-
mysql 普通索引 limit 慢的问题
- 面试被问到 mysql limit 深度大的时候优化问题;
select * from t order by 普通的索引 limit 起始位置,分页长度- 1
问题复现
- 起始位置小,执行计划情况:
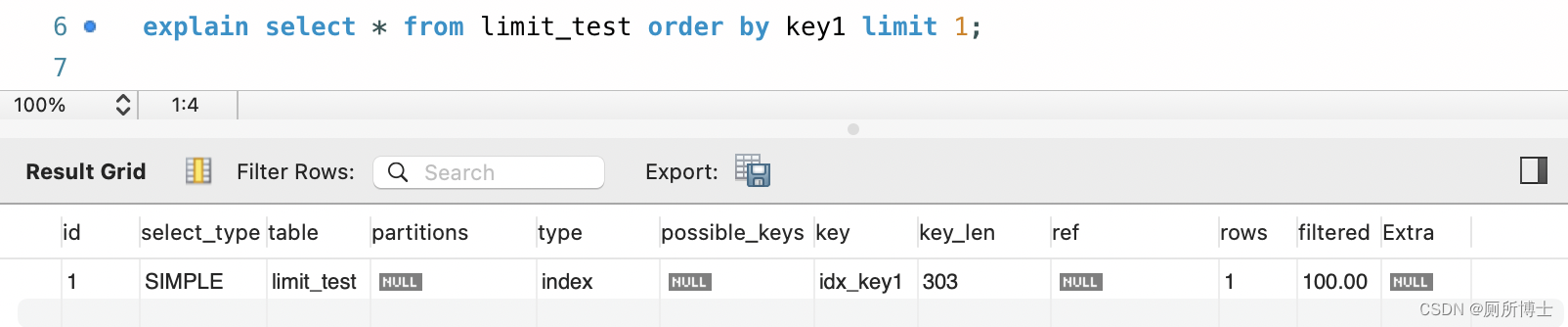
- 起始位置大,执行计划情况:
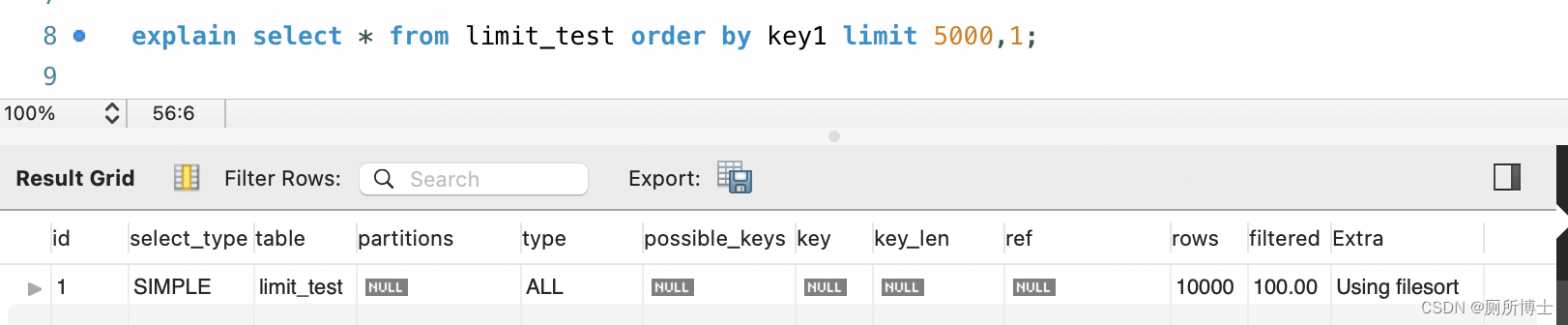
起始位置小时,走了索引;当 limit 起始位置较大时,使用的是全表扫描 + filesort 比较慢的方式;
为什么这么慢呢
从 mysql 的 server 端和存储引擎执行过程说起
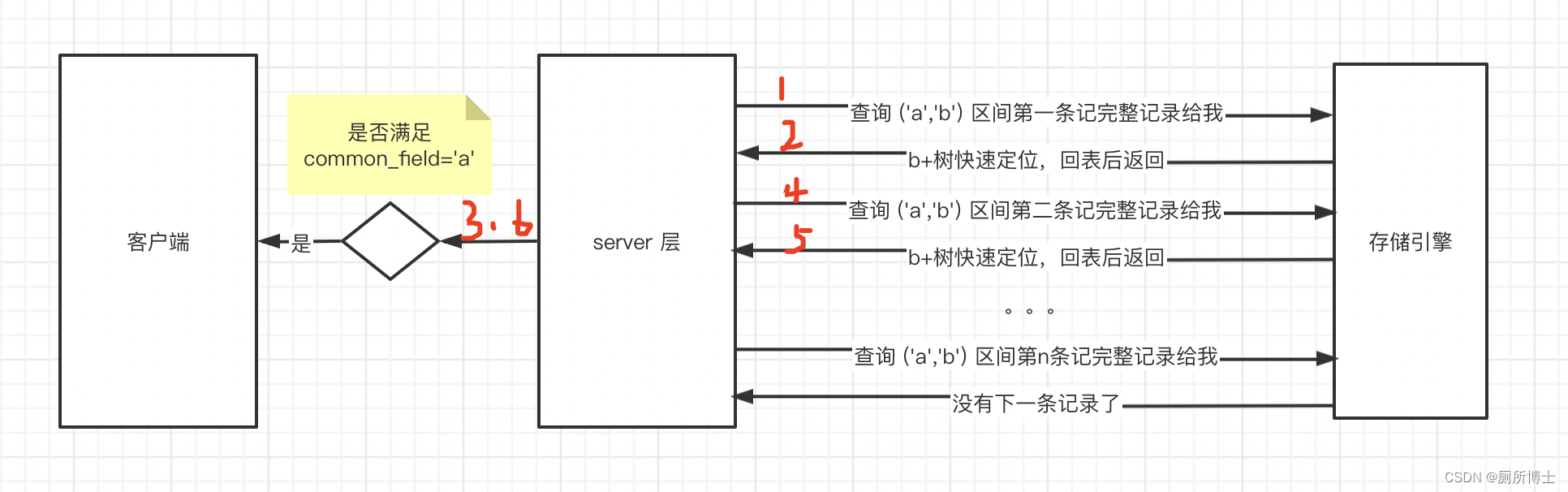
先找一条 sql 如下,当它使用了 key1 普通索引在执行的时候过程如下:
select * from limit_test where key1 > 'a' and key1 < 'b' and common_field='a';- 1
- 步骤一:server 层告诉存储引擎查询二级索引 key1 的(‘a’,‘b’)区间的第一条记录,然后进行回表把完整的数据返回给 server 层。
- 步骤二:存储引擎通过 key1 对应的二级索引 B+ 树,快速定位(‘a’,‘b’) 区间的第一条记录,然后进行回表,返回给 server 层。
- 步骤三:server 层收到聚簇索引记录后,继续判断 common_field = ‘a’ 是否成立,不成立舍弃,否则发送给客户端,然后问存储引擎要下一条记录。
- 步骤四:根据第一条记录的 next_record 属性找到 (‘a’,‘b’) 区间下一条二级索引记录,然后进行回表操作,返回给 server 层。
- 步骤五:server 层继续判断 common_field = ‘a’ 是否成立,不成立舍弃,否则返回给客户端。
- 步骤六:重复上述过程直到 (‘a’,‘b’) 区间没有下一条记录了
执行过程 uml 图表示:
limit 什么情况
limit 是 server 层准备向客户端发生记录的时候才去处理 limit 的内容;先找一条 sql:
select * from test_limt order by key1 limit 5000,1;- 1
- 步骤一:server 层向存储引擎要第一条记录,存储引擎获取第一条记录,然后回表得到完整的聚簇索引返回给 server 层,server 层准备发送给客户端之前,要处理
limit 5000,1,意味着第 5001 条才是真正要发送给客户端的,所以这里先做一个统计,假设 server 层维护了一个称作 limit_count 变量用于统计已经跳过了多少条记录,此时 limit_count = 1; - 步骤二:server 层向存储引擎要下一条记录,存储引擎根据 next_record 属性找到下一条记录,回表后将完整的聚餐索引记录返回给 server 层,server 层继续判断 ``limit 5000,1```,并根据 limit_count 不返回给客户端,limit_count=2;
- … 重复上述过程
- 指定 limit_count 等于 5001 的时候,server 层才会真正将存储引擎返回的完整聚餐索引记录发送给客户端
放到 uml 图:

上述过程有一个问题,server 层在发送给客户端之前才去判断 limit 条件,意味着要进行 5001 次回表。server 层在进行执行计划分析的时候,觉得执行这么多次回表的成本太大了,还不如直接执行全表扫描 + filesort 块,所以这么慢;
如何优化
进行了 5001 次回表操作成本太高了,如果能只回表一次就好了;
select * from limit_test,(select id from limit_test limit 5000,1) as d where limit_test.id = d.id- 1
这样写的话,
select id from limit_test limit 5000,1首先通过 key1 普通索引获取到 id ,然后通过 id 去 limit_test 中去查询。这样省去了 5000 次回表,效率大大提高;
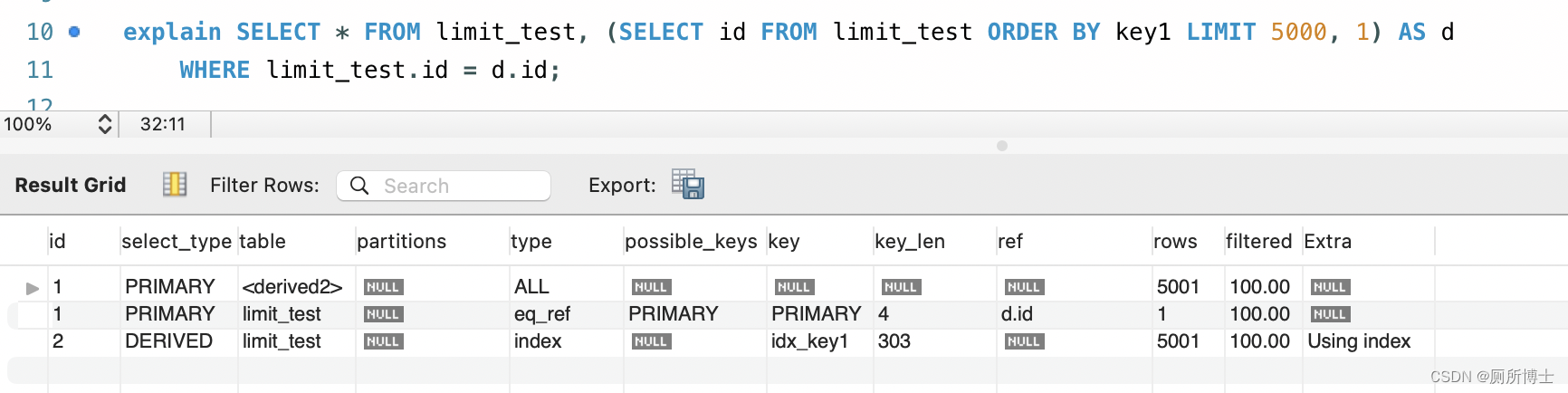
执行时间比较:

其他
优化后
select * from limit_test,(select id from limit_test limit 5000,1) as d where limit_test.id = d.id
虽然子查询只查询了主键 id,limit 实现 server 层去存储引擎还是一条一条去拿,再进行判断是不是 5001,只是减少了回表成本。
以上参考Mysql 是怎么运行的作者的公众号文章——MySQL的LIMIT这么差劲的吗其他解决方案
在分页查询情况下,可以把用户翻页的把上一页开始 key1(first_key1) 和 结束的 key1(last_key1) 数据以请求参数的形式带到这次的分页查询中;
- 用户选择了上一页:where key1 < first_key1 limit 1;
- 用户选择了下一页:where key1 > last_key1 limit 1;
这样查询也可以,但是需要注意如果当 key1 有重复的情况,就不能准确分页了;需要改写成where key1 <= first_key1 limit 2 和 where key1 > last_key1 limit 2;做冗余代码处理;就不展开进行讨论了。
参考8 种最坑SQL语法!
- 面试被问到 mysql limit 深度大的时候优化问题;
-
相关阅读:
抖音招聘直播报白有成本低和招聘效果精准的优势
微服务自动化【Docker-Compose】
今日绘画关键词分享
Mysql(库操作)
Day 64 django csrf操作 auth认证模块 项目功能封装优化
Linux面试题1:用户态和内核态
Flutter应用-使用sqflite升级数据库
567个!最常用的英语动词短语搭配汇总大全!
Swift编写爬取商品详情页面的爬虫程序
Spring的循环依赖,到底是什么样的
- 原文地址:https://blog.csdn.net/x123453316/article/details/126429527