-
LZ4压缩算法简介
LZ4 是一种追求极致压缩与解压速度的压缩算法。由
Yann Collet开发,Yann Collet应该是一名非常出色的压缩算法专家,还著有另外一个近年大热的zstd压缩算法。zstd现在属于 Facebook 的开源项目。术语
为了行文方便,统一对英文术语做如下翻译:
- Magic Number:文件标识符(魔幻数)
- F. Descriptor:文件描述符
- Block:数据块
- EndMark:结束符
- C. Checksum:校验字
文件结构
LZ4 的整体文件结构是比较好理解的,可以参见 https://github.com/lz4/lz4/blob/dev/doc/lz4_Frame_format.md
文件结构如下:
文件标识符 文件描述符 数据块 …… 结束符 校验字 字节数 4 3 - 15 0 - n 4 0 / 4 -
文件标识符固定为0x184D2204,小端模式 -
文件描述符字节长度 3 - 15,包含有如下信息:
- LZ4 协议版本号
- 数据块独立性设置标志
- 数据块是否包含校验字
- 被压缩文件的大小(可配置是否携带)
- 数据块最大长度
- 字典 ID 等等
-
数据块恢复压缩文件的重要信息全部包含在数据块中(重点理解,后文详细展开) -
结束符标识数据块结束 -
校验字文件完整性校验
LZ4 压缩文件的结构如前文所述,是比较符合逻辑的定义,其中有些字段使用了动态长度的方式,主要是为了节省一些空间,不过由于除数据块之外的字段总共最大也只有 20 多个字节,可以压缩的空间不大。
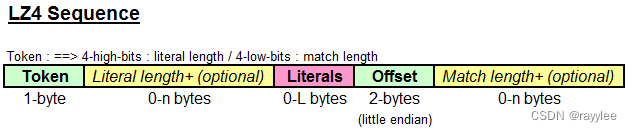
数据块结构 (LZ4 Data Block Format)
数据块的编码结构是 LZ4 的核心,其压缩的思想也主要体现在这里面。官方文档仅对编码结构做了一般性描述,对于 offset 字段的介绍十分云里雾里。下面按照我个人的理解进行一下阐述:
- 数据块可以由多个 Token 组成
- Token 头部可以分为两个 4 位的区域,高四位表示字面量长度(t1),低四位表示数据匹配长度(t2)。
- 由于 t1、t2 只能表示 16 个信息,对于更长的信息就无可奈何了,原协议提供了一个比较巧妙的办法(编码效率并不高)。当 t1 或 t2 为 15 时,e1 和 e2 区域启用,e1 和 e2 可以包含多个字节,直至其不为 0xFF(例如:FF E8)
- 字面量长度为:t1 + e1[0] + … + e1[n]
- 数据匹配长度为:t2 + e2[0] + … + e2[n] + 4 (最少4个字节)
- offset 表示当前偏移位置(curPos)与匹配区域起始位置(matchPos)的偏移
- matchPos = curPos - offset
- 初始时 curPos 为0,每解压一个字节增一
- matchPos 大于 0,匹配已解压区域
- matchPos 小于 0,匹配字典,从字典末端向前偏移(非常重要)
- 由于 offset 定义为 2 个字节,故此字典大小不超过 64KB

一个实例
现给定字符串 dfabcdefghijklmnabcdkkkkkk ,后面出现的“abcd”能够用前面的“abcd”经过偏移量offset与匹配长度matchLength进行代替,实际上这就是LZ4算法的主要思想。LZ4算法的最小匹配长度是4,最后5个字符按照字面量存储,也就是说当字节数<=9时是不压缩的(最后会给出解释)。测试
详细的LZ4编码数据涉及到的变量如下:
-
字面量值literalValue,即: dfabcdefghijklmn
-
字面量值长度literalLength=16
-
匹配长度matchLength=4
-
偏移量offset=16-2=14
编码格式如下:
token_literalLength(可选)_literalValue_offset_matchLength(可选)
token占用1个字节,前4位表明字面量值长度,若是长度值>=15与255(1个字节的无符号数)进行比较,若是比255大则减去255并写入1个字节,将剩余的值如此循环比较,反之直接写入1个字节。如字面量长度值为512,token前4位等于15。literalLength等于512-15=255+242占用两个字节。后四位表示匹配的长度,原理和前面同样,在实现的时候能够优化一下,由于默认最小匹配长度为4,因此能够将值减4。如匹配长度为512,token后4位等于15,matchLength等于512-4-15=255+238占用两个字节。literalLength与matchLength为何要加入可选,就是这个缘由,由于值小于15的时候,4个比特位已经足够表示了。offset占用2个字节,即最大值为65535。
上面的字符串压缩后的字节序列是:(0b11110000)_(1)_(dfabcdefghijklmn)_(14)_(0b01100000)_(kkkkkk)
问题一:为何最小匹配值为4?
我我的的理解是由于token占1个字节、offset占2个字节,只有匹配值大于3的时候才有可能起到压缩效果。注:为何是“有可能”呢,由于压缩算法是基于几率的,好比上面的例子并无起到压缩效果,反而多占一个字节。
问题二:为何最后的5个字节按照字面量直接存储?
我我的的理解是假设给定9个字节的字符串abcdabcde,按照正常流程压缩时格式以下:(0b01000000)(abcd)(4)------(0b00010000)_(e),一样占了9个字节,没有起到压缩效果。注意(4)是占2个字节的。
参考
- https://github.com/lz4/lz4/blob/master/doc/lz4_Block_format.md
- https://github.com/lz4/lz4/blob/dev/doc/lz4_Block_format.md
- http://ticki.github.io/blog/how-lz4-works/
- https://blog.csdn.net/MarkusZhang/article/details/125134975
-
相关阅读:
第2章 持久化初始数据到指定表
前端线上部署,如何通知用户有新版本
POJ1094Sorting It All Out题解
MySQL的DDL操作表
软考 系统架构设计师系列知识点之软件架构风格(5)
Vue怎么通过JSX动态渲染组件
超超超级详细的画图以及代码分析各种排序的实现!
kafka分区迁移失败任务的处理
WPF基础:在Canvas上绘制图形
Docker安装Nginx较佳实践
- 原文地址:https://blog.csdn.net/hbuxiaofei/article/details/126414804