-
Java 异常
Java异常是Java提供的一种识别及响应错误的一致性机制异常继承图
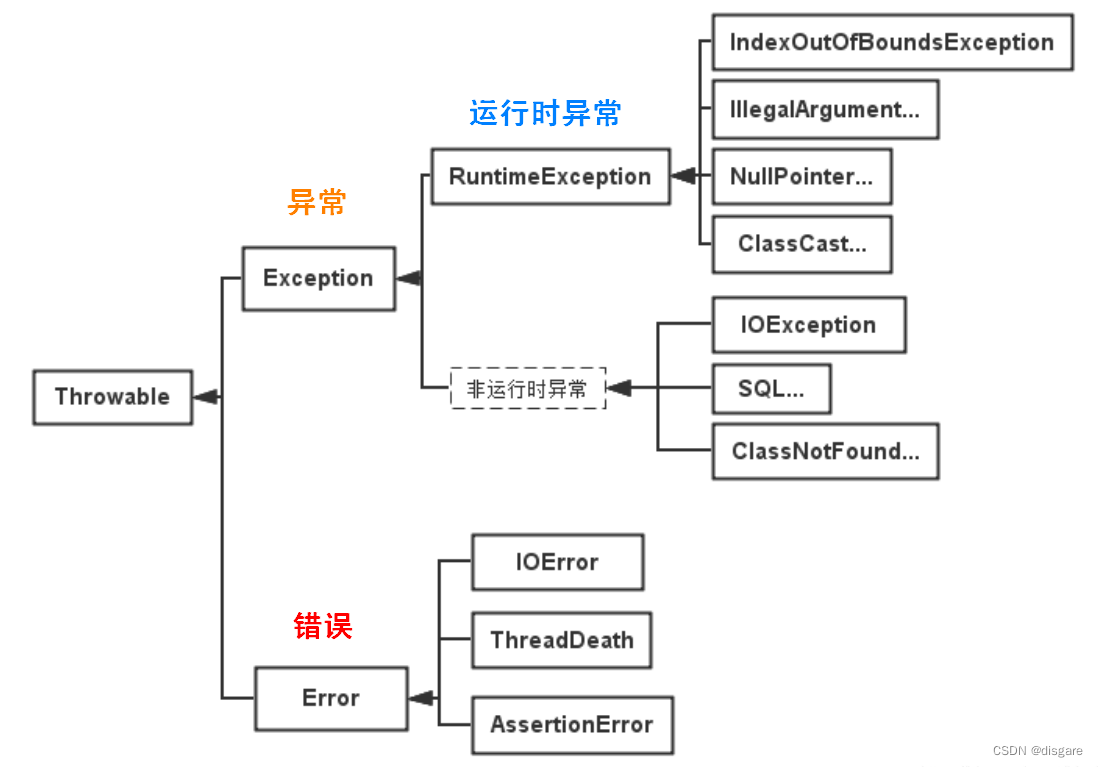
Throwable 实现了 Serializable 接口,它有 Error 与 Exception 两个子类,程序出现错误时,方法就会向外抛异常,它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息Error 类及其子类表示了程序中无法处理的错误。比如著名的 OOM,以及虚拟机栈中可能会出现的 StackOverflowError 等错误。此类错误发生时,JVM 将终止线程,我们也不应该处理这些错误
Exception 中的非运行时异常如果不在写代码时手动处理,程序就不能编译通过,比如如 IOException、SQLException 等异常。这类异常又被称为可查异常,即编译器要求必须处理的异常
Exception 中的运行时异常 RuntimeExceptionn 是我们着重关注的异常类型,可以自定义异常来表示运行时异常的错误类型。一个程序员水平的高低一定程度上取决于对异常情况的考量。这类异常又被称为不可查异常,编译器不会要求处理
try-catch-finally
这个捕获异常的语句有以下特性
- 在一个 try-catch 语句块中可以捕获多个异常类型,同一个 catch 也可以捕获多种类型异常,用 | 隔开
- 不管是 try、catch还是 finally 中出现了异常,都是从异常发生的行数结束代码块的,异常发生之前的行数是会正常运行的
- 在 try 或者 catch 语句中定义了 return 或者 throw 语句,程序会在这些语句之前先执行 finally 代码块,再返回结果,如果在 finally 代码块中出现了异常或者 return 语句,会直接返回
- finally 可用在不需要捕获异常的代码,可以保证资源在使用后被关闭。例如使用Lock对象保证线程同步,通过finally可以保证锁会被释放;数据库连接代码时,关闭连接操作等
不想在 finally 语句块中定义一遍又一遍关闭链接的代码块的话,可以考虑实现 AutoCloseable 接口。JAVA 7 提供了可以自动释放资源的接口 AutoCloseable,比如 Scanner
public final class Scanner implements Iterator<String>, Closeable { // ... } public interface Closeable extends AutoCloseable { public void close() throws IOException; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
它有什么好处呢?finally 中的 close 方法也可能抛出 IOException, 从而覆盖了原始异常,实现该接口的话抛出的仍然为原始异常。被抑制的异常会由 addSusppressed 方法添加到原来的异常,如果想要获取被抑制的异常列表,可以调用 getSuppressed 方法来获取
最佳实践
1,尽量使用标准的异常,在不可避免的情况下才自定义异常,常见的异常如下:
- IllegalArgumentException 参数的值不合适
- NullPointerException 在null被禁止的情况下参数值为null
- ConcurrentModificationException 在禁止并发修改的情况下,对象检测到并发修改
2,在提供 RPC 接口时或者服务层接口时可能出现的异常需要使用 throws 抛出,声明抛出异常时,也需要使用 @throws 进行文档说明;调用接口时也需要考虑调用失败的情况
3,不要吞掉异常;不要捕获 Throwable 类;有多个 throw 时,应该按从细到粗的粒度捕获异常;不要记录并抛出异常,这样会给同一个异常输出多条日志;不要使用 printStackTrace 方法打印堆栈信息
4,包装异常时不要抛弃原始的异常
为什么要改变异常类型?在多系统集成时,当某个子系统故障,异常类型可能有多种,可以用统一的异常类型向外暴露,不需暴露太多内部异常细节;或者为异常提交更为详细的错误信息
那应该怎么包装异常?使用 try-catch 捕获异常之后,可以使用 Exception 类提供的构造方法传入原本的异常。该类也提供了一些方法来传入异常
catch (Exception e) { throw new MyException("hello exception", e); }- 1
- 2
- 3
JVM 层面的异常处理
JVM 使用 Exception Table 异常表来处理异常,在使用 try-catch-finally 语句后,class 文件的常量池后面会出现类似这样的语句
Exception table: from to target type 0 3 6 Class java/lang/Exception 0 3 15 any 6 8 15 any- 1
- 2
- 3
- 4
- 5
各个属性的解释
- from 可能发生异常的起始点
- to 可能发生异常的结束点
- target 上述from和to之前发生异常后的异常处理者的位置
- type 异常处理者处理的异常的类信息,any 表示发生了任何异常都会跳转到这个语句并执行
当异常发生时,JVM会这么处理
- 如果当前方法异常表不为空,并且异常符合处理者的from和to节点,并且type也匹配,则调用位于target的调用者来处理
- 如果上一条未找到合理的处理者,则继续查找异常表中的剩余条目。如果当前方法的异常表无法处理,则向上查找(弹栈处理)刚刚调用该方法的调用处,并重复上面的操作
- 如果所有的栈帧被弹出,仍然没有处理,则抛给当前的Thread,Thread则会终止
- 如果当前Thread为最后一个非守护线程,且未处理异常,则会导致JVM终止运行
跳转语句
你可能会想到在 try 或者 catch 语句中定义了 return 或者 throw 语句,程序会在这些语句之前先执行 finally 代码块,再返回结果,这一段过程 JVM 是如何实现的
Code: 0: invokestatic #3 // Method testNPE:()V 3: goto 11 6: astore_0 7: aload_0 8: invokevirtual #5 // Method java/lang/Exception.printStackTrace:()V 11: return- 1
- 2
- 3
- 4
- 5
- 6
- 7
就是利用这个 goto 语句实现的,将 return 语句写在最后面,在 try 或者 catch 的语句里面定义的 return 语句都会被替换为 goto
异常为什么会耗时(源码层面异常处理)
众所周知,建立一个异常对象,是建立一个普通Object耗时的约20倍,而抛出、接住一个异常对象,所花费时间大约是建立异常对象的4倍,这是为什么呢?
先来看看 Throwable 的源码,它的成员变量如下
//空数组 private static final StackTraceElement[] UNASSIGNED_STACK = new StackTraceElement[0] // 堆栈信息 private StackTraceElement[] stackTrace = UNASSIGNED_STACK; // 异常的具体信息,比如:FileNotFoundException , 就是 the file that could not be found private String detailMessage; //导致这个异常被抛出的原因 private Throwable cause = this;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
同时需要注意的还有这个类,StackTraceElement 为程序的堆栈信息,描述了类,方法,文件名,行号。你用getStackTrace 方法,拿到的就是 StackTraceElement 数组
public final class StackTraceElement implements java.io.Serializable { private String declaringClass; private String methodName; private String fileName; private int lineNumber; ...- 1
- 2
- 3
- 4
- 5
- 6
Throwable 的四个构造函数最终都会调用 fillInStackTrace 方法,所以构造函数我们无视,直接看 fillInStackTrace
public synchronized Throwable fillInStackTrace() { if (stackTrace != null || backtrace != null /* Out of protocol state */ ) { fillInStackTrace(0); stackTrace = UNASSIGNED_STACK; } return this; } private native Throwable fillInStackTrace(int dummy);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
我们看到它在构造一个异常对象的时候居然上锁了,这是它性能问题的原因之一。调用的 native 方法大致就是把当前堆栈快照给记录到 stackTrace 这个 StackTraceElement 数组中,记录栈帧所指向的类名,方法名,以及在哪一行代码上抛出的异常信息等等,这个方法的执行过程也是性能问题原因之一
我们有时new自己定义的业务异常时,且用不到堆栈,但是会调用这个方法,严重影响系统性能。因此,如果自定义异常的话一定要把 fillInStackTrace 重写掉
因为获取异常堆栈、创建并 catch 异常都要消耗大量的性能,如果调用 printStackTrace 方法它会把所有的堆栈打印出来而且这个过程还是上锁的,如果再把它输出到日志,加上 IO 消耗,那性能简直没法看,所以不要输出异常堆栈
最后还留有一个问题:
异常在出现的时候就已经被确定类型了,在发生异常的时候会创建一个异常对象,那底层到底是怎么确定异常类型的呢?
-
相关阅读:
洛谷 P2922 / bzoj1590【Trie】
ffmpeg ts 关于av_seek_frame
微服务从代码到k8s部署应有尽有系列(三、鉴权)
表单与列表在HTML与CSS中是这么玩的
SQL基本语法用例大全
一个月赚够一年钱的“服装博览会”,堪称商户老板的噩梦!
精准突击!Mysql亿级数据开发手册,GitHub 132k starts | 实战解析。
机器学习(七)模型选择
【PB续命04】借用Oracle的加密解密续命
【附源码】计算机毕业设计JAVA客户台账管理
- 原文地址:https://blog.csdn.net/sekever/article/details/126340194