-
Redis中常见数据结构和数据类型
常见数据结构
- SDS简单动态字符串
- 双向链表
- 压缩列表
- 哈希表
- 跳表
- 整数集合
- quicklist
- listpack**
常见数据类型
1. String——字符串
2. List——列表(按照插入顺序排序)
3. Hash——哈希
4. Set——集合(无序并唯一)
5. Zset——有序集合(有序并唯一)
新增
6. BitMap(2.2版新增)
7. HyperLogLog(2.8版新增)
8. GEO(3.2版新增)
9. Stream(5.0版新增) 常见数据类型的底层是常见数据结构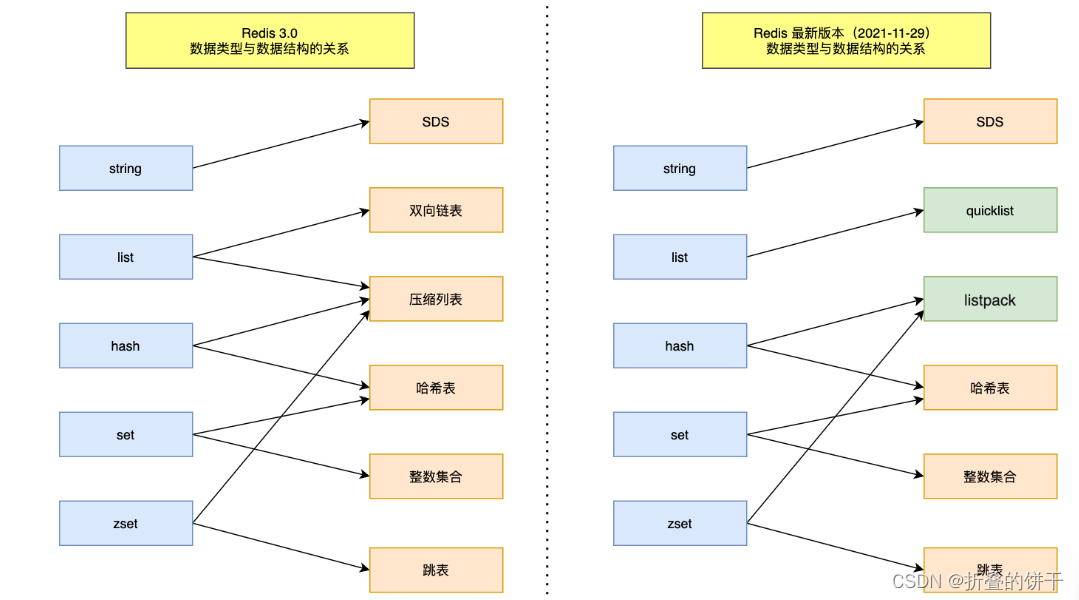
1. String——字符串
底层实现:
int +SDS(新增3个属性,3大优势)
基本操作:
# 设置 key-value 类型的值 > SET name lin OK # 根据 key 获得对应的 value > GET name "lin" # 判断某个 key 是否存在 > EXISTS name (integer) 1 # 返回 key 所储存的字符串值的长度 > STRLEN name (integer) 3 # 删除某个 key 对应的值 > DEL name (integer) 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
批量设置 :
# 批量设置 key-value 类型的值 > MSET key1 value1 key2 value2 OK # 批量获取多个 key 对应的 value > MGET key1 key2 1) "value1" 2) "value2"- 1
- 2
- 3
- 4
- 5
- 6
- 7
计数器(字符串的内容为整数的时候可以使用):
# 设置 key-value 类型的值 > SET number 0 OK # 将 key 中储存的数字值增一 > INCR number (integer) 1 # 将key中存储的数字值加 10 > INCRBY number 10 (integer) 11 # 将 key 中储存的数字值减一 > DECR number (integer) 10 # 将key中存储的数字值键 10 > DECRBY number 10 (integer) 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
过期(默认为永不过期):
# 设置 key 在 60 秒后过期(该方法是针对已经存在的key设置过期时间) > EXPIRE name 60 (integer) 1 # 查看数据还有多久过期 > TTL name (integer) 51 #设置 key-value 类型的值,并设置该key的过期时间为 60 秒 > SET key value EX 60 OK > SETEX key 60 value OK- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
不存在就插入:
# 不存在就插入(not exists) >SETNX key value (integer) 1- 1
- 2
- 3
应用场景
-
- 缓存对象
eg.对象JSON(SET user:1 ‘{“name”:“xxx”, “age”:18}’)
分离key(MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20)
- 缓存对象
-
- 常规计数
访问次数,点赞,转发,库存数量等
- 常规计数
-
- 分布式锁
setnx可以实现key不存在才插入,可以用它实现分布式锁
- 分布式锁
# 不存在就插入(not exists) >SETNX key value (integer) 1- 1
- 2
- 3
加锁
- 如果key不存在,则显示插入成功,表示加锁成功
- 如果key存在,则显示插入失败,表示加锁失败
一般还会对分布式锁加上时间
SET lock_key unique_value NX PX 10000- 1
- lock_key 就是 key 键;
- unique_value 是客户端生成的唯一的标识;
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
解锁
解锁需要保证执行操作的客户端是加锁的客户端才能删除- 先判断锁的unique_value是否为加锁的客户端
- 如果是,再删除
有两个操作,需要LUA脚本来保证解锁的原子性(Redis执行LUA脚本时,可以以原子方式执行,保证锁释放操作的原子性)
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end- 1
- 2
- 3
- 4
- 5
- 6
-
- 共享Session信息
通常开发后台管理系统时,会使用Session保存用户的会话(登录)状态,通常保存在服务器端,但只适用于单系统应用,如果是分布式系统将不适用
eg. 用户一的 Session 信息被存储在服务器一,但第二次访问时用户一被分配到服务器二,这个时候服务器并没有用户一的 Session 信息,就会出现需要重复登录的问题,问题在于分布式系统每次会把请求随机分配到不同的服务器。
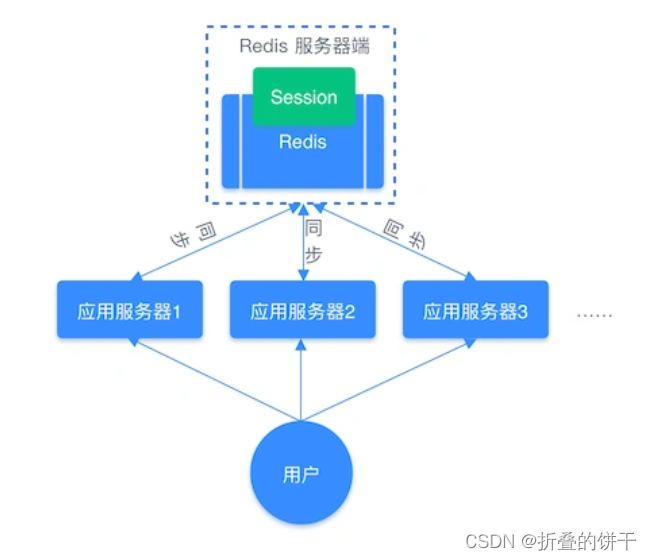
- 共享Session信息
2. List——列表
最大长度2^32-1
底层实现:
双向链表 / 压缩链表(元素个数小于512个,每个元素的值小于64字节)
按照插入顺序排序,可以从头部或尾部向List列表添加元素基本操作
# 将一个或多个值value插入到key列表的表头(最左边),最后的值在最前面 LPUSH key value [value ...] # 将一个或多个值value插入到key列表的表尾(最右边) RPUSH key value [value ...] # 移除并返回key列表的头元素 LPOP key # 移除并返回key列表的尾元素 RPOP key # 返回列表key中指定区间内的元素,区间以偏移量start和stop指定,从0开始 LRANGE key start stop # 从key列表表头弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞 BLPOP key [key ...] timeout # 从key列表表尾弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞 BRPOP key [key ...] timeout- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
应用场景
-
- 消息队列
消息队列在取消息时,必须满足三个需求
- 消息队列
- 消息保序
- 处理重复的消息
- 保证消息可靠性 Redis的List和Stream两种数据类型,可以满足消息队列的这三个需求
- List实现消息保序
本身就是按先进先出进行存取,可以使用 LPUSH + RPOP (或者反过来,RPUSH+LPOP)命令实现消息队列。
- 生产者:使用 LPUSH key value[value…] 将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息。
- 消费者:使用 RPOP key 依次读取队列的消息,先进先出。
问题:消费者不知道生产者是否发送消息,需要一直RPOP获取,导致消费者CPU一直小孩在执行RPOP命令上,带来不必要的性能损失
问题解决:提供BRPOP,阻塞式读取(客户端没读到队列时,自动阻塞,直到有新的数据写入队列,再开始读取新数据)
2. List处理重复的消息
实现重复消息判断的要求:1.每个消息都有一个全局id、2.消费者要记录已经处理过消息的id
全局 ID 为 111000102、库存量为 99 的消息插入了消息队列:LPUSH mq "111000102:stock:99" (integer) 1- 1
- 2
- 保证消息可靠性
当消费者程序从 List 中读取一条消息后,List 就不会再留存这条消息了。所以,如果消费者程序在处理消息的过程出现了故障或宕机,就会导致消息没有处理完成,那么,消费者程序再次启动后,就没法再次从 List 中读取消息了。
List提供BRPOPLPUSH命令,让消费者从程序的一个List中读取消息,同时把消息再插入到另一个List(备份List)留存
List作为消息队列的缺陷:
不支持多个消费者消费同一条消息
如果要实现多个消费者消费同一条消息,就要将多个消费者组成一个消费组。
Stream能够满足消息队列的三大需求,同时支持消费组形式的消息读取3. Hash——哈希
是一个键值对集合,特别适合用于存储对象
底层实现
压缩列表/哈希表
基本操作
# 存储一个哈希表key的键值 HSET key field value # 获取哈希表key对应的field键值 HGET key field # 在一个哈希表key中存储多个键值对 HMSET key field value [field value...] # 批量获取哈希表key中多个field键值 HMGET key field [field ...] # 删除哈希表key中的field键值 HDEL key field [field ...] # 返回哈希表key中field的数量 HLEN key # 返回哈希表key中所有的键值 HGETALL key # 为哈希表key中field键的值加上增量n HINCRBY key field- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
应用场景
- 缓存对象
对象可以通过String+Json存储,也可以通过HASH存储
一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。 - 购物车
以用户 id 为 key,商品 id 为 field,商品数量为 value
##添加商品: HSET cart:{用户id} {商品id} 1 ## 添加数量: HINCRBY cart:{用户id} {商品id} 1 ##商品总数: HLEN cart:{用户id} ##删除商品: HDEL cart:{用户id} {商品id} ##获取购物车所有商品: HGETALL cart:{用户id}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4. Set——集合
是一个无序并唯一的键值集合,存储顺序不会按照插入的先后顺序进行存储
最多可以存储2^32-1个元素,除了增删改查,还支持交集,并集,差集底层实现
哈希表/整数集合
基本操作
# 往集合key中存入元素,元素存在则忽略,若key不存在则新建 SADD key member [member ...] # 从集合key中删除元素 SREM key member [member ...] # 获取集合key中所有元素 SMEMBERS key # 获取集合key中的元素个数 SCARD key # 判断member元素是否存在于集合key中 SISMEMBER key member # 从集合key中随机选出count个元素,元素不从key中删除 SRANDMEMBER key [count] # 从集合key中随机选出count个元素,元素从key中删除 SPOP key [count]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
应用场景
集合的主要几个特性:无序、不可重复、支持并交差等操作
适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集
set的差集、并集和交集的计算复杂度较高,在数据量大的情况下,如果直接执行,会导致Redis实例阻塞。
在主从集群中,为了避免主库因为 Set 做聚合计算(交集、差集、并集)时导致主库被阻塞,我们可以选择一个从库完成聚合统计,或者把数据返回给客户端,由客户端来完成聚合统计。- 点赞
可以保证一个用户只能点一个赞
# uid:1 用户对文章 article:1 点赞 > SADD article:1 uid:1 (integer) 1 # uid:1 取消了对 article:1 文章点赞 > SREM article:1 uid:1 (integer) 1 # 获取 article:1 文章所有点赞用户 : > SMEMBERS article:1 1) "uid:3" 2) "uid:2"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 共同关注
# 获取共同关注 > SINTER uid:1 uid:2 1) "7" 2) "8" 3) "9" # 给 uid:2 推荐 uid:1 关注的公众号: > SDIFF uid:1 uid:2 1) "5" 2) "6"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 抽奖活动
保证同一个用户不会中奖两次
如果允许重复中奖,可以使用 SRANDMEMBER 命令。
# 抽取 1 个一等奖: > SRANDMEMBER lucky 1 1) "Tom" # 抽取 2 个二等奖: > SRANDMEMBER lucky 2 1) "Mark" 2) "Jerry"- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果不允许重复中奖,可以使用 SPOP 命令。
# 抽取一等奖1个 > SPOP lucky 1 1) "Sary" # 抽取二等奖2个 > SPOP lucky 2 1) "Jerry" 2) "Mark"- 1
- 2
- 3
- 4
- 5
- 6
- 7
5. Zset——有序集合
相比于set类型,多了一个排序属性score(分值)
集合key值不可以重复,但元素有序底层实现
压缩列表(元素个数小于128个,每个元素的值小于64字节时)/跳表
基本操作
# 往有序集合key中加入带分值元素 ZADD key score member [[score member]...] # 往有序集合key中删除元素 ZREM key member [member...] # 返回有序集合key中元素member的分值 ZSCORE key member # 返回有序集合key中元素个数 ZCARD key # 为有序集合key中元素member的分值加上increment ZINCRBY key increment member # 正序获取有序集合key从start下标到stop下标的元素 ZRANGE key start stop [WITHSCORES] # 倒序获取有序集合key从start下标到stop下标的元素 ZREVRANGE key start stop [WITHSCORES] # 返回有序集合中指定分数区间内的成员,分数由低到高排序。 ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] # 返回指定成员区间内的成员,按字典正序排列, 分数必须相同。 ZRANGEBYLEX key min max [LIMIT offset count] # 返回指定成员区间内的成员,按字典倒序排列, 分数必须相同 ZREVRANGEBYLEX key max min [LIMIT offset count]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Zset 运算操作(相比于 Set 类型,ZSet 类型没有支持差集运算):
# 并集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积 ZUNIONSTORE destkey numberkeys key [key...] # 交集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积 ZINTERSTORE destkey numberkeys key [key...]- 1
- 2
- 3
- 4
应用场景
- 排行榜(从小到大)
如果数据更新频繁或者需要分页显示,可以优先考虑使用Sorted Set
# arcticle:1 文章获得了200个赞 > ZADD user:xiaolin:ranking 200 arcticle:1 (integer) 1 # arcticle:2 文章获得了40个赞 > ZADD user:xiaolin:ranking 40 arcticle:2 (integer) 1- 1
- 2
- 3
- 4
- 5
- 6
# 文章 arcticle:4 新增一个赞 > ZINCRBY user:xiaolin:ranking 1 arcticle:4 "51"- 1
- 2
- 3
# 获取文章赞数最多的 3 篇文章,可以使用 ZREVRANGE 命令(倒序获取有序集合 key 从start下标到stop下标的元素): > ZREVRANGE user:xiaolin:ranking 0 2 WITHSCORES 1) "arcticle:1" 2) "200" 3) "arcticle:5" 4) "150" 5) "arcticle:3" 6) "100"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 电话、姓名排序
> ZRANGEBYLEX names [A (B 1) "Aidehua" 2) "Aimini"- 1
- 2
- 3
6. BitMap(2.2版新增)
位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素,通过最小的单位bit进行0|1的设置,表示某个元素的值或状态,时间复杂度O(1)
适用于数据量大且使用二值统计的场景,在记录海量数据时,Bitmap 能够有效地节省内存空间。底层实现
String
保存为二进制的字节数组基本操作
# 设置值,其中value只能是 0 和 1 SETBIT key offset value # 获取值 GETBIT key offset # 获取指定范围内值为 1 的个数 # start 和 end 以字节为单位 BITCOUNT key start end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
bitmap 运算操作:
# BitMap间的运算 # operations 位移操作符,枚举值 AND 与运算 & OR 或运算 | XOR 异或 ^ NOT 取反 ~ # result 计算的结果,会存储在该key中 # key1 … keyn 参与运算的key,可以有多个,空格分割,not运算只能一个key # 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0。返回值是保存到 destkey 的字符串的长度(以字节byte为单位),和输入 key 中最长的字符串长度相等。 BITOP [operations] [result] [key1] [keyn…] # 返回指定key中第一次出现指定value(0/1)的位置 BITPOS [key] [value]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
应用场景
注意offset从0开始
- 签到统计
# 签到6.3 SETBIT uid:sign:100:202206 2 1 # 判断6.3是否签到 GETBIT uid:sign:100:202206 2 # 统计该用户在6月的签到次数 BITCOUNT uid:sign:100:202206 # 统计这个月首次打卡时间 # BITPOS key bitValue [start] [end] 可选的 start 参数和 end 参数指定要检测的范围 BITPOS uid:sign:100:202206 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 判断用户登录态
- 连续签到用户总数
key每天的日期 value打卡用户
一共有 7 个这样的 Bitmap,对这 7 个 Bitmap 的对应的 bit 位做与运算。
Redis 提供了 **BITOP operation destkey key [key …]**这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。
opration 可以是 and、OR、NOT、XOR。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0 。空的 key 也被看作是包含 0 的字符串序列。
# 与操作 BITOP AND destmap bitmap:01 bitmap:02 bitmap:03 # 统计 bit 位 = 1 的个数 BITCOUNT destmap- 1
- 2
- 3
- 4
即使一天产生一个亿的数据,Bitmap 占用的内存也不大,大约占 12 MB 的内存(10^8/8/1024/1024),7 天的 Bitmap 的内存开销约为 84 MB。同时我们最好给 Bitmap 设置过期时间,让 Redis 删除过期的打卡数据,节省内存。
7. HyperLogLog(2.8版新增)
8. GEO(3.2版新增)
9. Stream(5.0版新增) 常见数据类型的底层是常见数据结构
键值对数据库的实现
键key:字符串对象(String)
值value:字符串对象(String)/集合数据类型的对象(List、Hash、Set、Zset)
Redis采用哈希表保存所有键值对
哈希表就是一个数组,数组中的元素叫做哈希桶,哈希桶存放指向键值对数据的指针(dictEntry*),这样就可以通过指针找到键值对数据
由于键值对数据结构不是直接保存值本身,而是保存了void *key,void *value指针,分别指向实际的键对象和值对象哈希表优点:查找时间复杂度O(1)
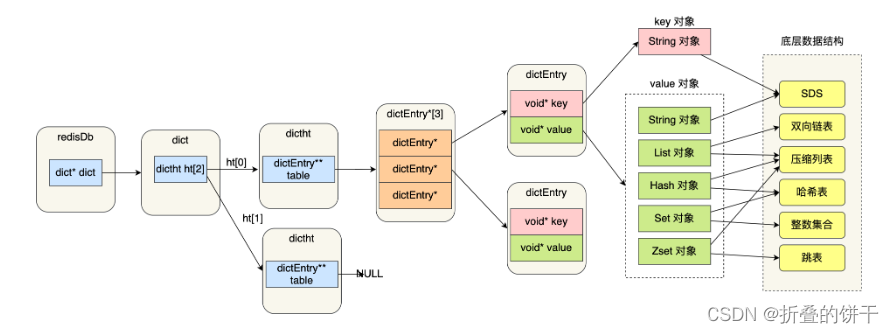
redisDb结构,表示Redis数据库的结构——存放了指向dict结构的指针
dict结构,结构体里存放了2个哈希表——大小为2的dictht数组 哈希表1:正常情况下用 哈希表2:rehash时用
dictht结构,表示哈希表结构
dictEntry,表示哈希表节点结构,里面存放void *key和void *value指针SDS
redis通过c语言实现,而redis对于字符串类型,不直接使用char*字符串数组,而是封装了一个名为sds简单动态字符串(simple dynamic string)的结构,解决char *字符数组的一些缺陷
c语言字符串的缺陷
-
c语言获取字符串长度的时间复杂度是O(N)
c语言通过‘\0’标识字符串结尾,strlen通过遍历字符串计数,遇到‘\0’停止遍历 -
二进制不安全,不能保存像图片、音频、视频文化这样的二进制数据
如果字符串中有’\0’,strlen就是提前终止 -
字符串操作函数strcat不高效且不安全,可能会造成缓冲区溢出,程序终止
c语言字符串不会记录缓冲区大小,strcat遍历完字符串后进行追加,缓冲区不够,则会溢出
SDS结构设计
在char *buf[]字符数组基础上增加
- len——记录字符串长度
获取字符串时间复杂度O(1) - alloc——分配给字符数组的空间长度
通过alloc-len计算剩余可用空间大小,可以在修改时判断缓冲区大小是否可用,不够用时,Redis将自动扩大SDS空间大小(小于1MB扩大一倍(len+1[\0]+len),大于1MB扩大1MB(len+1+1MB),以满足修改所需的大小,且有效减小预分配次数,不需要手动修改大小,也不会发生缓冲区溢出,实现了内存空间预分配和惰性空间释放 - flags——用来表示不同类型的sds
Redis 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
这 5 种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同。
设计不同的结构体,是为了灵活保存不同大小字符串,有效节约空间
除了设计不同类型的结构体,Redis 在编程上还使用了专门的编译优化来节省内存空间,即在 struct 声明了 attribute ((packed)) ,它的作用是:告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐。
跳表
是一种可以实现查找的多层有序链表,每个层级的结点都通过指针连接起来
只有zset对象底层实现用到了跳表优势
支持平均时间复杂度为**O(logN)**复杂度的查找(单点查找和范围查找)
结构

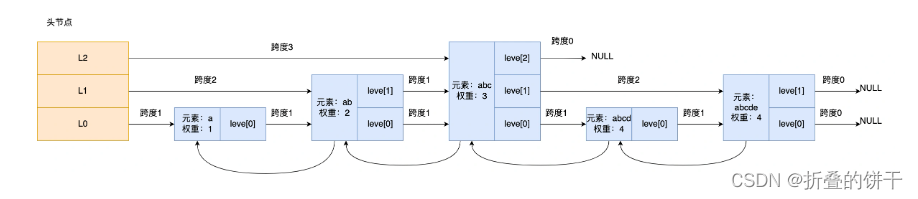
包含两个数据结构
1.zskiplistnode
2. zskiplistzskiplist包含
1. 跳表头head
2. 尾tail
3. 最大层级level
4. 跳表长度typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;- 1
- 2
- 3
- 4
- 5
zskiplistnode包含
1. sds元素
2. double元素权重
3. 后退指针(指向前一个结点,方便从跳表尾结点开始访问结点)
4. level数组(保存每层的前向指针和跨度(计算结点在跳表中的排位——沿途访问过的所有层的跨度累加起来)typedef struct zskiplistNode { //Zset 对象的元素值 sds ele; //元素权重值 double score; //后向指针 struct zskiplistNode *backward; //节点的level数组,保存每层上的前向指针和跨度 struct zskiplistLevel { struct zskiplistNode *forward; unsigned long span; } level[]; } zskiplistNode;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
查询过程
- 从最高层开始查
- 如果权重小于当前结点权重/等于当前结点权重且sds类型数据小于当前节点:访问该层的下一个结点
- 如果上面两个条件都不满足或下一结点为空,使用level数组的下一层指针进行查找
结点层数设置
跳表相邻两层节点数量比例会影响跳表的查询性能
趋近0:1就相当于退化成一个链表了
理想情况:相邻两层节点数量最理想的比例是2:1,能够进行二分查找,查找复杂度可以降到O(logN)Redis采用的方法:
在创建节点时,随机生成0-1的随机数,随机数小于0.25(25%概率),层数增加1层,然后继续生成下一个随机数,直到随机数>0.25结束,最终确定层数
相当于每增加一层的概率不超过25%,层数越高,概率越低,层高最大限制为64哈希
本质
数组
根据key值通过hash函数确定Entry键值对放在数组的位置
优点:查询数据时间复杂度O(1)
缺点:哈希表固定的情况下,哈希冲突可能性也会很高解决哈希冲突方法**
- 开放寻址法——当前位置被占,继续遍历找下一个空位
缺点:
会占满
解决方法:
扩容
增长因子:已经占的位置与总位置的百分比
Java中HashMap在增长因子达到75%时扩容(新建一个数组为原来两倍,然后把原数组数据放进去) - 拉链法——分配在同一个哈希桶上的节点通过next指针连接成一个单链表
缺点:
链表过长,查找时间复杂度从O(1)退化到O(N)
解决方法:
Java中HashMap,如果当前链表长度大于等于8的话,链表就会转换成树结构,当然如果长度小于等于6的话,就会还原链表。以此来解决链表过长导致的性能问题。中间有个7作为一个差值,来避免频繁的进行树和链表的转换。
Redis采用拉链法解决哈希冲突
解决拉链法链表过长的方法——rehash
Redis定义dict结构体,包含两个dictht哈希表
resh通过这两个hash表进行实现
步骤:- 给hash表2分配空间,一般比hash表1大1倍
- 将hash表1数据迁移到hash表2
- 迁移完成后,释放hash表1空间,将hash表2设置为hash表1,在hash表2新创建一个空白的hash表,为下次rehash做准备
解决rehash在数据迁移中,因拷贝数据耗时而影响Redis性能——渐进式rehash
也就是将数据迁移由分一次变为分多次迁移
步骤:- 给hash表2分配空间
- 在rehash期间,每次哈希表执行增删改查操作时,顺序将hash表1中索引位置上的所有key-value迁移到hash表2
eg.新增元素直接插入到hash表2
查找元素时hash表2如果查不到就到hash表1中查 - 最终在某个时间点完成rehash操作
rehash触发条件
与负载因子有关
负载因子=哈希表已保存节点数量/哈希表大小
当负载因子≥1,在没有执行RDB快照(执行bgsave命令)/AOF重写(执行bgrewriteaof命令)时,进行rehash操作
当负载因子≥5,此时哈希冲突非常严重,不管有没有执行RDB快照和AOF重写,都会强制进行rehash操作 -
相关阅读:
L - Median
微信小程序与idea后端如何进行数据交互
外汇天眼:中国银行马尼拉分行推出数字外汇!
边端融合系统安全风险分析及评估方法
WPF动画小知识
C++|前言
一篇了解全MVCC
CentOS和Ubantu的Mysql主从配置
一分钟秒懂人工智能对齐
pytest-allure报告
- 原文地址:https://blog.csdn.net/weixin_45627369/article/details/125892969
