-
Redis(十) 布隆过滤器
速记
为什么使用布隆过滤器?
1.为了省内存,提高速率
2.因为1所以布隆过滤器不需要百分百正确
3.说存在不一定存在,说不存在一定不存在
4.在解决缓存穿透的问题时,拦截了大部分的请求,只有小部分携带了大量信息的恶意请求访问到了数据库
5.不准确的原因是可能会和别的key发生冲突,所以位数组越大精确度越高,但是占用内存越多。所以在设置布隆过滤器的时候,这个容错率是多少是百分之一还是百分之十,是否牺牲内存来提高容错率这个我们要权衡一下。
6.专门用来解决缓存穿透的问题一. Bloom Filter
1.1 布隆过滤器介绍
Bloom Filter 专门用来解决我们上面所说的去重问题的,使用 Bloom Filter 不会像使用缓存那么浪费空间。当然,他也存在一个小小问题,就是不太精确。即
说存在不一定存在,说不存在一定不存在
Bloom Filter 相当于是一个不太精确的 set 集合,我们可以利用它里边的 contains 方法去判断某一个对象是否存在,但是需要注意,这个判断不是特别精确。一般来说,通过 contains 判断某个值不存在,那就一定不存在,但是判断某个值存在的话,则他可能不存在。1.2例子
实际案例1
以今日头条为例,假设我们将用户的浏览记录用 B 表示,A 表示用户没有浏览的新闻,现在要给用户推送消息,先去 B 里边判断这条消息是否已经推送过,如果判断结果说没推送过(B 里边没有这条记录),那就一定没有推送过。如果判断结果说有推送过(B 里边也有可能没有这条消息),这个时候该条消息就不会推送给用户,导致用户错过该条消息,当然这是概率极低的。
实际案例二
前面所说的新闻推送过滤算是一个应用场景。
解决 Redis 穿透或者又叫缓存击穿问题。
假设我有 1亿 条用户数据,现在查询用户要去数据库中查,效率低而且数据库压力大,所以我们会把请求首先在 Redis 中处理(活跃用户存在 Redis 中),Redis 中没有的用户,再去数据库中查询。
现在可能会存在一种恶意请求,这个请求携带上了很多不存在的用户,这个时候 Redis 无法拦截下来请求,所以请求会直接跑到数据库里去。这个时候,这些恶意请求会击穿我们的缓存,甚至数据库,进而引起“雪崩效应”。
为了解决这个问题,我们就可以使用布隆过滤器。将 1亿条用户数据存在 Redis 中不现实,但是可以存在布隆过滤器中,请求来了,首先去判断数据是否存在,如果存在,再去数据库中查询,否则就不去数据库中查询。
1.3 布隆过滤器原理
每一个布隆过滤器,在 Redis 中都对应了一个大型的位数组叫做
位数组以及几个不同的 hash 函数。所谓的 add 操作是这样的:
首先根据几个不同的 hash 函数给元素进行 hash 运算一个整数索引值,拿到这个索引值之后,对位数组的长度进行取模运算,得到一个位置,每一个 hash 函数都会得到一个位置,将位数组中对应的位置设置位 1 ,这样就完成了添加操作。
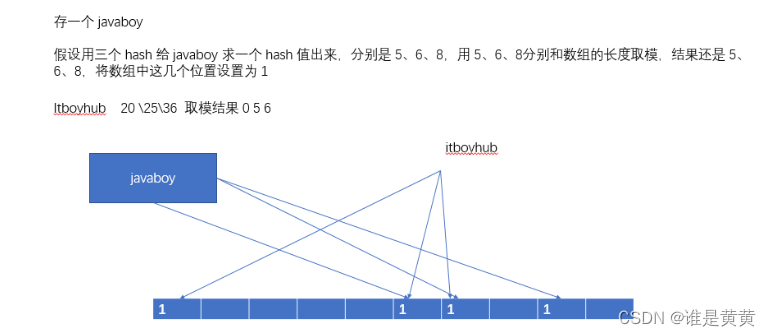
比如说你想存一个值
javaboy
这里的位数组用三个hash给javaboy求一个hash出来,分别是5,6,8然后用5,6,8分别和数组的长度取模,结果还是5,6,8
相同,itboyhub 取模结果是0,5,6
当判断元素是否存在时,依然先对元素进行 hash 运算,将运算的结果和位数组取模,然后去对应的位置查看是否有相应的数据,如果有,表示元素可能存在(因为这个有数据的地方也可能是其他元素存进来的),如果没有表示元素一定不存在。Bloom Filter 中,误判的概率和位数组的大小有很大关系,
位数组越大,误判概率越小,当然占用的存储空间越大;位数组越小,误判概率越大,当然占用的存储空间就小。实际应用中自己去设置这个概率,布隆过滤器会自动的分配数组的大小1.4 布隆过滤器的安装
布隆过滤器是GitHub上的开源项目
github.com/RedisBloom/RedisBloom/releases我们先访问这个地址去找到适合自己版本的布隆过滤器这里黄黄下载一个2.2.18的稳定版本,你要下载什么版本要对照着你Redis的版本哦
然后去把你的redis集群全部关掉

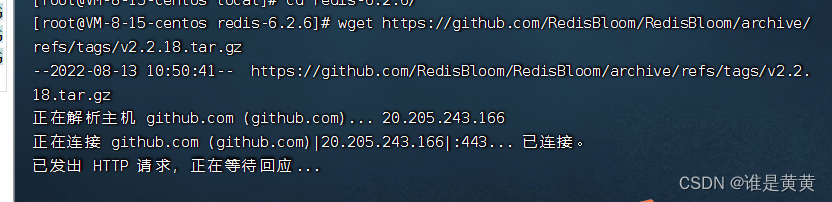
进入你的redis的目录下去下载布隆过滤器
wget https://github.com/RedisBloom/RedisBloom/archive/refs/tags/v2.2.18.tar.gz
(如果下载不下来的兄弟,用刚才的github的路径下载安装包到windows,再丢到linux里面去解压吧,再用tar -zxvf 文件包名 去解压)
然后进入布隆过滤器的包中:
因为我们之前装过了gcc,所以这里只要执行make指令就行,没有装gcc的兄弟翻一下以前的博客装一下gcc

安装完成之后发现比安装之前多了一个redisbloom.so文件

记住到RedisBloom包之中的路径:
黄黄这里是:/usr/local/redis-6.2.6/RedisBloom-2.2.18

退回到redis包中

进入redis.conf配置类,启动布隆过滤器的开机自动启动

/moules搜索到外部modules模块:如下

添加:/usr/local/redis/RedisBloom是我们上面保存的地址加上/redisbloom.so即我们找到的这个布隆过滤器里的配置文件,记得加上loadmoule前缀,即
loadmodule /usr/local/redis/RedisBloom/redisbloom.so

,启动我们的redis就行了,因为配置了布隆过滤器,所有开启redis布隆就应该生效了,当然没生效肯定是配置的什么地方出现了问题,那么就要我们自己去排错了。

判断布隆过滤器是否启动
再进入命令行就可以去使用命令了
主要是两类命令,添加和判断是否存在。bf.add\bf.madd添加和批量添加bf.exists\bf.mexists判断是否存在和批量判断
1.5 布隆过滤器的基本用法-小例子
添加依赖
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.7.0</version> </dependency> <dependency> <groupId>com.redislabs</groupId> <artifactId>jrebloom</artifactId> <version>1.2.0</version> </dependency> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.17.5</version> </dependency> <dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>6.2.0.RELEASE</version> </dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
public class BloomFilterDemo { public static void main(String[] args) { //通用的连接池对象,这里主要是设置最大连接数、最小空闲数等参数 GenericObjectPoolConfig<Jedis> poolConfig = new GenericObjectPoolConfig<>(); //最大连接数 poolConfig.setMaxTotal(100); //最小空闲数 poolConfig.setMinIdle(10); //连接最大空闲数 poolConfig.setMaxIdle(20); JedisPool jedisPool = new JedisPool(poolConfig, "1.12.235.192", 6379,null,"123"); Client client = new Client(jedisPool); for (int i = 0; i < 100; i++) { client.add("myfilter", "zhangsan:" + i); } System.out.println("client.exists(\"myfilter\", \"zhangsan:99\") = " + client.exists("myfilter", "zhangsan:99")); System.out.println("client.exists(\"myfilter\",\"zhangsan:99999999\") = " + client.exists("myfilter", "zhangsan:99999999")); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1.5.1 调节布隆的过滤错误率
默认情况下,我们使用的布隆过滤器它的错误率是 0.01 ,默认的元素大小是 100。但是这两个参数也是可以配置的。
我们可以调用 bf.reserve 方法进行配置。
BF.RESERVE k1 0.0001 1000000
第一个参数是 key,第二个参数是错误率,错误率越低(意味着位数组越长),占用的空间越大,第三个参数预计存储的数量,当实际数量超出预计数量时,错误率会上升。1.6布隆的典型场景
前面所说的新闻推送过滤算是一个应用场景。
解决 Redis 穿透或者又叫缓存击穿问题。
假设我有 1亿 条用户数据,现在查询用户要去数据库中查,效率低而且数据库压力大,所以我们会把请求首先在 Redis 中处理(活跃用户存在 Redis 中),Redis 中没有的用户,再去数据库中查询。
现在可能会存在一种恶意请求,这个请求携带上了很多不存在的用户,这个时候 Redis 无法拦截下来请求,所以请求会直接跑到数据库里去。这个时候,这些恶意请求会击穿我们的缓存,甚至数据库,进而引起“雪崩效应”。
为了解决这个问题,我们就可以使用布隆过滤器。将 1亿条用户数据存在 Redis 中不现实,但是可以存在布隆过滤器中,请求来了,首先去判断数据是否存在,如果存在,再去数据库中查询,否则就不去数据库中查询
-
相关阅读:
【OpenCV】基于OpenCV/C++实现yolo目标检测
FFmpeg入门详解之8:YUV Player简介
API(八)cosocket常用SDK
PHP去除字符串前或后的字符或空格
使用Conda
Pytorch实战教程(二)-PyTorch基础
代数、图算法:图基础
【多线程进阶】死锁问题
14条最佳JavaScript代码编写技巧
《程序员延寿指南》登GitHub热榜,最多可增寿20年?
- 原文地址:https://blog.csdn.net/weixin_43189971/article/details/126257458
