-
KDD'22 | 对比学习+知识蒸馏,Bing搜索广告最新利器!

作者 | Maple小七
整理 | NewBeeNLP
大家好,这里是NewBeeNLP。今天我们分享Bing在搜索广告的最新技术细节,来自微软和北航的合作工作,发表在KDD 2022。
Uni-Retriever: Towards Learning The Unified Embedding Based Retriever in Bing Sponsored Search
https://arxiv.org/abs/2202.06212
不同于NLP中的文本相关性任务,搜索广告模型的训练有着多个优化目标:给定一个用户查询,模型需要返回高相关性且高点击率的广告,但简单地在点击日志上训练模型并不能有效地建模用户查询和广告的语义相关性,这可能会导致某些广告的点击率(CTR)虽然很高,但转化率(CVR)却很低。
针对这一问题,借助于知识蒸馏和对比学习技术,本文提出了一个联合建模相关性和点击率的召回模型:Uni-Retriever,同时提出了一系列模型训练策略提升最终性能,目前Uni-Retriever已成为Bing搜索广告的主要召回路径之一。
Introduction
随着深度神经网络和近似最近邻检索技术的发展, 向量检索(embedding based retrieval, EBR) 在问答、搜索、广告、推荐等应用场景中已经是一条不可或缺的召回路径。
其中,搜索广告(sponsored search) 是搜索引擎和网购平台的重要收入来源之一,给定一个用户查询,一个搜索广告系统需要检索出不仅与用户查询意图高度相关 (high-relevance) ,而且用户最有可能会点击的广告 (high-CTR) 。
因此,相比于问答、搜索这类仅需要建模文本相关性的任务,搜索广告面临的是一个更复杂的多目标优化问题。
下面举一个具体的例子来阐述搜索广告的多目标性,给定一个用户的query:“Secondhand Chevy”(二手雪佛兰),返回的Ad-1虽然相关性很高,但点击率却很低,这是因为Ad-1缺少了商家名称,导致该广告看上去可信度不高;Ad-2的点击率很高,但相关性却很低,这是因为虽然该广告给出了商家名称,但却没有很好地满足用户的查询意图;Ad-3的相关性和点击率都很高,该条广告正是我们希望搜索广告系统能够返回的结果。

因此,一个高相关的广告不一定有高点击率,一个高点击率的广告也不一定高相关,由于用户查询和高相关高点击率广告之间的标注数据很难获得,因此想要训练一个能够准确返回高相关高点击率的广告的向量检索模型并不容易。
但是,单独的高相关和高点击率的监督数据却很容易得到, 因为我们常用的web搜索引擎就是在建模文本的语义相关性,而大规模的点击日志天然地为我们的点击率预估模型提供了充分的训练数据。
基于这一观察,本文提出一个面向Bing搜索广告业务的表示学习框架: Uni-Retriever (the Unified Embedding Based Retriever) ,它将两个不同的训练模式: 对比学习(contrastive learning) 和 知识蒸馏(knowledge distillation) 进行了有效融合,其中对比学习用于从大规模点击日志中学习点击率建模能力,而知识蒸馏用于从现有的文本语义相关性模型中蒸馏出query和ads的相关性建模能力,从而同时满足了搜索广告的高相关性和高点击率的建模目标。一系列离线和在线实验表明Uni-Retriever显著改善了服务质量,目前Uni-Retriever已成为了Bing搜索广告业务的主要召回路径。
另外,搜索广告系统通常需要在短时间内从几十亿的广告库中筛选出和用户查询最相关的广告,而常用的ANN算法,比如HNSW、NSG、IVFPQ,要么会带来巨大的内存开销,要么会导致召回率大幅下降。
因此本文给出了一套基于DiskANN的大规模向量检索系统的部署方案,在低时延、低内存消耗的条件下实现了检索结果的高召回率,由于本人对ANN技术没有做深入研究,因此这里不做具体讲解。
Uni-Retriever
搜索广告的召回阶段所面临的多目标优化问题可以表达为下面的形式:
即在保证文本相关性的前提下最大化返回结果的点击率,其中是通过最大内积搜索(MIPS)算法检索得到的候选广告集合。表示相关性打分阈值,为了方便端到端优化,我们可以对该优化目标做一个松弛:
402 Payment Required
即模型的训练目标为相关性目标和点击率目标的线性加权,其中用于调节相关性和点击率的重要程度。
Knowledge Distillation
针对相关性建模,我们可以使用现有的相关性教师模型以知识蒸馏的方式来训练Uni-Retriever,而本文使用的相关性教师模型是一个基于BERT的交叉编码器(cross-encoder):
402 Payment Required
其中将输出向量映射到实值,为sigmoid函数,该模型在人工标注的相关性数据集上得到了充分的训练。
在知识蒸馏的训练过程中,教师模型为输入的query和ad计算相关性分数作为监督信号,然后Uni-Retriever优化如下的MSE loss:
402 Payment Required
Contrastive Learning
针对点击率建模,Uni-Retriever优化如下的InfoNCE loss:
402 Payment Required
其中为点击正样本,为采样的负样本集合。众所周知,对比学习的性能十分依赖于负样本的构建方式,一般来说,负样本越多,越难,对比学习也就越有效,因此作者也分别提出了下面的两个技巧来提升负样本的数量和质量。
Cross-device Negative Sampling: 针对负样本的数量问题,作者提出了跨设备负采样技巧扩大batch size,也就是在多GPU训练时,将输入到其他GPU的负样本也当作当前GPU的负样本,作为当前GPU的一个额外的梯度补偿,其本质上就是RocketQA提出的cross-batch策略。
ANN based hard negatives: 针对负样本的质量问题,作者利用上一版的Uni-Retriever挖掘高相关性的负样本。具体来说,首先利用召回模型获取召回Top-200候选广告集并按相关性从大到小排序,然后在Top-100~200候选广告集中随机采样负样本,该技巧同样是检索召回模型的常用训练技巧。
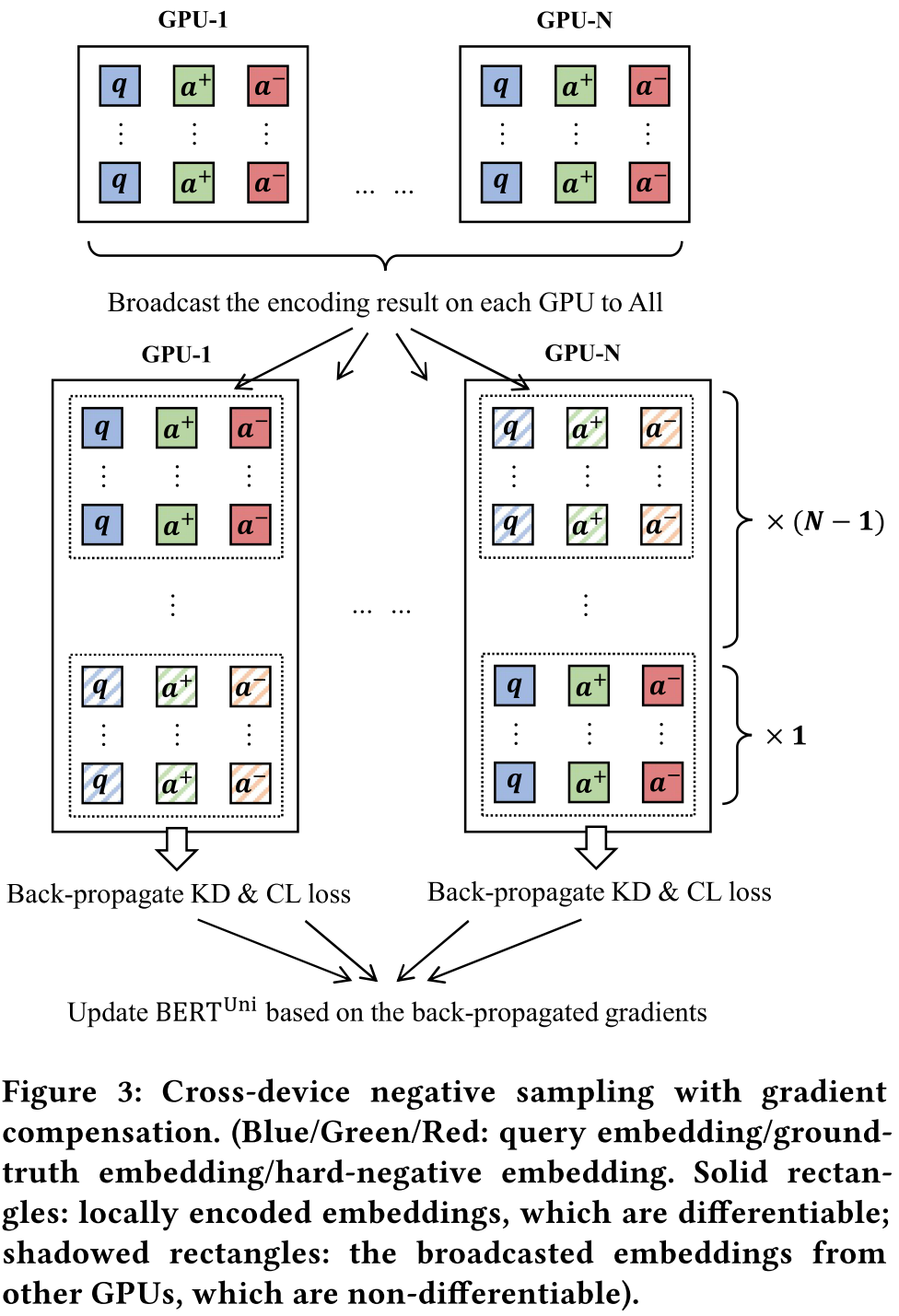
Disentangle and Multi-objective Learning
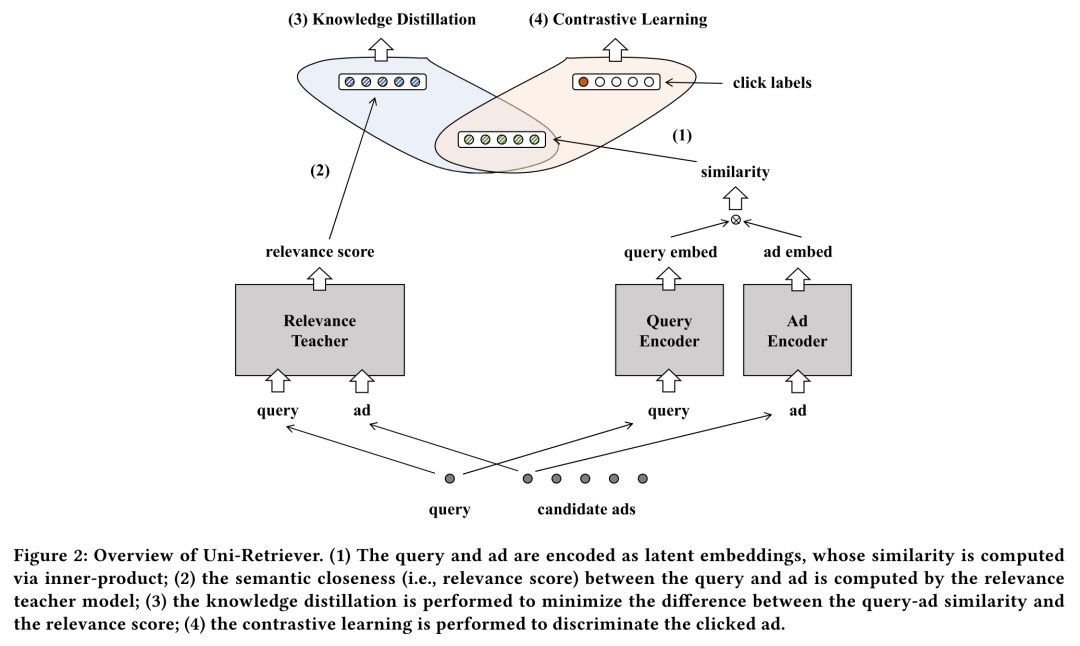
直觉上来说,将相关性embedding和点击率embedding解耦能够获得更好的性能,因此作者设置了两个不同的pooling head。
优化相关性目标时,模型输出的embedding为,优化点击率目标时,模型输出的embedding为,在用于推理测试时,将这两个大小相同的embedding相加并归一化得到最终的embedding表示。
整体的训练过程如下图所示,在训练过程中我们联合优化知识蒸馏损失和对比损失,需要注意的是,由于相关性建模中cross-encoder的编码成本很高,因此知识蒸馏损失仅应用于点击正样本以提升训练速度。
Experiments
Offline Test
作者收集了15亿的真实query-ad pairs,其中570万的query-ad pairs用于模型测试,同时抽取了2000万个广告作为模型测试阶段的ad corpus。作者使用Hit@K(点击样本的Top-k召回率)、Rel@K(Top-k检索结果的平均相关性)作为召回结果的评估指标。
作者从基线模型开始,一步一步加入如下的改进策略:
Baseline: 在点击日志上使用对比学习训练,每个query在ad corpus中随机采样10个负样本。
+Multi-obj: 加入基于知识蒸馏的相关性建模目标;
+Disentangle: 训练时将相关性和点击率建模的向量解耦;
+In-batch: 将随机负样本优化为批内负样本;
+Cross-device: 加入跨设备负样本策略;
+ANN negative: 加入ANN召回的难负样本(Top200随机采样)
+Score filter: 加入难负样本筛选策略(删除Top200中相关性高于0.5的样本)
+Rank filter: 修改难负样本筛选策略(删除Top0-100的样本)
最终实验结果如下表所示,可以看到,上述策略中能够带来大幅提升的策略包括
+Multi-obj、+In-batch、+ANN negative,这三大策略目前实际上已经广泛地应用在了各类向量检索模型的训练中: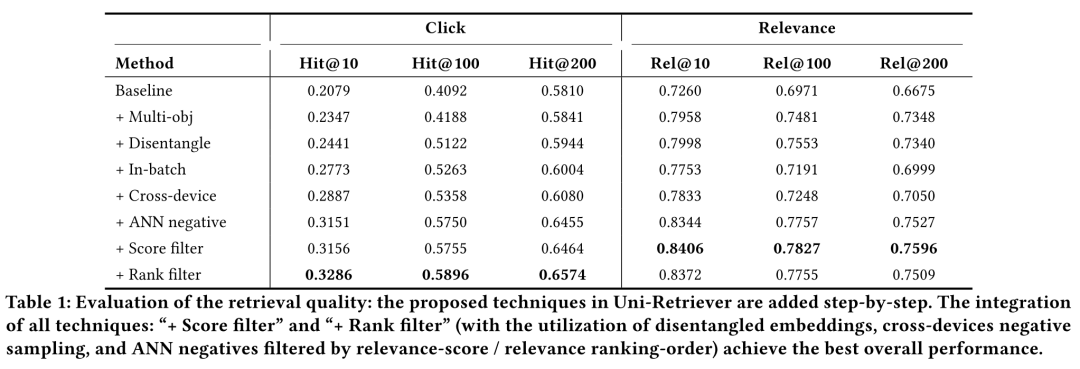
Online A/B Test
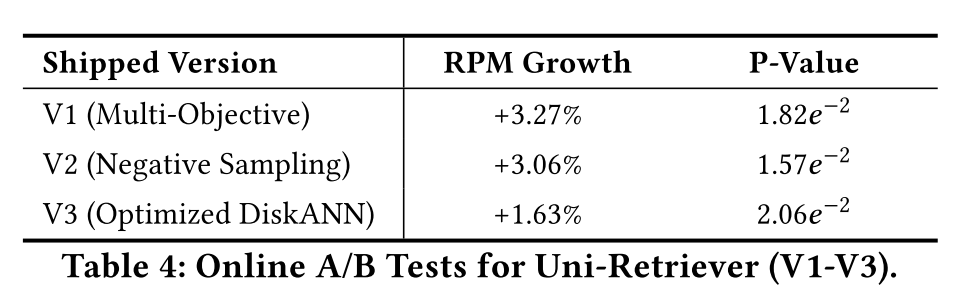
作者给出了三次线上迭代的A/B测试的结果,其中V1为加入了基于知识蒸馏和对比学习的多目标优化,V2在V1的基础上优化了负采样策略(跨设备采样和ANN难负样本采样),V3将ANN索引替换为了DiskANN,每次迭代均显著提升了RPM值(Revenue Per Mille)。
Conclusion
本文是一篇来自工业界的论文,对于绝大部分ToC的互联网公司来说,搜索广告业务都是一个重要的收入来源,而搜索广告业务中存在的问题也远比学术界中简单的文本相关性匹配来得复杂。
实际上,搜索问答业务中也存在一些多目标优化问题,但这些问题却很少被NLP社区所注意。因此学术界和工业界互相合作是很重要的,工业界常会借鉴学术界研究出来的新模型在各种业务上做尝试,学术界也应该更多地关注工业界中存在的痛点问题,而不是在现有的模型上做启发式的修补。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

-
相关阅读:
请求 响应
KubeSphere 3.3.0 离线安装教程
9月大型语言模型研究论文总结
Tableau 自定义调色板及应用全流程讲解【保姆级】
面试常问:数组拍平(扁平化)实现
最新Cocos Creator 3.x 如何动态修改3D物体的透明度
电脑重装系统c盘如何备份资料
0基础python全栈教程前言,0基础学习python难不难
RabbitMQ传递序列化/反序列化自定义对象时踩坑
创建SpringCloudGateWay
- 原文地址:https://blog.csdn.net/Kaiyuan_sjtu/article/details/126357696