-
计算机中的编码问题
目录
一、字符编码与字符集
1、字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。
编码:字符(能看懂的)–字节(看不懂的)
解码:字节(看不懂的)–>字符(能看懂的)字符编码: 就是一套自然语言的字符与二进制数之间的对应规则。
2、字符编码分类
1)ASCII编码
美国人首先对其英文字符进行了编码,也就是最早的ASCII码,用一个字节的低7位来表示英文的128个字符,高1位统一为0;使用一个字节来表示一个字符的这种编码方式,就是最早的:ASCII编码。

后来欧洲人发现这128位不够用,比如法国人字母上面的还有注音符,把高1位编了进来,这样欧洲普遍使用一个全字节进行编码,最多可表示256位。
2)GBK编码
GB就是国标的意思,是为了显示中文而设计的一套字符集。
GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
GB2312,GBK,GB18030,基本都能向前兼容,其中GBK是目前最通用的。
3)UTF-8编码
当然,如果世界各国都使用自己的编码,那国家与国家之间的交流就比较麻烦。所以,为了解决这个问题,由一个名为 Unicode 学术学会的组织,制订了一套编码规则-Unicode编码。该规则支持世界上超过650种语言。是一种世界通用字符规则。
Unicode虽然统一了全世界字符的二进制编码,但没有规定如何存储。如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,文本文件的大小会因此大出二三倍,这对于存储来说是极大的浪费。这样导致一个后果:出现了Unicode的多种存储方式。
UTF-8就是Unicode最重要的实现方式之一。另外还有UTF-16、UTF-32等。UTF-8不是固定字长编码的,而是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。这是种比较巧妙的设计,如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
UTF-8是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
3、字符集
字符集:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。
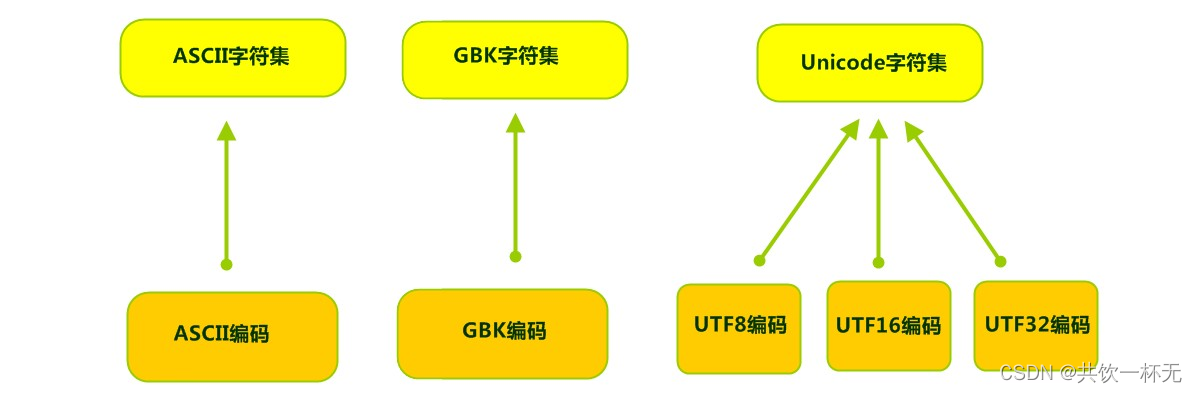
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
二、计算机系统中的编码应用
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码;用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
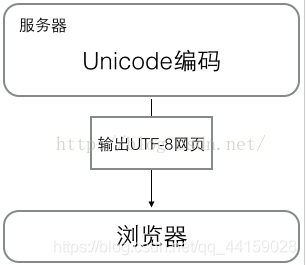
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码
三、乱码问题
比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
乱码只是因为我们在对字节解析的时候,组装错误了,就类似于玩积木的时候,放错位置了,但本质的字节没有改变。
乱码产生的原因
1、编码与解码的字符集不相同,导致乱码;
2、字节缺少或者长度丢失,导致乱码;
- /**
- * 乱码的原因
- */
- @Test
- public void test() throws UnsupportedEncodingException {
- // 默认字符集“utf-8”
- System.out.println("默认字符集:" + System.getProperty("file.encoding"));
- String info = "北京欢迎您!"; // 解码
- byte[] data = info.getBytes(); // 编码:char--->byte,字符或者字符串到字节
- // 编码与解码字符集统一,都使用工作空间默认的字符集
- System.out.println(new String(data)); // 解码:byte--->char,字节到字符或者字符串
- // 不统一则出现乱码
- System.out.println(new String(data, "GBK"));
- // 编码与解码的字符集必须相同,否则乱码
- byte[] data2 = "JPM,你好!".getBytes("GBK");// 编码
- String info2 = new String(data2, "GBK");// 解码
- System.out.println(info2);
- // 乱码的原因之二,字节缺少,长度丢失
- String str = "北京";
- byte[] data3 = str.getBytes();
- System.out.println(data3.length); // 6
- System.out.println(new String(data3, 0, 5)); // 字节数不完整导致乱码
- }
运行结果:
默认字符集:UTF-8
北京欢迎您!
鍖椾含娆㈣繋鎮紒
JPM,你好!
6
北�Java中IO流注意的问题
在IDEA中,使用
FileReader读取项目中的文本文件。由于IDEA的设置,都是默认的UTF-8编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。如何解决?-----> 指定编码读取
InputStreamReader(InputStream in, String charsetName): 将字节流转化为一个指定字符集的字符流,用于解码操作。
字符流不能设置字符集,只能是把字符流变为字节流才能进行字符集的设置,因为字节流才有设置字符集的方法。
- public class ReaderDemo2 {
- public static void main(String[] args) throws IOException {
- // 定义文件路径,文件为gbk编码
- String FileName = "E:\\file_gbk.txt";
- // 创建流对象,默认UTF8编码
- InputStreamReader isr = new InputStreamReader(new FileInputStream(FileName));
- // 创建流对象,指定GBK编码
- InputStreamReader isr2 = new InputStreamReader(new FileInputStream(FileName) , "GBK");
- // 定义变量,保存字符
- int read;
- // 使用默认编码字符流读取,乱码
- while ((read = isr.read()) != -1) {
- System.out.print((char)read); // ��Һ�
- }
- isr.close();
- // 使用指定编码字符流读取,正常解析
- while ((read = isr2.read()) != -1) {
- System.out.print((char)read);// 大家好
- }
- isr2.close();
- }
- }
参考文章:
-
相关阅读:
RedisTemplate序列化后数据字段增加,代码无常,大肠包小肠
js实现一个可指定超时时间的异步函数重试机制
从1000篇热门笔记,看小红书的种草趋势
HDFS 分布式环境搭建
模型压缩常用方法简介
Spring Boot项目学习之通用权限管理项目02
【JavaWeb】JSP基本语法、指令、九大内置对象、四大作用域
接口自动化测试:pytest基础讲解
【ORACLE】谈一谈NVARCHAR2、NCHAR、NCLOB等数据类型和国家字符集
部署云MYSQL(在线版)
- 原文地址:https://blog.csdn.net/qq_51409098/article/details/126409683
