-
建模杂谈系列155 从一段程序讨论通用的任务执行方法
说明
这篇是对实际操作中的一段程序进行分析,目的是使得这一类操作可以称为一个模板,这样以后所有的操作都会按这个模板走。
简单来说,是为了降本增效,属于自动化的内容。(某种定义上说,自动化也就是人工智能)
内容
1 Sample
先从一段实际的程序出发,里面有些数据库的操作使用对象进行了集成。反正数据库的操作默认ok,关键是看如何把这个操作模板化。
之所以选择这段程序是因为赶时间做完,所以很讲实际,追求成本最低的操作(至简)。在做的过程中发现,虽然程序语句上略有繁琐之处,但是在不同的段落之间是高度相似的(模板)。最后,整个过程非常顺利,没有任何出错(正确),说明是有效的。简单、正确、规范,正是我追求的。
这段代码的所用是将Buffer库中某个表的内容经过处理然后搬到OprLog库中的某个表。这个过程是在Mongo中发生的,中间有查询过Mysql。
然后再对Mysql中的某个表进行删除、插入。
最后对处理完成的记录(Record)进行回应(ACK)。
ktgg_read.set_a_index('Buffer', 'a_ent', idx_var='task_channel_001') ktgg_read.set_a_index('OprLog','a_result', idx_var='table_id' ) for i in tqdm.tqdm(range(1000)): # 1 起点;上个步骤的ent ent_recs = ktgg_read.query_recs('Buffer', 'a_ent', filter_dict = {'task_channel_001':{'$ne':2}} , limits = 3000) if len(ent_recs['data']): ent_recs_df = pd.DataFrame(ent_recs['data']) # 【处理】 # 2 查询对应的mid mid_recs = ktgg_read.query_recs('Buffer', 'a', filter_dict ={'id': {'$in': list(ent_recs_df['doc_id'])}}, keep_cols = ['id','mid'], limits = 10000, silent=True) mid_recs_df = pd.DataFrame(mid_recs['data']) mid_recs_dict = dict(zip(list(mid_recs_df['id']),list(mid_recs_df['mid']))) # 3 匹配数据并将现有数据整合 ent_recs_df['mid'] = ent_recs_df['doc_id'].map(mid_recs_dict) ent_recs_df['table_id'] = ent_recs_df['doc_id'] ent_recs_df['table_mid'] = ent_recs_df['mid'] ent_recs_df['ent_name'] = ent_recs_df['ORG_result'] + ',' + ent_recs_df['PER_result'] # 4 查询当前已有的数据 str_id_list = [str(x) for x in list(ent_recs_df['doc_id'])] already_recs = req.post(mysql.mysql_agent_host + 'exe_sql_plus/', json ={**mysql.mysql_cfg, 'sql':'select table_id, ent_name from result_a where table_id in (%s)' % ','.join(str_id_list)} ).json() already_recs_df = pd.DataFrame(already_recs['data'], columns = already_recs['data_cols']) already_recs_dict = dict(zip(list(already_recs_df['table_id']),list(already_recs_df['ent_name']))) ent_recs_df['before_ent_name'] = ent_recs_df['doc_id'].map(already_recs_dict) # 准备插入的缓存数据 buffer_recs = ent_recs_df[['table_id','table_mid','ent_name','create_time','before_ent_name']].to_dict(orient='records') filter_list = ent_recs_df[['table_id']].to_dict(orient='records') ktgg_read.rep_plus_recs('OprLog','a_result',filter_list=filter_list, attr_list= buffer_recs) # 回应 ktgg_read.update_attr('Buffer','a_ent', filter_list=[{'doc_id':{'$in':list(ent_recs_df['doc_id'])}}], attr_list=[{'task_channel_001':2}]) else: print('Done') break # ---- 段2 for i in range(1000): hd_recs_to_write = ktgg_read.query_recs('OprLog', 'a_result', filter_dict = {'task_channel_001':{'$ne':2}} , limits = 3000 ) if len(hd_recs_to_write['data']): hd_recs_to_write_df = pd.DataFrame(hd_recs_to_write['data']) del_id_list = list(hd_recs_to_write_df['table_id']) hd_insert_listofdict = hd_recs_to_write_df[['table_id','table_mid' ,'ent_name','create_time']].to_dict(orient='records') req.post(mysql.mysql_agent_host + 'del_id_set_recs/', json = {**mysql.mysql_cfg ,'table_name':'result_a', 'condition_list':None, 'id_dict':{'table_id':del_id_list}}).json() # 插入 req.post(mysql.mysql_agent_host + 'insert_recs/', json = {**mysql.mysql_cfg,'table_name':'result_a' ,'listofdict':hd_insert_listofdict}).json() # 进行ack ktgg_read.update_attr('OprLog','a_result', filter_list=[{'table_id':{'$in':del_id_list}}], attr_list=[{'task_channel_001':2}]) else: print('Done') break- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
2 抽象
2.0 处理状态
7个步骤,13个状态码值。
- 1 初始化 0
- 2 连通性 1,2
- 3 数据有无 3,4
- 4 数据合规 5,6
- 5 数据处理 7,8
- 6 数据缓存 9,10
- 7 数据交付 11,12
2.1 处理域
2.1.1 Porter
本次处理速度比较快,全部都集中在Mongo中处理。所以,可以认为一个工具对象的处理域都是在本地的高速局网(CN001)中处理的。从长久来来看,还需要一个搬运工 Porter。 搬运工的任务就是将要处理的数据拉到CN001,最后再将CN001中的数据送往目标。对应上面的程序:
这段说明
a_ent已经搬入了数据,所以工具对象才会设置索引。所以在实际处理时,Porter的工作被省略了。ktgg_read.set_a_index('Buffer', 'a_ent', idx_var='task_channel_001')- 1
而段2的那部分,实际也对应了部分Porter的搬出工作。出和入实际上非常重要,但是也是通用化程度最高的。需要注意的是Porter的“TCP”模式,以下图片是从这篇文章摘的,比较形象。

特别是在交付时,Porter向目标完成数据库操作时,并没有结束,要再进行一次查询,才会标记。最终数据的状态应该是11或12。11也意味着可以删除了。另外在操作时,有时是“先删后插”,有的时候是更新某个字段的。这些都可以模板化。

2.1.2 Buffer
承接流程
某个任务的名称是唯一的(最好是驼峰体, TaskName),在此基础之上会有若干处理流程,每个流程可以按自己的名称添加后缀。例如TaskName_p001_xxx。
一般一个数据处理总是可以分为少数几个大的流程,所以一个项目会生成若干个(一般不超过10)的流程表。
将一个项目的处理流程都放在一个Buffer里方便检查流程数据
这要求每个表都是“主表”,即:每条记录都有一个主键,即使在不同的流程表中,都可以用这个主键进行唯一索引。当需要检查某些记录的变化时,可以容易地从这些表把数据摘出来。例如观察rec_id为1的数据在不同的处理步骤后的情况。
some_rec_id step_name step_result 1 step001 这是第一步处理结果 1 step002 这是第二步处理结果 1 step003 这是第三步处理结果 
按月变换Buffer
为了避免Buffer一直增长,因此按照每个自然月创建新的Buffer库。对于Mongo来说,按照数据库来管理是比较好的,一旦删除可以完全释放存储空间。
Buffer的交接
启用新的Buffer库要注意老库的数据任务是否完成,因此在处理程序端除了会去读
Current Buffer之外,还会去读History Buffer,确保没有遗漏的任务。因为Buffer最终会删除,所以需要为Buffer维持一个统计主表(BufferStat)。在统计主表中会记录Buffer中每个表的记录数,任务状态等。
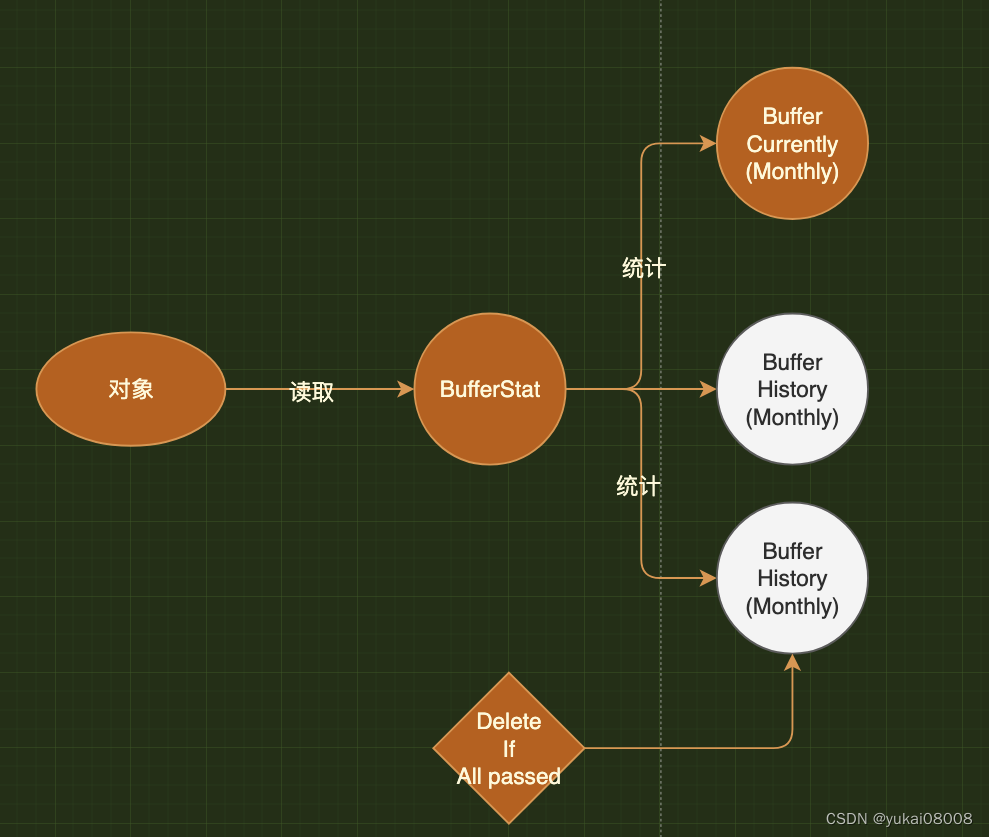
2.1.3 OprLog
确保交付
将要写入目标的数据放在OprLog中,这样如果发生写入失败,不需要再次进行计算。
OprLog还可以实现多空间(MVD)数据的应用,当我们希望迭代时,通常会进行一些分支探索。例如我们用新的方法来处理Step2, 此时产生数据可以称为
Step2 Master Fork1,那么处理流就可以略作改变,从而生成不同于原制程的处理方式。只要能够确保可以同时处理两个通路,那么就可以迭代了。
2.1.4 任务通道 task_channel_xxx(Multi Task)
同一条数据,会有多个处理任务
一类是基本的操作,例如IO。一条记录不会只有一种处理任务,很可能既要拷贝到A,也要拷贝到B,如果只有一个任务状态字段,就容易混乱,或者低效(做A任务时不能执行B任务)。
为了支持多任务处理,从表的角度上,会有多个列,这些列用来存放状态字段。形象点说,这些字段就是任务通道。为了节约字段,每条记录只允许存放一组任务的其他元数据:例如优先级,可领取时间等等。
对于任务状态来说,状态只有0,1,2,3。而数据对象的数据处理过程状态是0~12。任务状态是标记批次任务的,数据处理状态是标记在数据记录上。
需要注意的是"灰"的表达
例如有1万条数据,如果成功处理了9999条,我们怎么归类?或者反过来,如果一万条数据只成功处理了一条数据,错了9999,又怎么归类。
做一个简单的约定:在对象的处理流程中,总是"尽力执行"
所以在步骤的衔接过程中,总是通过过滤-执行的方式处理任务。每次都先过滤符合条件的数据,除非为空,否则就一直执行。只有当全部的数据都出问题(一条正确的都没有),那么我们会给对应的批次任务标记 “3”,否则总是2。此时2的准确含义是:批次处理产生了有用的结果,但是有可能包含了一些处理出错的数据。所以,一般会给每个Channel再加上一个表示“完成率”的字段。当我们发现某个批次的完成率低于1时才有必要去查看。
在查看问题数据时,我们可以通过数据库查询,将出现问题的数据揪出来,通过Data Status可以清楚的看到在不同的流程流转下数据出现的问题。
2.1.5 多种处理结果 MVD(MultiVerse Data)
上面已经简单的提到过MVD的概念,从存储上看,就是会有多个等效的平行集合。要使用好相对复杂一些,暂先简单的认为有多个版本的结果,使用时只取一个版本。
3 应用
3.1 数据节点
元数据存放的数据库集群。
序号 名字 解释 1 BatchTask 存放批量服务的库 2 WorkerLog 存放Worker日志的库 3 *BufferStat 统计各个Buffer的库 4 *IterTask 循环迭代任务 业务数据库
序号 名字 解释 1 Buffer_20xxxx 按年月自动生成的数据库 2 OprLog 暂存输出结果的库 3.2 方法
刚开始还是尽量简单点,方法就两类。一类是嗅探,结果会生成批次任务的元数据。一种是预计好的批次任务,还有一种是迭代任务。在手动情况下,嗅探可以跳过,直接放入一个批次数据。
另外一类是处理。从批次任务中获取对应的批次元数据,然后去提取对应的记录数据进行处理。在处理的过程中,要对:
- 1 任务元数据进行ACK
- 2 记录数据进行ACK
- 3 处理过程记录日志 Log
大致就现在这个层级,进行多一些的实践进行固化。尽量避免大结构设计变更,先进行完善,然后用起来。感觉差不多。
-
相关阅读:
C语言之输入(scanf)输出(printf)
求质数的方法
jxTMS设计思想之业务框架
【Shell】简单的交互式脚本
目标检测算法——医学图像开源数据集汇总(附下载链接)
品牌线上渠道管控,如何考察第三方控价公司
嵌入式分享合集101-PLC
MATLAB算法实战应用案例精讲-【回归算法】逐步式回归(Stepwise Regression)(附MATLAB、Java、Python和R语言代码)
深度学习人体语义分割在弹幕防遮挡上的实现 - python 计算机竞赛
成功解决note: This is an issue with the package mentioned above,not pip
- 原文地址:https://blog.csdn.net/yukai08008/article/details/126727572
