-
* 论文笔记 【OffDQ: An Offline Deep Learning Framework for QoS Prediction】
标题 * 表示未完成本论文提出了一种OffDQ离线训练模型来解决QoS的预测问题,主要运用了对QoS矩阵进行预处理的方法来检测QoS矩阵的异常点并对其处理,包含余弦相似度的计算、均值归一化、神经网络、对特征向量使用去噪自编码器等方式。
- 研究目的
- 随着互联网上针对不同用户提供的各项服务日益增多,开发一种健壮的服务质量(QoS)预测算法来实时的推荐服务已成为当今的一个挑战。
- 目前的Qos预测算法还未能有效地同时满足高精度和低耗时的要求。
- 实现QoS预测的三个主要目标:prediction accuracy、 prediction time、scalability。
- 现有方法(研究现状)
- Qos所使用的 log matrix 往往是稀疏矩阵,这大大降低了预测准确度。
- memory-based协同过滤往往存在这种数据稀疏情况。
- 冷启动问题和Scalability问题一直是有待解决的问题。目前Scalability可以通过离线模式下的集群阶段部分【Y. Shi et al. 2011. A New QoS Prediction Approach based on User Clustering and Regression Algorithms. In IEEE ICWS. 726–727.】解决,而基于MF(矩阵分解)的方法可以解决数据稀疏性和冷启动问题,但是这种方法不足以很好的处理Qos数据之间的复杂联系。
- 对于prediction accuracy,主要有待解决的问题有:Qos矩阵总是存在异常值、Qos矩阵时常是稀疏的、Qos数据集中的复杂关系缺乏系统的分析、user和sevice直接的相关性分析、冷启动问题。
- 对于prediction time,主要有待解决的问题有:如今的数据大多存在着在线计算量的问题、虽然提出了离线学习算法来缓解在线计算的压力但很难设计出具有良好 query-agnostic(即模型训练过程中,不需要知道目标用户/服务)的算法.
- 对于High scalability,主要有待解决的问题有:如何高效处理高维数据。
- 本文模型及方法
- 在本文中提出了一个离线QoS预测框架(OffDQ),它包括两个阶段:(i)预处理 (ii)生成离线预测模型。预处理阶段的目的是去除矩阵稀疏性,而第二阶段的重点是为目标用户和其可能选择的服务预测QoS值。
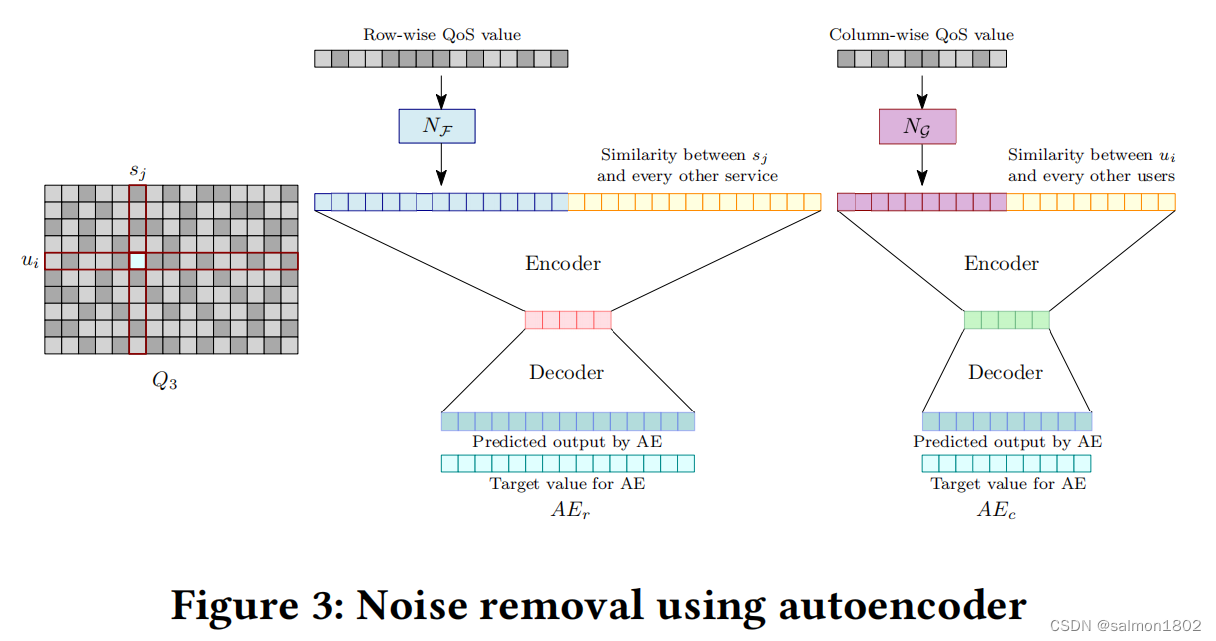
- 在本文中提出了一种新的策略来提取特征,此策略使用了去噪自编码器。


- 异常点的检测。本文提出的算法利用了向量的均值对于异常值是敏感的这一特点,不断迭代到某一标准时停止。首先计算出 V(say,µ) 的均值,再计算出小于 V(say,µ) 的数据集所占百分比 µ (say, lµ ),同理,计算出大于 V(say,µ) 的数据集所占百分比 µ (say, rµ ),如果 | lµ − rµ | > Tµ (Tµ是由手动设置的门拦) ,则说明数据集中存在异常数据,我们可以标识最高或最小元素为异常值。而当 |lµ − rµ| ≤ Tµ 或检测到的异常值在 µ ± Tr σ【Tr是由经验设定的阈值,σ是V(say,µ)的标准差】范围内时,算法终止。
- 异常点的去除。本文对QoS矩阵的列使用上述的异常点检测算法,而对于QoS矩阵的行则使用 中心化(均值取列的均值) 后再使用上述的检测算法来判定异常点(如果直接使用的话,因为同一个用户很可能会访问计算密集型的服务,此服务本是正常的,但在均值下可能会显得不正常)。
之后将所有被判定为无效的结点使用神经网络进行预测并填充。神经网络建立过程如下。
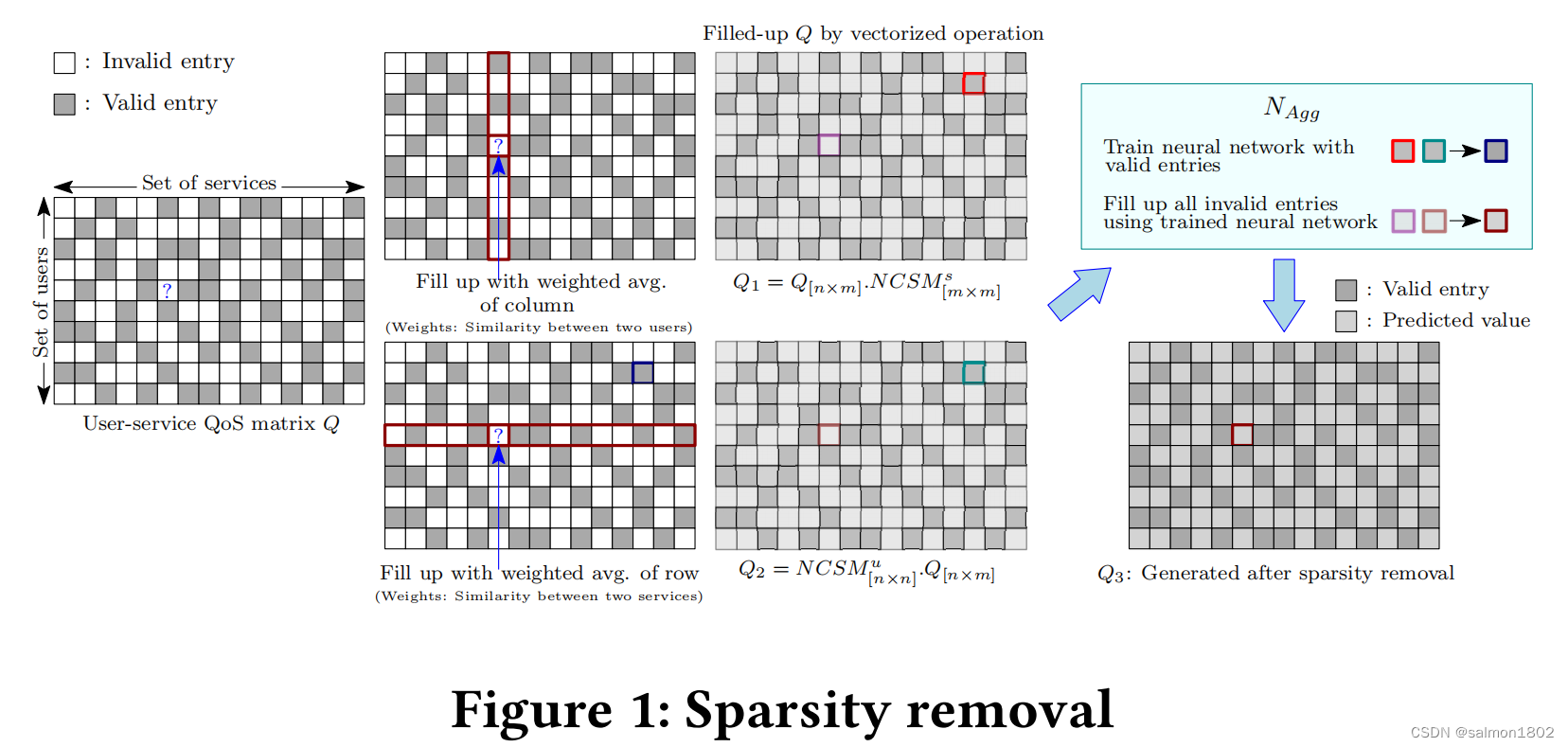
这里结合了memory-based and model-based CF的模型方法来处理Q中的无效值,即先将处理好的原Q矩阵中的异常点分别使用行、列的加权均值填充(使用余弦相似度作为权重),形成新矩阵A,B。再使用A,B中相同位置的有效结点训练神经网络模型。最后按照同样的策略使用训练好的模型预测异常点值。 具体计算步骤如下:
(1). 使用矩阵Q、Q的转置矩阵分别计算出其对应的余弦相似矩阵
这里可以发现零向量转化值置为1,CSMu与CSMs是对称矩阵
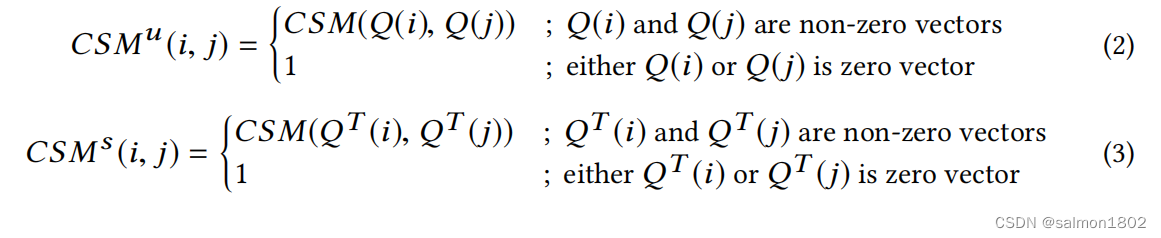
(2). 将计算出的CSMu与CSMs进行归一化处理,作为权重矩阵。
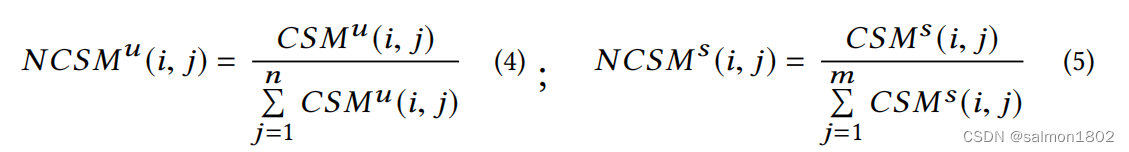
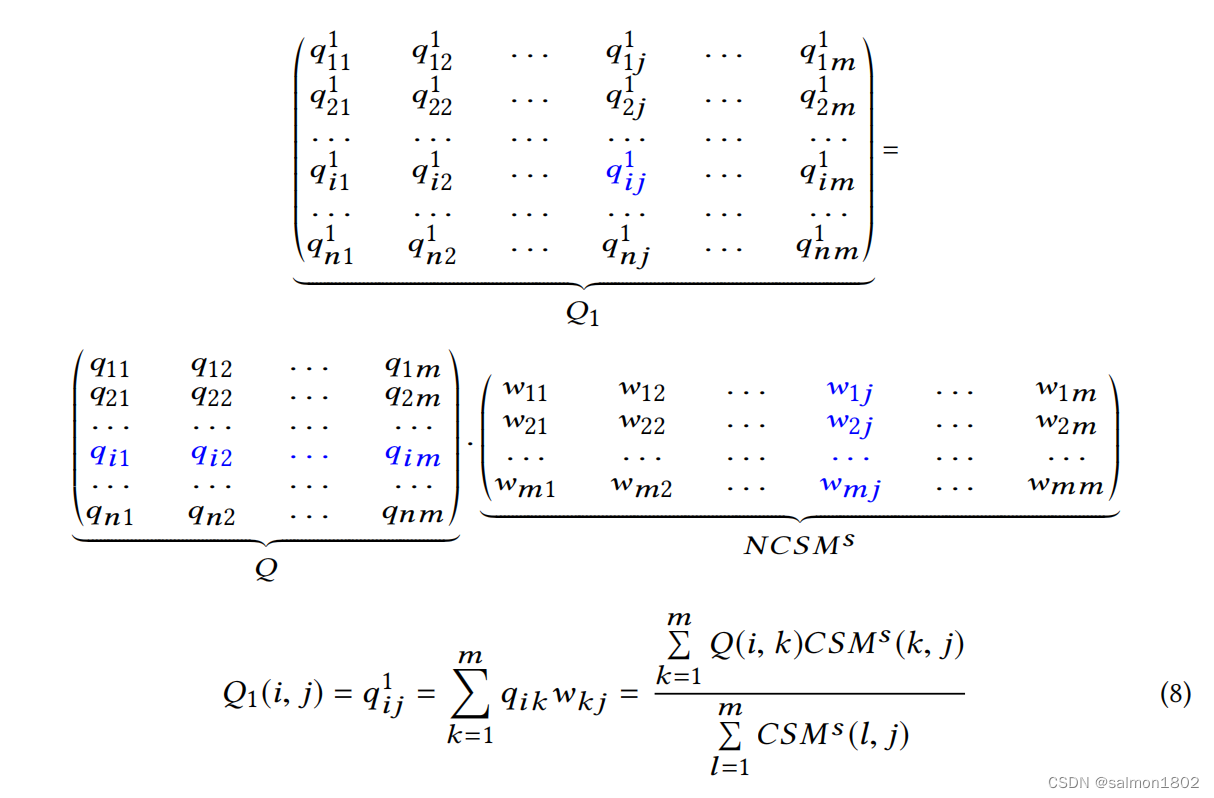
(3). 计算出Q1与Q2的矩阵

(4). 由Q1,Q2矩阵中的有效结点训练神经网络,并将训练好的模型用于预测Q矩阵中的无效结点。

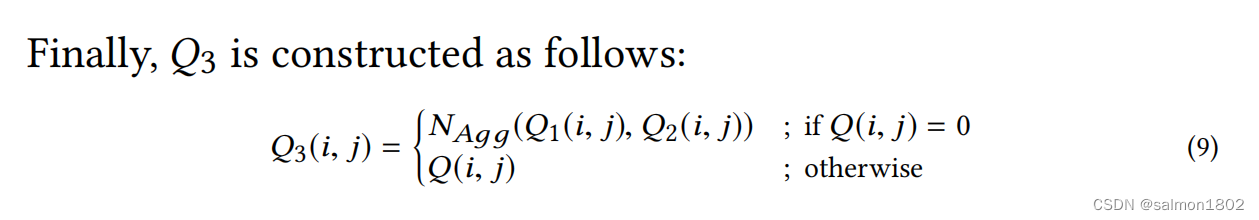
- 神经网络特征工程
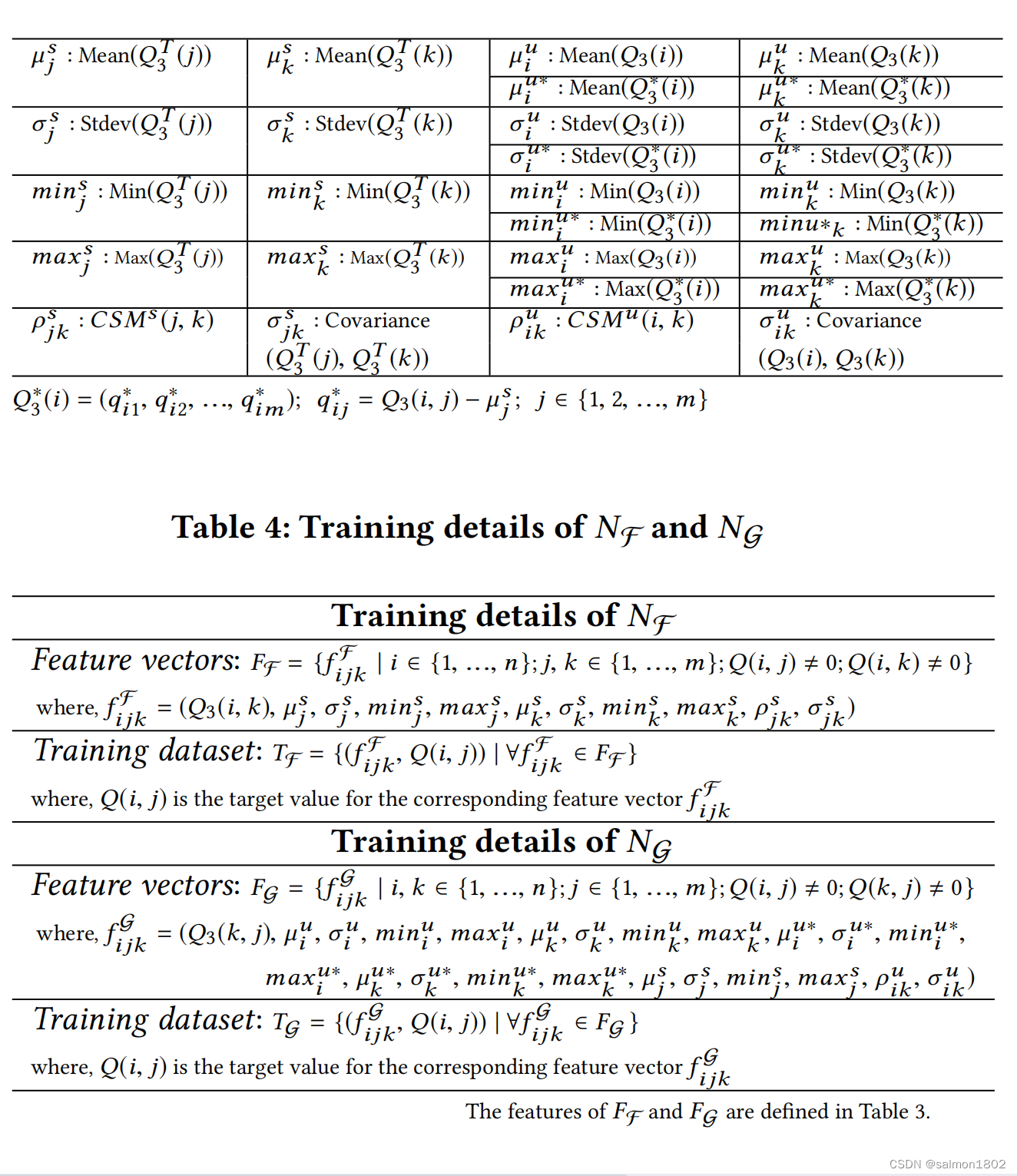
此时发现在Q中如果存在不相关数据,则会大大影响精准度,所以使用了去噪自动编码器来处理,这不仅可以最大程度的消除噪声还可以减少特征向量维度。
- 实验结果
-
在本文中按照经验设置Tµ = 30%,Tr = 2.5。
-
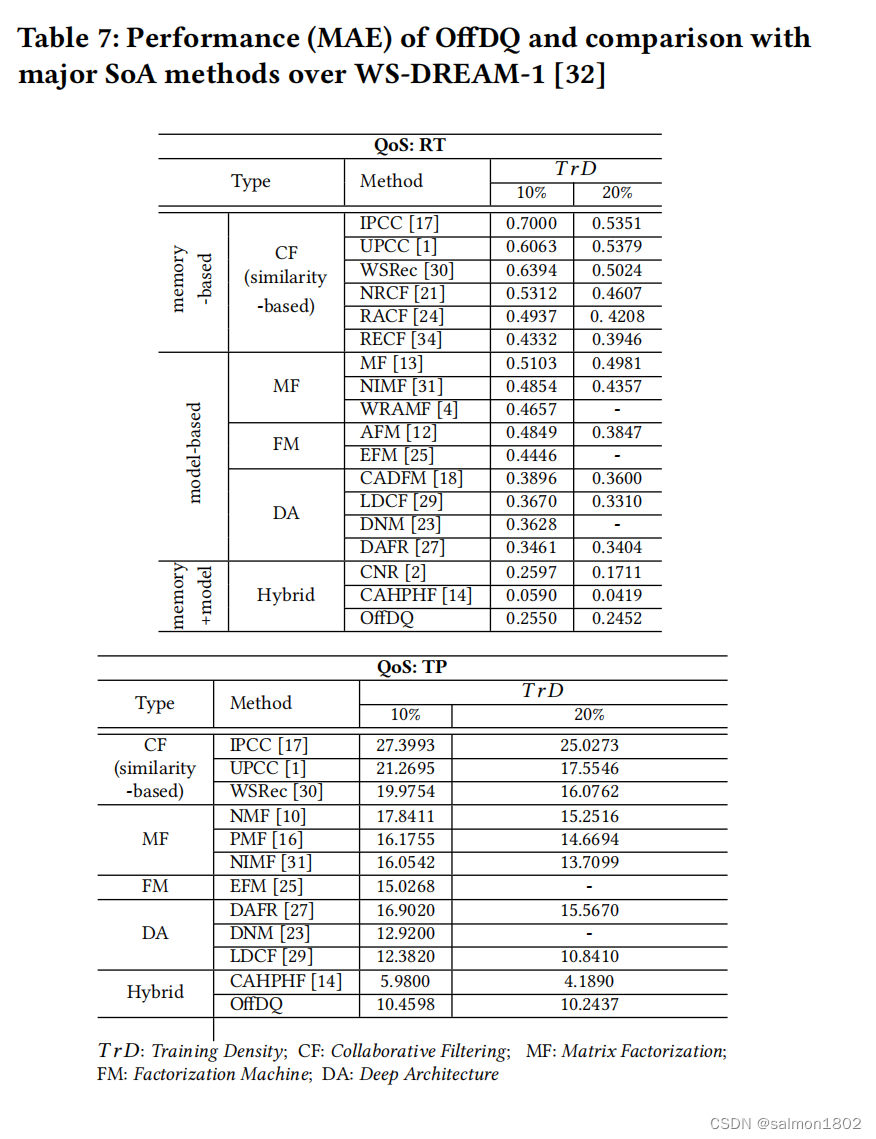
本文的OffDQ方法相比于memory-based CF的预测准确性,在RT数据集中,分别在10%和20%的训练密度下有了41.14%和37.86%的提高;在TP数据集中,分别在10%和20%的训练密度下有了47.64%和36.28%的提高。
-
本文的OffDQ方法相比于model-based CF的预测准确性,在RT数据集中,分别在10%和20%的训练密度下有了26.32%和25.92%的提高;在TP数据集中,分别在10%和20%的训练密度下有了26.82%和19.85%的提高。
-
本文的OffDQ方法相比于大多数离线预测模型( DAFR [27], LDCF [29] 等 )的预测准确性,在平均情况下,在RT数据集中,分别在10%和20%的训练密度下有了28.42%和26.94%的提高;在TP数据集中,分别在10%和20%的训练密度下有了15.52%和5.51%的提高。
-
在某些情况下CNR比OffDQ的准确性要高,但用时比OffDQ要高的多。
-
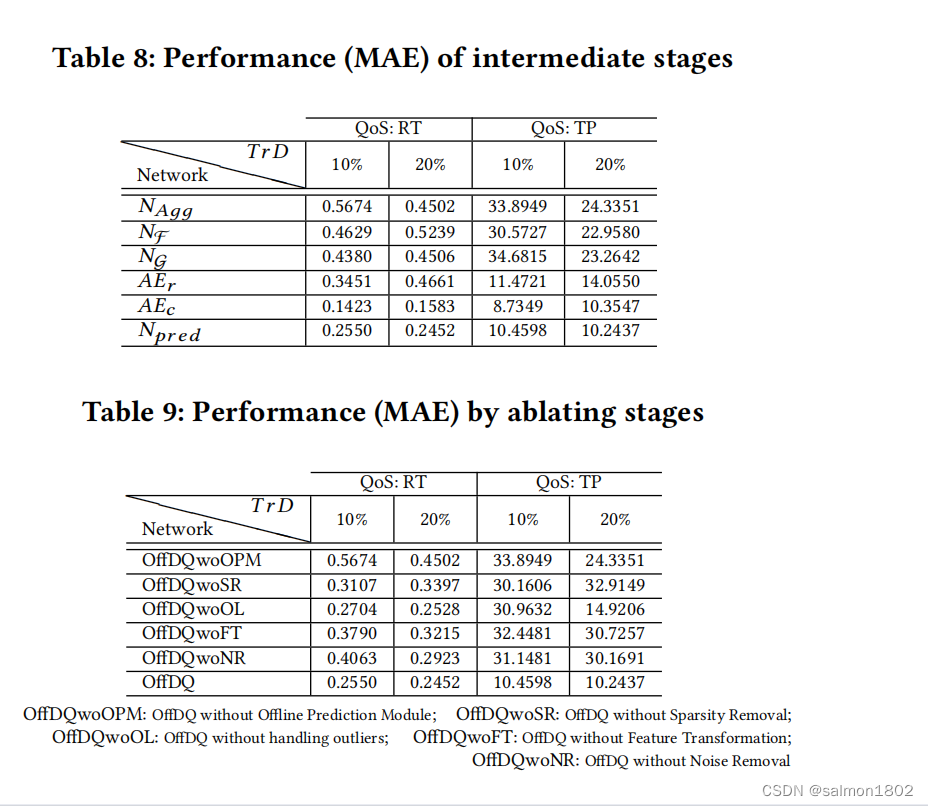
CAHPHF虽然比OffDQ准确度要高65.42%,但OffDQ比它快9486.15倍。
-
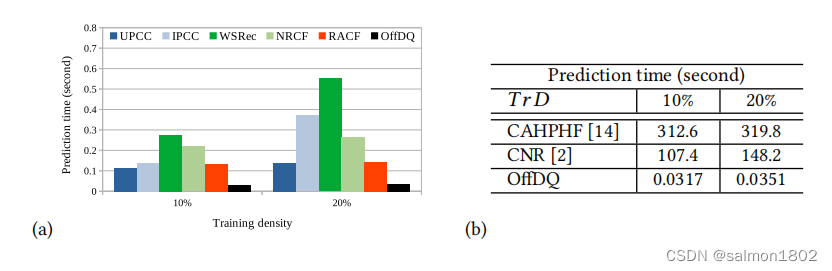
关于预测时间,在平均情况下OffDQ比最快的方法仍旧高了4.12倍(图a);与一些预测准确度可以和OffDQ媲美的在线方法比较,可以发现OffDQ算法要强上不少(图b)。
- 后面的不写了,反正就是本算法如何如何好,比现在主流的算法好在哪里,高明在哪里。
- 其它
-
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。

-
建立的神经网络模型解决了矩阵的稀疏性问题
-
冷启动问题被余弦相似矩阵所处理
-
mean absolute error (MAE)
-
state-of-the-art (SoA)
-
training density (TrD)
-
Matrix Factorization(MF)
-
Factorization Machine(FM)
-
Deep Architecture(DA)
-
END
-
相关阅读:
微信公众号根据关键词取文章列表 API
【ArcGIS】11 河道断面提取
【uvm】How to write uvm sequence
uniapp缓存对象数组
1.4 计算机网络在我国的发展
计算机网络-应用层(1)
基于nodejs+vue食力派网上订餐系统
hive学习之grouping set /cube/rollup
一起来打靶 02
Codeforces Round #828 (Div. 3) (A~D)
- 原文地址:https://blog.csdn.net/Salmon1122/article/details/126434488