-
YoloV7实战:手把手教你使用Yolov7进行物体检测(附数据集)
摘要
YoloV6出来没有多久,YoloV7就开始流行了。如今的Yolo系列的模型都是沿用了YoloV3的架构,大家都是在卷积上做了一些更改。Yolov6和Yolov7都加入了Rep的结构。如图:

图片来自:https://zhuanlan.zhihu.com/p/543743278
YOLOv7 在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的物体检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时物体检测器中具有最高的准确度 56.8% AP。
论文翻译:https://wanghao.blog.csdn.net/article/details/126302859
代码:https://github.com/WongKinYiu/yolov7
论文链接:https://arxiv.org/abs/2207.02696
今天我们一起学习如何使用YoloV7训练自己的数据集数据集
数据集是我自己标注的飞机数据集,下载地址:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/63242994。
总共32种飞机:
[‘c17’, ‘c5’, ‘helicopter’, ‘c130’, ‘f16’, ‘b2’, ‘other’, ‘b52’, ‘kc10’, ‘command’, ‘f15’, ‘kc135’, ‘a10’, ‘b1’, ‘aew’, ‘f22’, ‘p3’, ‘p8’, ‘f35’, ‘f18’, ‘v22’, ‘f4’, ‘globalhawk’, ‘u2’, ‘su-27’, ‘il-38’, ‘tu-134’, ‘su-33’, ‘an-70’, ‘su-24’, ‘tu-22’, ‘il-76’]
接下来是如何制作yolov6数据集,yolov6使用的数据集格式和yolov5一样。如图:
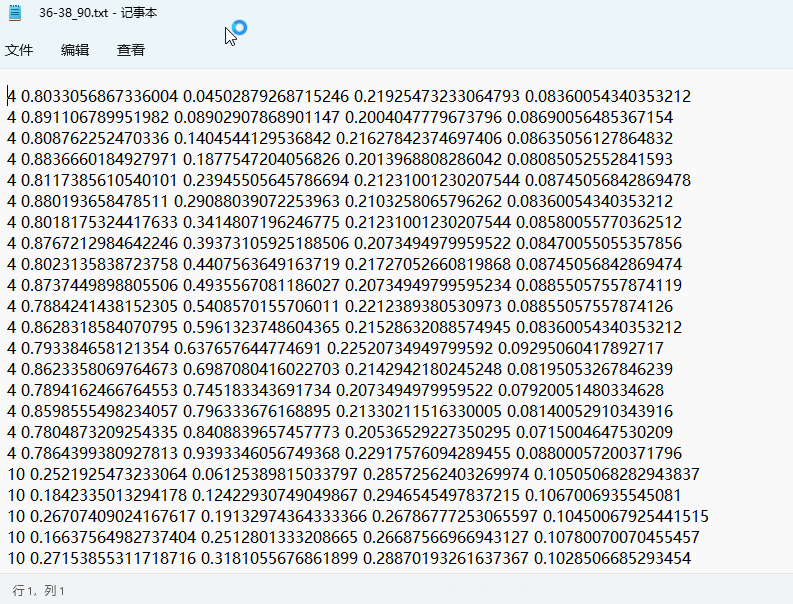
格式:类别,中心点x,中心点y,w,h。
新建脚本make_yolo_data.py,插入代码:import os import shutil import numpy as np import json from glob import glob import cv2 from sklearn.model_selection import train_test_split from os import getcwd def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = (box[0] + box[1]) / 2.0 - 1 y = (box[2] + box[3]) / 2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def change_2_yolo5(files, txt_Name): imag_name=[] for json_file_ in files: json_filename = labelme_path + json_file_ + ".json" out_file = open('%s/%s.txt' % (labelme_path, json_file_), 'w') json_file = json.load(open(json_filename, "r", encoding="utf-8")) # image_path = labelme_path + json_file['imagePath'] imag_name.append(json_file_+'.jpg') height, width, channels = cv2.imread(labelme_path + json_file_ + ".jpg").shape for multi in json_file["shapes"]: points = np.array(multi["points"]) xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0 xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0 ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0 ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0 label = multi["label"].lower() if xmax <= xmin: pass elif ymax <= ymin: pass else: cls_id = classes.index(label) b = (float(xmin), float(xmax), float(ymin), float(ymax)) bb = convert((width, height), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') # print(json_filename, xmin, ymin, xmax, ymax, cls_id) return imag_name def image_txt_copy(files,scr_path,dst_img_path,dst_txt_path): """ :param files: 图片名字组成的list :param scr_path: 图片的路径 :param dst_img_path: 图片复制到的路径 :param dst_txt_path: 图片对应的txt复制到的路径 :return: """ for file in files: img_path=scr_path+file print(file) shutil.copy(img_path, dst_img_path+file) scr_txt_path=scr_path+file.split('.')[0]+'.txt' shutil.copy(scr_txt_path, dst_txt_path + file.split('.')[0]+'.txt') if __name__ == '__main__': classes = ['c17', 'c5', 'helicopter', 'c130', 'f16', 'b2', 'other', 'b52', 'kc10', 'command', 'f15', 'kc135', 'a10', 'b1', 'aew', 'f22', 'p3', 'p8', 'f35', 'f18', 'v22', 'f4', 'globalhawk', 'u2', 'su-27', 'il-38', 'tu-134', 'su-33', 'an-70', 'su-24', 'tu-22', 'il-76'] # 1.标签路径 labelme_path = "USA-Labelme/" isUseTest = True # 是否创建test集 # 3.获取待处理文件 files = glob(labelme_path + "*.json") files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files] for i in files: print(i) trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55) # split train_files, val_files = train_test_split(trainval_files, test_size=0.1, random_state=55) train_name_list=change_2_yolo5(train_files, "train") print(train_name_list) val_name_list=change_2_yolo5(val_files, "val") test_name_list=change_2_yolo5(test_files, "test") #创建数据集文件夹。 file_List = ["train", "val", "test"] for file in file_List: if not os.path.exists('./VOC/images/%s' % file): os.makedirs('./VOC/images/%s' % file) if not os.path.exists('./VOC/labels/%s' % file): os.makedirs('./VOC/labels/%s' % file) image_txt_copy(train_name_list,labelme_path,'./VOC/images/train/','./VOC/labels/train/') image_txt_copy(val_name_list, labelme_path, './VOC/images/val/', './VOC/labels/val/') image_txt_copy(test_name_list, labelme_path, './VOC/images/test/', './VOC/labels/test/')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
转换完成后就可以得到用于训练的数据集了,如下图:
核心思路:
第一步 使用train_test_split方法切分出训练集、验证集和测试集。
第二步 调用change_2_yolo5方法将json里面的数据转为yolov5格式的txt数据,返回训练集、验证集和测试集的图片list。
第三步 创建数据集文件夹,然后将图片和txt文件copy到对应的目录下面。
接下来就开始训练了训练
有了数据集就可以开始训练了。下载yolov7的代码,将其解压到指定的位置,然后将数据集复制到yolov7的根目录。如下图:
然后下载yolov7的权重,下载地址:
https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt
如果下载中断可以使用迅雷下载。
下载完成后放在YoloV7项目的根目录。
在data目录增加VOC.yaml
在里面填写如下内容:# Please insure that your custom_dataset are put in same parent dir with YOLOv7_DIR train: ./VOC/images/train # train images val: VOC/images/val # val images test: VOC/images/test # test images (optional) # whether it is coco dataset, only coco dataset should be set to True. is_coco: False # Classes nc: 32 # number of classes names: ['c17', 'c5', 'helicopter', 'c130', 'f16', 'b2', 'other', 'b52', 'kc10', 'command', 'f15', 'kc135', 'a10', 'b1', 'aew', 'f22', 'p3', 'p8', 'f35', 'f18', 'v22', 'f4', 'globalhawk', 'u2', 'su-27', 'il-38', 'tu-134', 'su-33', 'an-70', 'su-24', 'tu-22', 'il-76']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
修改train.py里面的参数
parser.add_argument('--weights', type=str, default='yolov7.pt', help='initial weights path') parser.add_argument('--cfg', type=str, default='cfg/training/yolov7.yaml', help='model.yaml path') parser.add_argument('--data', type=str, default='data/VOC.yaml', help='data.yaml path') parser.add_argument('--epochs', type=int, default=300) parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs') parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')- 1
- 2
- 3
- 4
- 5
- 6
weights:权重文件。
cfg:yolov7模型配置文件。
data:数据配置文件
workers:在win系统下面设置为0,否则报错。上面修改了,检查一下环境配置是否正确,依赖包是否都安装了。
# Usage: pip install -r requirements.txt # Base ---------------------------------------- matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.1 Pillow>=7.1.2 PyYAML>=5.3.1 requests>=2.23.0 scipy>=1.4.1 torch>=1.7.0,!=1.12.0 torchvision>=0.8.1,!=0.13.0 tqdm>=4.41.0 protobuf<4.21.3 # Logging ------------------------------------- tensorboard>=2.4.1 # wandb # Plotting ------------------------------------ pandas>=1.1.4 seaborn>=0.11.0 # Export -------------------------------------- # coremltools>=4.1 # CoreML export # onnx>=1.9.0 # ONNX export # onnx-simplifier>=0.3.6 # ONNX simplifier # scikit-learn==0.19.2 # CoreML quantization # tensorflow>=2.4.1 # TFLite export # tensorflowjs>=3.9.0 # TF.js export # openvino-dev # OpenVINO export # Extras -------------------------------------- ipython # interactive notebook psutil # system utilization thop # FLOPs computation # albumentations>=1.0.3 # pycocotools>=2.0 # COCO mAP # roboflow- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
如果没有问题就可以开始训练,如下图:
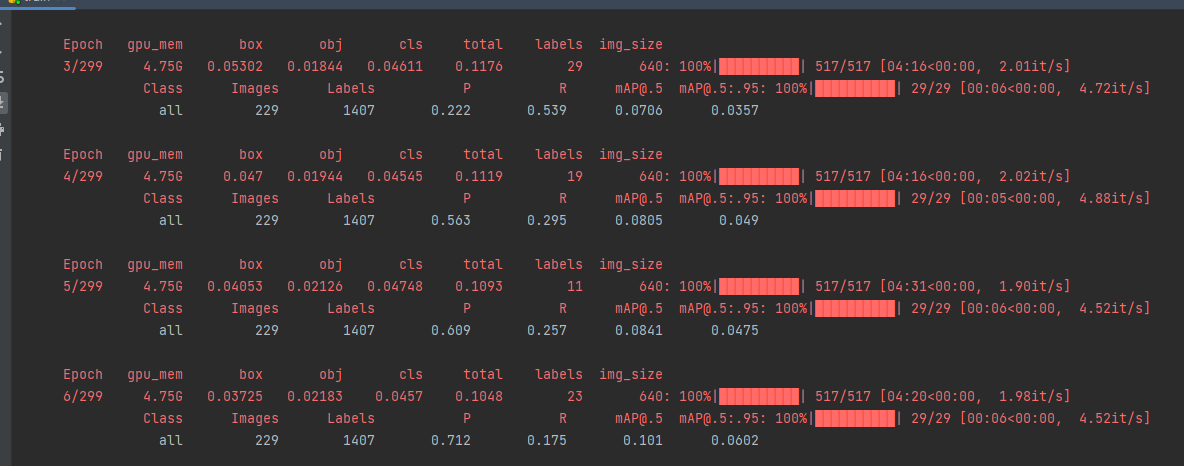
等待训练完成后就可以才是测试了。测试
测试使用detect.py脚本文件
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp9/weights/best.pt', help='model.pt path(s)') parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)') parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold') parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS') parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')- 1
- 2
- 3
- 4
- 5
- 6
weights:训练好的模型路径
source:测试图片的路径。
img-size:图片输入的大小。
conf-thres:置信度的下线。
iou-thres:IOU的阈值
device:GPU的编号,或者设置为cpu。
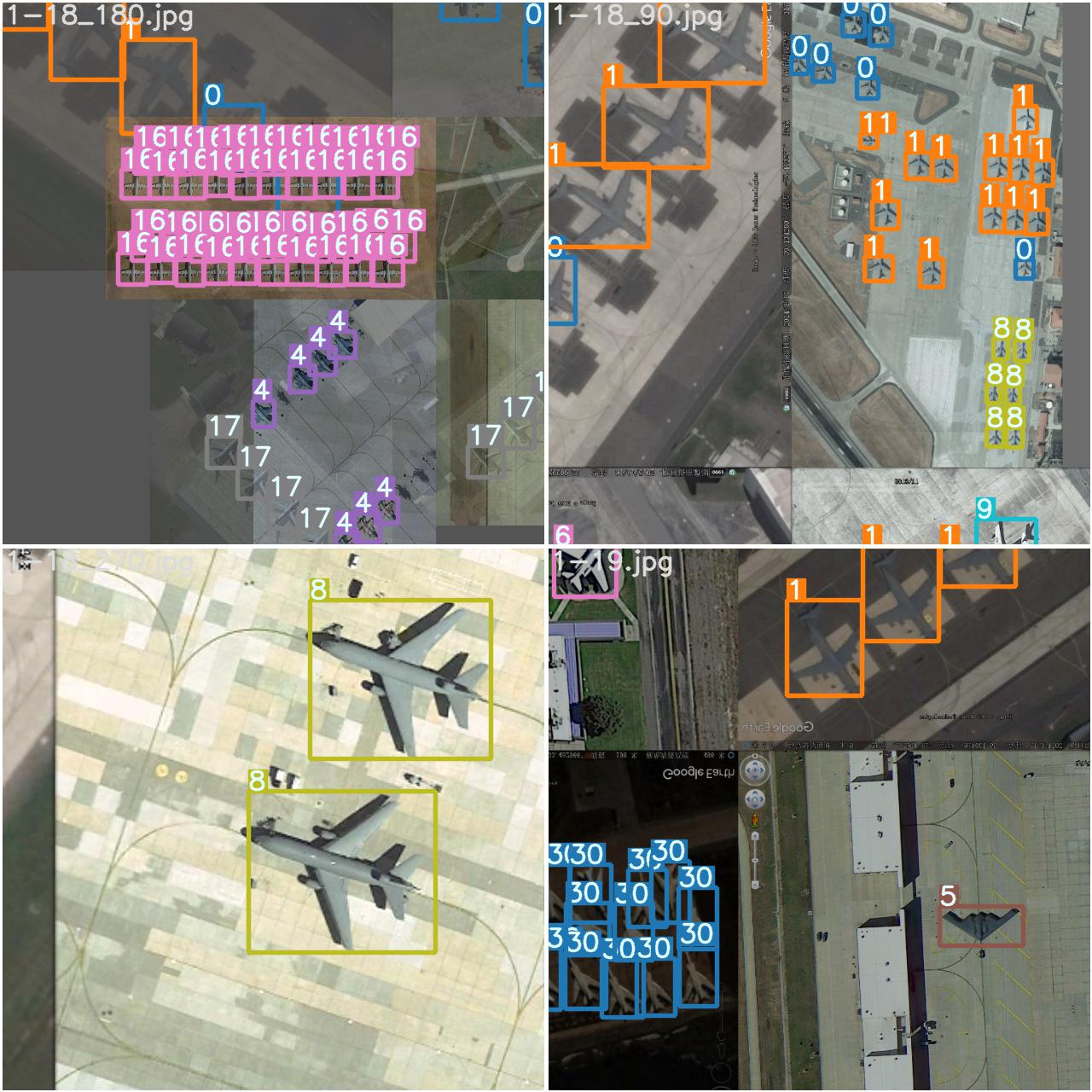
然后就可以运行detect.py脚本了。
测试结果:

-
相关阅读:
docker-metabase镜像打入clickhouse驱动
使用llama.cpp实现LLM大模型的格式转换、量化、推理、部署
Python将字符串转换成dataframe
01 SpringMVC 入门
DL之GRU:基于2022年6月最新上证指数数据集利用GRU算法预测最新股票上证指数实现回归预测
坚持五件事,带你走出迷茫困境
DAO 的发展状态
LQ0212 蚂蚁感冒【序列处理】
软件测试面试大全(2023版,答案+文档)
Spread for ASP.NET 15.2 个性化需求中文版
- 原文地址:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/126361009