-
打造千万级流量秒杀第二十一课 Redis 实战:如何使用 Redis 缓存库存信息?
首先问你一个问题:秒杀系统中最重要的数据是什么?是秒杀活动信息吗?不是!是秒杀库存信息。
我在需求分析的时候给你介绍过,秒杀活动之所以吸引人,是因为它用少量库存超低价的方式吸引用户。秒杀库存之所以重要,是因为库存数远小于参与秒杀活动的用户数。如果库存数据没处理好,要么影响用户体验,要么可能导致超售带来损失。所以,秒杀库存数据的高性能访问和高一致性,是秒杀系统保障性能和稳定性的关键。而为了保证这一点,一般采用具有高性能的 Redis ,来缓存库存数据。
那么,具体该如何实现呢?接下来我给你详细介绍下。
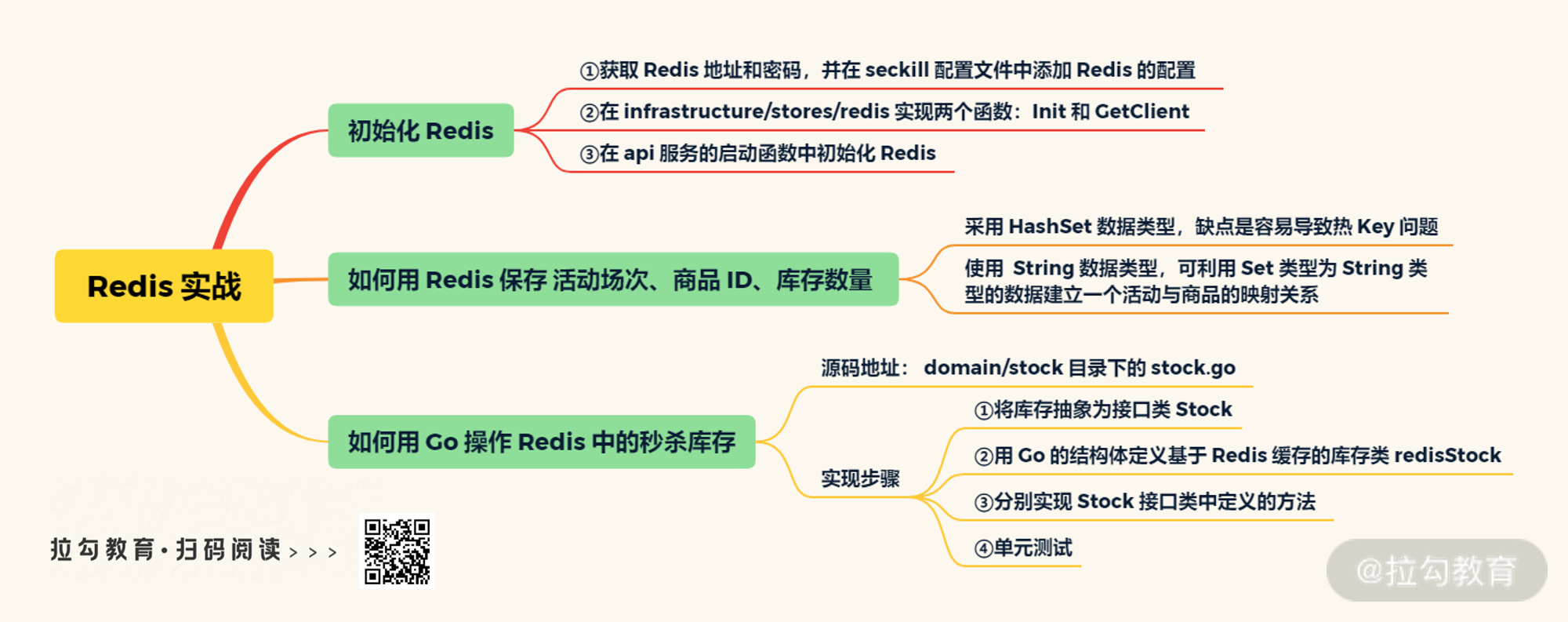
初始化 Redis
在使用 Redis 之前,我们需要初始化 Redis。假设你本地的电脑上已经启动了 Redis 服务,并且监听了 6379 端口,那么 Redis 服务的地址就是 127.0.0.1:6379。
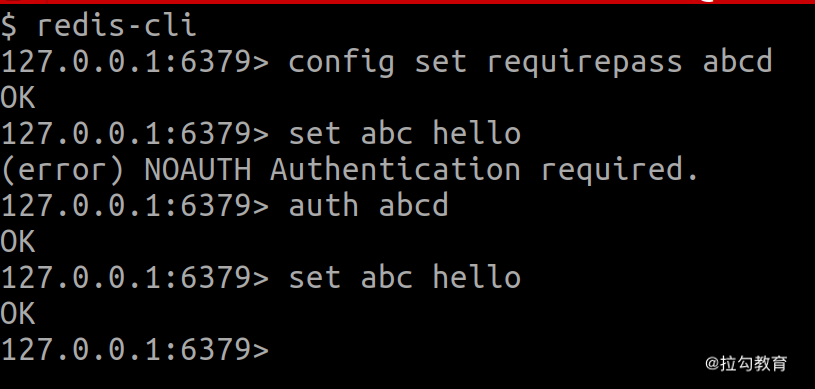
由于 Redis 性能很高,而且使用非常简单方便,如果没有密码,可以连接到 Redis 的程序能轻易获取或者修改里面的数据。因此,在一些重要的业务中,通常会给 Redis 设置访问密码。
比如,可以通过redis-cli config set requirepass abcd命令,或者在配置文件中添加 requirepass abcd 配置,将 Redis 的密码设置为 abcd。在本地电脑上,配置文件的路径通常是 /etc/redis 目录下的 redis.conf。
这两种方式的区别在于:用命令的方式设置,一旦 Redis 服务重启了,则密码会失效;而用配置文件的方式能确保密码不丢失。
设置完密码后,通过 redis-cli 连接到 Redis 服务后,执行任何 set、get 命令都会报错,提示你需要认证。只有执行了 auth abcd 后,才能正常读写数据。如下图所示:
知道了 Redis 的地址和密码后,我们就可以在代码中初始化 Redis 客户端了。怎么做呢?
首先,在 seckill 配置文件中添加 Redis 的配置,主要有地址 address 和密码 auth。如下所示:
[redis] address = "127.0.0.1:6379" auth = "abcd"- 1
- 2
- 3
- 1
- 2
- 3
由于 Redis 属于基础设施,接下来我们在 infrastructure/stores/redis 目录下的 redis.go 中实现两个函数:Init 和 GetClient。
在 Init 函数中,主要是读取配置文件中的 address 和 auth 配置,并作为参数调用 redis.NewClient 函数创建一个 Redis Client 对象,将其保存到一个全局变量 cli 中。这样,就可以在 GetClient 函数中获取 cli 并提供给调用方使用。具体代码如下:
const Nil = redis.Nil var cli *redis.Client func Init() error { addr := viper.GetString("redis.address") auth := viper.GetString("redis.auth") if addr == "" { addr = "127.0.0.1:6379" } opt := &redis.Options{ Network: "tcp", Addr: addr, Password: auth, } cli = redis.NewClient(opt) if cli == nil { return errors.New("init redis client failed") } return nil } func GetClient() *redis.Client { return cli }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
需要注意的是,redis 客户端库在发现 Key 不存在的时候,会返回 redis.Nil 错误。为了避免在判断错误的时候重复引用客户端库,我在代码中定义了一个 Nil 常量供上游调用方使用,值为 redis.Nil。
接下来,我们就可以在 api 服务的启动函数中初始化 Redis。具体做法是在 interfaces/api/api.go 中调用 redis.Init 函数,并判断是否出错。代码如下所示:
if err := redis.Init(); err != nil { return err }- 1
- 2
- 3
秒杀库存的 Redis 数据结构
我们知道,Redis 是个 KV 存储,要用好 Redis,就需要设计好数据在 Redis 中的 Key 和 Value 格式。秒杀库存数据包含三个维度信息:活动场次、商品 ID、库存数量,而 Redis 的 Key 和 Value 只有两个维度。那么,我们该如何用 Redis 保存那三个维度的库存信息呢?
在 Redis 中通常有两种常用的方法保存 3 个维度的信息。
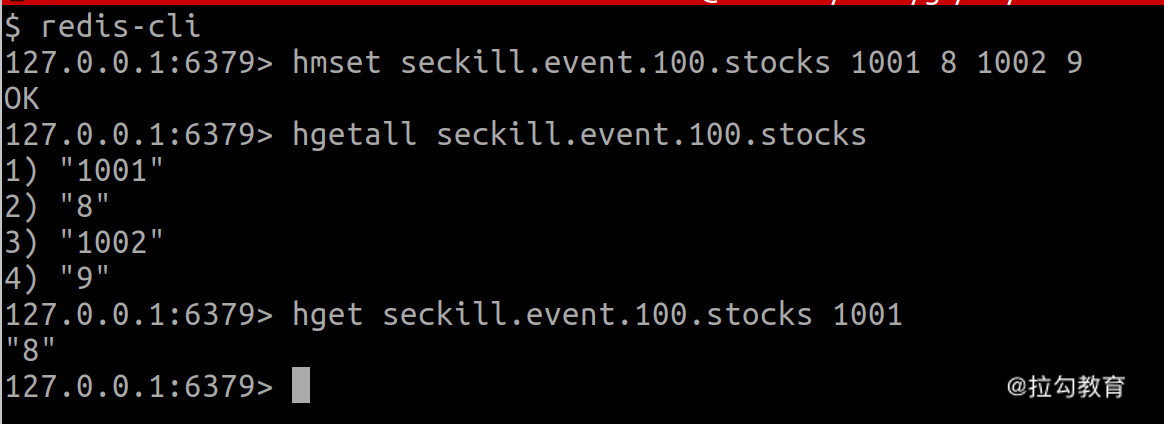
第一种是采用 HashSet 数据类型。 HashSet 在 Key-Value 的基础上,还多了一个 Field 参数。比如,一场活动中有多个商品,对应着多个库存数据,就可以把这场活动的所有库存信息放到一个 HashSet 里。具体来说,就是用活动场次 ID 做 Key,用商品ID 做 Field,而 Value 是库存数量。
不过,为了避免不同活动系统之间的 ID 冲突,通常需要在 Key 里加个前缀,如 seckill。假如活动 ID 为 100,商品 ID 为 1001 和 1002,库存分别为 8 和 9。那么,我们可以将 Key 构造成 seckill.event.100.stocks,然后用 hmset 命令将 ID 为 1001 和 1002 这两个商品的库存保存到活动 ID 为 100 的 HashSet 中。
接下来,我们就可以用 hgetall 命令获取该 HashSet 中的所有数据,或者通过 hget 命令获取商品 ID 为 1001 的库存。效果如下所示:
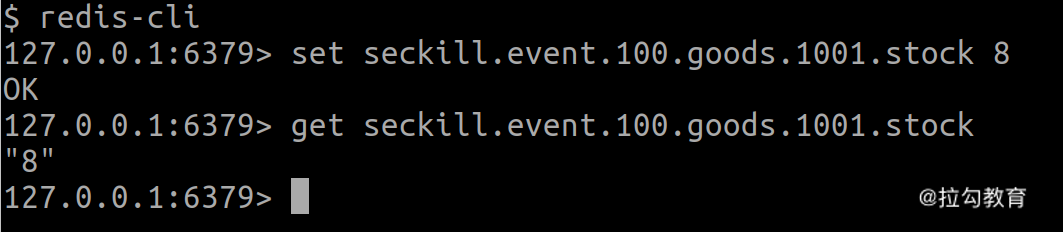
第二种方法是使用最常用的 String 数据类型。 我们可以将活动 ID 和商品 ID 拼接成 Key 来存储。以前面的活动和商品为例,拼接成 Key 后便是 seckill.event.100.goods.1001.stock 。接下来我们用 set 命令便可将该商品的库存保存到 Redis 中,通过 get 命令便可以取到库存。如下图所示:
这两种方法各有什么优缺点呢?我们最终选取哪种方式呢?
第一种方法的好处是能一次性取出活动中所有商品的库存信息。这种方式在单节点的 Redis 中没什么问题,在 Redis 集群中它就个很致命的缺点:容易导致热 Key 问题。
具体来说,主要是因为 Redis 集群是按照 Key 来将数据分配到不同节点上的。当采用 HashSet 时,一场活动的数据只会分配到一个节点。在高并发下频繁读写一场活动的库存数据,容易导致存储该活动的 Redis 节点的负载远高于其他节点,从而导致 Redis 集群节点负载不均衡,影响性能和稳定性。
第二种方法虽然解决了第一种方法中的热 Key 问题,但会导致无法通过活动 ID 获取到该活动下的所有商品库存信息。
怎么办呢?Redis 不像 MySQL 那样有表索引,但是,我们可以利用 Set 类型为 String 类型的数据建立一个活动与商品的映射关系。比如,构造一个名为 seckill.event.100.goods 的 Key,然后用 sadd 命令将 ID 为 1001 和 1002 这两个商品与 ID 为 100 的活动建立映射关系,通过 smembers 命令便可以获取到该场活动下的所有商品。如下图所示:
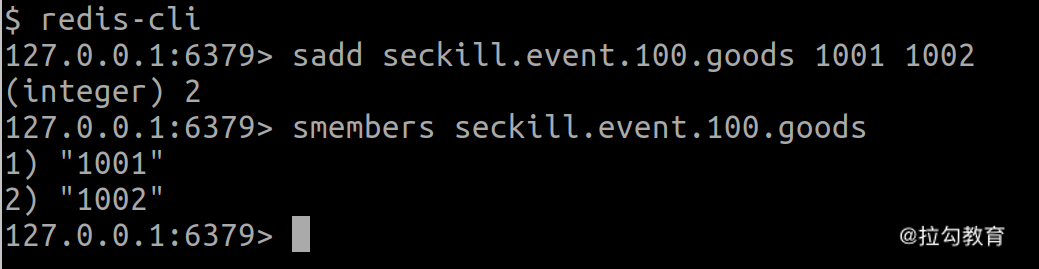
在活动过程中,虽然这个映射关系会频繁使用,但不会被修改,因此我们可以将其缓存到内存中。再加上商品的库存数据分散到各个商品的 Key 中,也就大大降低了热 Key 问题的风险。
如何用 Go 操作 Redis 中的秒杀库存?
在 DDD 中,库存是属于支撑域,用来支撑秒杀活动的。所以,我们需要将操作库存的代码逻辑放到 domain/stock 目录下的 stock.go 中。
由于库存逻辑有多种实现,比如基于内存缓存的库存逻辑、基于 Redis 缓存的库存逻辑等,因此,我们需要将库存抽象为接口类 Stock。它主要包括这几个方法: Set、Get、Sub、Del、EventID、GoodsID,分别用于设置库存值、获取库存值、扣减库存值、删除库存、获取活动 ID、获取商品 ID。具体实现如下:
type Stock interface { // 设置库存,并设置过期时间 Set(val int64, expire int64) error // 直接返回剩余库存 Get() (int64, error) // 尝试扣减一个库存,并返回剩余库存 Sub() (int64, error) // 删除库存数据 Del() error // 返回活动 ID EventID() string // 返回商品 ID GoodsID() string }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
接下来,我们用 Go 的结构体定义基于 Redis 缓存的库存类 redisStock。它主要包括 eventID、goodsID、key 这三个字段,分别用于保存活动 ID、商品 ID、Redis 缓存中的 Key。并且,我们实现一个 NewRedisStock 函数,参数为活动 ID 和商品 ID,用于创建基于 Redis 的库存对象。代码如下:
type redisStock struct { eventID string goodsID string key string } func NewRedisStock(eventID string, goodsID string) (Stock, error) { if eventID == "" || goodsID == "" { return nil, errors.New("invalid event id or goods id") } stock := &redisStock{ eventID: eventID, goodsID: goodsID, key: fmt.Sprintf("seckill#%s#%s", eventID, goodsID), } return stock, nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
之后,我们分别实现 Stock 接口类中定义的方法。在 Set、Get、Sub、Del 方法中,我们调用 Redis 客户端的方法操作库存数据。代码示例如下所示:
func (rs *redisStock) Set(val int64, expiration int64) error { cli := redis.GetClient() _, err := cli.Set(rs.key, val, time.Duration(expiration)*time.Second).Result() return err } func (rs *redisStock) Sub() (int64, error) { cli := redis.GetClient() return cli.Decr(rs.key).Result() } func (rs *redisStock) Get() (int64, error) { cli := redis.GetClient() if val, err := cli.Get(rs.key).Int64(); err != nil && err != redis.Nil { return 0, err } else { return val, nil } } func (rs *redisStock) Del() error { cli := redis.GetClient() return cli.Del(rs.key).Err() } func (rs *redisStock) EventID() string { return rs.eventID } func (rs *redisStock) GoodsID() string { return rs.goodsID }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
最后,我们实现一个单元测试来测试一下我们实现的代码逻辑,代码在 domain/stock 目录下的 stock_test.go 中,函数为 TestStock。
在单元测试中,我们先调用 redis.Init 初始化 Redis 客户端,然后调用 NewRedisStock 创建一个 Redis 库存对象,并调用 Set 函数将值设置为 10,过期时间设置为 1 秒。接着我们分别调用它的 Get、Sub、Del 方法,并校验返回值是否正确。如果不正确,就输出错误日志并退出测试。代码如下:
func TestStock(t *testing.T) { var ( st Stock err error val int64 ) if err = redis.Init(); err != nil { t.Fatal(err) } if st, err = NewRedisStock("101", "1001"); err != nil { t.Fatal(err) } if err = st.Set(10, 1); err != nil { t.Fatal(err) } if val, err = st.Get(); err != nil { t.Fatal(err) } else if val != 10 { t.Fatal("not equal 10") } if val, err = st.Sub(); err != nil { t.Fatal(err) } else if val != 9 { t.Fatal("not equal 9") } if err = st.Del(); err != nil { t.Fatal(err) } if val, err = st.Get(); err != nil { t.Fatal(err) } else if val != 0 { t.Fatal("not equal 0") } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
在 Goland 中,点击单元测试函数 TestStock 左边的绿色小箭头,就可以运行单元测试。效果如下:
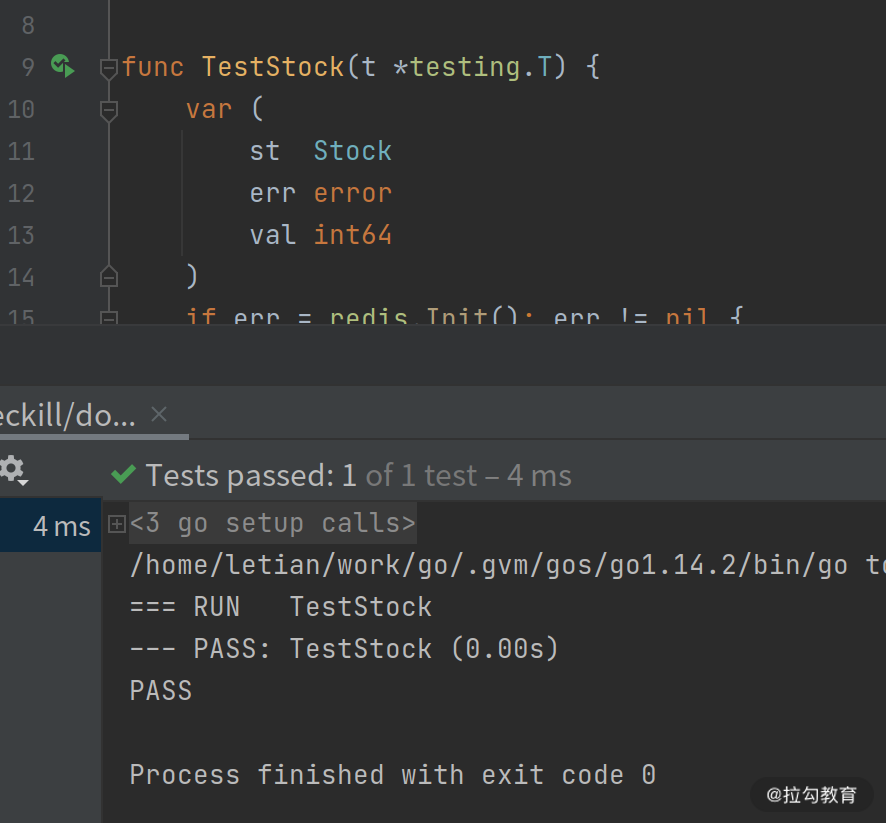
如果逻辑正常,你将看到 PASS TestStock 这样的日志。如果不正常,你将看到 FAIL TestStock 这样的日志。
小结
这一讲我主要给你介绍了秒杀系统如何使用 Redis 存储库存数据,以及如何解决 Redis 热 Key 问题。
在使用 Redis 的时候,始终要记住,Redis 不像 MySQL 那种关系型数据库,Redis 中所有数据关系需要你自己维护。你需要根据需求来决定:是否设置过期时间,过期时间多久。对于无过期时间的数据要建立映射关系,以便方便管理和清理无用数据,避免 Redis 中数据膨胀,导致资源浪费。
现在你可以思考一下:秒杀系统中,库存数据的过期时间应当如何设置呢?
好了,这一讲就到这里了,下一讲我将给你介绍“如何使用内存缓存提升数据命中率”。到时见!
源码地址:https://github.com/lagoueduCol/MiaoSha-Yiletian
精选评论
**5183:
redis代码没有更新
官方客服回复:
已经更新了的,在源码仓库 https://github.com/lagoueduCol/MiaoSha-Yiletian 的 infrastructure/stores/redis 和 domain/stock 目录里面,老师也在文章里面提示了具体的代码位置~
*佳:
为什么hashset不能避免集群中的热点key问题,而String能避免呢?
讲师回复:
redis集群是根据 key 来分片的,无法根据 hashset的 field 来分片。如果 hashset 里有成千上万个 field,每个 field 访问量都很高,会导致 hashset 数据量大,请求量大,会把某个 redis 实例的带宽打满。如果将hashset 的 field 都拆出来,拆分成多个 string ,比较均衡地分布在多个 redis 实例中,就能有效避免 redis 集群中负载不均衡的问题
*佳:
您好,我看这里redis缓存的秒杀相关的数据是不是有点少了1、秒杀商品详情 这也应该要缓存起来吧,比如用String这种数据结构,key是秒杀商品id2、秒杀场次列表 比如List这种结构key是当前租户,value是所有场次3、秒杀场次下的商品列表 List这种结构,key是具体场次,value是商品列表另外有个问题:比如 缓存了商品列表,是否还需要缓存单个单个的商品详情呢?
讲师回复:
是的,这些都需要缓存。但商品相关的缓存逻辑比较简单,因为它在活动过程中是只读。而库存是同时涉及读写操作的,实现难度比商品大。
-
相关阅读:
Scala基础教程--16--泛型
基于Python的工人员工工资管理系统
NeurIPS 2022 | 涨点神器!利用图像辅助三维点云分析的训练新范式
以激励为导向的配电网分布式电压调节
1.计算机系统概述-王道考研计算机组成原理
Ubuntu编译AOSP Android9
基于 .NET 6 的轻量级 Webapi 框架 FastEndpoints
JUCE框架教程(5)——Plugin项目构造基础
生成函数、多项式题单
pbootcms模板提交留言表单后,如何跳转到指定的网址?
- 原文地址:https://blog.csdn.net/fegus/article/details/126362260
