-
HashMap是怎么解决哈希冲突的?
HashMap是怎么解决哈希冲突的?
一搜博客啊,我靠,咱也不知道写的啥都。人家问的是HashMap是怎么解决哈希冲突的?,写一堆乱七八糟的方法,也没扣上题,可显得会的多啊,哎
没办法,自己整吧接着。
首先HashMap采用链式寻址法,其他三个方法是扩展的昂,他们可以解决哈希冲突,是一种思想,但不是HashMap里用的啊可!!!!
什么是哈希冲突?
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们就把它叫做碰撞(哈希碰撞/冲突)。
HashMap采用链式寻址法解决
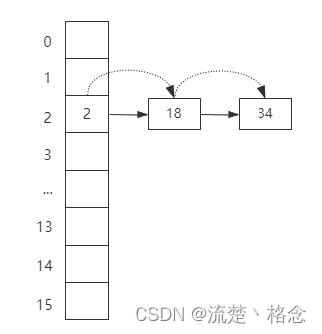
首先,HashMap底层采用了数组的结构来存储数据元素,数组的默认长度是16,当我们通过put方法添加数据的时候,HashMap根据Key的hash值进行取模运算,最终根据得到的结果将数据保存到数组的指定位置。
但是这种设计会存在hash冲突问题,也就是两个不同hash值的key,最终取模后会落到同一个数组下标。
所以HashMap引入了链式寻址法来解决hash冲突问题, 对于存在冲突的key,HashMap把这些key组成一个单向链表,然后采用尾插法把这个key保存到链表的尾部。
然后还会使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均;public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }- 1
- 2
- 3
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }- 1
- 2
- 3
- 4
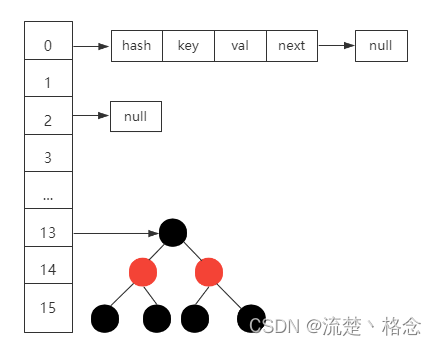
另外,为了避免链表过长的问题,当链表长度大于8并且数组长度大于等于64的时候,HashMap会把链表转化为红黑树,从而减少链表数据查询的时间复杂度问题,提升查询性能。
扩展
另外:解决hash冲突问题的方法有很多
-
开放寻址法:直接从冲突的数组位置往下寻找一个空的数组下标进行数据存储,这个在ThreadLocal里面有使用到。
-
再hash法:如果某个hash函数产生了冲突,再用另外一个hash进行计算,比如布隆过滤器就采用了这种方法。
-
建立公共溢出区:也就是把存在冲突的key统一放在一个公共溢出区里面。
开放寻址法
开放定址法也称线性探测法,就是从发生冲突的那个位置开始,按照一定次序从Hash表找到一个空闲位置然后把发生冲突的元素存入到这个位置,而在java中,ThreadLocal就用到了线性探测法来解决Hash冲突
如图,在Hash表索引1的位置存了key=name,再向它添加key=hobby的时候,假设计算得到的索引也是1,那么这个时候发生哈希冲突,而开放开放定址法就是按照顺序向前找到一个空闲的位置,来存储这个冲突的key
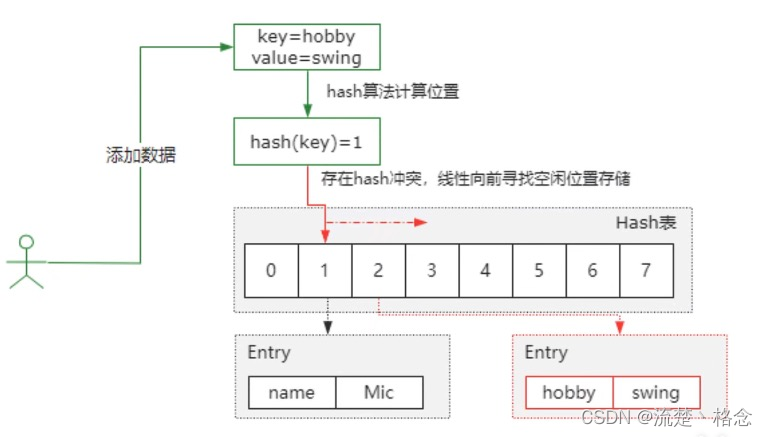
如图,在Hash表索引1的位置存了key=name,再向它添加key=hobby的时候,假设计算得到的索引也是1,那么这个时候发生哈希冲突,而开放开放定址法就是按照顺序向前找到一个空闲的位置,来存储这个冲突的key再Hash法
就是通过某个Hash函数计算的key,存在冲突的时候,再用另外一个Hash函数对这个可以进行Hash,一直运算,直到不再产生冲突为止,这种方式会增加计算的一个时间,性能上呢会有一些影响
建立公共溢出区
建立公共溢出区,就是把Hash表分为基本表和益处表两个部分,凡是存在冲突的元素,一律放到溢出表中
-
相关阅读:
Linux快速上手6:常用命令之压缩解压命令
技术心得--如何成为优秀的架构师
2022最新版-李宏毅机器学习深度学习课程-P49 GPT的野望
Python Fire:更加灵活的命令行参数
数据结构—链表
LC-2300. 咒语和药水的成功对数(排序+贪心、排序+二分)
JavaScript高级复习下(60th)
Qt创建线程(使用moveToThread方法创建子线程)
Redis(五)发布与订阅
【Python(一)】环境搭建之Anaconda安装
- 原文地址:https://blog.csdn.net/weixin_45525272/article/details/126347752