-
【21天算法学习】希尔排序
作者简介:
🍀姓姜,字君竹。
🍁浅薄观点:科以载文,文以载道
🌱软件技术升计科,计划考研
🌾要有最朴素的生活和最遥远的梦想,即使明日,天寒地冻,路遥马亡-
概念及介绍
希尔排序有称缩小增量排序,是直接插入排序的一种改进算法,更为高效。希尔排序的核心思想是先将数据进行分组,每个分组分别进行直接插入排序。待整个序列中的记录基本有序时,再对全体记录进行依次直接插入排序。
由于在前几次的分组和排序中,已经调整了元素的位置,所以最后一次的元素串位次数会大大减少。在分组的过程中,增量d不断变化,通常第一个增量的选需求不会超过n/2(这样每组中至少有两个元素),然后每次减半,知道增量为1。如果这样调节增量,则分组排序可以在不超过log2n的情况下完成操作。
与直接插入排序不同的是,每次分组排序后,整体序列更加接近有序,但是不产生有序区。在分组中的每次排序都是把较小的数尽量的往做测丢,因为组内的数据量较小,这样就能有效的减少数据串位的次数,在最后一次的调整时就可以减少数据的串位次数和串位距离。 -
时间空间复杂度
希尔排序时间复杂度是 O(n1.3-2),空间复杂度为常数阶 O(1)。希尔排序没有时间复杂度为 O(n(logn)) 的快速排序算法快 ,因此对中等大小规模表现良好,但对规模非常大的数据排序不是最优选择,总之比一般 O(n2) 复杂度的算法快得多。
算法在执行过程中,只需要几个定义的临时变量,所以空间复杂度为常数级O(1)。 -
图解
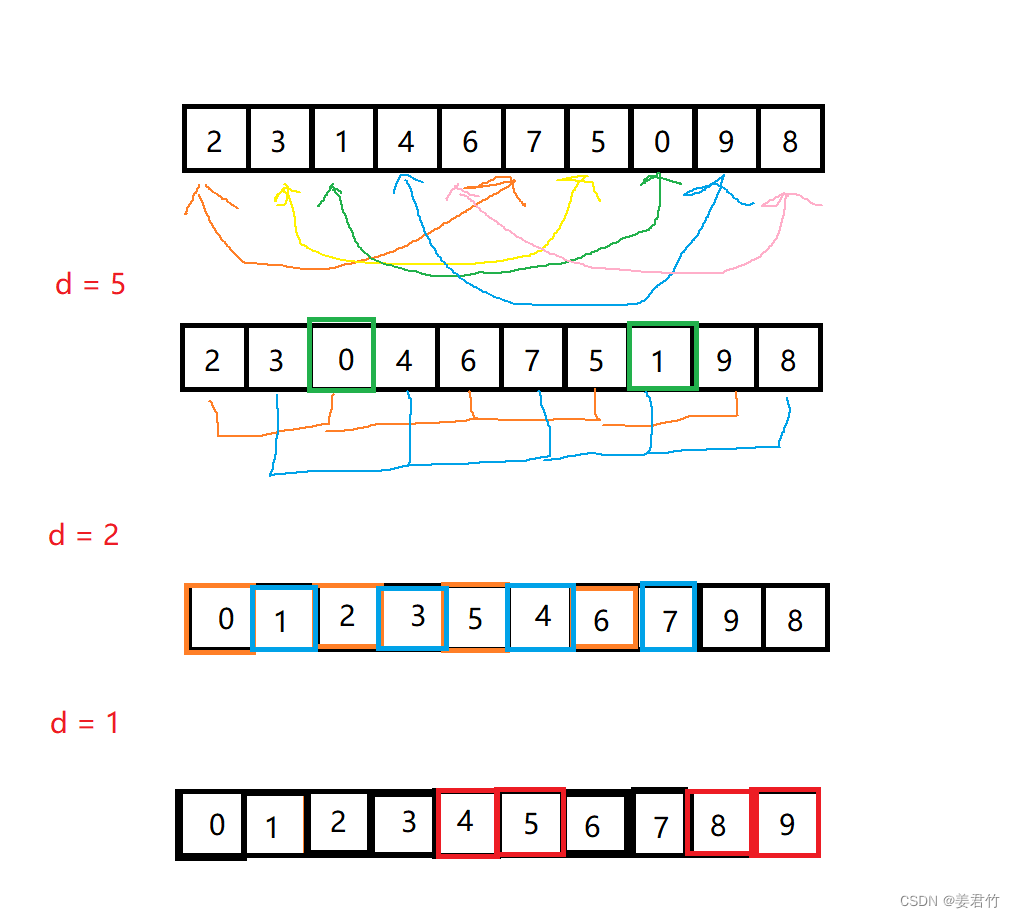
-
代码时间
int main() { int a[] = { 2, 3, 1, 4, 6, 7, 5, 0, 9, 8 }; int sz = sizeof(a) / sizeof(a[0]); int d = sz / 2; int i = 0; while (d > 0) { for (i = 0; i < d; i++) { int j = 0; for (j = i + d; j < sz; j = j + d) { int tmp = a[j]; int k = j - d; while (k >= 0 && a[k] > tmp) { a[k + d] = a[k]; k = k - d; } a[k + d] = tmp; } } d = d / 2; } for (i = 0; i < sz; i++) { printf("%d ", a[i]); } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。
-
-
相关阅读:
写技术博客的一些心得分享
快速排序及其变体
11 结构型模式- 代理模式
【mysql】1000w数据量的分页查询SQL,如何优化提升性能?
frp内网穿透搭建-宝塔版
一键批量转码:将MP4视频转为MP3音频的简单方法
从零自制docker-14-【实现 mydocker commit 打包容器成镜像】
【C++】模板
webpack简介及入门
【无标题】
- 原文地址:https://blog.csdn.net/qq_47658735/article/details/126440255
