-
web自动化测试(一)之web控件定位
常见控件定位方法
定位方式 含义描述 id(重点) id 属性对应的值 class name(重点)) class 属性对应的值 name(重点) name 属性对应的值 css selector(重点) css 表达式 xpath(重点 ) xpath表达式 link text(不常用,不稳定) 查找其可见文本与搜索值匹配的锚元素 partial link text 查找其可见文本包含搜索值的锚元素。如果多个元素匹配,则只会选择第一个元素。 tag name 标签名称 一、id定位
- id定位语法格式: driver.find_element(By.ID, “ID属性对应的值”)
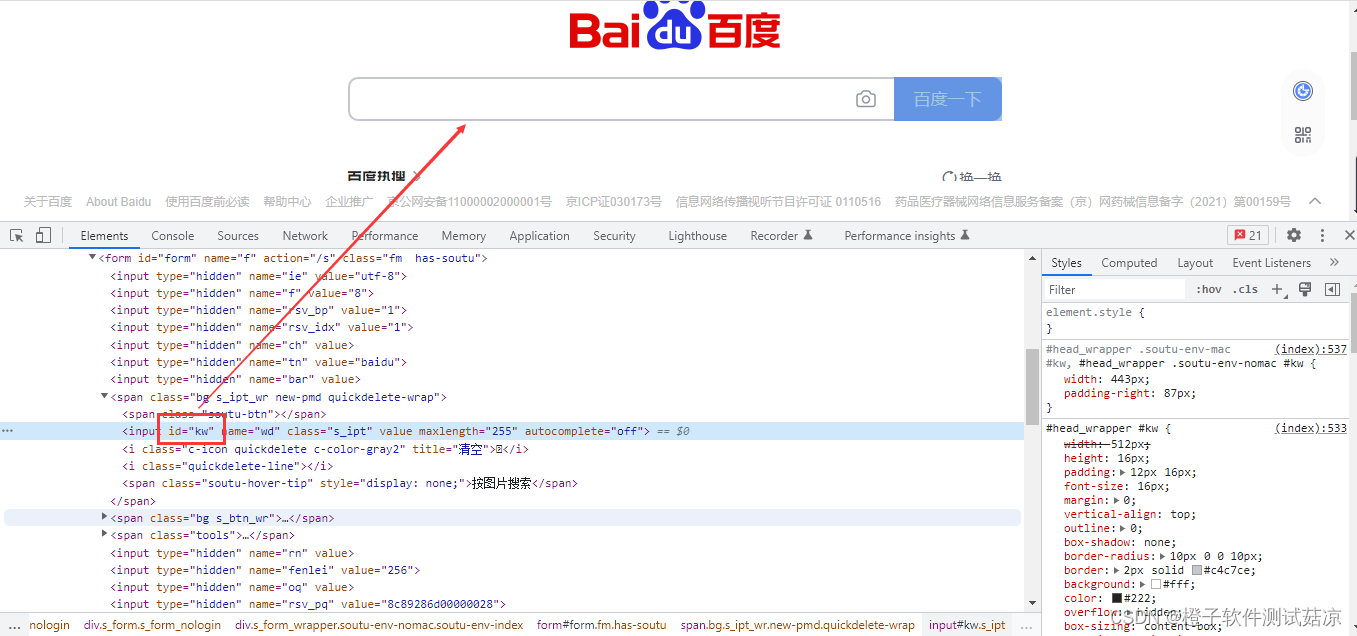
# 导入依赖 from selenium import webdriver import time from selenium.webdriver.common.by import By class TestHogwarts(): def test_id(self): # 创建driver self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.implicitly_wait(5) # 打开百度网站 self.driver.get('http://www.baidu.com') # 点击输入框 self.driver.find_element(By.ID, "kw").click() # 等待两秒 time.sleep(2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
二、name定位
- name定位语法格式: driver.find_element(By.ID, “name属性对应的值”)

# 导入依赖 from selenium import webdriver import time class TestHogwarts(): def test_id(self): # 创建driver self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.implicitly_wait(5) # 打开百度网站 self.driver.get("https://www.baidu.com/") # 点击输入框 self.driver.find_element_by_id("kw").click() # name定位,输入“霍格沃兹测试开发” self.driver.find_element_by_name("wd").send_keys("霍格沃兹测试开发") # 等待两秒 time.sleep(2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
三、class name定位
- class name定位语法格式: driver.find_element(By.ID, “class name属性对应的值”)
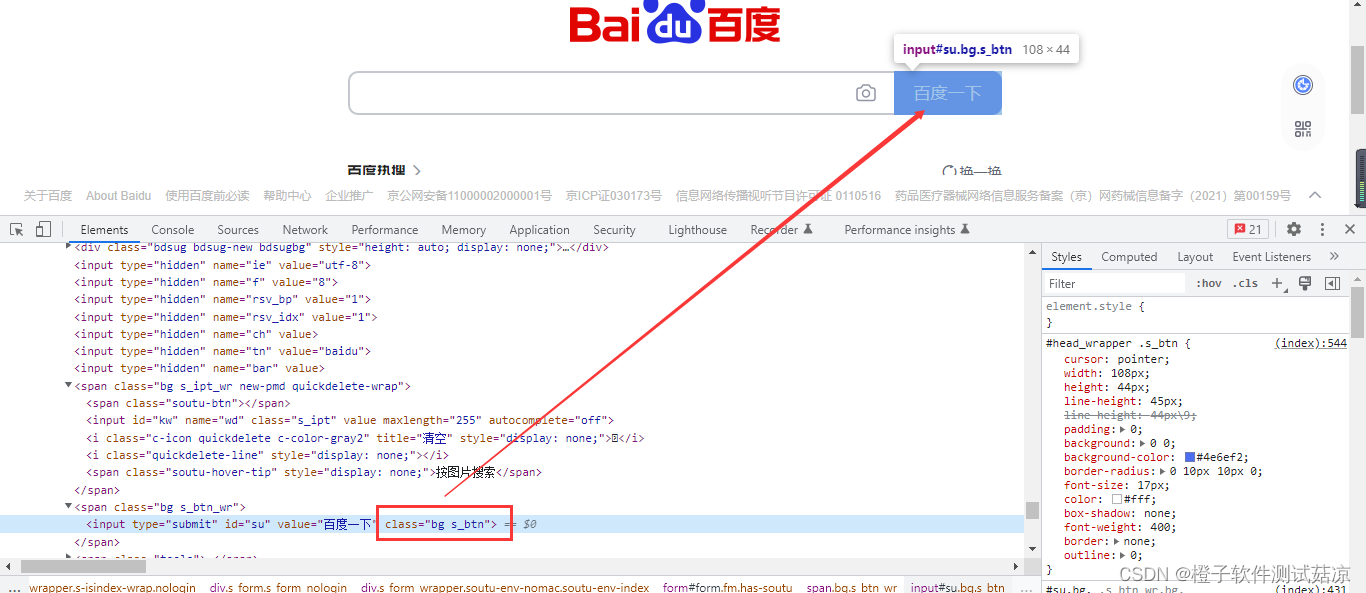
# 导入依赖 from selenium import webdriver import time class TestHogwarts(): def test_id(self): # 创建driver self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.implicitly_wait(5) # 打开百度网站 self.driver.get("https://www.baidu.com/") # 点击输入框 self.driver.find_element_by_id("kw").click() # 输入“霍格沃兹测试开发” self.driver.find_element_by_name("wd").send_keys("霍格沃兹测试开发") # 点击百度 self.driver.find_element_by_class_name("s_btn").click() # 等待两秒 time.sleep(2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
四、Css Selector定位
XPath 可以定位绝大多数元素,但是它采用从上到下的遍历模式,速度并不快,而 css_selector 采用样式定位,速度要优于 XPath,而且语法更简洁。
下面是 Selenium 使用 css_selector 的例子,css_selector 找到 class 属性为logo-big的元素:
driver.find_element_by_css_selector('.logo-big')- 1
选择器 例子 例子描述 .class .intro 选择 class = “intro” 的所有元素 #id #firstname 选择 id= "firstname " 的所有元素 * * 选择所有元素 element p 选择所有p元素 element,element div,p 选择所有div元素和选择所有p元素 element element div p 选择所有div元素内部的所有p元素 element>element div>p 选择父元素为div元素的所有p元素 element+element div+p 选择紧接在div元素之后的所有p元素 - 格式: driver.find_element(By.CSS_SELECTOR, “css 表达式”)
# 在console中的写法 # 元素,元素(选择所有bg、s_ipt_wr、new-pmd、quickdelete-wrap的元素) $('.bg,.s_ipt_wr,.new-pmd,.quickdelete-wrap') # 元素>元素(选择父元素id为s_kw_wrap元素下的所有input元素) $('#s_kw_wrap>input') # 元素 元素(选择所有form元素内部的所有input元素) $('#form input') # 元素+元素,了解即可(class为soutu-btn和input元素是相邻的兄弟的元素) $('.soutu-btn+input') # 元素1~元素2,了解即可(class为soutu-btn和i元素不是相邻的兄弟的元素) $('.soutu-btn~i')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
CSS 顺序关系
类型 格式 父子关系+顺序 元素 元素 父子关系+标签类型+顺序 元素 元素 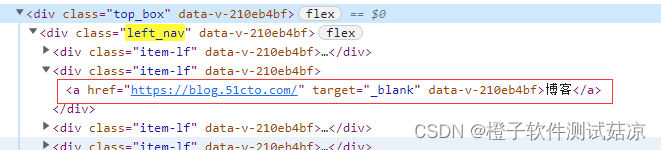
$(".left_nav>div:nth-child(2)")- 1
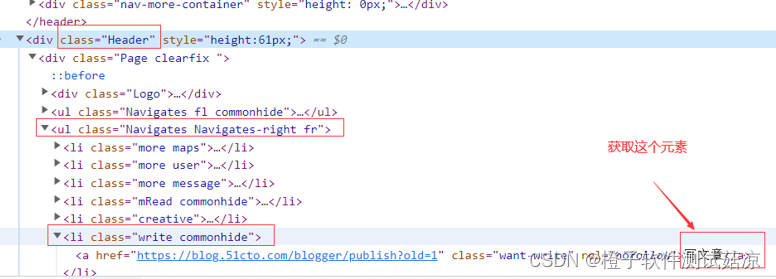
# .Header代表的是class为Header # div:nth-child(1)代表的是Header下的第一个div标签,因为Header下的所有元素的都是div标签,所以使用的是nth-child(1) # ul:nth-of-type(2)代表的是第一个div标签下的第二个ul标签,因为第一个div标签下的元素不是一样,所以使用的是nth-of-type(2) # li:nth-child(6)代表的是ul元素下的第6个li标签,因为都是li标签,所以使用的是nth-child $(".Header>div:nth-child(1)>ul:nth-of-type(2)>li:nth-child(6)")- 1
- 2
- 3
- 4
- 5
五、XPath定位
1、XPATH定义的概念
- XPath 是一门在 XML 文档中查找信息的语言
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 的应用非常广泛
- XPath 可以应用在UI自动化测试
2、xpath运用场景
- web自动化测试
- app自动化测试
3、xpath 基础语法
表达式 结果 / 从该节点的子元素选取 // 从该节点的子孙元素选取 * 通配符 nodename 选取此节点的所有子节点 … 选取当前节点的父节点 @ 选取属性 # 整个页面 $x("/") # 页面中的所有的子元素 $x("/*") # 整个页面中的所有元素 $x("//*") # 查找页面上面所有的div标签节点 $x("//div") # 查找id属性为site-logo的节点 $x('//*[@id="site-logo"]') # 查找节点的父节点 $x('//*[@id="site-logo"]/..')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4、xpath 顺序关系
- xpath通过索引直接获取对应元素
# 获取此节点下的所有的li元素 $x("//*[@id='ember21']//li") # 获取此节点下【所有的节点的】第一个li元素 $x("//*[@id='ember21']//li[1]")- 1
- 2
- 3
- 4
5、xpath 高级用法
- [last()]:选取最后一个
- [@属性名=‘属性值’ and @属性名=‘属性值’]:与关系
- [@属性名=‘属性值’ or @属性名=‘属性值’]:或关系
- [text()=‘文本信息’]:根据文本信息定位
- [contains(text(),‘文本信息’)]:根据文本信息包含定位
- 注意:所有的表达式需要和[]结合
# 选取最后一个input标签 //input[last()] # 选取属性name的值为passward并且属性pwd的值为123456的input标签 //input[@name='passward' and @pwd='123456'] # 选取属性name的值为passward或属性pwd的值为123456的input标签 //input[@name='passward' or @pwd='123456'] # 选取所有文本信息为'霍格沃兹测试开发'的元素 //*[text()='霍格沃兹测试开发'] # 选取所有文本信息包'霍格沃兹'的元素 //*[contains(text(),'霍格沃兹')] # 选取第二个input元素 //input[2] # 选取前2个input元素 input[postion()<3] # 选取所有value属性为text的元素 //*[@value='text']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
六、link text定位与 partial link text定位
元素中会出现文字,比如下面的分类,可以利用这段文字进行定位:
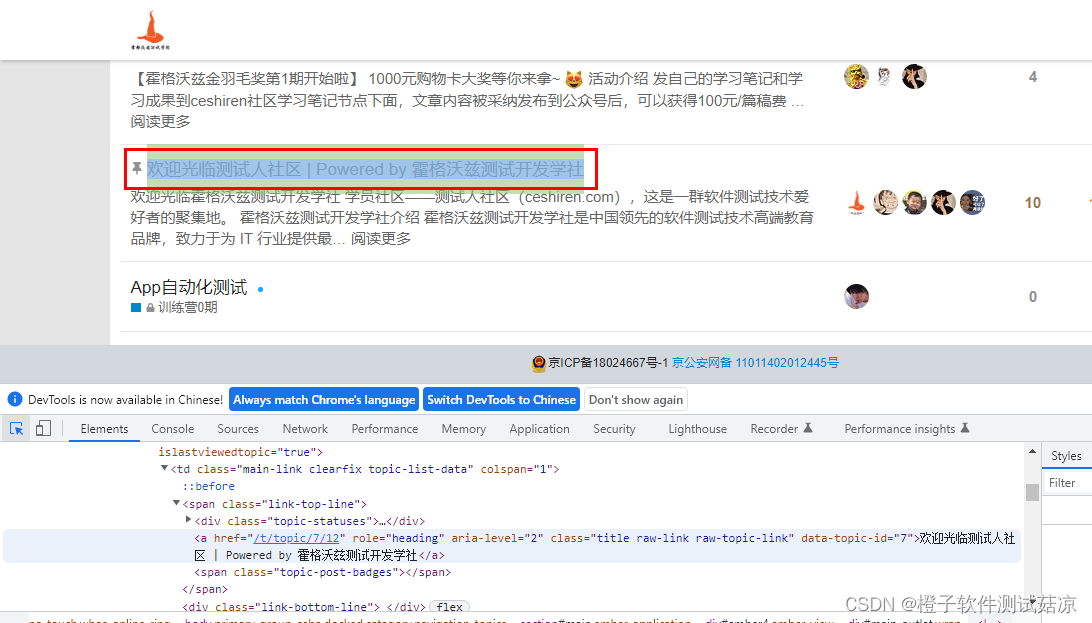
driver.find_element_by_link_text('欢迎光临测试人社区')- 1
也可以采用部分匹配方式,不必写全,可写成“欢迎光临”、“欢迎光临测试人社区”、“测试人”
driver.find_element_by_partial_link_text('测试人社区')- 1
七、Tag标签定位
DOM 结构中,元素都有自己的 tag 标签,比如 input 标签, button 标签, anchor 标签等等,每一个 tag 标签拥有多个属性,比如 id, name, value class,等等。下面的高亮部分就是 tag 标签:
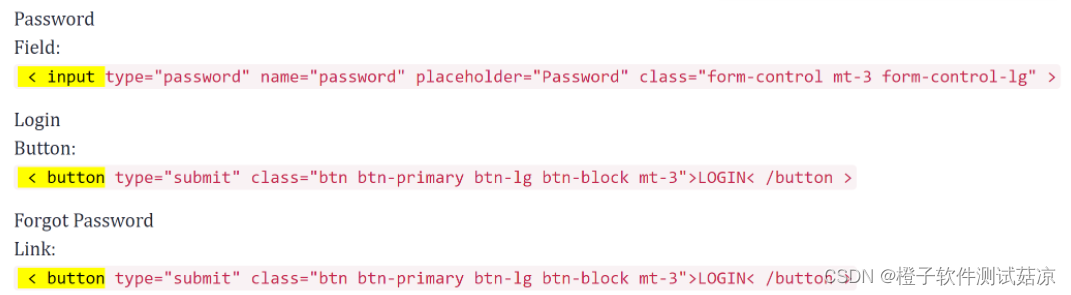
可以使用 tag 标签进行定位:driver.find_element_by_tag_name('input')- 1
- id定位语法格式: driver.find_element(By.ID, “ID属性对应的值”)
-
相关阅读:
解决数据重复插入问题(sql与锁方法)
在一款芯片中多个时钟域非常常见,跨时钟域检查至关重要。本篇记录的是CDC跨时钟域的基础概念。
USB-数据传输
抖音矩阵系统源码,抖音矩阵系统,抖音SEO源码。、
记录最近两次java内存过高的分析
计算机毕设(附源码)JAVA-SSM基于推荐算法的鞋服代购平台
Debian12换镜像源
ConcurrentHashMap--addCount()
跨站脚本攻击(XSS)以及如何防止它?
选择共享wifi项目哪个公司好?!
- 原文地址:https://blog.csdn.net/qq_43911915/article/details/126185265
