-
MIT6.824-lab4A-The Shard controller(基于Raft的Shard KV数据库-分片控制器)
4A(The Shard controller,分片控制器)
前言
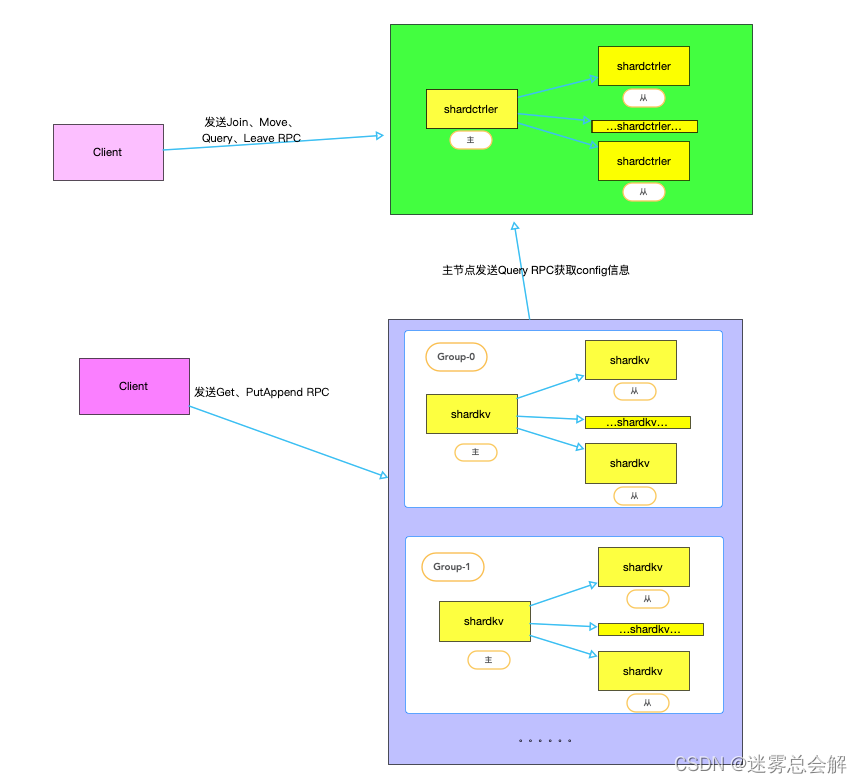
在本实验中,我们将构建一个带分片的KV存储系统,即一组副本组上的键。每一个分片都是KV对的子集,例如,所有以“a”开头的键可能是一个分片,所有以“b”开头的键可能是另一个分片…。
分片的原因是性能。每个replica group只处理几个分片的 put 和 get,并且这些组并行操作;因此,系统总吞吐量(每单位时间的投入和获取)与组数成比例增加。
我们要实现的分片KV存储将有两个主要组件:
- replica groups(复制组)。每个replica group负责分片的一个子集。副本由少数使用 Raft 复制组的分片的服务器组成;
- shard controller(分片控制器)。分片控制器决定哪个副本组应该为每个分片服务,此信息称为配置。配置随时间而变化。客户端通过请求分片控制器找到某一个key的replica group,并且replica group请求控制器以找出要服务的分片。整个系统有一个单一的controller,使用 Raft 作为容错服务实现。
分片存储系统必须能够在replica group之间移动分片,因为某些组可能比其他组负载更多,因此需要移动分片以平衡负载;而且replica group可能会加入和离开系统,可能会添加新的副本组以增加容量,或者可能会使现有的副本组脱机以进行修复或报废。
本实验的主要挑战是处理重新配置——移动分片所属。在单个副本组中,所有组成员必须就何时发生与客户端 Put/Append/Get 请求相关的重新配置达成一致。例如,Put 可能与重新配置大约同时到达,导致副本组停止对该Put包含的key的分片负责。组中的所有副本必须就 Put 发生在重新配置之前还是之后达成一致。如果之前,Put 应该生效,分片的新所有者将看到它的效果;如果之后,Put 将不会生效,客户端必须在新所有者处重新尝试。推荐的方法是让每个副本组使用 Raft 不仅记录 Puts、Appends 和 Gets 的顺序,还记录重新配置的顺序。您需要确保在任何时候最多有一个副本组为每个分片提供请求。
重新配置还需要副本组之间的交互。例如,在配置 10 中,组 G1 可能负责分片 S1。在配置 11 中,组 G2 可能负责分片 S1。在从 10 到 11 的重新配置过程中,G1 和 G2 必须使用 RPC 将分片 S1(键/值对)的内容从 G1 移动到 G2。
不论是KV数据库,还是replica groups以及分片的实现,都可以看看redis的源码,redis的处理十分巧妙和优美。又或者是参考BigTable, Spanner, FAWN, Apache HBase, Rosebud, Spinnaker等技术的架构。
lab4相比于lab3,也要实现exactly once语义,但是其更加接近于工业界的KV数据库的实现,因此lab4 是一个相对贴近生产场景的 lab。
整体的架构可以参考:
任务
4A主要就是实现shardctrler,其实它就是一个高可用的集群配置管理服务。它主要记录了当前整个系统的配置信息Config,即每组中各个节点的 servername 以及当前每个 shard 被分配到了哪个组。
对于前者,shardctrler 可以通过用户手动或者内置策略自动的方式来增删 raft 组,从而更有效地利用集群的资源。对于后者,客户端的每一次请求都可以通过询问 shardctrler 来路由到对应正确的数据节点,其实有点类似于 HDFS Master 的角色,当然客户端也可以缓存配置来减少 shardctrler 的压力。
在工业界,shardctrler 的角色就类似于 TiDB 的 PD 或者 Kafka 的 ZK,只不过工业界的集群配置管理服务往往更复杂些,一般还要兼顾负载均衡,事务授时等功能。
具体来说任务就是:
- 完善ShardCtrler数据结构、初始化代码,适当修改Command.go文件;
- 针对客户端的Query、Join、Leave、Move四种rpc分别设置处理函数;
- 编写applyCh的处理函数,处理Query、Join、Leave、Move四种命令,后三种命令处理中要进行一次配置调整;
- 自己指定策略,根据当前的调整命令对配置进行调整,即shard的配置调整。(最难)
任务须知
-
在lab4中,client并不会实现get、put、append这些命令的调用,而是四种函数:Query、Join、Leave、Move,分别对应四种RPC,主要是方便管理员控制 shardctrler:
- Query RPC。查询配置,参数是一个配置号, shardctrler 回复具有该编号的配置。如果该数字为 -1 或大于已知的最大配置数字,则 shardctrler 应回复最新配置。 Query(-1) 的结果应该反映 shardctrler 在收到 Query(-1) RPC 之前完成处理的每个 Join、Leave 或 Move RPC;
- Join RPC 。添加新的replica group,它的参数是一组从唯一的非零副本组标识符 (GID) 到服务器名称列表的映射。 shardctrler 应该通过创建一个包含新副本组的新配置来做出反应。新配置应在所有组中尽可能均匀地分配分片,并应移动尽可能少的分片以实现该目标。如果 GID 不是当前配置的一部分,则 shardctrler 应该允许重新使用它(即,应该允许 GID 加入,然后离开,然后再次加入);
- Leave RPC。删除指定replica group, 参数是以前加入的组的 GID 列表。 shardctrler 应该创建一个不包括这些组的新配置,并将这些组的分片分配给剩余的组。新配置应在组之间尽可能均匀地划分分片,并应移动尽可能少的分片以实现该目标;
- Move RPC。移动分片,的参数是一个分片号和一个 GID。 shardctrler 应该创建一个新配置,其中将分片分配给组。 Move 的目的是让我们能够测试您的软件。移动后的加入或离开可能会取消移动,因为加入和离开会重新平衡。
-
shardctrler 管理一系列编号的configuration。每个configuration都描述了一组副本组和分片到副本组的分配。每当此分配需要更改时,分片控制器都会使用新分配创建一个新配置。键/值客户端和服务器在想知道当前(或过去)配置时联系 shardctrler;
-
第一个configuration应该编号为零。它不应包含任何组,并且所有分片都应分配给 GID 零(无效的 GID)。下一个configuration(为响应加入 RPC 而创建)应该编号为 1。分片通常比组多得多(即每个组将服务多个分片),以便可以以相当精细的粒度转移负载;
-
Query RPC和lab3的Get RPC有一点不一样,Query RPC的参数如果不是-1,则查询的是某一个不会再改变的数据,因此不管是哪一个节点都能够返回;但是如果是-1则表明查询的最新的,因此必须要在leader中当做一个命令来进行处理,因为只有按照顺序来执行才能准确的获取当前的配置信息,但可以不考虑幂等性;
-
分配调整策略,如果没有好想法的话,可以参考:①尽量不改变当前的分配结果进行调整。每一个group都有一个分配shard的平均值,这也是每个hroup要分配到的最小值,多出来的shard可以轮询所有group进行分配,但是如果一个group已经分配的shard数 <= 平均值+多出来shard,就可以考虑多出来shard全部分配给它;②如果有group分配到的shard数小于平均值,则将空的shard分配给它达到平均值。但是注意因为group的遍历先后顺序问题,可能当前没有足够的shard进行分配,因此当前全部遍历完,需要再尝试一次;③最终分配完,可能所有的group都达到了平均值,但是多出来的shard可能没有进行分配完,因此可以进行轮询分配。
例子:
当前:4个group,23个shard,1-group分配了5个,2-group分配了8个,3-group分配了5个,4-group分配了5个
此时加入了0-group,因此就是5个group,23个shard,平均值为4,多出来shard为3。
第一次大循环:
0-group没有分配到,因为0是第一个进行shard调整,又当前没有空shard,因此就没有分配到;
1-group分配到5个,此时多出来shard为2;
2-group分配到6个,此时多来shard为0;
3-group分配到4个;4-group分配到4个。
第二次大循环:
0-gropu分配到4个。
代码
shardctrler的代码整体逻辑和kvraft相同,client部分几乎不用我们实现了,server部分一个RPC请求的处理也是rpc接收->start->applyCh处理->具体处理函数(除了Query有点不同)。
client
type Clerk struct { servers []*labrpc.ClientEnd // Your data here. clientId int64 }- 1
- 2
- 3
- 4
- 5
以join为例,代码就是:
func (ck *Clerk) Join(servers map[int][]string) { args := &JoinArgs{} // Your code here. args.Servers = servers args.ClientId = ck.clientId args.CommandId = nrand() for { // try each known server. for _, srv := range ck.servers { var reply JoinReply ok := srv.Call("ShardCtrler.Join", args, &reply) if ok && reply.WrongLeader == false { return } } time.Sleep(100 * time.Millisecond) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
其他的都是自带的代码,就不说了。写完kvraft这部分应该没问题。
server
数据结构
type ShardCtrler struct { mu sync.Mutex me int rf *raft.Raft applyCh chan raft.ApplyMsg // Your data here. stopCh chan struct{} commandNotifyCh map[int64]chan CommandResult lastApplies map[int64]int64 //k-v:ClientId-CommandId configs []Config // indexed by config num //用于互斥锁 lockStartTime time.Time lockEndTime time.Time lockMsg string } type CommandResult struct { Err Err Config Config } type Op struct { // Your definitions here. // Field names must start with capital letters, // otherwise RPC will break. ReqId int64 //用来标识commandNotify CommandId int64 ClientId int64 Args interface{} Method string }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
初始化代码
func StartServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister) *ShardCtrler { labgob.Register(Op{}) sc := new(ShardCtrler) sc.me = me sc.configs = make([]Config, 1) sc.configs[0].Groups = map[int][]string{} sc.applyCh = make(chan raft.ApplyMsg) sc.rf = raft.Make(servers, me, persister, sc.applyCh) // Your code here. sc.stopCh = make(chan struct{}) sc.commandNotifyCh = make(map[int64]chan CommandResult) sc.lastApplies = make(map[int64]int64) go sc.handleApplyCh() return sc }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
RPC接收处理代码
func (sc *ShardCtrler) Join(args *JoinArgs, reply *JoinReply) { // Your code here. res := sc.waitCommand(args.ClientId, args.CommandId, "Join", *args) if res.Err == ErrWrongLeader { reply.WrongLeader = true } reply.Err = res.Err } func (sc *ShardCtrler) Leave(args *LeaveArgs, reply *LeaveReply) { res := sc.waitCommand(args.ClientId, args.CommandId, "Leave", *args) if res.Err == ErrWrongLeader { reply.WrongLeader = true } reply.Err = res.Err } func (sc *ShardCtrler) Move(args *MoveArgs, reply *MoveReply) { res := sc.waitCommand(args.ClientId, args.CommandId, "Move", *args) if res.Err == ErrWrongLeader { reply.WrongLeader = true } reply.Err = res.Err } func (sc *ShardCtrler) Query(args *QueryArgs, reply *QueryReply) { // Your code here. DPrintf("server %v query:args %+v", sc.me, args) //如果是查询已经存在的配置可以直接返回,因为存在的配置是不会改变的; //如果是-1,则必须在handleApplyCh中进行处理,按照命令顺序执行,不然不准确。 sc.lock("query") if args.Num >= 0 && args.Num < len(sc.configs) { reply.Err = OK reply.WrongLeader = false reply.Config = sc.getConfigByIndex(args.Num) sc.unlock("query") return } sc.unlock("query") res := sc.waitCommand(args.ClientId, args.CommandId, "Query", *args) if res.Err == ErrWrongLeader { reply.WrongLeader = true } reply.Err = res.Err reply.Config = res.Config }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
以上分别是四种RPC的处理代码,都是调用waitCommand函数进行处理,query的处理除外,在调用waitCommand函数之前,可以进行一次判断,如果满足条件就直接返回,这里可以直接返回的原因是:以往的配置是不可变的,只要获取的不是最新的配置,就可以直接获取,而最近的配置信息因为命令的执行先后顺序不同,产生的配置也会不同,因此,必须按照顺序来执行命令,才能获取当前query命令执行时准确的最新配置。
query调用的getConfigByIndex函数是根据configNum获取对应的config,这里要注意的一点就是:获取的config一定要Copy以下,就是进行一次深拷贝,简单处理就是创建一个新的相同对象。
func (sc *ShardCtrler) getConfigByIndex(idx int) Config { if idx < 0 || idx >= len(sc.configs) { //因为会在config的基础上进行修改形成新的config,又涉及到map需要深拷贝 return sc.configs[len(sc.configs)-1].Copy() } return sc.configs[idx].Copy() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
其实可以不进行深拷贝的,仅仅是简化了后面的处理代码,比如因为join、move代码我们要创建一个新的config,而新的config其实和上一个config很多内容相同,因此可以直接在这个config上进行修改。如果不是深拷贝,旧的config就改变了。简单看下后面的代码:
func (sc *ShardCtrler) handleJoinCommand(args JoinArgs) { conf := sc.getConfigByIndex(-1) conf.Num += 1 //加入组 for k, v := range args.Servers { conf.Groups[k] = v } sc.adjustConfig(&conf) sc.configs = append(sc.configs, conf) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这么处理仅仅是因为方便,不这么写也没问题。
再来看下rpc的核心处理代码waitCommand:
func (sc *ShardCtrler) waitCommand(clientId int64, commandId int64, method string, args interface{}) (res CommandResult) { DPrintf("server %v wait cmd start,clientId:%v,commandId: %v,method: %s,args: %+v", sc.me, clientId, commandId, method, args) op := Op{ ReqId: nrand(), ClientId: clientId, CommandId: commandId, Method: method, Args: args, } index, term, isLeader := sc.rf.Start(op) if !isLeader { res.Err = ErrWrongLeader DPrintf("server %v wait cmd NOT LEADER.", sc.me) return } sc.lock("waitCommand") ch := make(chan CommandResult, 1) sc.commandNotifyCh[op.ReqId] = ch sc.unlock("waitCommand") DPrintf("server %v wait cmd notify,index: %v,term: %v,op: %+v", sc.me, index, term, op) t := time.NewTimer(WaitCmdTimeOut) defer t.Stop() select { case <-t.C: res.Err = ErrTimeout case res = <-ch: case <-sc.stopCh: res.Err = ErrServer } sc.removeCh(op.ReqId) DPrintf("server %v wait cmd end,Op: %+v.", sc.me, op) return }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
主要的处理步骤:
- 根据命令信息封装一个Op命令;
- 调用Start提交该命令;
- 创建一个用于处理该命令的唤醒ch;
- 阻塞等待ch的返回,不管是哪个ch返回,都要删除前一步创建的ch,防止内存泄漏。
命令应用代码
基于raft的协议,每当一个日志达到多数派,那么对应的命令就如进入applyCh,而applyCh的处理就需要我们自己来进行定义:
//处理applych func (sc *ShardCtrler) handleApplyCh() { for { select { case <-sc.stopCh: DPrintf("get from stopCh,server-%v stop!", sc.me) return case cmd := <-sc.applyCh: //处理快照命令,读取快照的内容 if cmd.SnapshotValid { continue } //处理普通命令 if !cmd.CommandValid { continue } cmdIdx := cmd.CommandIndex DPrintf("server %v start apply command %v:%+v", sc.me, cmdIdx, cmd.Command) op := cmd.Command.(Op) sc.lock("handleApplyCh") if op.Method == "Query" { //处理读 conf := sc.getConfigByIndex(op.Args.(QueryArgs).Num) sc.notifyWaitCommand(op.ReqId, OK, conf) } else { //处理其他命令 //判断命令是否重复 isRepeated := false if v, ok := sc.lastApplies[op.ClientId]; ok { if v == op.CommandId { isRepeated = true } } if !isRepeated { switch op.Method { case "Join": sc.handleJoinCommand(op.Args.(JoinArgs)) case "Leave": sc.handleLeaveCommand(op.Args.(LeaveArgs)) case "Move": sc.handleMoveCommand(op.Args.(MoveArgs)) default: panic("unknown method") } } sc.lastApplies[op.ClientId] = op.CommandId sc.notifyWaitCommand(op.ReqId, OK, Config{}) } DPrintf("apply op: cmdId:%d, op: %+v", cmdIdx, op) sc.unlock("handleApplyCh") } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
处理逻辑是在一个for循环中,从applyCh中会获取两种命令:快照命令和普通命令,当然lab4A不需要完成快照命令的处理。具体处理如下:
- 获取applyCh中的数据后,先进行一个转换,转成我们的Op结构;
- 如果是Query操作,简单的根据configNum获取config,并唤醒等待的协程;
- 如果是Move、Join、Move操作,需要先判断是否满足exactly once语义,即命令是否和上一个命令重复;然后分别进行处理;处理完成后唤醒等待的协程。
其中,Move、Join、Move操作的处理函数如下:
func (sc *ShardCtrler) handleJoinCommand(args JoinArgs) { conf := sc.getConfigByIndex(-1) conf.Num += 1 //加入组 for k, v := range args.Servers { conf.Groups[k] = v } sc.adjustConfig(&conf) sc.configs = append(sc.configs, conf) } func (sc *ShardCtrler) handleLeaveCommand(args LeaveArgs) { conf := sc.getConfigByIndex(-1) conf.Num += 1 //删掉server,并重置分配的shard for _, gid := range args.GIDs { delete(conf.Groups, gid) for i, v := range conf.Shards { if v == gid { conf.Shards[i] = 0 } } } sc.adjustConfig(&conf) sc.configs = append(sc.configs, conf) } func (sc *ShardCtrler) handleMoveCommand(args MoveArgs) { conf := sc.getConfigByIndex(-1) conf.Num += 1 conf.Shards[args.Shard] = args.GID sc.configs = append(sc.configs, conf) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- Join:将参数的server加入config的group,然后调用adjustConfig进行shard的分配调整;
- Leave:将参数的server移出config的group,并删除对应的shard标识,然后调用adjustConfig进行shard的分配调整;
- handleMoveCommand:只要修改参数中指定的shard的归属形成一个cnonfig。
notifyWaitCommand唤醒命令应用完成的等待协程:
func (sc *ShardCtrler) notifyWaitCommand(reqId int64, err Err, conf Config) { if ch, ok := sc.commandNotifyCh[reqId]; ok { ch <- CommandResult{ Err: err, Config: conf, } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
配置调整代码
//我们的策略是尽量不改变当前的配置 func (sc *ShardCtrler) adjustConfig(conf *Config) { //针对三种情况分别进行调整 if len(conf.Groups) == 0 { conf.Shards = [NShards]int{} } else if len(conf.Groups) == 1 { for gid, _ := range conf.Groups { for i, _ := range conf.Shards { conf.Shards[i] = gid } } } else if len(conf.Groups) <= NShards { //group数小于shard数,因此某些group可能会分配多一个或多个shard avgShardsCount := NShards / len(conf.Groups) otherShardsCount := NShards - avgShardsCount*len(conf.Groups) isTryAgain := true for isTryAgain { isTryAgain = false DPrintf("adjust config,%+v", conf) //获取所有的gid var gids []int for gid, _ := range conf.Groups { gids = append(gids, gid) } sort.Ints(gids) //遍历每一个server for _, gid := range gids { count := 0 for _, val := range conf.Shards { if val == gid { count++ } } //判断是否要改变配置 if count == avgShardsCount { //不需要改变配置 continue } else if count > avgShardsCount && otherShardsCount == 0 { //多出来的设置为0 temp := 0 for k, v := range conf.Shards { if gid == v { if temp < avgShardsCount { temp += 1 } else { conf.Shards[k] = 0 } } } } else if count > avgShardsCount && otherShardsCount > 0 { //此时看看多出的shard能否全部分配给该server //如果没有全部分配完,下一次循环再看 //如果全部分配完还不够,则需要将多出的部分设置为0 temp := 0 for k, v := range conf.Shards { if gid == v { if temp < avgShardsCount { temp += 1 } else if temp == avgShardsCount && otherShardsCount != 0 { otherShardsCount -= 1 } else { conf.Shards[k] = 0 } } } } else { //count < arg for k, v := range conf.Shards { if v == 0 && count < avgShardsCount { conf.Shards[k] = gid count += 1 } if count == avgShardsCount { break } } //因为调整的顺序问题,可能前面调整的server没有足够的shard进行分配,需要在进行一次调整 if count < avgShardsCount { DPrintf("adjust config try again.") isTryAgain = true continue } } } //调整完成后,可能会有所有group都打到平均的shard数,但是多出来的shard没有进行分配 //此时可以采用轮询的方法 cur := 0 for k, v := range conf.Shards { //需要进行分配的 if v == 0 { conf.Shards[k] = gids[cur] cur += 1 cur %= len(conf.Groups) } } } } else { //group数大于shard数,每一个group最多一个shard,会有group没有shard gidsFlag := make(map[int]int) emptyShards := make([]int, 0, NShards) for k, gid := range conf.Shards { if gid == 0 { emptyShards = append(emptyShards, k) continue } if _, ok := gidsFlag[gid]; ok { conf.Shards[k] = 0 emptyShards = append(emptyShards, k) } else { gidsFlag[gid] = 1 } } if len(emptyShards) > 0 { var gids []int for k, _ := range conf.Groups { gids = append(gids, k) } sort.Ints(gids) temp := 0 for _, gid := range gids { if _, ok := gidsFlag[gid]; !ok { conf.Shards[emptyShards[temp]] = gid temp += 1 } if temp >= len(emptyShards) { break } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
首先进行一个分支判断:
-
len(conf.Groups) == 0:表示当前没有groups,不需要调整;
-
len(conf.Groups) == 1:所有shard全部分配给它;
-
len(conf.Groups) <= NShards:这一步最重要,也是大部分情况下所处的状态,具体处理如下:
-
计算平均每一个group分配到的shard数,以及多余的shard数;
-
进行一个for循环,一般情况下执行1、2次。首先获取所有的group id,并进行升序排序;然后遍历每一个group id:
1)如果group分配的shard = 平均shard数,则当前group不用进行处理;
2)如果group分配的shard > 平均shard数 且多于的shard数为0,则将多出来的shard标记为0;
3)如果group分配的shard > 平均shard数 且多于的shard数大于0,则当前group每多分配一个,多余的shard数-1,如果多余的shard数减为0了,那么就和分支3相同了,即剩下的分配给当前group的shard就要标记为0;
4)如果group分配的shard < 平均shard数,则将标记为0的shard分配给当前group,只要分配的shard数达到平均值,就继续处理下一个group,如果当前的shard不够分配,则需要进行下一次循环(因为group遍历的先后问题)。
-
最后一步,就是针对上一步的调整,因为可能会有这样的情况:所有group都打到平均的shard数,但是多出来的shard没有进行分配,此时可以采用轮询的方法进行分配。
-
-
len(conf.Groups) > NShards:每一个group最多一个shard,会有group没有shard。gidsFlag用来标识每一个group是否已经被分配shard;emptyShards用来保存某些group分配的多余shard,用于接下来进行分配。
common代码
这一部分是common.go中的代码,简单介绍一下:
- init()函数主要是向labgob注册接口的可能类型。在Op的数据结构中我们有一个结构是:Args interface{},在raft调用Call将AppendEntries RPC将日志发送给其它节点时,就会使用labgob进行编解码,如果没有注册就会报错;(并不是都需要注册,为了方便,我就全列出来了)
- Config就是存储配置信息,要为config创建一个copy函数,用于进行深拷贝,具体的原因可以看RPC接受处理代码部分;
- Query、Join、Move、Leave分别有自己的args和reply。
type Err string // The number of shards. const NShards = 10 //状态码 const ( OK = "OK" ErrWrongLeader = "wrongLeader" ErrTimeout = "timeout" ErrServer = "ErrServer" ) //必须注册才能进行解码和编码 func init() { labgob.Register(Config{}) labgob.Register(QueryArgs{}) labgob.Register(QueryReply{}) labgob.Register(JoinArgs{}) labgob.Register(JoinReply{}) labgob.Register(LeaveArgs{}) labgob.Register(MoveArgs{}) labgob.Register(LeaveReply{}) labgob.Register(MoveReply{}) } // A configuration -- an assignment of shards to groups. // Please don't change this. //保存配置信息 type Config struct { Num int // config number,当前配置的编号 Shards [NShards]int // shard -> gid,每一个分片到replica group id的映射 Groups map[int][]string // gid -> servers[],每一个replica group包含哪些server } type ClientCommandId struct { ClientId int64 CommandId int64 } type JoinArgs struct { Servers map[int][]string // new GID -> servers mappings ClientCommandId } type JoinReply struct { WrongLeader bool Err Err } type LeaveArgs struct { GIDs []int ClientCommandId } type LeaveReply struct { WrongLeader bool Err Err } type MoveArgs struct { Shard int GID int ClientCommandId } type MoveReply struct { WrongLeader bool Err Err } type QueryArgs struct { Num int // desired config number ClientCommandId } type QueryReply struct { WrongLeader bool Err Err Config Config } func (c *Config) Copy() Config { config := Config{ Num: c.Num, Shards: c.Shards, Groups: make(map[int][]string), } for gid, s := range c.Groups { config.Groups[gid] = append([]string{}, s...) } return config }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
测试结果
-
相关阅读:
Redis(三) Redis的java客户端
FTP服务器
YOLOv9理性解读 | 网络结构&损失函数&耗时评估
skywalkingUI界面说明
算法通关村17关 | 透析跳跃游戏
pytorch UserWarningfault grid_sample; Python opencv Qt报Current thread的新解决方法
JUC笔记(一) --- 计算机基础
Spring Boot项目启动速度优化
C++初识 - 引用
腾讯云4核8G服务器支持多少人在线访问?
- 原文地址:https://blog.csdn.net/qq_44766883/article/details/126430294
