-
疫情防控大屏展示
🙋作者:爱编程的小贤
⛳知识点:Flask、前端、Echarts、Linux
🥇:每天学一点,早日成大佬🥊一、项目概述
1.1项目介绍
本项目是一个基于 Python + Flask + Echarts 打造的一个疫情监控系统,涉及到的技术有:
- Python 网络爬虫
- 使用 Python 与 MySQL 数据库交互
- 使用 Flask 构建 web 项目
- 基于 Echarts 数据可视化展示
- 在 Linux 上部署 web 项目及爬虫
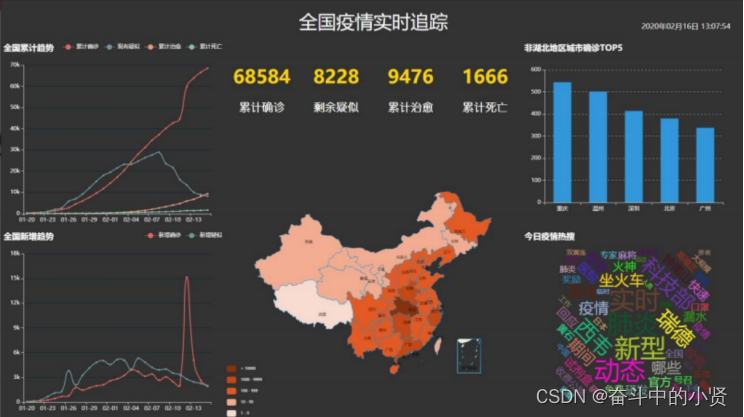
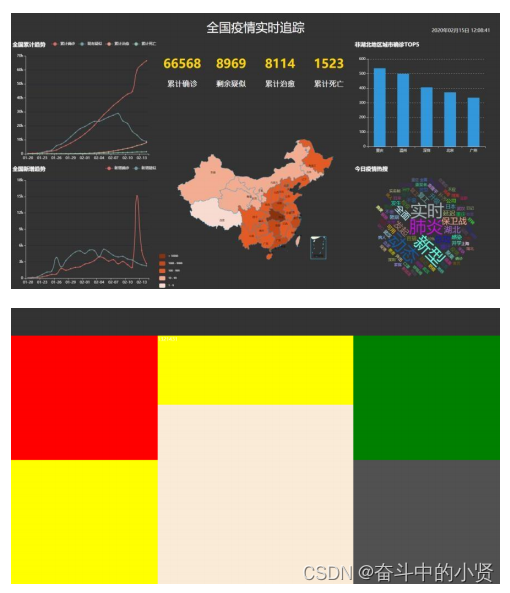
效果展示:
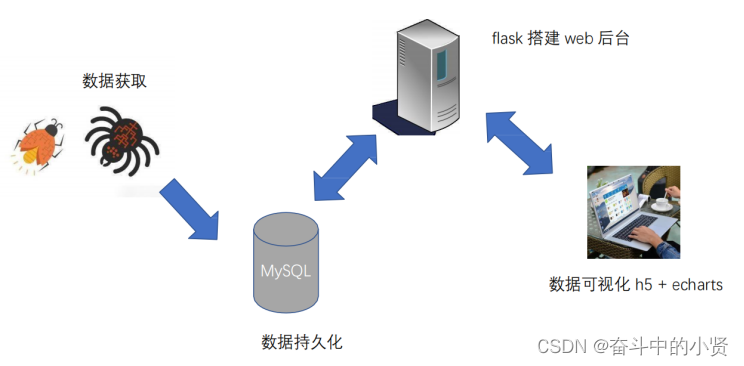
1.2项目架构
1.3 项目环境准备
- Python 3.x
- MySQL5.7或8.0
- PyCharm (Python IDE)
- Jupyter notebook (Pyhon IDE)
- Linux 主机(后期项目部署)
1.4 notebook
Jupyter Notebook(此前被称为 IPython notebook)是一个基于网页的用于交互计算的应用程序,在数据科学领域很受欢迎。
简言之,notebook 是以网页的形式打开,可以在 code 类型单元格中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在 markdown 类型的单元格中直接编写,便于作及时
的说明和解释- 安装 pip install notebook - 启动: jupyter notebook - 修改工作目录 ① jupyter notebook --generate-config ②编辑 jupyter_notebook_config.py 文件 - notebook 的基本操作 ① 新建文件与导入文件 ② 单元格分类:code 、markdown ③ 命令模式(蓝色边框)与编辑模式(绿色边框) ④ 常用快键键 单元格类型转换:Y 、M; 插入单元格:A、B; 运行单元格:ctrl / shift / alt + enter 删除单元格:DD- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
🥊二、数据获取
2.1 爬虫概述
爬虫,就是给网站发起请求,并从响应中提取需要的数据的自动化程序。
爬虫步骤:1. 确定目标的url
2. 发送请求,获取响应
通过 http 库,对目标站点进行请求。等同于自己打开浏览器,输入网址
常用库:urllib、urllib3、requests
服务器会返回请求的内容,一般为:html、二进制文件(视频,音频)、文档,json 字符串等
3. 解析提取数据
寻找自己需要的信息,就是利用正则表达式或者其他库提取目标信息
常用库:re、beautifulsoup4
4. 保存数据
将解析得到的数据持久化到文件或者数据库中2.1.1使用 urllib 发送请求
➢request.urlopen()

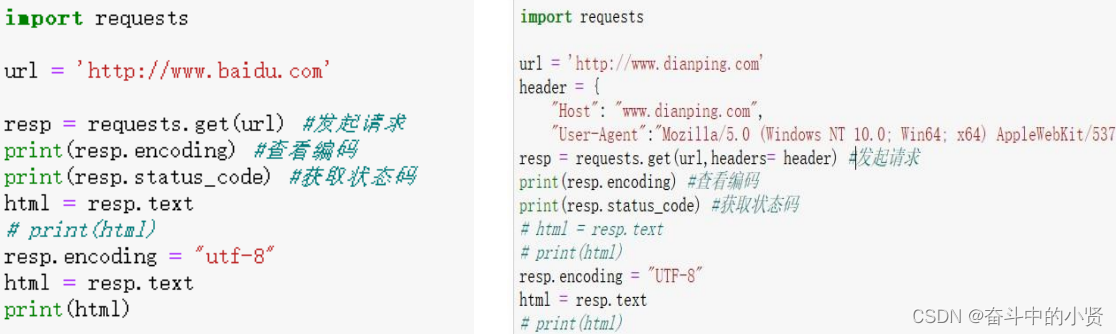
2.1.2使用 requests发送请求
➢安装: pip install requests
➢requests.get()
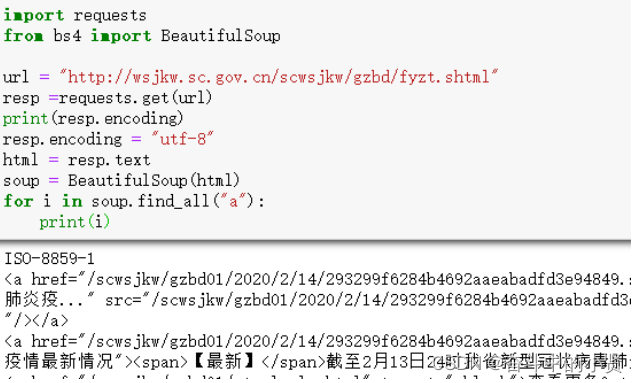
2.1.3使用 beautifulsoup4 解析内容
beautifulsoup4 将复杂的 HTML 文档转换成一个树形结构,每个节点都是 Python 对象
➢安装:pip install beautifulsoup4 ➢BeautifulSoup(html) ➢ 获取节点:find()、find_all()/select()、 ➢ 获取属性:attrs ➢ 获取文本:text- 1
- 2
- 3
- 4
- 5
2.1.4使用 re 解析内容
➢re 是 python 自带的正则表达式模块,使用它需要有一定的 正则表达式 基础 ➢re.search( regex ,str) ① 在 str 中查找满足条件的字符串,匹配不上返回None ② 对返回结果可以分组,可在字符串内添加小括号分离数据: groups() group(index) : 返回指定分组内容- 1
- 2
- 3
- 4
- 5
- 6

2.2 爬取腾讯疫情数据(部分代码)
- 有了爬虫基础后,我们可以自行去全国各地的卫健委网站上爬取数据,不过部分网站反爬虫手段很高明,需要专业的反反爬手段
- 我们也可以去各大平台直接爬取最终数据,比如:
百度疫情动态
https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_1
腾讯疫情动态
https://news.qq.com/zt2020/page/feiyan.htm#/ - 获取所有病情数据
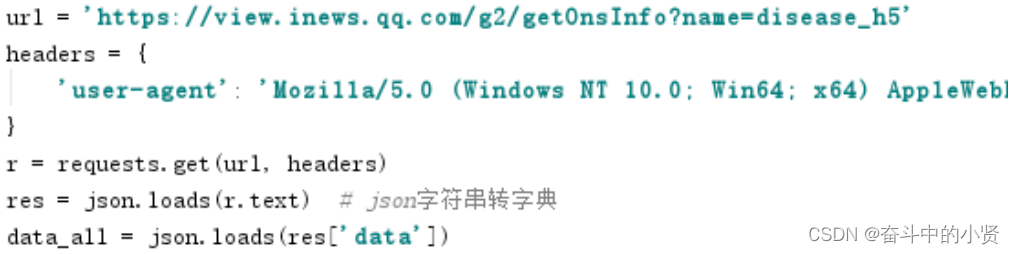
当日详情数据
url = "https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=localCityNCOVDataList,diseaseh5Shelf" response = requests.get(url) result = json.loads(response.text) update_time = result['data']['diseaseh5Shelf']['lastUpdateTime'] # 获取省份数据列表 province_data = result['data']['diseaseh5Shelf']['areaTree'][0]['children']- 1
- 2
- 3
- 4
- 5
- 6
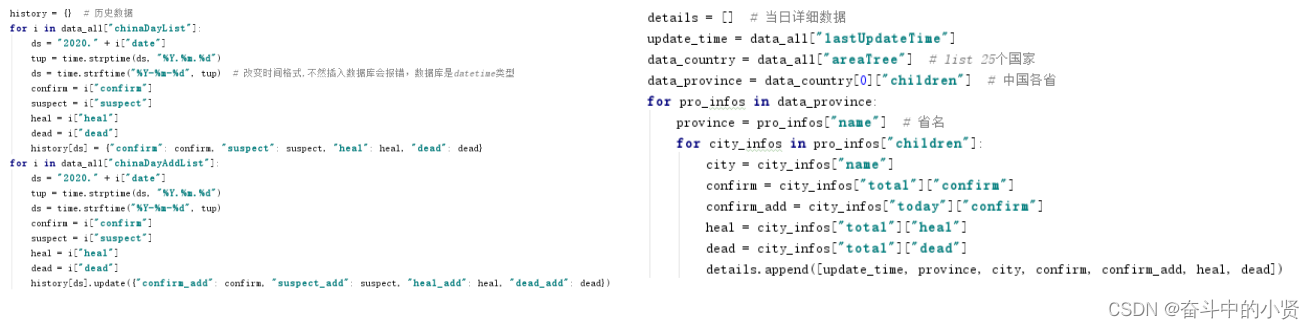
历史数据
url = "https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=chinaDayListNew,chinaDayAddListNew&limit=30" response = requests.get(url) result = json.loads(response.text) day_data = result['data']['chinaDayListNew'] day_data_add = result['data']['chinaDayAddListNew']- 1
- 2
- 3
- 4
- 5
- 分析与处理

- 数据存储
history 表存储每日总数据,details 表存储每日详细数据

create_history_sql = """ CREATE TABLE IF NOT EXISTS `history` ( `ds` datetime NOT NULL, `confirm` int(11) DEFAULT NULL, `confirm_add` int(11) DEFAULT NULL, `suspect` int(11) DEFAULT NULL, `suspect_add` int(11) DEFAULT NULL, `heal` int(11) DEFAULT NULL, `heal_add` int(11) DEFAULT NULL, `dead` int(11) DEFAULT NULL, `dead_add` int(11) DEFAULT NULL, PRIMARY KEY (`ds`) ); """ create_details_sql = """ CREATE TABLE IF NOT EXISTS `details` ( `id` INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, `update_time` datetime DEFAULT NULL, `province` varchar(50) DEFAULT NULL, `city` varchar(50) DEFAULT NULL, `confirm` int(11) DEFAULT NULL, `confirm_add` int(11) DEFAULT NULL, `heal` int(11) DEFAULT NULL, `dead` int(11) DEFAULT NULL ); """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
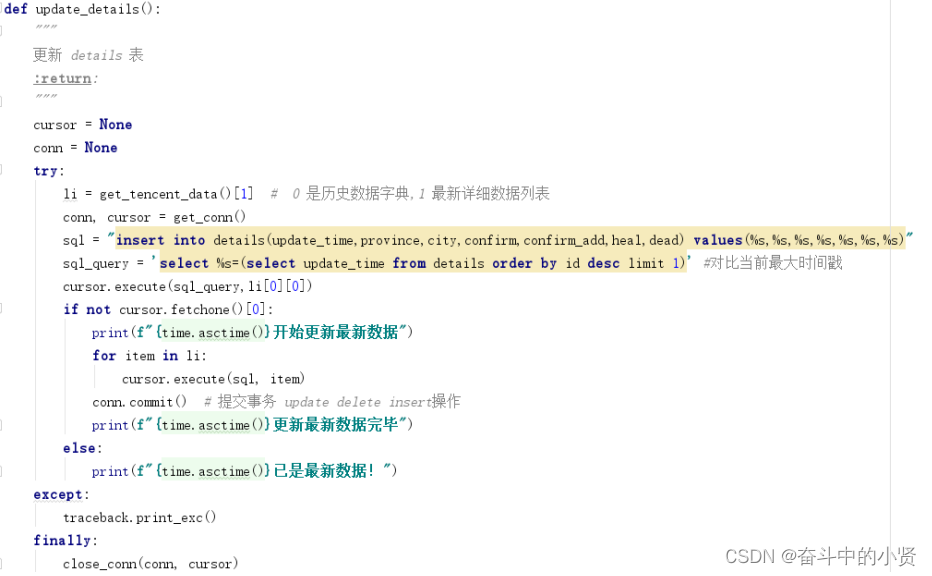
➢使用 pymysql 模块与数据库交互 ➢安装: pip install pymysql ① 建立连接 ② 创建游标 ③ 执行操作 ④ 关闭连接- 1
- 2
- 3
- 4
- 5
- 6
2.3 爬取百度热搜数据(部分代码)
百度的数据页面使用了动态渲染技术,我们可以用 selenium 来爬取
➢selenium 是一个用于 web 应用程序测试的工具,直接运行在浏览器中,就像真正的用
户在操作一样
➢安装: pip install selenium
➢安装浏览器(谷歌、火狐等) ➢下载对应版本浏览器驱动:
谷歌驱动https://registry.npmmirror.com/binary.html?path=chromedriver/
① 创建浏览器对象
② 浏览器.get()
③ 浏览器.find()2.3.1数据爬取

2.3.2数据存储
同样,我们也需要把数据存储到mysql 数据库

🥊三、Web程序开发
3.1Flask 快速入门
Flask 是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI(Python Web Server Gateway Interface) 工具包采用 Werkzeug ,模板引擎则使用 Jinja2 ,是目前十分流行的 web 框架。
• 安装:pip install flask
• 创建 Flask 项目
项目结构
from flask import Flask, jsonify, render_template import sqlite3 import config app = Flask(__name__) @app.route('/', methods=['GET']) def index(): return render_template('index.html') @app.route('/map_data', methods=['GET']) def map_data(): conn = sqlite3.connect(config.DB_PATH) cursor = conn.cursor() cursor.execute("select * from details where city = ''") result = [] for row in cursor.fetchall(): result.append({"name": row[2], "value": row[4]}) cursor.close() conn.close() return jsonify(result), 201 @app.route('/count_data', methods=['GET']) def count_data(): conn = sqlite3.connect(config.DB_PATH) cursor = conn.cursor() cursor.execute("select * from history where ds = (select max(ds) from history)") row = cursor.fetchone() cursor.close() conn.close() return jsonify([row[1], row[2], row[5], row[7]]), 201 @app.route('/word_data', methods=['GET']) def word_data(): conn = sqlite3.connect(config.DB_PATH) cursor = conn.cursor() # cursor.execute("select city,confirm from details where city !='' and city !='待确认地区' limit 2,25") cursor.execute("select province,heal from details group by province") # row = cursor.fetchall() result = [] for row in cursor.fetchall(): result.append({"name": row[0], "value": row[1]}) cursor.close() conn.close() return jsonify(result), 201 @app.route('/sum_data', methods=['GET']) def sum_data(): conn = sqlite3.connect(config.DB_PATH) cursor = conn.cursor() # 取日期最新的30天数据,按新到旧排序 cursor.execute("select ds,confirm,suspect,heal,dead from history order by ds desc limit 30") result = { "legend": ['累计确诊', '剩余疑似', '累计治愈', '累计死亡'], "ds": [], "confirm": [], "suspect": [], "heal": [], "dead": [] } for row in cursor.fetchall(): result['ds'].append(row[0]) result['confirm'].append(row[1]) result['suspect'].append(row[2]) result['heal'].append(row[3]) result['dead'].append(row[4]) # 重新排序数据,按日期顺序排序 result['ds'] = result['ds'][::-1] result['confirm'] = result['confirm'][::-1] result['suspect'] = result['suspect'][::-1] result['heal'] = result['heal'][::-1] result['dead'] = result['dead'][::-1] cursor.close() conn.close() return jsonify(result), 201 @app.route('/add_data', methods=['GET']) def add_data(): conn = sqlite3.connect(config.DB_PATH) cursor = conn.cursor() # 取日期最新的30天数据,按新到旧排序 cursor.execute("select ds,confirm_add,suspect_add,heal_add,dead_add from history order by ds desc limit 30") result = { "legend": ['新增确诊', '新增疑似', '新增治愈', '新增死亡'], "ds": [], "confirm": [], "suspect": [], "heal": [], "dead": [] } for row in cursor.fetchall(): result['ds'].append(row[0]) result['confirm'].append(row[1]) result['suspect'].append(row[2]) result['heal'].append(row[3]) result['dead'].append(row[4]) # 重新排序数据,按日期顺序排序 result['ds'] = result['ds'][::-1] result['confirm'] = result['confirm'][::-1] result['suspect'] = result['suspect'][::-1] result['heal'] = result['heal'][::-1] result['dead'] = result['dead'][::-1] cursor.close() conn.close() return jsonify(result), 201 @app.route('/bar_data', methods=['GET']) def bar_data(): conn = sqlite3.connect(config.DB_PATH) cursor = conn.cursor() cursor.execute("select city,confirm from details where province='福建' order by confirm asc limit 4,5") # row = cursor.fetchall() result = { "city": [], "confirm": [] } for row in cursor.fetchall(): result['city'].append(row[0]) result['confirm'].append(row[1]) cursor.close() conn.close() return jsonify(result), 201 if __name__ == '__main__': app.run('0.0.0.0', 9999)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
• 模板的使用
➢模板就是预先写好的页面, 里面可以使用特殊语法引入 变量 ➢使用 render_template 返 回模板页面- 1
- 2
- 3
- 4
- 5
DOCTYPE html> <html> <head> <title>全国疫情监控可视化title> <script type="text/javascript" src="static/js/jquery-3.6.0.js">script> <script src="static/js/echarts.min.js">script> <script src="static/js/echarts-wordcloud.js">script> <script src="static/js/china.js">script> <script type="text/javascript" src="static/js/main.js">script> <script type="text/javascript" src="static/js/charts.js">script> <link rel="stylesheet" href="static/css/common.css"/> head> <body> <div class="container"> <div class="top"> <h1>全国疫情实时追踪h1> <div id="time">div> div> <div class="side"> <div id="left_top">div> <div id="left_bottom">div> div> <div class="middle"> <div id="mt"> <div> <h1>h1> <span>累计确诊span> div> <div> <h1>h1> <span>今日新增span> div> <div> <h1>h1> <span>累计治愈span> div> <div> <h1>h1> <span>累计死亡span> div> div> <div id="middle_bottom">div> div> <div class="side"> <div id="right_top">div> <div id="right_bottom">div> div> div> body> <script> window.onload = function () { //事件处理函数 getDataAndDrawLine("left_top","全国累积趋势") getDataAndDrawLine("left_bottom","全国新增趋势") getDataAndDrawBar("right_top") getDataAndDrawWord("right_bottom") getDataAndDrawMap("middle_bottom") } script> html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
• Flask 获取请求参数
➢ 使用 request 对象获取参数 ① request.values 获取参数字典 ② request.values.get("参数名")- 1
- 2
- 3
• 使用 Ajax 局部刷新页面
➢Ajax 是 Asynchronous JavaScript and XML 的简称,通过 Ajax 向服务器发送请求,接收服务器返回的 json数据,然后使用 JavaScript 修改网页的来实现页面局部数据更新 ➢使用 jquery 框架可方便的编写ajax代码,需要 jquery.js 文件- 1
- 2

3.2 可视化大屏模板制作
• 使用绝对定位划分版块

• echarts 快速入门
ECharts,缩写来自 Enterprise Charts,商业级数据图表,是百度的一个开源的数据可视化工具,提供了丰富的图表库,能够在 PC 端和移动设备上流畅运行
官方网站
https://echarts.apache.org/zh/index.html

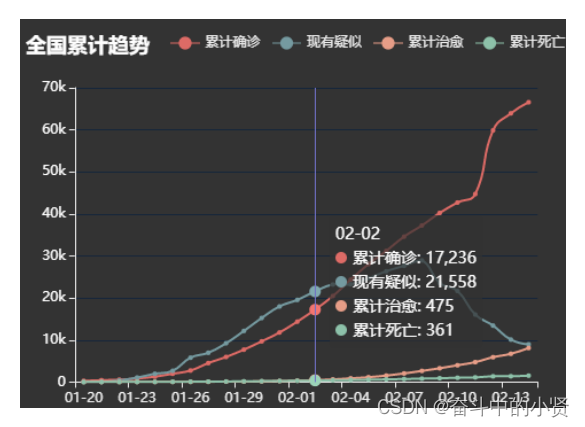
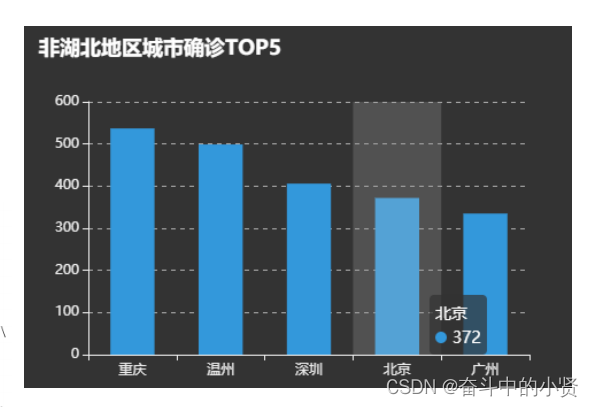

🥊四、项目部署
4.1 部署 Flask 项目
• 生产模式部署
➢部署 Flask 应用时,通常都是使用一种 WSGI 应用服务器搭配 Nginx 作为反向代理 ➢常用的 WSGI 服务器: gunicorn、uwsgi ➢反向代理和正向代理:- 1
- 2
- 3

➢安装 Nginx:yum install nginx ➢安装 Gunicorn: pip install gunicorn ➢启动 Gunicorn: gunicorn -b 127.0.0.1:8080 -D my_app:app ➢编辑 Nginx 配置文件 vim /etc/nginx/nginx.conf ➢启动 Nginx : /usr/sbin/nginx- 1
- 2
- 3
- 4
- 5
• 获取脚本参数
➢sys.argv ➢sys.argv[0] 是脚本所在绝对路径 ➢根据不同参数调用不用方法- 1
- 2
- 3
• Linux 安装 chrome
➢yum install https://dl.google.com/linux/direct/google-chromestable_current_x86_64.rpm- 1
• 下载 chromedriver
➢http://npm.taobao.org/mirrors/chromedriver/- 1
• 获取crontab 定时调度
➢crontab –l 列出当前任务 ➢crontab –e 编辑任务- 1
- 2

🥊总结
本项目到这里我们就全部讲完啦!!!!👍👍👍 如果有帮到你欢迎给个三连支持一下哦❤️ ❤️ ❤️需要源码私信哦!!!
如果有哪些需要修改的地方欢迎指正啦!!!一起加油啦👏👏👏 -
相关阅读:
软件系统测试怎么进行?有什么注意事项?
Pytorch之GoogLeNet图像分类
SpringBoot2应用及其底层源码学习(一)(转自尚硅谷)
GO语言容器大全(附样例代码)
【BOOST C++ 19 应用库】(6)Boost.Uuid
大一新生必备电脑软件&插件有哪些?
三个禁止使用U盘的方案
Java设计模式-状态模式
【语音识别】搭建本地的语音转文字系统:FunASR
(附源码)php在线考试系统 毕业设计 032028
- 原文地址:https://blog.csdn.net/weixin_53000329/article/details/126322231
