-
推荐系统方法梳理
推荐系统流程
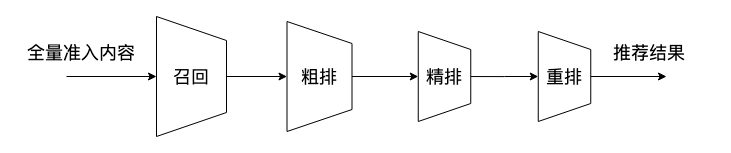
召回:从千百万量级的全量内容中挑选出用户可能感兴趣的几百/几千条内容,主要包括热门内容召回、基于内容的召回、基于用户行为的召回(CF、MF、双塔DSSM、graph embedding)、倒排索引、强化学习(for内容冷启动)等。
粗排/精排:利用模型对召回内容进行打分,取top k进入重排。主要包括LR、特征交叉流派(FM家族)、行为序列流派(DIN、DIEN/DSIN、BST等)、其他流派(pairwise、listwise)。
重排:按照业务策略对内容顺序进一步调整,形成最终的推荐list返回给用户。主要包括listwise、多样性算法(MMR、DPP)、强化学习等。步骤1:召回
基于内容的召回(Content-based)
抽取内容的semantic features(如电影名称、导演、主演、类别等),对内容进行embedding,向用户推荐semantic embedding相似的内容。
Problem:用户冷启动问题协同过滤(Collaborative Filtering)
User-CF
计算用户间的相似度(这里的特征向量为用户给不同商品的评分),推荐相似的用户喜欢的item。

Item-CF
计算商品之间的相似度(这里的特征向量为商品被各个用户的评分),推荐相似的item。

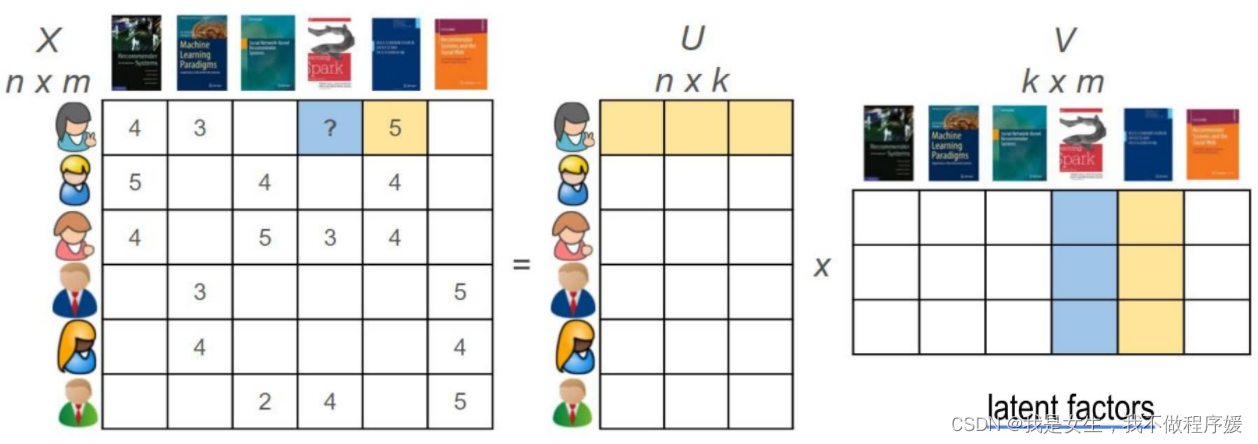
MF(Model-CF)
利用matrix factorization对用户-商品矩阵进行分解,从而得到新的用户、商品的特征表示向量,并用这些向量来计算用户/商品之间的相似度,进行推荐。
DSSM双塔模型(Deep Structured Semantic Models)
论文:Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations
简单讲就是user和item分别用DNN做embedding,最终使用cosine计算相似度进行推荐。在工业界非常常用。

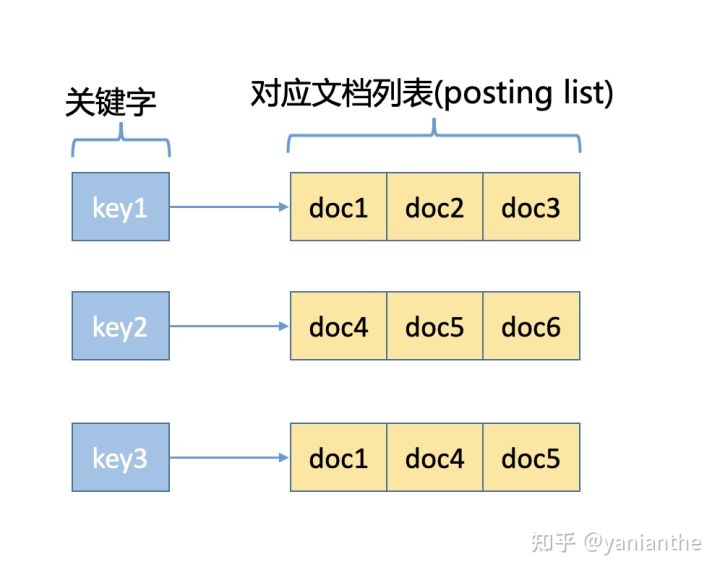
倒排索引召回
倒排索引最初是搜索领域的方法,通过记录包含关键词key的文章document(以及出现的位置、权重等),在用户对关键词进行搜索时,直接通过索引找到对应文章。复杂度由O(n)变为O(1)。
由于实际应用中,使用属性值来查找记录,而非用记录查找值,因此被称为“倒排”。
对于搜索引擎,关键词由用户主动输入;而对于推荐系统,关键词需要系统生成。生成策略包括根据用户画像等进行内容召回、根据热度等进行策略召回。
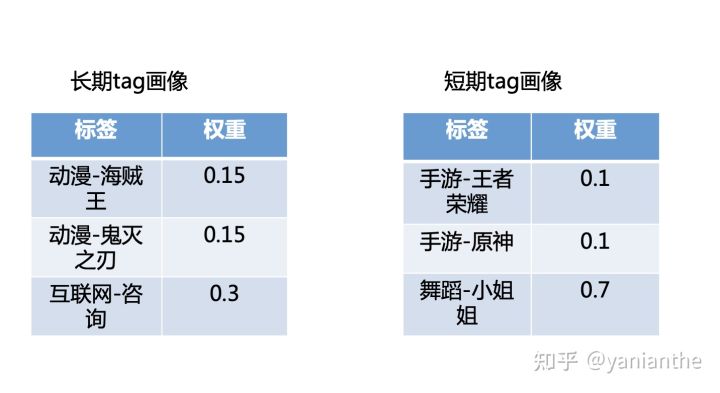
用户画像示例如下:
多路召回
使用多种召回策略同时召回,再进行加权平均等方式得到最终的召回item。
可以结合上述策略的优点。粗排
LR(Logistic Regression)
LR 模型是 CTR 预估领域早期最成功的模型.
LR 使用 “线性模型 + 人工特征组合引入非线性” 特征,对item的分数进行预测。
LR 模型具有训练快、上线快、可解释性强、容易上规模等优点,目前仍然有不少实际系统采取这种粗排模式。
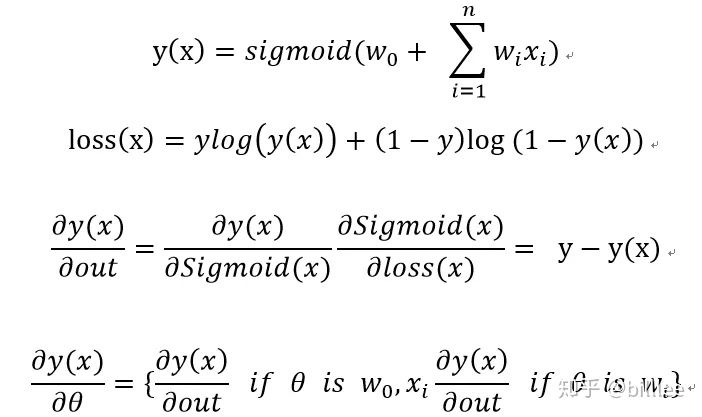
树模型
GBDT、XGB、LightGBM、GDBT+LR等。
精排
特征交叉流派
FM实现了二阶特征组合自动化;
接下来引入深度学习,wide&deep、DeepFM、xDeepFM(CIN)、Deep&Cross(Cross)向显式特征组合的方向发展。tricks:
- 实验证明,二阶特征交叉有效,三阶部分有效,四阶及以上特征交叉基本没有作用。
- 深度学习实现了高阶特征组合自动化,但速度慢、可解释性差。
pairwise&listwise
前面介绍的方法主要是pointwise维度的,即对每个item单独打分。
设query为q,文档为c,预测得分为h(q,c),实际得分为标签y。pointwise直接最小化h(q,c)和y之间的差距构造损失函数。这种方法存在以下缺点:
- pointwise追求的是文章的精确打分,没有考虑到文章之间的关联性,而推荐追求的是相对排序;
- pointwise为了追求整体loss最小化,导致优化结果被对应文章多的query所支配,而推荐追求每个query处于同等地位;
- 实际推荐情景中,top k之间的顺序远比末尾若干内容的顺序重要,pointwise的损失函数没有考虑相对位置信息,会无意间过于注重不重要的文章排序。
pairwise
Pairwise通过近似为分类问题解决排序问题。
pairwise通过计算h(q,c1)-h(q,c2) 构造损失函数,标签y表示h(q,c1)-h(q,c2)>0或<0。
输入样本为“标签-文档对”。学习一个二分类器,对输入的一对文档对AB,根据A相关性是否比B好,二分类器给出分类标签1或0。
对所有文档对进行分类,就可以得到一组偏序关系,从而构造文档全集的排序关系。
该类方法通过降低排序中的逆序文档对的个数来降低排序错误,从而达到优化排序结果的目的。例如:三个文档 A、B 、 C,完美排序是 “B>C>A”。pairwise通过学习 “B>C”、“B>A” 和 “C>A” 来重构 “B>C>A”。
代表算法:基于 SVM 的 Ranking SVM 算法、基于神经网络的 RankNet 算法和基于 Boosting 的 RankBoost 算法。
pairwise存在问题:
- pairwise使用的两两排序的损失函数还是不能真正代表整体排序的损失函数,甚至可能出现负相关;
- doc pair的数量是doc的二次,query对应文章数量不平衡的问题被进一步放大;
- pairwise依然没有考虑文档在整体排序列表的出现顺序,导致排序结果依然受到不重要的文档影响;
- pairwise会对噪声数据更敏感。如果一个文章对预测错误,与这两个文档相关的排序都将受到影响。
listwise
Listwise方法是直接优化排序列表。
输入为单条样本为一个query和它对应的所有候选item。
计算S= softmax(h(q,c1),h(q,c2)…h(q,cn)),其标签Y=(y1,y2…yn) 表示各候选文档的实际得分排序。最小化S和Y之间的KL散度得到最优排序。代表算法:AdaRank,SoftRank,LambdaMART、 ListNet、ListMLE、BoltzRank等。
listwise存在问题:
- 训练复杂度较高;
- 位置信息在listwise中也没有在loss中得到充分利用,可以在 ListNet 和 ListMLE 的 loss 中考虑引入位置折扣因子。
出于时延考虑,目前大多数推荐系统仍然采用pointwise方法进行精排。
重排
重排作为离用户最近的一个步骤,涉及打散、多样性等过程,需要充分考虑用户体验,避免用户抵触。
打散
对同类目、同作者、相似封面图的item进行打散,可以有效防止用户疲劳和系统过度个性化,同时有利于探索和捕捉用户的潜在兴趣,对用户体验和长期目标都很关键。
多样性
可以从user和item两个角度评估,比如平均每个用户的曝光一二级类目数,曝光item同属一个类目的概率等。可以从类目、作者、标签等多个维度进行数据分析和评价。此外,由于粗排和精排考虑到时延,主要采用pointwise方法;而重排的量级较小,可以采用pairwise和listwise提升排序的准确性和有效性。
-
相关阅读:
【大数据Hive】hive 加载数据常用方案使用详解
【现代密码学原理】——密钥管理和其他公钥密码体制(学习笔记)
Vue+element 登录业务实现
live555 音视频处理相关文档解读,
JPA之使用复合主键
人工智能(AI)与地理信息技术(GIS)的融合:开启智能地理信息时代
32GB的SD卡在windows上格式化后只有252kb怎么办?
用友YonSuite前后端一体化数智赋能,有化妆品的地方就有老中医
抽奖小游戏
python爬虫实战——小红书
- 原文地址:https://blog.csdn.net/weixin_44644621/article/details/126269084