-
kafka学习笔记
一、kafka的工作原理
我们知道,kafka是一个高性能、高可用和高扩展的消息队列,其中往队列中发送数据的称为生产者producer,从队列中拿取数据的称为消费者Consumer。根据不同的业务需求,我们肯定需要有多个不同的队列,其中每一个队列称为一个topic(主题)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PQ9RHrrP-1660806112053)(E:/Blog/lansg/source/img/image-20220817092207084.png)]](https://1000bd.com/contentImg/2024/03/29/9ae186207d6d0be7.png)
可以多个生产者往一个topic里面发送数据,也可以有多个消费者从一个topic里面拿取数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c2pzlREx-1660806112054)(E:/Blog/lansg/source/img/image-20220817092428664.png)]](https://1000bd.com/contentImg/2024/03/29/00ae4c0ab6682fd2.png)
既然kafka是高可用的,那么把海量的数据放在一台主机上肯定是不行的,如果这台主机宕机了怎么办?
我们对比联想一下数据库和缓存是如何解决这个问题的:
- 在数据库设计中,当单表的数据量达到几千万或者上亿时,我们会将它拆分成多个库或者多张表;
- 在缓存设计中,我们通过redis cluster将主节点分片,从而解决单机瓶颈的问题;
kafka同样采取了这种水平拆分的思想,它将每一个topic中的数据拆分为多个partition(分区),每一个partition分布在不同的kafka实例上,构成kafka集群,所有partition中的数据合集就是全部的数据。当生产者发送数据时,实际上是发送到了topic中的partition里,同样消费者也是从partition中拿取数据进行消费。其中一个kafka实例也称为一个broker。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h1xAIoUZ-1660806112055)(E:/Blog/lansg/source/img/image-20220817095658785.png)]](https://1000bd.com/contentImg/2024/03/29/2b144f6a6dd7b40e.png)
这样将数据分布在不同的broker上,即使一台broker宕机了,其他的broker依然能够提供服务。但是你有没有发现,由于不同的partition存放的是不同的数据,那肯定要对数据进行持久化,不然数据丢了怎么办。
kafka是将partition的数据写在磁盘的(消息日志),不过Kafka只允许追加写入(顺序访问),避免缓慢的随机 I/O 操作。但是kafka也不是partition一有数据就立马将数据写到磁盘上,它会先缓存一部分,等到足够多数据量或等待一定的时间再批量写入(flush)。
但是还有一个问题,要是某一个broker在对数据进行持久化之前就宕机了,那该部分数据不是还是会丢失?
事实上,kafka会在不同的broker上对该broker的partition进行备份,就像这样:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E0YWtw7S-1660806112055)(E:/Blog/lansg/source/img/image-20220817101916144.png)]](https://1000bd.com/contentImg/2024/03/29/aeef04e11a401405.png)
每个broker中有自己的主分区和别的broker的备份分区。只有主分区对外提供服务,备份分区仅用于备份,不进行读写。当某个broker宕机时,会从其他broker上的备份分区选举出主分区提供服务。
现在基本完成了消息存储的高可用,为了提高吞吐量,保证消息消费的效率,kafka提出了消费者组consumer group的概念。
还记得上文所说的同一个topic可以被多个消费者消费吗?在没有引入消费者组的情况下,如上图所示,消费者1独自消费partition0、partition1、partition2中的数据,引入消费者组后,组中的每一个消费者消费一个partition的数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-js64Uy2a-1660806112056)(E:/Blog/lansg/source/img/image-20220817104159950.png)]](https://1000bd.com/contentImg/2024/03/29/0d5732ccb4d14b3a.png)
此外,Kafka 限定了每个 partition 只能由消费组中的一个消费者进行消费,消费者组中的每一个消费者只能消费一个partition(一对一的关系)。
- 如果消费者组中某个消费者宕机了,那么剩下的消费者中,某一个可能要消费两个partition;
- 如果只有三个partition,而消费者组中有四个消费者,那么有一个消费者会空闲;
消费者组之间逻辑是独立的。上图中如果新增加一个消费者组,那么它仍然可以消费topic1中的全部数据。
现在假设消费者1宕机了,那么消费者2和消费者3会有一个消费者消费两个partition,但是该消费者如何知道消费者1的消费进度呢?
这就要提到
offset了。每个消费者都有自己的offset,它表示该消费者的消费进度,每次消费者进行消费的时候,都会提交这个offset,可以选择手动提交或者自动提交。
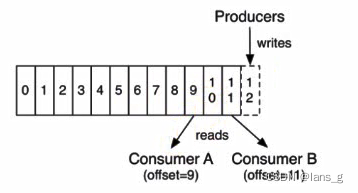
在以前版本的Kafka,这个
offset是由Zookeeper来管理的,后来Kafka开发者认为Zookeeper不合适大量的删改操作,于是把offset在broker以内部topic(__consumer_offsets)的方式来保存起来。但是kafka对于zookeeper还是有重要依赖的,zk为kafka提供了但不限于以下服务:- 探测broker和consumer的添加或移除;
- 负责维护所有partition的领导者/从属者关系(主分区和备份分区),如果主分区挂了,需要选举出备份分区作为主分区;
- 维护topic、partition等元配置信息
- …
二、kafka的高性能设计
作为当下大数据和分布式的宠儿,kafka为了性能优化可谓是做出了不少的努力,其中的很多设计思想都是值得我们学习和揣摩的。但是如果没有一条清晰的脉络,就会觉得知识太散,难以组合起来。
接下来我们从生产消息(生产者)、存储消息(broker)、消费消息(消费者)三个角度,看看kafka是如何实现高性能的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qAmbLE4o-1660806112057)(E:/Blog/lansg/source/img/image-20220817111811585.png)]](https://1000bd.com/contentImg/2024/03/29/6f98c80f142f402a.png)
1.生产者
传统的数据库或者消息中间件都是想办法让 client 端更轻量,将 server 设计成重量级,仅让 client 充当应用程序和 server 之间的接口。但是kafka将许多工作放在了客户端完成,这样的好处是减轻了服务端的压力。
在客户端部分,kafka主要采取了以下几种措施进行优化:
- 批量发送消息
- 消息压缩
- 高效序列化
- 内存池复用
批量发送消息
Kafka 作为一个消息队列,很显然是一个 IO 密集型应用,它所面临的挑战除了磁盘 IO(broker 端对消息持久化),还有网络 IO(producer到 broker,broker 到 consumer)。
至于磁盘IO,我们到broker优化的时候再说,现在先看看客户端对网络IO做了哪些优化。
我们知道,在一个topic队列中是会进行分区partition的,基于这个背景, Kafka 采用了批量发送消息的方式,将多条消息按照分区进行分组,然后每次发送一个消息集合,从而大大减少了网络传输的开销(这里的开销主要指一些头部控制信息,由于每次发送都要带上它们,因此也被称为系统开销)。
消息压缩
在客户端发送消息之前会对数据进行压缩,有了前面批量发送的前提,压缩可以大大的提高网络传输率(数据量越大,压缩效果越好)。kafka支持三种压缩算法:gzip、snappy、lz4,对比如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l61BA1xL-1660806112058)(E:/Blog/lansg/source/img/image-20220818095820887.png)]](https://1000bd.com/contentImg/2024/03/29/47507b90401b971a.png)
其实压缩消息不仅仅减少了网络 IO,它还大大降低了磁盘 IO。因为批量消息在持久化到 broker 中的磁盘时,仍然保持的是压缩状态,最终是在 consumer 端做了解压缩操作。
高效序列化
kafka 消息中的 Key 和 Value,都支持自定义类型,只需要提供相应的序列化和反序列化器即可。因此,用户可以根据实际情况选用快速且紧凑的序列化方式(比如 ProtoBuf、Avro)来减少实际的网络传输量以及磁盘存储量,进一步提高吞吐量。
内存池复用
前面说过 producer发送消息是批量的,因此消息都会先写入 producer的内存中进行缓冲,直到多条消息组成了一个 Batch,才会通过网络把 Batch 发给 broker。
当这个 Batch 发送完毕后,显然这部分数据还会在 producer端的 JVM 内存中,由于不存在引用了,它是可以被 JVM 回收掉的。但是大家都知道,JVM GC 时一定会存在 Stop The World 的过程,这对于 Kafka 这种高并发场景肯定会带来性能上的影响。
于是便引出了 Kafka 的内存池机制,它和连接池、线程池的本质一样,都是为了提高复用,减少频繁的创建和释放。具体是如何实现的呢?
其实很简单:producer一上来就会占用一个固定大小的内存块,比如 64MB,然后将 64 MB 划分成 M 个小内存块(比如一个小内存块大小是 16KB)。
当需要创建一个新的 Batch 时,直接从内存池中取出一个 16 KB 的内存块即可,然后往里面不断写入消息,但最大写入量就是 16 KB,接着将 Batch 发送给 Broker ,此时该内存块就可以还回到缓冲池中继续复用了,根本不涉及垃圾回收。
2.broker
在服务器端的优化主要是对消息的读取和存储,实现方式包括了以下几点:
- IO多路复用
- 磁盘顺序写
- Page Cache
- 分区分段结构
IO多路复用
首先要解决的问题,肯定是和produce、consumer之间的消息传递了。为了高效的进行网络通信,kafka采取了Reactor 模型(多Reactor 多线程)。
简单记忆就是1+N+M:
1:表示 1 个 主线程,当MainReactor监听到建立连接的事件后,会通过Acceptor获取新的连接,然后将新连接交给 Processor 线程处理。(主Reactor )
N:表示 N 个 Processor 线程,每个 Processor 都有自己的 selector,负责从 socket 中读写数据。(从Reactor )
M:表示 M 个 KafkaRequestHandler 业务处理线程,它通过调用 KafkaApis 进行业务处理,然后生成 response,再交由给 Processor 线程。
磁盘顺序写
作为服务器,存储消息是必不可少的。但我们知道磁盘IO是很慢的,kafka是如何做到将数据保存在磁盘中还做到高性能的呢?
Kafka 选用的是「日志文件」来存储消息,并且采用的是磁盘顺序写的方式。
磁盘随机IO是很慢的,但如果是顺序写入,就可大大节省磁盘寻道和盘片旋转的时间,提高效率。为什么kafka可以做到顺序写呢?
这得益于kafka的特性。kafka 作为消息队列,本质上就是一个队列,是先进先出的,而且消息一旦生产了就不可变。这种有序性和不可变性使得 kafka 完全可以顺序写日志文件,也就是说,仅仅将消息追加到文件末尾即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uf93HxCo-1660806112058)(E:/Blog/lansg/source/img/image-20220818105428156.png)]](https://1000bd.com/contentImg/2024/03/29/3395bdf40f485323.png)
PageCache页缓存
当用户对文件进行读写时,实际上是对文件的页缓存进行读写。内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把页缓存的数据拷贝给用户。写入数据时会先写到页缓存中,然后内核会定时把这些页缓存刷新到磁盘中。
Page Cache 缓存的是最近会被使用的磁盘数据,利用的是时间局部性原理,依据是:最近访问的数据很可能接下来再访问到。而预读到 Page Cache 中的磁盘数据,又利用了空间局部性原理,依据是:数据往往是连续访问的。
kafka作为消息队列,消息先是顺序写入,然后马上就会被消费者读取,这不是完美契合?所以,页缓存可以说是 Kafka 做到高吞吐的重要因素之一。
分区分段结构
前面说了kafka会将topic进行分区,其实在 Kafka 的存储底层,在分区之下还有一层:那便是「分段」。简单理解:分区对应的其实是文件夹,分段对应的才是真正的日志文件。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lbA5Qshn-1660806112059)(E:/Blog/lansg/source/img/image-20220818111007106.png)]](https://1000bd.com/contentImg/2024/03/29/d875462d9ae04b71.png)
为什么有了 Partition 之后,还需要 Segment 呢?
如果不引入 Segment,一个 Partition 只对应一个文件,那这个文件会一直增大,势必造成单个 Partition 文件过大,查找和维护不方便。
此外,在做历史消息删除时,必然需要将文件前面的内容删除,只有一个文件显然不符合 Kafka 顺序写的思路。而在引入 Segment 后,则只需将旧的 Segment 文件删除即可,保证了每个 Segment 的顺序写。
3.消费者
消费者的目的主要是先通过broker读取数据,然后通过io拉取数据。主要包括以下优化:
- 稀疏索引
- mmap
- 零拷贝
- 批量拉取
稀疏索引
消费者要消费数据,首先就是根据
offset获取broker中存储的数据。那么如何高效获取数据,我们肯定会想到索引。我们可以通过哈希索引,在内存中维护一个**「从 offset 到日志文件偏移量」**的映射关系即可,每次根据 offset 查找消息时,从哈希表中得到偏移量,再去读文件即可。但是当数据越来越来大,内存中肯定无法存储所有数据的。
我们发现消息的 offset 完全可以设计成有序的(实际上是一个单调递增 long 类型的字段),这样消息在日志文件中本身就是有序存放的了,我们便没必要为每个消息建 hash 索引了,完全可以将消息划分成若干个 block,只索引每个 block 第一条消息的 offset 即可,先根据大小关系找到 block,然后在 block 中顺序搜索,这便是 Kafka 稀疏索引 的设计思想。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BTgWS5A4-1660806112060)(E:/Blog/lansg/source/img/image-20220818144339643.png)]](https://1000bd.com/contentImg/2024/03/29/014a1ebc8ac209cf.png)
mmap
稀疏索引解决了 查询数据的问题,但是读写数据还可以进行优化,kafka采取了mmap的方式读写稀疏索引文件。
如何理解 mmap?常规的文件操作为了提高读写性能,使用了 Page Cache 机制,但是由于页缓存处在内核空间中,不能被用户进程直接寻址,所以读文件时还需要通过系统调用,将页缓存中的数据再次拷贝到用户空间中。
而采用 mmap 后,它将磁盘文件与进程虚拟地址做了映射,并不会招致系统调用,以及额外的内存 copy 开销,从而提高了文件读取效率。
为什么log文件不用mmap?
因为mmap 有多少字节可以映射到内存中与地址空间有关,32 位的体系结构只能处理 4GB 甚至更小的文件。Kafka 日志通常足够大,可能一次只能映射部分,因此读取它们将变得非常复杂。然而,索引文件是稀疏的,它们相对较小。将它们映射到内存中可以加快查找过程,这是内存映射文件提供的主要好处。
零拷贝
零拷贝主要是用来解决,broker读取数据后,将数据发送到socket的问题。
传统的文件传输是这样的:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jA8kRHC1-1660806112060)(E:/Blog/lansg/source/img/image-20220818145436955.png)]](https://1000bd.com/contentImg/2024/03/29/b0ca6d92446feb9d.png)
kafka采用的是sendfile()零拷贝,传输数据是这样的:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iHT2DKj2-1660806112061)(E:/Blog/lansg/source/img/image-20220818145707269.png)]](https://1000bd.com/contentImg/2024/03/29/ade537cee4de1468.png)
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
关于零拷贝,推荐大家看这篇文章:零拷贝
批量拉取
最后就是消息的接收了,消费者拉取消息的时候也是批量拉取的,每次拉取一个消息集合,和生产者很相似。当拉取完消息之后,会在消费者端将消息进行解压缩。
-
相关阅读:
.NET6: 开发基于WPF的摩登三维工业软件 (10) - 机器人
SqlBoy:打折日期交叉问题
CloudService计算类技术和网络类技术以及存储类技术的基础学习
高等院校教师资格证考试怎么考,要什么条件?
组件之间通过bus中央事件总线进行通信
树形结构-二叉树
【MCAL_CANDriver】-2.1-硬件过滤(Hardware Filter)详述及配置
Ant-Design-Pro-V5 :QueryFilter高级筛选组件、Table以及Pagination组件结合实现查询。
【漏洞库】Fastjson_1.2.24_rce
循环读取图像实例
- 原文地址:https://blog.csdn.net/lans_g/article/details/126406119