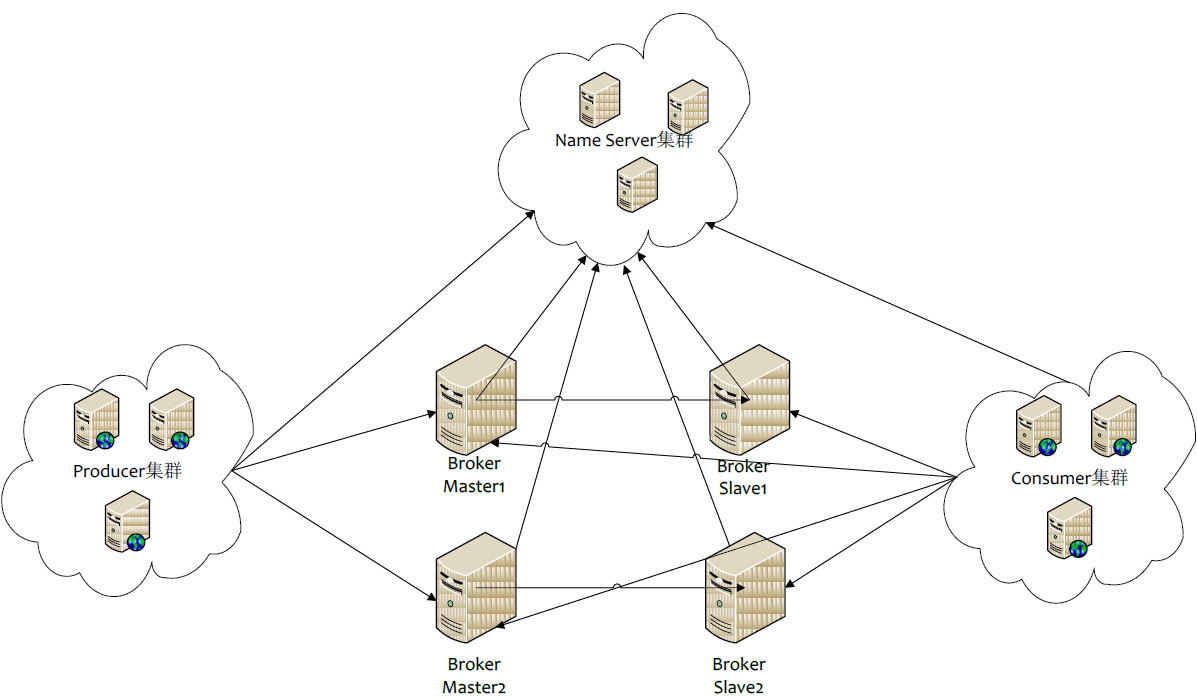
消息类型
按照发送的特点区分:
-
同步发送
-
同步发送,线程阻塞,投递completes阻塞结束
-
如果发送失败,会在默认的超时时间3秒内进行重试,最多重试2次
-
投递completes不代表投递成功,要check SendResult.sendStatus来判断是否投递成功
-
SendResult里面有发送状态的枚举:SendStatus,同步的消息投递有一个状态返回值的
public enum SendStatus { SEND_OK, FLUSH_DISK_TIMEOUT, FLUSH_SLAVE_TIMEOUT, SLAVE_NOT_AVAILABLE, }- 1
- 2
- 3
- 4
- 5
- 6
-
retry的实现原理:只有ack的SendStatus=SEND_OK才会停止retry
注意事项:发送同步消息且Ack为SEND_OK,只代表该消息成功的写入了MQ当中,并不代表该消息成功的被Consumer消费了
-
-
异步发送
- 异步调用的话,当前线程一定要等待异步线程回调结束再关闭producer啊,因为是异步的,不会阻塞,提前关闭producer会导致未回调链接就断开了
- 异步消息不retry,投递失败回调onException()方法,只有同步消息才会retry,源码参考 DefaultMQProducerImpl.class
- 异步发送一般用于链路耗时较长,对 RT 响应时间较为敏感的业务场景,例如用户视频上传后通知启动转码服务,转码完成后通知推送转码结果等。
-
单向发送
- 消息不可靠,性能高,只负责往服务器发送一条消息,不会重试也不关心是否发送成功
- 此方式发送消息的过程耗时非常短,一般在微秒级别
按照使用功能特点分
-
普通消息(订阅)
普通消息是我们在业务开发中用到的最多的消息类型,生产者需要关注消息发送成功即可,消费者消费到消息即可,不需要保证消息的顺序,所以消息可以大规模并发地发送和消费,吞吐量很高,适合大部分场景。
-
顺序消息
顺序消息分为分区顺序消息和全局顺序消息,全局顺序消息比较容易理解,也就是哪条消息先进入,哪条消息就会先被消费,符合我们的FIFO,很多时候全局消息的实现代价很大,所以就出现了分区顺序消息。分区顺序消息的概念可以如下图所示:
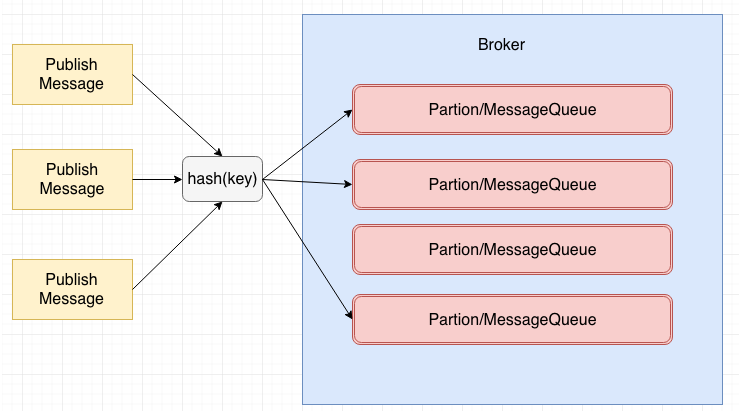
我们通过对消息的key,进行hash,相同hash的消息会被分配到同一个分区里面,当然如果要做全局顺序消息,我们的分区只需要一个即可,所以全局顺序消息的代价是比较大的。
-
延时消息 - 订单超时库存归还
延迟的机制是在 服务端实现的,也就是Broker收到了消息,但是经过一段时间以后才发送
服务器按照1-N定义了如下级别: “1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”;若要发送定时消息,在应用层初始化Message消息对象之后,调用Message.setDelayTimeLevel(int level)方法来设置延迟级别,按照序列取相应的延迟级别,例如level=2,则延迟为5s
msg.setDelayTimeLevel(2); SendResult sendResult = producer.send(msg);- 1
- 2
实现原理:
- 发送消息的时候如果消息设置了DelayTimeLevel,那么该消息会被丢到ScheduleMessageService.SCHEDULE_TOPIC这个Topic里面
- 根据DelayTimeLevel选择对应的queue
- 再把真实的topic和queue信息封装起来,set到msg里面
- 然后每个SCHEDULE_TOPIC_XXXX的每个DelayTimeLevelQueue,有定时任务去刷新,是否有待投递的消息
- 每 10s 定时持久化发送进度
-
事务消息
阿里云官方文档
https://help.aliyun.com/document_detail/43348.html?spm=a2c4g.11186623.2.16.78ee6192siK1qV#concept-2047067
python操作RQ
安装python rq client
https://github.com/apache/rocketmq-client-python
需要注意 rocketmq-client-cpp 需要安装2.1.0 版本的,2.0.0版本的有回调检查有bug
- 发送普通消息
producer
from rocketmq.client import Producer, Message topic = "TopicTest" def create_message(): msg = Message(topic) msg.set_keys("imooc") msg.set_tags('bobby') msg.set_property("name", "micro services") msg.set_body("微服务开发") return msg def send_message_sync(count): producer = Producer("zhouzy1_test") producer.set_name_server_address("192.168.146.189:9876") #首先要启动producer producer.start() for n in range(count): msg = create_message() ret = producer.send_sync(msg) print(f"发送状态:{ret.status}, 消息id:{ret.msg_id}") print("消息发送完成") producer.shutdown() if __name__ == "__main__": #发送普通消息 send_message_sync(5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
consumer
from rocketmq.client import PushConsumer, ConsumeStatus import time topic = "TopicTest" def callback(msg): print(msg.id, msg.body.decode("utf-8"), msg.get_property("name")) return ConsumeStatus.CONSUME_SUCCESS def start_consume_message(): consumer = PushConsumer("python_consumer") consumer.set_name_server_address("192.168.146.189:9876") consumer.subscribe(topic, callback) print("开始消费消息") consumer.start() while True: time.sleep(3600) consumer.shutdown() if __name__ == "__main__": start_consume_message()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
-
发送延时消息
producer
在生产者中设置set_delay_time_level 即可发送延时消息
rq的延时消息的延时时间是规定的,有以下几个级别:
1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
这里设置的 2 代表的是延时5s
- 当生产者发送延时消息后,消费者在消费消息的时候就会延迟消费
一般用于需要倒计时处理的业务场景,比如说订单超时:
在生产订单时,就生产一个延时的订单超时消息,当延时时间到了后消费者就会消费超时订单消息,开始处理超时订单
from rocketmq.client import Producer, Message topic = "TopicTest" #延迟消息 def create_message(): msg = Message(topic) msg.set_keys("imooc") msg.set_tags('延时消息') msg.set_delay_time_level(2) #1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h msg.set_property("name", "延时消息") msg.set_body("微服务开发") return msg def send_message_sync(count): producer = Producer("zhouzy1_test") producer.set_name_server_address("192.168.146.189:9876") #首先要启动producer producer.start() for n in range(count): msg = create_message() ret = producer.send_sync(msg) print(f"发送状态:{ret.status}, 消息id:{ret.msg_id}") print("消息发送完成") producer.shutdown() if __name__ == "__main__": #发送普通消息 send_message_sync(5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
-
发送事务消息
阿里官方文档
https://help.aliyun.com/document_detail/43348.html
事务消息发送步骤如下:
-
生产者将半事务消息发送至消息队列RocketMQ版服务端。
-
消息队列RocketMQ版服务端将消息持久化成功之后,向生产者返回Ack确认消息已经发送成功,此时消息为半事务消息。
-
生产者开始执行本地事务逻辑。
-
生产者根据本地事务执行结果向服务端提交二次确认结果(Commit或是Rollback),服务端收到确认结果后处理逻辑如下:
- 二次确认结果为Commit:服务端将半事务消息标记为可投递,并投递给消费者。
- 二次确认结果为Rollback:服务端将回滚事务,不会将半事务消息投递给消费者。
-
在断网或者是生产者应用重启的特殊情况下,若服务端未收到发送者提交的二次确认结果,或服务端收到的二次确认结果为Unknown未知状态,经过固定时间后,服务端将对消息生产者即生产者集群中任一生产者实例发起消息回查。
事务消息回查步骤如下:
- 生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 生产者根据检查得到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半事务消息进行处理
python代码实现
-
按照rq的事务消息设置, 生产者在成功发送完半事务消息后,就需要开始执行本地业务代码,当本地业务代码执行失败的时候,就需要告诉 rq 取消投递消息
因此生产者在实例化的时候需要一个回调检查的方法check_callback,用于当本地业务代码执行异常的时候,回调确认事务状态
from rocketmq.client import TransactionMQProducer, Message, TransactionStatus import time topic = "TopicTest" def create_message(id): msg = Message(topic) msg.set_keys("zhouzy1") msg.set_tags('事务消息') msg.set_property("name", "micro services") msg.set_property("id", id) msg.set_body("测试发送事务消息") return msg def check_callback(msg): # 用于rq 二次回调检查生产者事务状态,以确认接下来是否投递消息给消费者 # 当二次检查的状态为 COMMIT 的时候,消费者将成功消费 # 当二次检查的状态为 ROLLBACK 的时候,将取消投递消息 # 当二次检查的状态为 UNKNOWN 时,等待一定时间后(rq 默认为30s)继续回调查询事务状态 # 最多回调12小时 print(f"事务消息回查:{msg.body.decode('utf-8')}") return TransactionStatus.COMMIT def local_execute(msg, user_args): # 生产者本地业务逻辑代码,此处模拟业务逻辑代码执行状态为 UNKNOWN 状态(未知异常) # 这样rq 就会回调检查check_callback方法二次确认事务状态 # 当本地业务逻辑代码为 ROLLBACK 或者 COMMIT 时 rq 就不会执行回调检查事务状态 print("执行本地业务逻辑代码") return TransactionStatus.UNKNOWN def send_transaction_message(count): # 在实例化事务消息生产者的时候,必须传递一个二次回调检查的方法 producer = TransactionMQProducer("test", check_callback) producer.set_name_server_address("192.168.146.189:9876") import uuid id = str(uuid.uuid4()) #首先要启动producer producer.start() for n in range(count): msg = create_message(id) # 这里发送消息和生产者执行本地业务代码是异步的 # 因此这里需要传递本地业务逻辑的方法作为参数 ret = producer.send_message_in_transaction(msg, local_execute, None) print(f"发送状态:{ret.status}, 消息id:{ret.msg_id}") print("消息发送完成") while True: time.sleep(3600) if __name__ == "__main__": #发送事务消息 send_transaction_message(1) msg = Message(topic) msg.set_keys("zhouzy1") msg.set_tags('事务消息') msg.set_property("name", "micro services") msg.set_property("id", id) msg.set_body("测试发送事务消息") return msg def check_callback(msg): # 用于rq 二次回调检查生产者事务状态,以确认接下来是否投递消息给消费者 # 当二次检查的状态为 COMMIT 的时候,消费者将成功消费 # 当二次检查的状态为 ROLLBACK 的时候,将取消投递消息 # 当二次检查的状态为 UNKNOWN 时,等待一定时间后(rq 默认为30s)继续回调查询事务状态 # 最多回调12小时 print(f"事务消息回查:{msg.body.decode('utf-8')}") return TransactionStatus.COMMIT def local_execute(msg, user_args): # 生产者本地业务逻辑代码,此处模拟业务逻辑代码执行状态为 UNKNOWN 状态(未知异常) # 这样rq 就会回调检查check_callback方法二次确认事务状态 # 当本地业务逻辑代码为 ROLLBACK 或者 COMMIT 时 rq 就不会执行回调检查事务状态 print("执行本地业务逻辑代码") return TransactionStatus.UNKNOWN def send_transaction_message(count): # 在实例化事务消息生产者的时候,必须传递一个二次回调检查的方法 producer = TransactionMQProducer("test", check_callback) producer.set_name_server_address("192.168.146.189:9876") import uuid id = str(uuid.uuid4()) #首先要启动producer producer.start() for n in range(count): msg = create_message(id) # 这里发送消息和生产者执行本地业务代码是异步的 # 因此这里需要传递本地业务逻辑的方法作为参数 ret = producer.send_message_in_transaction(msg, local_execute, None) print(f"发送状态:{ret.status}, 消息id:{ret.msg_id}") print("消息发送完成") while True: time.sleep(3600) if __name__ == "__main__": #发送事务消息 send_transaction_message(1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
-
相关阅读:
docker搭建本地仓库
28线性空间02—— 坐标变换
Linux网络编程一(协议、TCP协议、UDP、socket编程、TCP服务器端及客户端)
json-server环境搭建
并发与并行,同步和异步,Go lang1.18入门精炼教程,由白丁入鸿儒,Go lang并发编程之GoroutineEP13
zoj 1377 Grandpa‘s Estate
javaweb高校实验室管理系统ssm
Mac解压缩软件BetterZip免费版注册码下载
深度学习Hotel-ID打击人口贩卖(1)项目介绍和数据预处理
水果店圈子:一家水果店要准备什么,开个水果店前期准备什么
- 原文地址:https://blog.csdn.net/qq_42586468/article/details/126452339
